
基于孪生神经网络的时间序列相似性度量
2019-08-01 01:54姜逸凡叶青
计算机应用 2019年4期
姜逸凡 叶青

摘 要:在时间序列分类等数据挖掘工作中,不同数据集基于类别的相似性表现有明显不同,因此一个合理有效的相似性度量对数据挖掘非常关键。传统的欧氏距离、余弦距离和动态时间弯曲等方法仅针对数据自身进行相似度公式计算,忽略了不同数据集所包含的知识标注对于相似性度量的影响。为了解决这一问题,提出基于孪生神经网络(SNN)的时间序列相似性度量学习方法。该方法从样例标签的监督信息中学习数据之间的邻域关系,建立时间序列之间的高效距离度量。在UCR提供的时间序列数据集上进行的相似性度量和验证性分类实验的结果表明,与ED/DTW-1NN相比SNN在分类质量总体上有明显的提升。虽然基于动态时间弯曲(DTW)的1近邻(1NN)分类方法在部分数据上表现优于基于SNN的1NN分类方法,但在分类过程的相似度计算复杂度和速度上SNN优于DTW。可见所提方法能明显提高分类数据集相似性的度量效率,在高维、复杂的时间序列的数据分类上有不错的表现。
关键词:时间序列;相似性度量;神经网络;孪生神经网络
中图分类号:TP391
文献标志码:A
文章编号:1001-9081(2019)04-1041-05
Abstract: In data mining such as time series classification, the similarity performance based on category of different datasets are significantly different from each other. Therefore, a reasonable and effective similarity measure is crucial to data mining. The traditional methods such as Euclidean Distance (ED), cosine distance and Dynamic Time Warping (DTW) only focus on the similarity formula of the data themselves, but ignore the influence of the knowledge annotation contained in different datasets on the similarity measure. To solve this problem, a learning method of time series similarity measure based on Siamese Neural Network (SNN) was proposed. In the method, the neighborhood relationship between the data was learnt from the supervision information of sample tags, and an efficient distance measure between time series was established. The similarity measurement and confirmatory classification