
基于AlexNet模型的佤语语谱图识别
2019-07-31 09:28:24解雪琴和丽华潘文林
云南民族大学学报(自然科学版) 2019年4期
王 翠,王 璐,解雪琴,和丽华,潘文林
(云南民族大学 数学与计算机科学学院,云南 昆明 650500)
语言和文字是一个民族的文化最重要的组成部分,在文化快速融合的时代,佤族的语言和文字面临消亡的处境.佤族是跨境而居的民族,而佤语作为佤族唯一的沟通交流工具,佤语语音的识别研究对国家安全和跨边境文化的交流有着重要的意义.中国语言资源保护工程(“语保工程”)录制大量的少数民族语音语料,佤语虽作为“语保工程”的一部分,但其国际音标人工标注信息并没有达到可信可用的程度,原因在于精确的标注不仅困难而且昂贵.本文选用了“语保工程”中的佤语作为研究对象,针对标注信息中出现的问题,最终实现佤语国际音标的自动标注及纠错,该任务分2步完成:第1步实现佤语识别,第2步基于识别结果进行国际音标自动标注.本文为研究目标的第1步.
佤语的主流研究方向有2个:语音学、传统的深度学习.语音学对佤语语言本身的语言结构进行研究[1-4]:音系归纳整理和语音演变探究,从宏观上为佤语的语音研究奠定了坚实的基础,但是如何应用科学实验的手段对佤语进行识别研究的工作很少.传统深度学习对佤语识别研究工作主要有:傅美君基于遗传算法的支持向量机对佤语进行分类[5-6],测试集在佤语音节分类的预测准确率达到84.83%.佤语音节分类基于多核支持向量机对免疫遗传进行优化,显著的增强音节分类的准确性.佤语语言动态共振峰提取自适应变分模式[7](AVWD)分解来研究佤语的共振峰特性与Praat软件获得的频率相比得到86%的正确率.陈绍雄[8-9]基于HTK的佤语特定人和非特定人的孤立词准确率达到92%.主要应用传统的深度学习方法对佤语进行识别研究,但实验结果的识别率还没有达到可用的程度.
近年来,主流语言应用深度学习的语音识别产品已较为成熟:百度使用端到端的深度学习方法高效的识别英语或普通话[10];谷歌使用最先进的序列到序列语音识别模型,使词错误率(WER)降到5.6%[11].而对少数民族语言语音识别的研究还较少,主要从语音信号和语谱图两个角度切入.语音信号,主要的研究方法有隐马尔科夫模型、深度置信网络等.蔡琴[12]建立了维吾尔语的连续数字语音声学模型,对维吾尔语连续数字短语识别率达到80%,词识别率达到91.19%.胡文君[13]分别训练了5种不同的声学模型: Monophone、Triphone1、Triphone2、O-SGMM、G-DNN,实验结果表明,随着语料量的增加,系统鲁棒性提高.语谱图,宋洋[14]针对维吾尔语音素的语谱图像提取二值和边缘特征,建立基于数学形态学分析的概率函数,应用近似模式识别计算音素特征矩阵的相似度,在单音素环境下识别率达77.5%,在连续语流中音素识别率达64%;最后,在神经网络中对音素的语音学特征进行分类,利用混沌矩阵给出分类的正确率约70%.由于主流语言应用深度学习的语音识别产品已较为成熟,然而少数民族语音识别采用传统的深度学习方法的识别率并没达到可用的程度,所以本文采用深度学习方法对佤语语音识别进行研究提高可用性.基于卷积神经网络在处理二维像素网格[15-16]、语义分类中的优势[17]、本文数据集的大小、网络参数量等参数的综合考量,选择运用卷积网络的AlexNet模型对佤语语谱图识别.
1 深度学习理论
卷积神经网络(convolutional neural network, CNN)在处理图片上有一定的优势,并且可以用来处理具有类似网络结构的数据.CNN的稀疏交互、参数共享、等变表示等特性,可以有效降低网络的复杂度,减少训练参数的数目.对数据的平移、扭曲、缩放具有一定程度的不变性,易于网络结构的训练和优化,使模型具有强鲁棒性、强容错能力.卷积神经网络前端由多个卷积层、汇聚层组成,可以看作网络的特征提取层.后端由多个全连接层组成,可以看作模式识别层.
