
混合的密度峰值聚类算法
2019-08-01 01:57王军周凯程勇
计算机应用 2019年2期
王军 周凯 程勇


摘 要:密度峰值聚类(DP)算法是一种新的基于密度的聚类算法,当它处理的单个聚类包含多个密度峰值时,会将每个不同密度峰值视为潜在聚类中心,以致难以在数据集中确定正确数量聚类,为此,提出一种混合的密度峰值聚类算法C-DP。首先,以密度峰值点为初始聚类中心将数据集划分为子簇;然后,借鉴代表点层次聚类算法(CURE),从子簇中选取分散的代表点,将拥有最小距离的代表点对的类进行合并,引入参数收缩因子以控制类的形状。仿真实验结果表明,在4个合成数据集上C-DP算法比DP算法聚类效果更好;在真实数据集上的Rand Index 指标对比表明,在数据集S1上,C-DP算法比DP算法性能提高了2.32%,在数据集4k2_far上,C-DP算法比DP算法性能提高了1.13%。由此可见,C-DP算法在单个类簇中包含多密度峰值的数据集中能提高聚类的准确性。
关键词:密度峰值;层次聚类;类合并;代表点;收缩因子
中图分类号: TP301.6
文献标志码:A
Abstract: As a new density-based clustering algorithm, clustering by fast search and find of Density Peaks (DP) algorithm regards each density peak as a potential clustering center when dealing with a single cluster with multiple density peaks, therefore it is difficult to determine the correct number of clusters in the data set. To solve this problem, a mixed density peak clustering algorithm namely C-DP was proposed. Firstly, the density peak points were considered as the initial clustering centers and the dataset was divided into sub-clusters. Then, learned from the Clustering Using Representatives algorithm (CURE), the scattered representative points were selected from the sub-clusters, the clusters of the representative point pairs with the smallest distance were merged, and a parameter contraction factor was introduced to control the shape of the clusters. The experimental results show that the C-DP algorithm has better clustering effect than the DP