experiments were performed on UCR-provided time series datasets. Experimental results show that compared with ED/DTW-1NN(one Nearest Neighbors), the overall classification quality of SNN is improved significantly. The Dynamic Time Warping (DTW)-based 1NN calssification method outperforms the SNN-based 1NN classification method on some data, but SNN outperforms DTW in complexity and speed of similarity calculation during the classification. The results show that the proposed method can significantly improve the measurement efficiency of the classification of dataset similarity, and has good performance for high-dimensional and complex time-series data classification.
Key words: time serie; similarity measure; neural network; Siamese Neural Network (SNN)
0 引言
時间序列是某一事件随着时间的推移产生的一系列数据,由一定的时间间隔提取采集得到,对于时间序列的数据挖掘在工业、农业、经济、医疗等领域时间序列都有广泛的应用,例如证券市场的基金、股票数据分析研究[1]、辅助心电图疾病诊断[2]等。时间序列的分类(Time Series Classification, TSC)等数据挖掘研究关键之一是时间序列之间的相似性度量,不同的相似性度量方法对时间序列的挖掘性能有很大的影响。目前主流的时间序列相似性度量使用L-P范数距离(如欧氏距离(European Distance, ED))和动态时间弯曲(Dynamic Time Warping, DTW)[3-6]。这两种距离度量方法都局限于时间序列之间特征向量的固定公式数值计算,不能有效利用标注好的类别标签。实际上,不同数据集的相似性描述并不能一概而论,数据样本中包含的关于类别的先验知识蕴含了相似性的统计规律,这些统计规律可以从标注好的训练集中进行学习,进而构成更有效的数据相似性度量的表达方式。
近年来深度学习在很多领域得到了广泛的应用,一些学者结合距离度量学习[7]与孪生神经网络(Siamese Neural Network, SNN)进行了各种应用研究。SNN最早用于手写签名验证[8],验证平板电脑上书写的签名真伪。文献[9-11]将图像识别中常用的卷积神经网络组成孪生卷积网络(Siamese Convolutional Neural Network, SCNN)模型应用于人脸识别(Face Verification)和行人重识别(Person Re-Identification)达到了不错的识别率。文献[12]将SNN用于文本匹配,每个文本对象分别由子网络单独向量化,计算两个向量的余弦相似度来衡量这两段文本的相似程度。这些方法的共同目标是学习一个好的距离度量,以便同类数据对之间的距离缩小,而异类数据对之间的距离尽可能地扩大。不同于一般基于特征向量的分类问题,时间序列数据往往具有高维度、属性之间先后次序不可变等特点。