卷积层用于提取图片的特征,每层数据之间的正向传播遵循非线性函数,输入变量记为x=(x1,x2, …,xn),层之间的连接权重记为w=(w1,w2, …,wn),偏置项记为b,则正向传播函数为y=wx+b,因RELU激活函数具有单侧抑制、相对宽阔的兴奋边界、稀疏激活性等优势,所以卷积层和全连接层皆选用RELU激活函数,激活后的输出结果记为Y=RELU(y).RELU激活函数如(式1)所示.
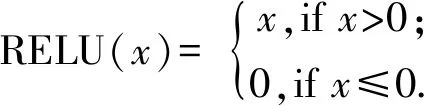
(1)
汇聚层主要对卷积层得到的特征进行选择,由此不仅降低特征的数量而且减少参数的数量.最大汇聚层(max pooling)如(式2)所示,一般取汇聚区域的最大值.
(2)
对于多分类问题,损失函数采用交叉熵(cross entropy)损失,以此让预测分布q逼近真实分布p,如(式3)所示.
H(p,q)=-∑p(x)logq(x) .
(3)
反向传播选用随机梯度下降法(SGD),其中梯度估计可以表示成(式4)所示:
(4)
式中,m表示样本个数,x(i)表示第i个样本,y(i)表示x(i)对应目标,为学习率.
输出层的分类选用Softmax函数,如式5所示.
(5)
2 AlexNet模型
AlexNet[18-19]网络结构如表1所示,整个网络有8个需要训练参数的层(不包括汇聚层和局部响应归一化层——LRN层),前 5层为卷积层,其中3个卷积层后面连接最大汇聚层,后 3 层为全连接层.卷积层和汇聚层可以看作是从一般抽象到高级抽象的特征提取层,全连接层可以看作特征映射层,因此整个AlexNet表示为嵌套的层次概念体系.AlexNex最后一层是有1 860类输出的Softmax层用作分类.LRN层出现在第1个及第2个卷积层后,而最大汇聚层出现在两个LRN层及最后一个卷积层后.在这8个网络层每一层的后面都应用ReLU激活函数.AlexNet模型流程如表1所示.

表1 Alxnet模型流程图
续表1

结构详细参数卷积层4num(kernel) = 384, kernel = 3×3,strides = 1,channel = 384,padding=SAME卷积层5num(kernel) = 256, kernel = 3×3,strides = 1,channel = 384,padding=SAMELRN 3—汇聚层3Max pooling,ksize = 3×3,strides = 2,padding=VALID全连接层outputNum = 4096全连接层outputNum = 4096全连接层outputNum = 1000
表1中,kernel:卷积核大小,channel:通道数,num(kernel):卷积核个数,strides:移动步长,padding:采样方式,ksize:池化核大小,outputNum:全连接输出神经元个数.LRN,即局部响应归一化层,LRN函数类似DROPOUT和数据增强作为RELU激励之后防止数据过拟合而提出的一种处理方法.
3 实验
AlexNet用于佤语语谱图识别流程,如图1所示,具体步骤如下:

1) 选用佤语语音数据集作为研究对象,数据集中总计37 200条佤语孤立词语音,37 200 =((2(女) + 2(男)) × 1 860(类)× 5(遍)).