algorithm on four synthetic datasets. The comparison of the Rand Index indicator on real datasets shows that on the dataset S1 and 4k2_far, the performance of C-DP is 2.32% and 1.13% higher than that of the DP. It can be seen that the C-DP algorithm improves the accuracy of clustering when datasets contain multiple density peaks in a single cluster.
Key words: density peak; hierarchical clustering; class merging; representative point; contraction factor
0 引言
聚類是将数据组织到不同的类中以寻找数据的固有隐藏模式的无监督学习方法[1]。聚类用途广泛,可以应用于图像处理[2]、模式识别[3]、生物信息学[4]、微阵列分析[5]和社交网络[6]等各个领域,聚类算法可以将更多类似的数据聚集到同一个类中,而不同的数据被组织到不同的类中,在数据挖掘领域应用广泛[7]。现如今已经提出了许多基于不同特征的聚类算法,并且可以进一步分类为基于划分的聚类算法、基于密度的聚类算法、基于模型的聚类算法、基于层次的聚类算法和基于网格的聚类算法[8]。
其中基于密度的聚类方法在研究人员中广受欢迎。即使存在噪声,基于密度的聚类算法也可以在大数据集中找到任意形状的聚类[9]。基于密度的噪声应用空间聚类 (Density-Based Spatial Clustering of Applications with Noise,DBSCAN)算法[10]是一种先进的基于密度的聚类算法,它利用关于数据的最小邻域来发现任意形状的聚类;但是,DBSCAN的有效性受到输入参数选择的影响[11]。
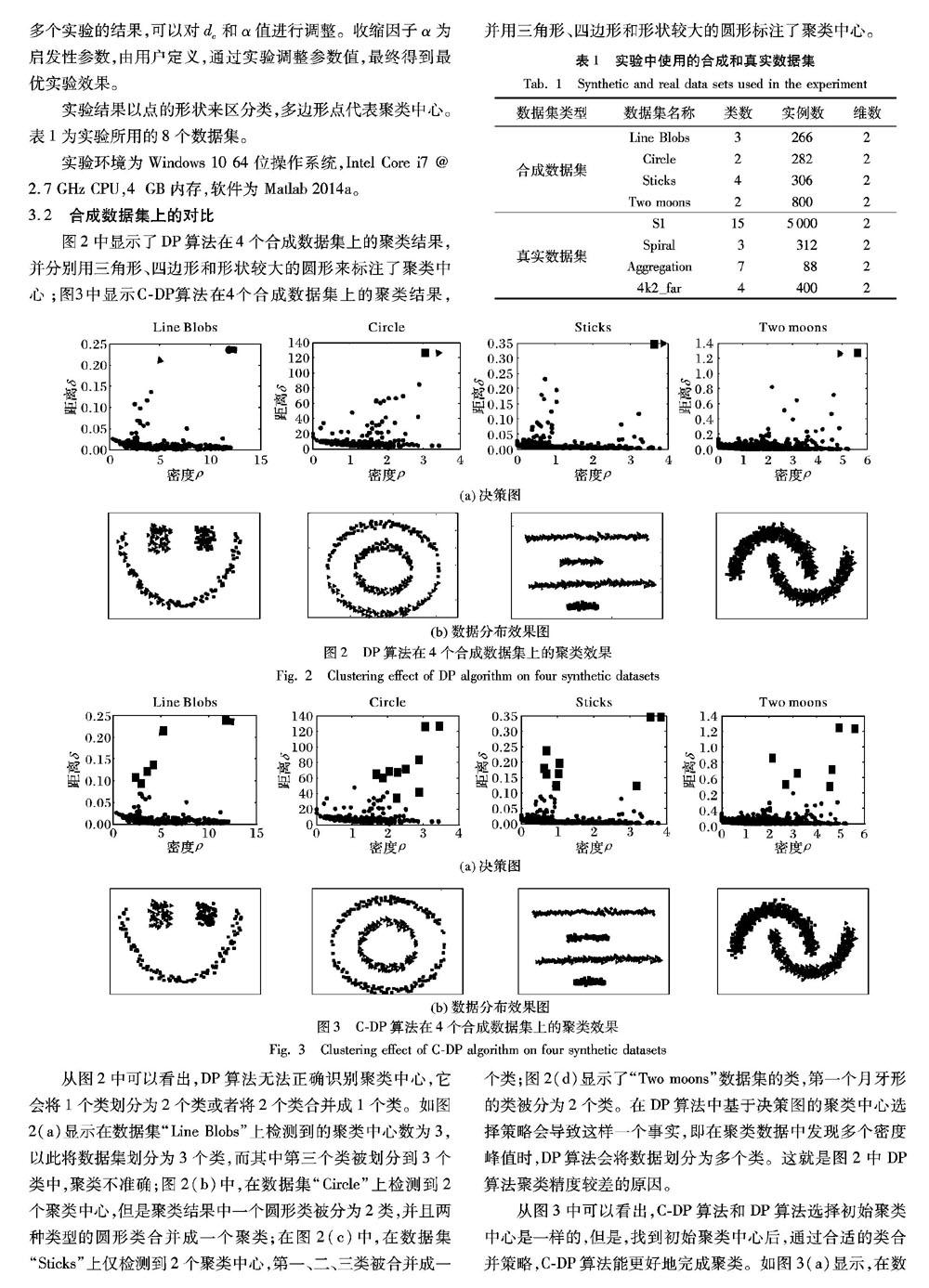
文献[12]提出了一种密度峰值聚类(clustering by fast search and find of Density Peaks, DP)算法。DP算法以密度峰值来选择聚类中心,运行高效,并且人工干预较少。DP算法使用了决策图(Decision Graph)的启发式方法来选择聚类中心。虽然DP算法简单高效,但其劣势和难点不容小觑: 对于单个数据集中可能包含多个密度峰值,而在DP算法中将不同的密度峰值作为潜在的聚类中心,这就将原本一个类分成多个类簇,导致聚类效果不佳。
针对这一问题,本文提出了一种新的基于密度的聚类算法C-DP(mixed Density Peaks clustering algorithm):先用DP算法对数据集进行初始的聚类,找到初始聚类中心;然后借鉴代表点层次聚类(Clustering Using REpresentatives, CURE)算法從初始聚类中选取类的代表点,对具有最小距离的代表点对的类进行合并,以提高聚类质量。仿真实验结果表明,该算法在合成数据集和真实数据集上可以识别任意形状的类簇。
1 相关工作