针对欧氏距离(ED)和DTW相似性度量方法的不足,借鉴SNN在模式识别等领域的良好表现,提出一种基于SNN的时间序列相似性度量学习方法,从标签信息和序列样本中学习其数据之间相似性关系的知识并形成度量模型,时间序列的时间顺序则在输入变量的排序中体现,SNN网络隐含层输出每个时间序列新的矢量表示,计算新矢量之间的距离度量作为网络的输出,该输出作为原时间序列之间的相似度S=SNN(Xi,Xj)。本文依据该相似度结合近邻分类器(K-Nearest Neighbor, KNN)[13]对时间序列进行分类,验证了该方法的优势。
1 相关理论基础
区别于ED、DTW依赖于输入空间中有意义且可计算的距离度量,SNN模型将度量学习的思想与神经网络的非线性表示嵌入结合起来,以监督的方式从数据中学习数据之间的相似度的特定表达,经过SNN子网络映射到新的度量空间中。
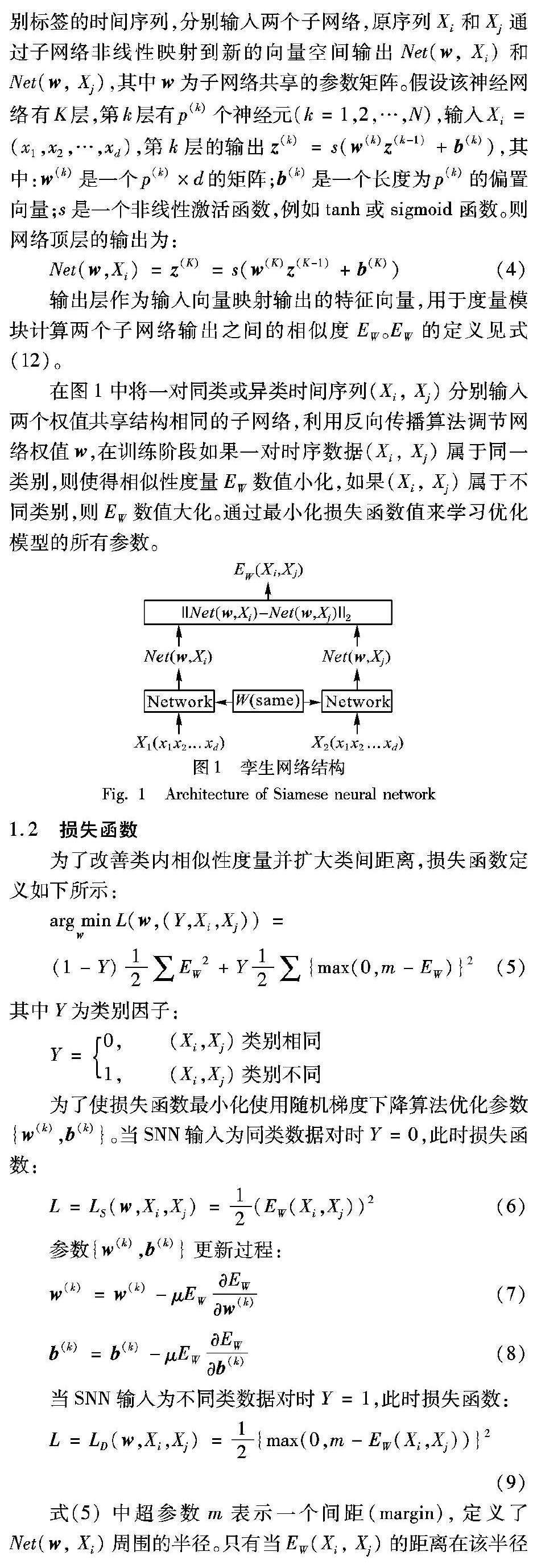
1.1 SNN网络一般结构
输出层作为输入向量映射输出的特征向量,用于度量模块计算两个子网络输出之间的相似度EW。EW的定义见式(12)。
在图1中将一对同类或异类时间序列(Xi, Xj)分别输入两个权值共享结构相同的子网络,利用反向传播算法调节网络权值w,在训练阶段如果一对时序数据(Xi, Xj)属于同一类别,则使得相似性度量EW数值小化,如果(Xi, Xj)属于不同类别,则EW数值大化。通过最小化损失函数值来学习优化模型的所有参数。
1.3 度量函数
2 相似性度量实验及分析
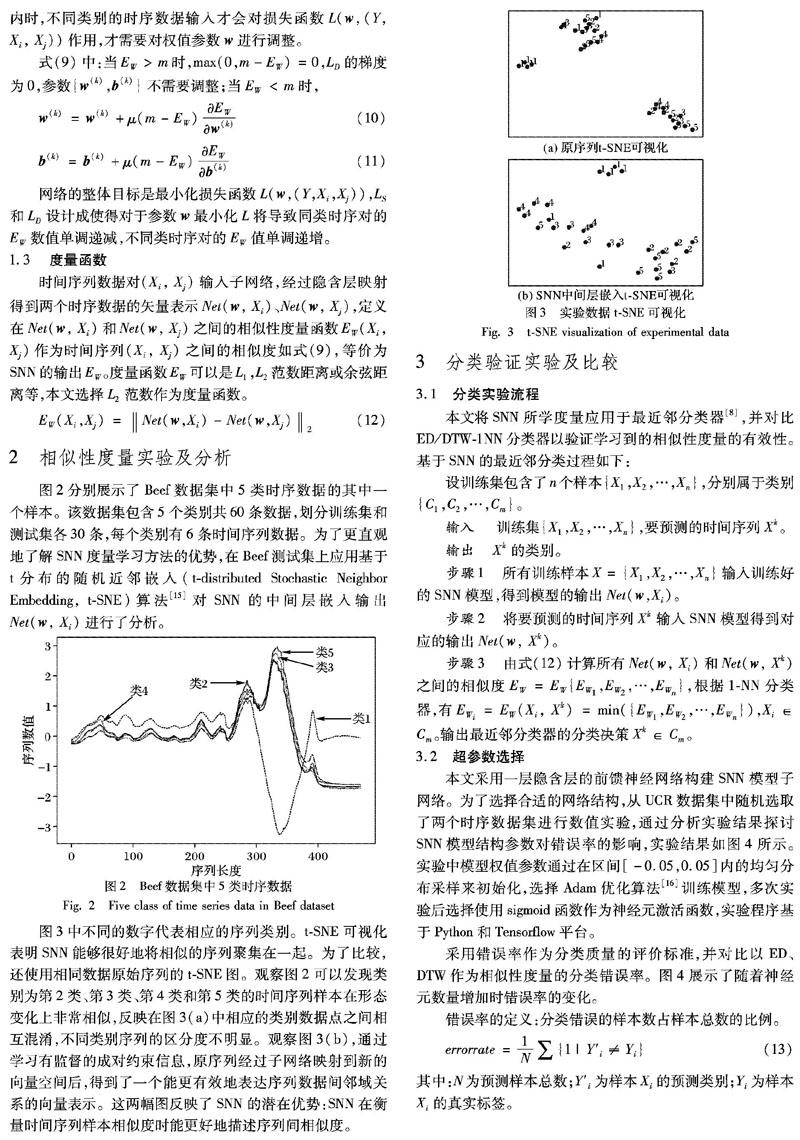
图2分别展示了Beef数据集中5类时序数据的其中一个样本。该数据集包含5个类别共60条数据,划分训练集和测试集各30条,每个类别有6条时间序列数据。为了更直观地了解SNN度量学习方法的优势,在Beef测试集上应用基于t分布的随机近邻嵌入(t-distributed Stochastic Neighbor Embedding, t-SNE)算法[15]对SNN的中间层嵌入输出Net(w, Xi)进行了分析。
图3中不同的数字代表相应的序列类别。t-SNE可视化表明SNN能够很好地将相似的序列聚集在一起。为了比较,还使用相同数据原始序列的t-SNE图。观察图2可以发现类别为第2类、第3类、第4类和第5类的时间序列样本在形态变化上非常相似,反映在图3(a)中相应的类别数据点之间相互混淆,不同类别序列的区分度不明显。观察图3(b),通过学习有监督的成对约束信息,原序列经过子网络映射到新的向量空间后,得到了一个能更有效地表达序列数据间邻域关系的向量表示。这两幅图反映了SNN的潜在优势:SNN在衡量时间序列样本相似度时能更好地描述序列间相似度。
3 分类验证实验及比较
3.1 分类实验流程
3.2 超参数选择
