
基于时-空特征的全卷积网络用于视频人眼关注预测的研究
2019-08-02 02:41史久琛孙美君
天津大学学报(自然科学与工程技术版) 2019年10期
史久琛,孙美君,王 征,张 冬
(1. 上海交通大学电子信息与电气工程学院,上海 200240;2. 天津大学智能与计算学部,天津 300072;3. 天津中医药大学中医药研究院,天津 300193)
随着互联网时代的高速发展,各种视频数量井喷式增长,视频内容愈加丰富.面对海量的多媒体资源,通过人工方式对多媒体视频语义信息进行过滤筛选的成本过高,因此,如何利用计算机算法快速精准地自动提取视频中的关键信息,是当前研究的热点问题之一[1].
人眼视觉关注预测是视频内容分析的重要内容之一,它能够获取视频中由于颜色、纹理、运动、形状、语义等多种特征的差别而最能吸引人眼视觉关注的区域,在视频语义分析、目标跟踪、对象分割等方面有着重要的应用.因此,通过自动的、准确的算法对视频中人眼视觉关注区域进行预测,可以有效地辅助进行视频分析[2].
20世纪50年代,国内外学者就开始了对人眼视觉显著性的研究.20世纪80年代,Marr等综合运用神经生物学、心理学、图像处理等方面的研究成果,提出了第一个该领域的视觉系统框架,从此使得人类对于视觉注意机制和计算机视觉的研究有了较为明确的体系.20世纪90年代,Itti等[3]提出获取初级视觉特征,得到高斯金字塔,并且通过中心-邻域算子建立模型得到结果图.此模型带来了深远的影响,部分学者之后在此模型的基础上进行了改进.Bruce等[4]探索了一种信息理论方法,利用图像中的局部显著性信息来预测人的注意力分配点. Oliva等[5]对于整个场景中的局部特性进行统计,采用场景中的稀疏性作为显著性研究的一个关键因素.Vig等[6]提出了一种通过在不同的特征生成模型配置上执行大规模搜索来获得最优特征的方法.
2012年以来,随着深度学习的发展,有学者研究将卷积神经网络(convolutional neural networks,CNN)用于图像人眼视觉关注的预测,CNN是一种深度前馈人工神经网络,在图像分类、分割、识别上取得了重大的进展[7].Liu等[8]提出了多分辨率CNN网络模型,以每一个像素点作为中心进行模型训练,以特定的比例对图像补丁进行分类以获得显著性信息.但存在开销过大和计算效率低下等问题.在文献[9-10]中,有学者提出了双层的卷积网络用于特征训练,实现视频对象的分割.全卷积网络是 CNN的延伸,没有全连接层从而大大减少了网络参数,提高了处理速度,在图像显著性检测方面取得了较好的结果[11].
综上所述,在视频人眼视觉关注预测中已经有了相关研究工作,但是当前方法依然存在着一些问题,主要表现在:当前预测算法大多基于静态图像开发,直接移植到视频中进行分析时忽略了视频中包含的时间运动信息[12];当前全卷积网络模型的输出结果由于上采样操作存在边界模糊、精确度不足的问题[13].
针对当前研究中存在的问题,本文提出了一种基于时间-空间特征的全卷积网络模型用于视频人眼关注的预测.首先使用全卷积网络提取单个视频帧图像中的显著信息作为空间特征,同时使用光流提取相邻帧之间的目标运动信息作为时间运动特征,共同形成空间-时间特征,有效弥补了当前研究中时间运动信息体现不明显的问题,同时使用长短期记忆网络逐层分析当前帧与其前 6帧的空间-时间特征,进一步增强视频序列中的时间运动信息.使用 INB和 IVB两个人眼关注视频数据库进行实验,以地球移动距离、受试者工作特征曲线下面积、标准化扫描路径显著性、线性相关性等 4个参数作为性能评估标准,验证本文方法的准确性.