基于密度的聚类算法对孤立点和噪声不敏感,可以处理具有不规则形状的数据并发现具有任意形状的聚类,聚类效果较好[13]。
文献[12]提出的DP算法利用数据集的密度峰值来找到任意形状数据集的类中心,并高效进行样本点归类和噪声剔除,处理大规模数据集的性能良好。
DP算法属于密度聚类算法中性能较好的,但仍有改善空间,研究人员已经针对DP算法进行了大量的优化改进工作。文献[14]中结合DP算法和变色龙(ChAmeleon,CA)算法,提出了一种扩展的快速搜索聚类算法(Extended fast search clustering algorithm: widely density clusters, no Density Peaks,E-DP),解决了DP算法无法处理一个类中有多个密度峰值点的问题;虽然与原DP算法相比,该改进算法的时间复杂度并未增加,但它的运算时间更长。文献[15]提出了一种基于支持向量机(Support Vector Machine,SVM)的新型合并策略算法。该策略首先利用SVM计算DP算法聚类后每两个类之间的反馈值;然后,以反馈值为依据合并聚类,以递归方式获得准确的聚类结果。该算法的时间复杂度较高。文献[16]提出了一种用于自适应选择聚类中心的通过快速搜索和查找密度峰值的模糊聚类 (Fuzzy Clustering by Fast Search and Find of Density Peaks, Fuzzy-CFSFDP) 算法,它在DP算法基础上通过使用模糊规则来确定聚类中心点,能提高类中心点选取的准确率,从而提升算法的性能;然而该算法的实现条件是数据集中的每个类有且仅有一个密度峰值,算法具有局限性。文献[17]提出了一种具有新的分配策略的领导密度峰值聚类 (Leading clustering with Density peaks, L-DP)算法,在原有DP算法获得聚类中心后,运用一种改进的领导聚类方法(Leader clustering)作为点分配策略,以此获得正确的聚类;然而,该方法没有考虑一个类中心有多个密度峰值的情况,而且该方法假设聚类中心更靠近高密度区域,实际上,聚类中心也可能靠近低密度区域。
4 结语
针对数据集中单个聚类中包含多个密度峰值,DP算法无法得到准确聚类结果的问题,本文提出了一种混合的密度峰值聚类算法C-DP:受CURE的启发,在聚类过程中先用DP算法得到初始聚类中心进行初始聚类,然后从初始类中选取类的代表点,并引入收缩因子α,然后根据收缩因子来移动它们,可以很好地控制类的形状。以最小距离度量方法作为类间相似性度量标准,不同类之间有最近距离代表点对的两个类被合并。实验结果表明,对于单个聚类包含多个密度峰值的数据集,C-DP算法与原始的DP算法相比可以更准确地进行聚类,而对于一些只有一个密度峰值的数据集,C-DP算法和原DP算法都能进行很好的聚类。
然而,C-DP算法与原始的DP算法,在获取数据集的聚类中心时是由用户选择的,这很难准确判定聚类中心。 以后的工作是将C-DP算法扩展为完全自适应方法。
参考文献:
[1] CASSISI C, FERRO A, GIUGNO R, et al. Enhancing density-based clustering: Parameter reduction and outlier detection [J]. Information Systems, 2013, 38(3): 317-330.