本文采用一层隐含层的前馈神经网络构建SNN模型子网络。为了选择合适的网络结構,从UCR数据集中随机选取了两个时序数据集进行数值实验,通过分析实验结果探讨SNN模型结构参数对错误率的影响,实验结果如图4所示。实验中模型权值参数通过在区间[-0.05,0.05]内的均匀分布采样来初始化,选择Adam优化算法[16]训练模型,多次实验后选择使用sigmoid函数作为神经元激活函数,实验程序基于Python和Tensorflow平台。
采用错误率作为分类质量的评价标准,并对比以ED、DTW作为相似性度量的分类错误率。图4展示了随着神经元数量增加时错误率的变化。
错误率的定义:分类错误的样本数占样本总数的比例。
在相同参数下进行五次实验取平均值为实验结果。图4的实验结果显示,随着隐层神经元个数的增加分类错误率随之明显下降,较多的神经元有利于学习数据的特征表示,但存在一定的饱和性。
3.3 数值实验
将SNN模型结合1-NN分类器与主流的ED/DTW-1NN分类器相比较,部分实验结果引用自文献[17]。在UCR公共数据集上选取22个数据集完成对比实验,数据在获取时已划分好训练集与测试集,所有错误率都在测试集上计算。表1展示了所对比的三种相似度度量方法在22个公共数据集上的分类错误率,加粗的数值表示所有对比方法中最优的结果。其中SNN-1NN的结果是五次实验平均值。
从表1展示的实验结果来看,总体上分类错误率ED-1NN>DTW-1NN>SNN-1NN,三种分类器在22个数据集上的平均分类错误率分别是0.251、0.236、0.191, SNN-1NN具有明显的优势,其分类错误率在其中12个数据集上显著低于主流的DTW-1NN分类器,相对于ED-1NN在其中19个数据集上表现明显占优,在其余数据集上分类错误率相近。若对于不同数据集测试选择更合适的调整网络结构则可进一步降低SNN-1NN的分类错误率。
4 结语
本文针对目前时间序列相似性度量方法的优点和不足,借鉴度量学习和神经网络模型相结合的思想,提出了一种基于SNN模型的度量学习方法,可提高對时间序列数据挖掘的性能。将该方法结合最近邻算法在UCR公共数据集上进行分类实验,结果表明,与ED/DTW-1NN相比在分类质量总体上有明显的提升。基于DTW-1NN的模型在部分数据上表现仍然优于SNN-1NN分类方法,但在分类过程的相似度计算复杂度和速度上,SNN优于DTW。在之后的工作中,可对本文方法作进一步的研究,针对数据集特点探讨更加合理的网络结构,改进模型的学习算法扩展到时间序列数据挖掘聚类等任务中的应用。
参考文献(References)
[1] 崔婧, 赵秀娟, 宋吟秋.中日股价序列相似性的比较分析[J]. 系统工程理论与实践, 2009, 29(12): 125-133. (CUI J, ZHAO X J, SONG Y Q. Similarity analysis on China's and Japan's security price series[J]. Systems Engineering — Theory and Practice, 2009, 29(12): 125-133.)
[2] SIVARAKS H, RATANAMAHATANA C A. Robust and accurate anomaly detection in ECG artifacts using time series motif discovery[J]. Computational and Mathematical Methods in Medicine, 2015, 2015: 453214.