1 基于时-空特征的全卷积网络模型
1.1 基于全卷积网络和光流的视频时-空特征提取
全卷积神经网络(fully convolutional networks,FCN)当前被广泛地应用于图像分割、目标检测等方面,其在显著性标记和视觉关注点检测等方面取得了较好的结果.全卷积神经网络将传统卷积神经网络中的全连接层转化成多个卷积层,并通过反卷积和上采样来获取与输入相同大小的结果输出[14].因此本文对视频中的单帧图像采用全卷积神经网络计算其图像的空间特征.
图 1显示了本文所用全卷积神经网络的结构和参数.针对单帧视频图像的处理过程与已训练优化的VGG-M模型结构类似[15]的特点,输入层为原始视频帧图像,大小为 640×360×3,经过第一层卷积操作(卷积核为 7×7×96)之后,再经过局部响应归一化(local response normalization,LRN)后,输入到大小为 3×3、步长为 2的最大池化层中,得到处理结果.然后将其输入到第二层卷积层(卷积核为 5×5×256),第二层最大池化层(大小为 3×3,步长为 2)中,继续进行卷积操作,各个卷积核大小如图 1中卷积层 3~8所示,得到视频帧经过卷积操作之后的结果,值得注意的是除了最后一个卷积层,其余的每一个卷积层后紧临一个整流线性单元(rectified linear unit,ReLU)作为激活函数进行处理.最后进行反卷积操作,反卷积核大小为 8×8×1,步长为 4,最终得到与输入视频帧图像同样大小的结果输出,能够反映视频帧中引起人眼视觉关注的区域.
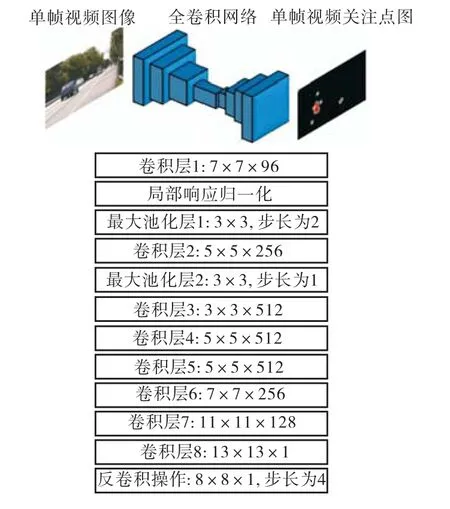
图1 单视频帧图像的全卷积网络模型结构Fig.1 Structure of the FCN in single video frame image
但是全卷积神经网络由于反卷积操作中的上采样使得检测结果模糊、精细度不足,并且只是在单个视频帧图像上进行空间特征提取,忽略了视频中的时间特征,因此本文使用光流算法计算视频中相邻帧之间的光流特征作为运动时间特征,如图2所示.
光流是目前运动图像分析的重要方法,能够获取图像中目标运动的变化信息,在目标对象分割、识别、跟踪等领域有着非常重要的应用.根据人眼视觉关注规律,在视频中,运动的目标物体容易吸引人眼的关注[16].假设相邻两帧视频图像的时刻分别为t和t+Δt,假设某点在时刻t的灰度值为I(x,y,t),在时刻t+Δt该点运动到了(x+Δx,y+Δy),其灰度值变为了I(x+Δx,y+Δy,t+Δt),在很短的时间间隔 Δt内灰度值保持不变,则有
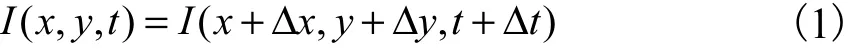
将上式按照泰勒公式展开,得到

在x和y方向,假设u=dx/dt,v=dy/dt,Ix、Iy和It分别表示I(x,y,t)对x坐标、y坐标和时间t坐标的偏导数,则可以简写为

式(3)则为光流约束方程,通过求解可以得到相邻帧之间的光流场变化.