[2] LI K, ZHU C Y, LYU Q, et al. Personalized multi-modality image management and search for mobile devices [J]. Personal and Ubiquitous Computing, 2013, 17(8): 1817-1834.
[3] AHN C-S, OH S-Y. Robust vocabulary recognition clustering model using an average estimator least mean square filter in noisy environments [J]. Personal and Ubiquitous Computing, 2014, 18(6): 1295-1301.
[4] NICOVICH P R, TABARIN T, STIEGLER J, et al. Analysis of nanoscale protein clustering with quantitative localization microscopy [J]. Biophysical Journal, 2015, 108(2): 475a.
[5] YEGANOVA L, KIM W, KIM S, et al. Retro: concept-based clustering of biomedical topical sets [J]. Bioinformatics, 2014, 30(22): 3240-3248.
[6] CHANG M-S, CHEN L-H, HUNG L-J, et al. Exact algorithms for problems related to the densest k-set problem [J]. Information Processing Letters, 2014, 114(9): 510-513.
[7] JAIN A K, MURTY M N, FLYNN P J. Data clustering: a review [J]. ACM Computing Surveys,1999, 31 (3): 264-323.
[8] 周涛,陆惠玲.数据挖掘中聚类算法研究进展[J].计算机工程与应用,2012,48(12):100-111. (ZHOU T, LU H L. Research progress of clustering algorithms in data mining [J]. Computer Engineering and Applications, 2012, 48(12): 100-111.)
[9] GENG Y-A, LI Q, ZHENG R, et al. RECOME:a new density-based clustering algorithm using relative KNN kernel density [J]. Information Sciences, 2016, 436/437: 13-30.
[10] 张丽杰.具有稳定饱和度的DBSCAN算法[J].计算机应用研究,2014,31(7):1972-1975. (ZHANG L J. Stable saturation density of DBSCAN algorithm [J]. Applications Research of Computers, 2014, 31(7): 1972-1975.)
[11] ZHOU A Y, ZHOU S G, CAO J, et al. Approaches for scaling DBSCAN algorithm to large spatial databases [J]. Journal of Computer Science and Technology, 2000, 15(6): 509-526.
[12] RODRIGUEZ A, LAIO A. Clustering by fast search and find of density peaks [J]. Science, 2014, 344(6191): 1492-1496.
[13] XU J, WANG G, DENG W. DenPEHC: density peak based efficient hierarchical clustering [J]. Information Sciences, 2016, 373: 200-218.
[14] ZHANG W, LI J. Extended fast search clustering algorithm: widely density clusters, no density peaks [EB/OL]. [2018-04-06]. https://arxiv.org/ftp/arxiv/papers/1505/1505.05610.pdf.
[15]XU X, DING S, XU H, et al. A feasible density peaks clustering algorithm with a merging strategy [J/OL]. Soft Computing, 2018 [2018-03-06]. https://doi.org/10.1007/s00500-018-3183-0.
[16] MEHMOOD R, BIE R, DAWOOD H, et al. Fuzzy clustering by fast search and find of density peaks [C]// Proceedings of the 2015 International Conference on Identification, Information, and Knowledge in the Internet of Things. Washington, DC: IEEE Computer Society, 2015: 258-261.
[17] DU M, DING S. L-DP: A hybrid density peaks clustering method [C]// DMBD 2017:Proceedings of the 2017 International Conference on Data Mining and Big Data, LNCS 10387. Cham: Springer, 2017: 74-80.
[18] 沈潔,赵雷,杨季文,等.一种基于划分的层次聚类算法[J].计算机工程与应用,2007,43(31): 175-177. (SHEN J, ZHAO L, YANG J W, et al. Hierarchical clustering algorithm based on partition [J]. Computer Engineering and Applications, 2007,43(31):175-177.)
[19] WIWIE C, BAUMBACH J, RTTGER R. Comparing the performance of biomedical clustering methods [J]. Nature Methods, 2015, 12: 1033-1038.