[3] 陈海燕, 刘晨晖, 孙博.时间序列数据挖掘的相似性度量综述[J]. 控制与决策, 2017, 32(1): 1-11. (CHEN H Y, LIU C H, SUN B. Survey on similarity measurement of time series data mining[J]. Control and Decision, 2017, 32(1): 1-11.)
[4] BERNDT D J, CLIFFORD J. Using dynamic time warping to find patterns in time series[C]// AAAIWS 1994: Proceedings of the 3rd International Conference on Knowledge Discovery and Data Mining. Menlo Park, CA: AAAI Press, 1994, 10(16): 359-370.
[5] FALOUTSOS C, RANGANATHAN M, MANOLOPOULOS Y. Fast subsequence matching in time-series databases[C]// SIGMOD 1994: Proceedings of the 1994 ACM SIGMOD International Conference on Management of Data. New York: ACM, 1994: 419-429.
[6] 李海林, 梁叶, 王少春.时间序列数据挖掘中的动态时间弯曲研究综述[J]. 控制与决策, 2018, 33(8): 1345-1353. (LI H L, LIANG Y, WANG S C. Review on dynamic time warping in time series data mining[J]. Control and Decision, 2018, 33(8): 1345-1353.)
[7] 沈媛媛, 严严, 王菡子.有监督的距离度量学习算法研究进展[J]. 自动化学报, 2014, 40(12): 2673-2686. (SHEN Y Y, YAN Y, WANG H Z. Recent advances on supervised distance metric learning algorithms[J]. Acta Automatica Sinica, 2014, 40(12): 2673-2686.)
[8] BROMLEY J, GUYON I, LECUN Y, et al. Signature verification using a “siamese” time delay neural network[C]// NIPS 1993: Proceedings of the 6th International Conference on Neural Information Processing Systems. San Francisco, CA: Morgan Kaufmann Publishers, 1994: 737-744.
[9] CHOPRA S, HADSELL R, LECUN Y. Learning a similarity metric discriminatively, with application to face verification[C]// CVPR 2005: Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2005: 539-546.
[10] WANG F Q, ZUO W M, LIN L, et al. Joint learning of single-image and cross-image representations for person re-identification[C]// CVPR 2016: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2016: 1288-1296.
[11] DONG Y, ZHEN L, SHENG L, et al. Deep metric learning for person re-identification[C]// Proceedings of the 2014 22nd International Conference on Pattern Recognition. Piscataway, NJ: IEEE, 2014: 34-39.
[12] HUANG P S, HE X D, GAO J F, et al. Learning deep structured semantic models for Web search using clickthrough data[C]// Proceedings of the 22nd ACM International Conference on Conference on Information & Knowledge Management. New York: ACM, 2013: 2333-2338.
[13] COVER T, HART P. Nearest neighbor pattern classification[J]. IEEE Transactions on Information Theory, 1967, 13(1): 21-27.
[14] BATISTA G E, WANG X, KEOGH E J. A complexity-invariant distance measure for time series[EB/OL]. [2018-05-10]. https://epubs.siam.org/doi/pdf/10.1137/1.9781611972818.60.
[15] MAATEN L, HINTON G. Visualizing data using t-SNE[J]. Journal of Machine Learning Research, 2008, 9: 2579-2605.
[16] KINGMA D P, BA J. Adam: a method for stochastic optimization[EB/OL]. [2018-05-10]. https://arxiv.org/pdf/1412.6980.
[17] CHEN Y, KEOGH E, HU B, et al. The UCR time series classification archive [DB/OL]. [2018-05-10]. http://www.cs.ucr.edu/~eamonn/time_series_data/.
猜你喜欢
中国教育信息化·高教职教(2022年4期)2022-05-13
计算技术与自动化(2022年1期)2022-04-15
计算技术与自动化(2021年2期)2021-11-10
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
软件(2017年6期)2017-09-23
电子技术与软件工程(2016年24期)2017-02-23
时代金融(2016年27期)2016-11-25
电脑知识与技术(2016年26期)2016-11-25
商(2016年32期)2016-11-24
软件工程(2016年8期)2016-10-25