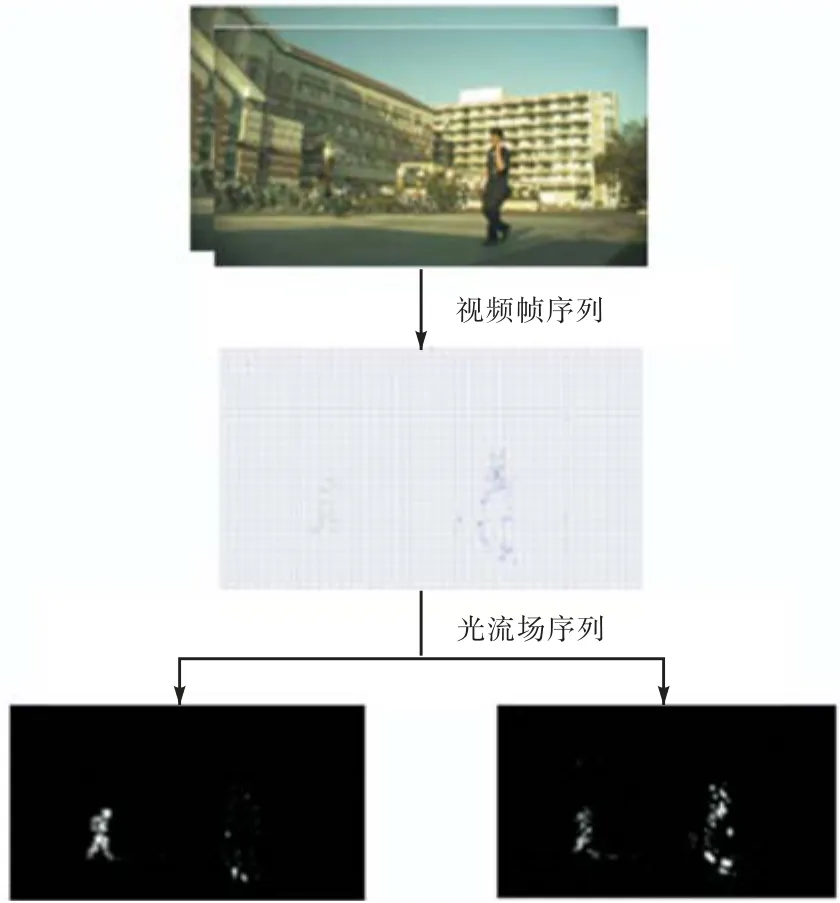
图2 针对视频帧的光流计算Fig.2 Optical flow calculation for video frames
1.2 长短期记忆网络
长短期记忆网络(long short term memory,LSTM)是一种时间递归神经网络,适合于处理和预测时间序列中间隔和延迟相对较长的重要事件.LSTM解决了梯度消失问题从而解决了在时序问题中存在的上下文长依赖问题.LSTM的每个单元中有输入门限、遗忘门限和输出门限,通过门控机制,单元中可以保持一段时间的信息,并在训练时保持内部梯度不受干扰[17].
二是着力加强农业生产环节管理。实行分公司、生产区、大队三级管理模式,不断提高农业管理精细化程度,提高农技人员队伍素质;建立与现代农业发展相配套的农机管理体系,采取国有农机总站与民营农机相结合的管理模式,高起点、高标准发展国有农机和民营农机。
本文方法使用LSTM依次分析上述得到的时间-空间特征信息,得到一定时间间隔内的人眼视觉关注结果.
1.3 基于时-空特征的全卷积网络模型
图 3显示了本文提出的基于时-空特征的全卷积网络模型方法.由视觉残差机制可知,人眼在观察某帧视频图像后,该帧图像会在视网膜上停留一定时间,本文设定停留时间为 7帧视频图像,并提取该 7帧视频图像的时-空特征进行显著性预测.从图 3中可以看出,本文方法通过全卷积网络提取了视频中第i帧和其前 6帧的空间全卷积网络特征.同时使用光流算法提取了第i帧的时间运动特征,再逐层通过LSTM对空间特征和时间特征进行计算融合,得到最终的人眼关注显著图.