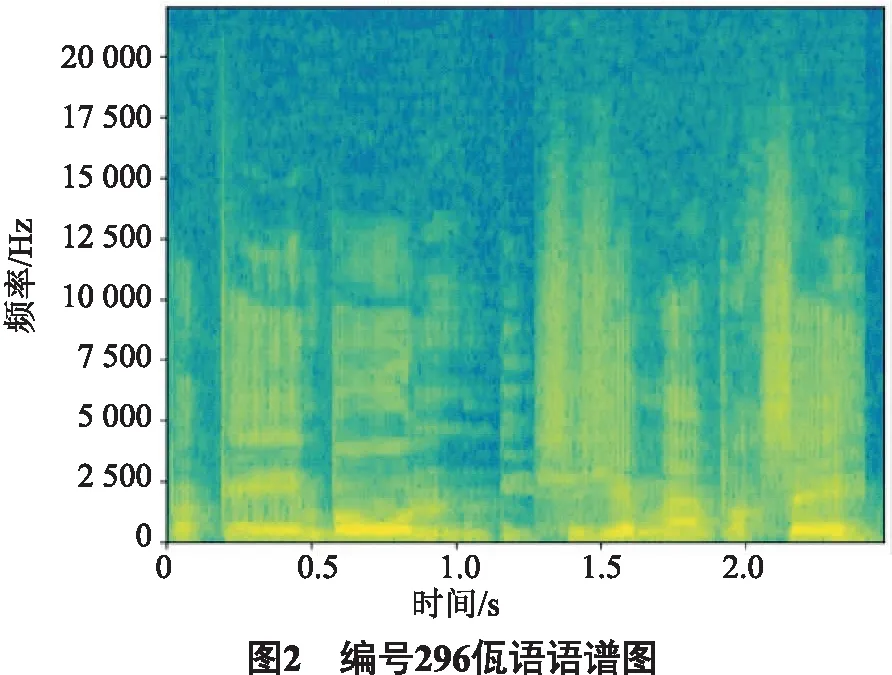
2) 语谱图可同时反应语音信号的时频域三维信息(时间、频率、能量),且宽带语谱图具有较好的时间分辨率,但频率分辨率较低,能给出语音的共振峰频率及清辅音的能量汇集区.计算37 200条语音信号的彩色宽带语谱图,语谱图大小为640×480×3.以编号296佤语语音信号为例,其语谱图如图2所示.图2中横轴表示时间,纵轴表示频率,颜色的深浅表示能量.
3) 以佤语孤立词类别种类数作为标签,并对标签采用one-hot编码.
4) 选用数据集中的60%作为训练集,剩余的40%作为测试集,网络每训练一次,随机从训练集中抓取一个批次的数据做交叉验证.
5) 将每个语谱图及其对应标签转换成tensorflow可读的文件形式(.tfrecords).
6) AlexNet模型参数设置:批次数150;网络迭代次数2 200,每迭代100次显示一次学习率及交叉验证率结果;为了有效的训练深层神经网络,采用学习率衰减,初始学习率α0=0.003,在第t(步长为500)次迭代时的学习率如式(6)所示,网络输出神经元个数1 860,
(6)
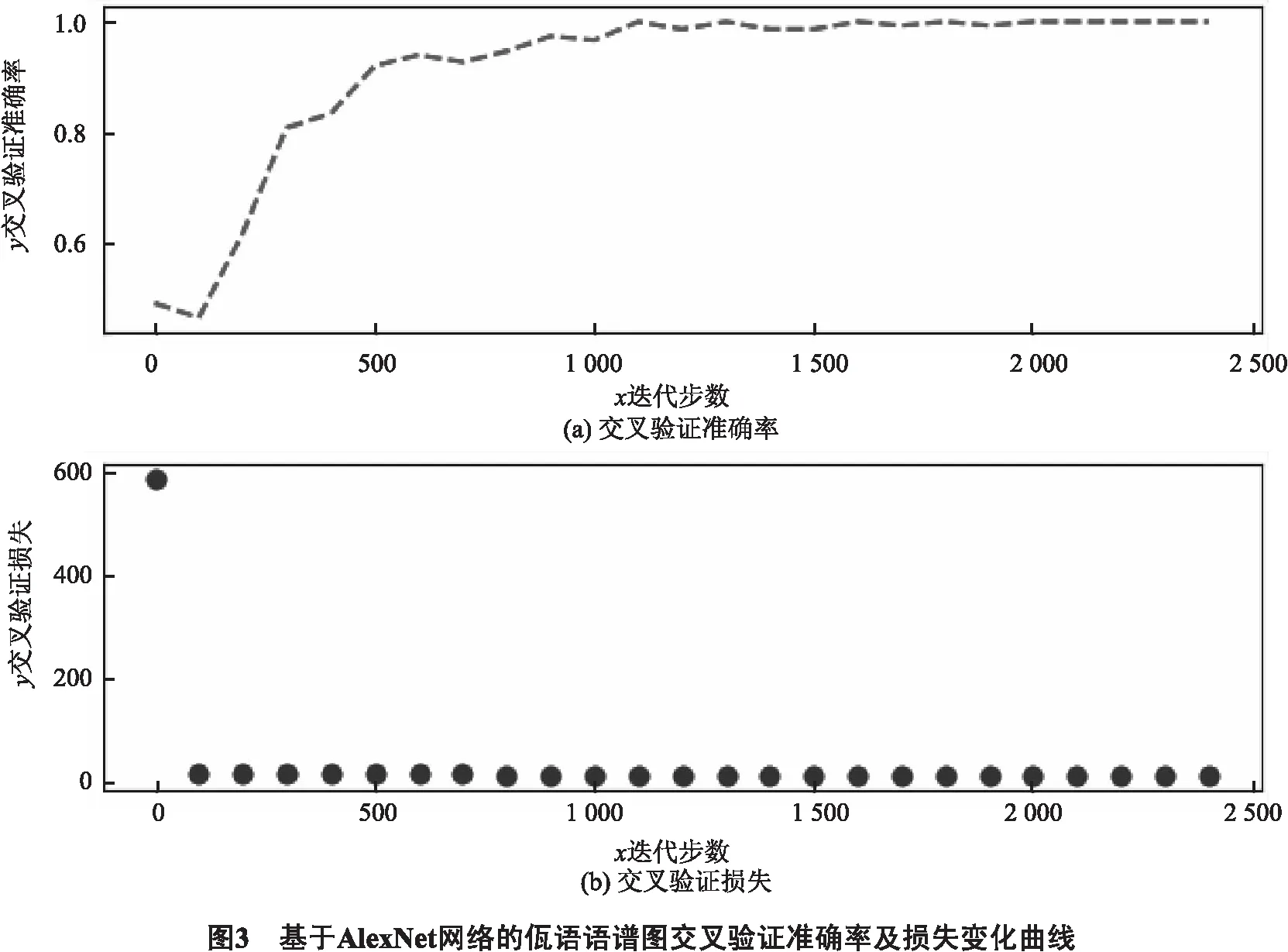
7) 实验结果如图3所示,为了直观的显示佤语语谱图识别过程中迭代次数、交叉验证准确率和交叉验证损失之间的变化关系,将实验结果绘制成曲线图.图中横坐标表示迭代次数,图3(a)纵坐标表示交叉验证准确率,图3(b)纵坐标表示交叉损失.从图中可以发现,随着迭代次数的增加,交叉验证准确率逐渐提升,交叉验证损失逐渐降低,当迭代次数达到1 200时,交叉验证准确率波动范围<1%,基本趋于平稳状态.基于该模型最终的实验准确率可以达到97%.实验结果表明,基于语谱图的语音识别可以有效避免清辅音对实验的干扰,系统鲁棒性强,最终的训练准确率为99.33%,测试准确率为96%.
