
基于搜索空间大小的动态变异算子差分进化算法①
2019-07-23 02:08苗晓锋刘志伟
计算机系统应用 2019年6期
苗晓锋,刘志伟
1(榆林职业技术学院神木校区 信息中心,神木 719300)
2(西北工业大学 信息中心,西安 710072)
差分进化(Differental Evolution,DE)是由Price 和Storn[1]首先提出的一种简单高效的基于群体的随机搜索算法.作为遗传算法的一个分支,DE 的性能在很大程度上受到其控制参数(收缩因子和杂交概率)的影响[2,3].选择不同的策略和控制参数会导致不同的算法性能,尤其会在很大程度上决定最终所能获得最优解的求解效率和质量[4].而选择适当的参数值是一个与待求解问题自身特征相关的问题,通常由使用者根据主观经验决定.许多研究都尝试更好地解决这个问题,例如自适应控制参数DE(SADE)[4],模糊DE(FADE)[5],自适应DE(SaDE)[6]和相邻搜索自适应DE(SaNSDE)[7]等改进DE 算法.
本文引入一种可根据进化代数实时调整变异策略步长的动态变异算子,以变异策略的改变来优化DE 性能,并将采用了这种动态变异算子的IDE(Improved DE)算法和已有的SADE[4],古典进化规划(CEP)[8]和快速进化规划(FEP)[8]等既有算法进行了仿真比较研究.
1 差分进化算法
差分进化(DE)算法是一种基于种群和定向搜索策略的遗传算法[1].它的求解过程与其它仿生算法类似,都是从一个随机生成的初始解种群开始,模仿生物进化过程中基因变异和杂交的过程进行迭代求解,直至找到最终最优解.
DE 有多种最基本的形式[1],最著名的一种是标准DE 即“DE/rand/1/bin”.该算法工作时首先随机生成一组初始解,然后通过变异和杂交操作产生一组对应的试验解,再根据最优适应值函数判断哪些试验解能作为下一代解种群成员,然后迭代进行以上操作,直至所得到当前解种群的精度达到要求时即停止求解循环.
首先,定义Xri,G(i=1,2,···,Np)是第G代种群的解向量,其中NP是种群的大小,
变异操作:每个G代种群中的解Xri,G变异生成一个试验解Vi,G,定义如下

其中,i=1,2,···,Np,r1,r2和r3是集合{ 1,2,···,Np}中任意互不相等随机整数,F是缩放系数.
杂交操作:如同其它遗传算法一样,DE 也利用杂交算子结合两个不同的解来生成试验解,该试验解定义如下:

其中,j=1,2,···,D(D是问题维数).
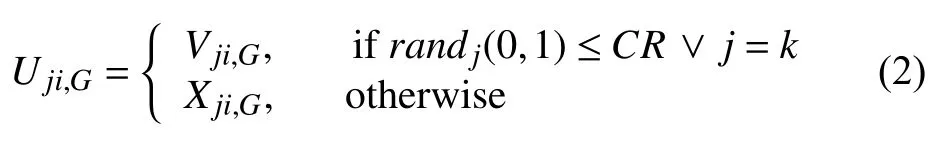
其中,CR 是预先定义好的杂交概率,randj(0,1)是(0,1)范围内的任意随机数,k∈{1,2,···,D}也是随机数.
选择操作:决定Ui,G和Xi,G二者当中哪一个成为下一代G+1 种群的成员.对求最优值问题而言,能得到更好目标值的解将被选中继续进行迭代运算.
2 根据搜索空间大小动态调整变异算子的算法
经典DE 算法的性能很大程度上受到其控制参数(收缩因子和杂交概率)的影响,不同的参数选择和变异策略会导致不同的算法性能.
在已有研究成果中,Yao 和Liu[9]提出了一种引入三角变异算子的DE,可以在算法的收敛速度和鲁棒性两者间取得较好的平衡.He 等[10]采用了辅助种群和放大因子F的自动计算.Shi[11]提出了结合DE 和分布估计的DE/EDA 算法.Liu 和Lampinen[3]提出了一种模糊自适应DE(FADE),它使用一个模糊逻辑控制器设置杂交与变异概率.Brest 等[5]研究了采用自适应控制参数的DE(SADE).SADE 采用自适应控制机制调整参数F 和CR.Qin 和Suganthan[4]提出了一种自适应DE(SaDE),研究参数CR 和变异策略的适应性.Yang 等人[6]提出了邻域搜索策略DE(NSDE),它利用服从高斯和柯西分布的随机数生成参数F,而不是预定义常数F.基于SaDE 和NSDE,Yang 等人[6]提出了另一个版本的DE(SaNSDE),它吸收了SaDE 和NSDE 的优点.苗晓锋等[12]提出了一种基于混合策略的HDE.虽然以上方法都采用加权因子的方法来控制变异步长,但很难解决待求解问题被自身特征支配的缺陷.
本文提出了一种新的动态变异算子,即根据当前搜索空间的大小动态调整局部搜索的步长,算子定义如下:
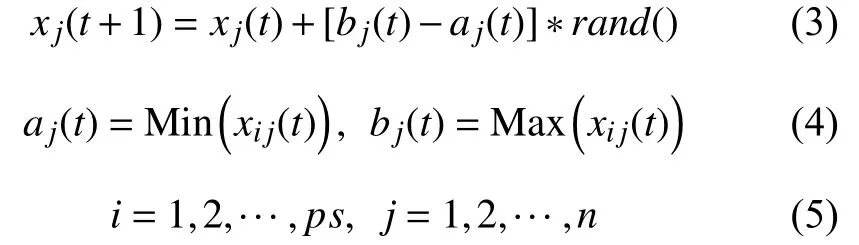
其中,xj是解个体x的第j维向量,aj(t)和bj(t)分别是当前搜索空间第j维的最小值和最大值.rand()是[0,1]区间上的随机数,PS 是种群规模大小,t= 1,2,…,指进化代数.
采用了该算子的IDE 算法流程如下:

Begin WhileNE<MAXNEdo Fori= 1 toPSdo根据式(1)和式(2)生成一个试验向量;计算试验向量的适应值;在Xi和试验向量中选择具有更好适应度的一个进入下一代种群;
其中,PS是种群规模,best 是当前最优解,NE是函数运行次数,MAXNE是函数运行最大次数.
在IDE 算法中,bj(t)-aj(t)可以被视为当前种群搜索空间变异步长的放大率.在进化初期,初始搜索空间大,步长bj(t)-aj(t)也大,此时较大的步长有利于覆盖全局搜索,便于发现潜在的更优解,同时加快算法收敛.随着代数的增加,种群将逐渐收敛到当前最优值附近,此时当前种群的搜索空间和步长bj(t)-aj(t)均变小.在这种情况下,较小的bj(t)-aj(t)值将更有利于在小范围局部搜索.
通过对著名的基准测试函数simple Sphere’s problem 进行求解,并选取当前解第一维b(t)-a(t)的变化进行记录,结果如图1所示.

图1 b(t)-a(t)值的收敛过程

End For根据式(4)计算aj(t)和bj(t);根据式(3)对最优个体best 进行变异操作;if best(t+1)的适应值优于best 的适应值best = best(t+1);if end End While End
可见,在进化开始时b(t)-a(t)值和最优适应值很大,在进化的最后阶段,最优适应值和b(t)-a(t)很小,
算法迅速收敛.
3 基准函数测试试验
为了测试算法性能,选择了三个单峰函数(f1-f3)和一个多峰函数(f4)来进行MATLAB 环境下的仿真求解实验.表1中给出了所有基准测试函数、变量维数、定义域及其全局最优解.

表1 测试函数
我们将常用的CEP、FEP、SADE 和IDE 四种算法进行比较,四种算法分别对四个测试函数进行求解运算.参数设置如下:
种群规模PS设置为50,控制参数CR和F分别设置为0.9 和0.5,函数调用最大次数MAXNE分别设置为150 000 (f1和f4),200 000 (f2),500 000 (f3).
表2中给出了测试函数的求解结果,其中Mean 表示上一代最优解的平均值,STD 代表标准方差.
显然,在同等条件下,SADE 对于前三个单峰函数的求解精度平均优于CEP 和FEP 多达e+24 倍、e+20 倍和e+12 倍,对第四个多峰函数的求解精度平均优于两种算法e+15 和e+13 倍.而IDE 的求解精度又远优于SADE,上述优势分别达到了e+27、e+25 和e+16 倍.只是在最后一个多峰函数上,IDE 和SADE 的求解精度数量级相同,但它的当前最优解的值比SADE 的值更接近于最终全局最优解.
其中IDE 对测试函数f1和f3求解时的收敛过程分别如图2和图3所示,可见其收敛过程也非常迅速,并未陷入局部最优.

表2 测试结果
4 结论与展望
本文提出了一种改进的IDE 算法,该方法可以根据当前搜索空间的大小动态调整变异步长.四个著名的基准测试函数求解实验表明,所提出的IDE 算法在同等条件下求解精度大大优于CEP、FEP 和SADE.今后的工作是尝试更多的进化和参数设置策略,以研究其对DE 算法性能的影响.

图2 改进DE 求解f1 时的收敛过程

图3 改进DE 求解f3 时的收敛过程
猜你喜欢
太原科技大学学报(2022年1期)2022-02-24
云南大学学报(自然科学版)(2022年1期)2022-02-21
计算机仿真(2021年1期)2021-11-18
计算机仿真(2021年3期)2021-11-17
校园英语·上旬(2020年1期)2020-05-09
卷宗(2017年16期)2017-08-30
科学与财富(2017年15期)2017-06-03
物联网技术(2017年5期)2017-06-03
科技创新与应用(2017年1期)2017-05-11
科技与创新(2017年3期)2017-03-17