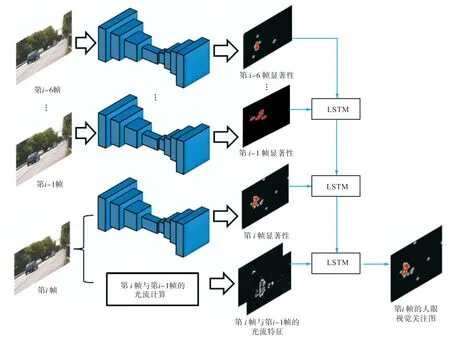
图3 基于时-空特征的全卷积网络模型结构Fig. 3 FCN model structure based on spatial-temporal features
2 实验结果
2.1 视频数据库
本文实验采用的是公开的视频数据库 Lübeck INB[18]和 IVB[19].Lübeck INB 视频数据库中包含了18个时长为 20s的视频片段,大部分是在固定镜头下拍摄的自然场景.IVB视频数据库中包含了 12个时长为6~12s的视频片段.具体的描述如表1所示.

表1 本文使用的视频数据库基本信息Tab.1 Basic information of the video database
为了评估本文方法的准确性,还需要得到视频数据库中的人眼关注区域标准图.本文所用视频数据库同时还通过专业仪器独立记录了不同受试观察者在观看每一帧视频时其人眼所在的位置坐标.IVB视频数据库记录了15个观察者在观看视频时的人眼关注点变化.INB视频数据库中人眼关注点的变化则由54位观察者进行标注.
视频中人眼关注显著区域的标准图计算公式为[20]
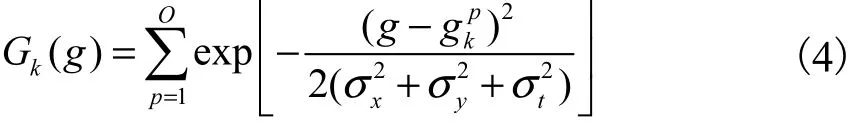
式中:Gk(g)为第k帧的人眼关注图G中的像素点;p ∈ [1,O],O表示视频数据库人眼关注度的观察者人数;gp=(x, y, t)表示第p个观察者的关注点;σ、kxσy、σt分别为 3D 高斯核在x、y、t方向上的标准偏差数值,其中σx、σy都为图像宽度的 0.01,σt为130ms.经过该 3D高斯核的处理,所得到的人眼关注显著区域的标准图较符合人眼视觉特点.
2.2 评价方法
假设通过不同观察者的实际关注点数据计算得到的视频关注图作为标准值G,将经过本文方法预测得到的视频人眼关注图记为预测值P,则本文使用地球移动距离、受试者工作特征曲线下面积,标准化扫描路径显著性、线性相关性作为评价指标进行模型的性能评价.
地球移动距离(earth mover's distance,EMD)是在某一区域两个概率分布距离的度量.通过计算EMD,能够获取将预测得到的显著图P的概率分布转换为标准显著图G的概率分布所需的最小成本.因此,EMD 数值越小,表示两幅显著图的概率分布越接近.
受试者工作特征曲线下面积(area under receiver operating characteristic,AUC)是在显著图性能评估中使用最广泛的评估标准.通过改变预测显著图中的分类阈值,将其与真实显著图对比得到真正类和假负类形成的受试者工作特征曲线(receiver operating characteristic,ROC),ROC 曲线与横纵坐标所形成的图像面积即为 AUC.通过定义可知,AUC为 0表示命中率为0,预测结果完全错误,AUC为1表示命中率为1.
标准化扫描路径显著性(normalized scanpath saliency,NSS)是 Peters等[21]为显著图评估特别引入的度量,通过计算预测显著图(具有零均值和单位标准偏差)中人眼固定点位置对应的显著性平均值来定义.
线性相关性(linear correlation coefficient,CC)通过计算预测显著图与标准显著图之间的线性相关性进行性能评估,其中线性相关性越接近 1,表示两幅显著图之间的相关性越高.
2.3 实验设置
本文实验共使用了INB和IVB两个数据库,随机选取每个视频数据库中的 80%的片段作为训练集进行模型的训练,剩余的 20%作为测试集进行交叉验证测试本文方法的准确性.
在全卷积网络模型中,训练的迭代数值为200k,初始的学习率为 10-7,动量为 0.9,权值衰减为0.0005.实验硬件环境为 3.4GHz CPU,32G 内存,TITANX GPU.