4 结语
语谱图已经将语音的所有特征表示在图片上,无需考虑清、浊音的影响.本文使用傅里叶变换将图片转换为对应的语谱图.由于成熟的AlexNet模型处理图片具有一定的优势,所以选用AlexNet深度模型用于佤语语谱图识别.该方法不仅可以有效避免语音信号中清辅音对识别结果的影响,还可通过表示学习的方式得到图片更抽象的特征参数.本文研究主要针对语谱图的分类问题,但对佤语的语音识别还未真正解决.在接下的工作中,本课题组会针对以上问题,对模型作相应更改,使用端到端模型实现佤语语音识别.
猜你喜欢
计算机工程(2020年3期)2020-03-19 12:24:50
小型微型计算机系统(2019年9期)2019-09-09 03:38:42
初中生世界·八年级(2019年6期)2019-08-13 18:41:18
中国听力语言康复科学杂志(2019年3期)2019-06-24 09:51:20
吉林大学学报(信息科学版)(2018年3期)2018-06-13 10:36:38
中国交通信息化(2018年3期)2018-06-13 03:27:58
东北师大学报(自然科学版)(2017年2期)2017-06-13 10:43:55
小学生导刊(低年级)(2016年6期)2016-07-02 22:17:33
中国交通信息化(2016年2期)2016-06-06 07:28:02
计算机工程(2015年8期)2015-07-03 12:19:54