2.4 实验结果分析
本文选取了 5种常用的人眼关注点显著性检测算法作为对比实验,分别为 GBVS[22]、Rahtu[23]、SR[24]、MLSN[25]、MCDL[26].所得到的结果如表 2~表5所示.
GBVS通过模拟视觉原理提取特征,在显著图的生成过程中引入马尔可夫链计算显著值,是一种较为适合处理自然图像的方法.Rahtu是一种结合条件随机场模型进行显著性计算的方法.通过局部特征中的光照、颜色、运动信息等的对比进行统计计算,从而得到显著性区域分割.SR是一个静态和时空显著性统一计算的框架,通过计算给定图像或视频的局部回归核自下而上的实现显著性检测的算法.MLSN通过直接从自然图像中学习并自动将更高级别的语义信息以可扩展的方式结合到模型中进行计算.MCDL建立以一个多层语义特征的深度学习框架进行显著性检测.将全局信息和局部信息同时输入到一个统一的基于卷积神经网络的深度学习框架中.
表 2~表 5显示了本文方法与 5种对比方法的结果数值,本文方法在两个视频数据库 INB和 IVB中的 EMD、AUC、NSS、CC 评价标准结果分别为0.3751、0.8186、2.0241、0.7457 和 0.4137、0.7856、1.9645、0.7349,要优于 5种对比算法.这是因为本文方法综合考虑了视频人眼关注显著性检测的特点,以 FCN提取视频中的显著性区域,以相邻帧的光流特征作为运动特征进行补充,同时计算其前若干帧特征进行 LSTM 计算,得到最终的人眼关注区域显著图.
图 4显示了所用数据库中视频帧的人眼关注区域显著图预测结果.在每个数据库中随机选取了 2个不同的视频片段中的两个视频帧图像进行结果显示.图中使用不同颜色(热度图)标注了预测得到的人眼关注区域,其中红色区域表示人眼关注度更高,黄色蓝色以此递减.第1行是视频帧的图像,第2行为经过计算得到的标准显著图,第3行表示本文方法得到的结果,剩余行分别为对比算法的结果.从其中第1列的结果中可以看出,本文算法的计算结果显著性区域更加精确,位置更加集中,而其他方法中,预测的显著区域范围较大、分布较广,结果精确度较低.从而证明本文方法在进行视频人眼关注区域预测中的准确性与实用性.

表2 使用不同预测模型进行人眼视觉关注点预测的EMD结果Tab.2 EMD of various models for the prediction of eye movements on the eye tracking datasets

表3 使用不同预测模型进行人眼视觉关注点预测的AUC结果Tab.3 AUC of various models for the prediction of eye movements on the eye tracking datasets

表4 使用不同预测模型进行人眼视觉关注点预测的NSS结果Tab.4 NSS of various models for the prediction of eye movements on the eye tracking datasets

表5 使用不同预测模型进行人眼视觉关注点预测的CC结果Tab.5 CC of various models for the prediction of eye movements on the eye tracking datasets
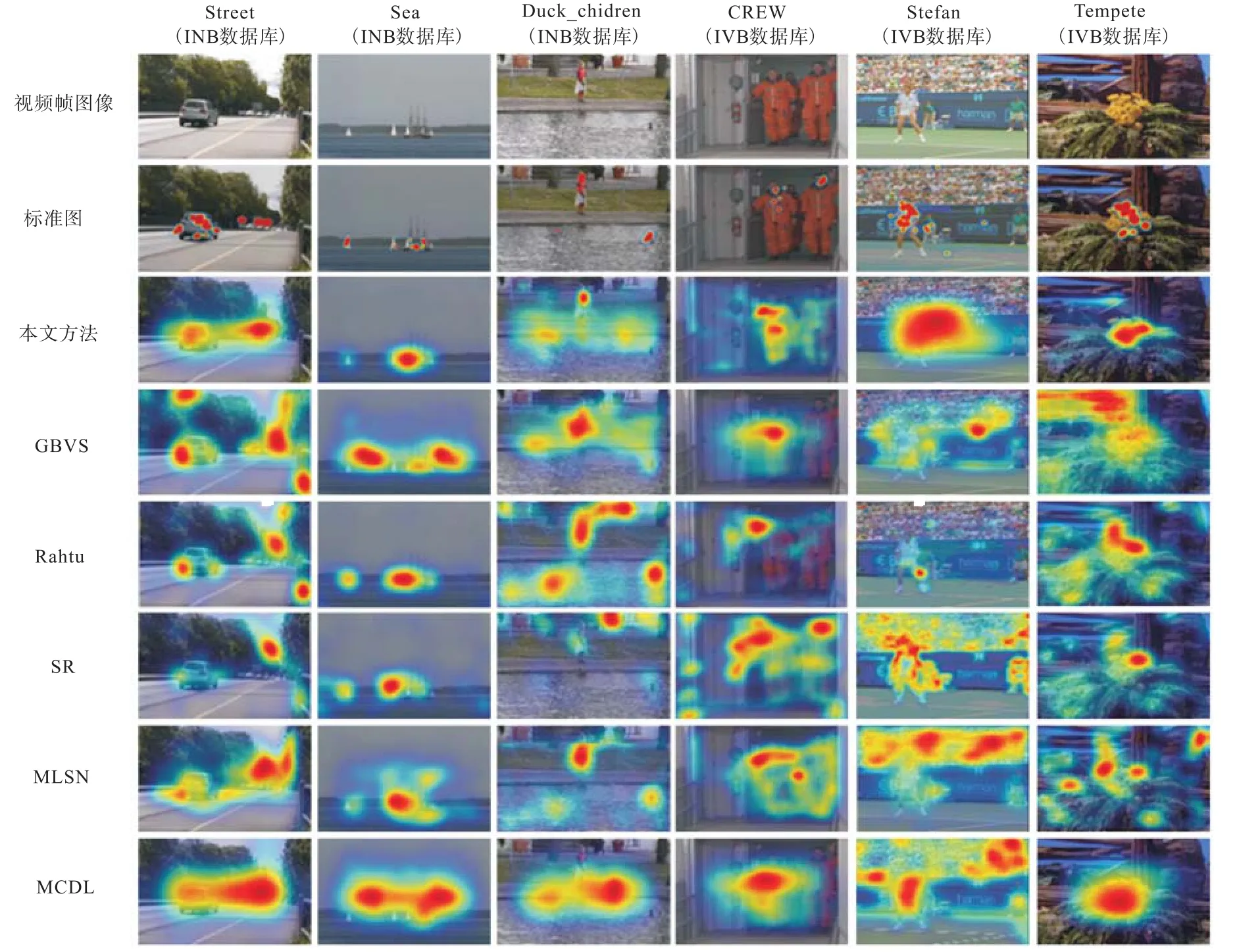
图4 本文方法和对比方法的人眼关注区域的预测结果Fig. 4 Prediction results of the human eye fixation for the method and the comparative methods in this paper
3 结 语
本文提出一种基于时空特征的深度学习模型进行视频中人眼关注区域的预测.首先,全卷积神经网络用于提取视频帧中的底层信息作为空间特征,光流算法用于提取相邻帧之间的运动特征,然后通过LSTM 综合计算当前 7帧的时空特征得到最终的人眼关注区域预测图.实验结果表明,本文方法预测得到的人眼视觉关注区域较准确,能够在视频自动处理与分析中提供帮助.
但是本文方法依然存在着一些问题,比如适用的视频场景较简单、无镜头切换等,计算开销和成本较大.在未来的工作中,笔者将考虑视频中场景复杂、切换频繁的特点,继续优化本文方法,同时降低参数规模,加快计算的速度.
猜你喜欢
山东第一医科大学(山东省医学科学院)学报(2022年7期)2023-01-05
黑龙江大学自然科学学报(2022年1期)2022-03-29
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
快乐语文(2019年9期)2019-06-22
小型微型计算机系统(2019年4期)2019-05-05
电子制作(2019年24期)2019-02-23
北京航空航天大学学报(2018年1期)2018-04-20
优雅(2016年12期)2017-02-28
