
基于K-means的SAMP系统数据库查询性能优化策略①
2019-07-23 02:07王喆峰尹震宇王春晓李明时廉梦佳
计算机系统应用 2019年6期
马 跃,王喆峰,尹震宇,王春晓,李明时,廉梦佳
1(中国科学院大学 计算机与控制学院,北京 100049)
2(中国科学院 沈阳计算技术研究所,沈阳 110168)
目前SAMP 系统以划分的14 个区域中心为逻辑层级结构,在物理结构设计上采用集中的单系统架构,这使得系统的架构层次变得简洁.同时随着系统间与模块间的交互变得可控,也减轻了系统交换层的压力.但由于SAMP 系统已在全院114 个所运行,8000 台设备在线,因此这种架构设计在应对每天千级以上的并发访问及百万级以上数据存储问题时,系统整体性能有待提高.
1 SAMP 系统性能瓶颈分析
1.1 SAMP 系统实体关系概念模型
系统中存在着两个核心的实体,分别为用户和仪器.系统中的其他实体,如研究所、仪器管理员、委托单、耗材、实验标准等均是在用户与仪器的基础上抽象衍生出来的.
在实体之间还存在着多种关系,这种关系可能是实体间的包含关系,也可能是实体间的操作关系.例如研究所和仪器之间具有"属于"的包含关系,用户和仪器之间具有包括"使用"、"预约"、"查看"或者"收藏"等多种操作关系.根据上面的描述,SAMP 系统实体关系核心概念模型如图1所示.

图1 SAMP 系统实体关系核心概念模型图
1.2 SAMP 系统性能潜在瓶颈
SAMP 系统的核心业务之一为用户对仪器的预约.由于用户对仪器的预约操作关系在SAMP 系统实体关系概念模型中是一个多对多的关系,因此在数据库中需要单独建表处理该关系,即创建预约表.该表中记录了用户的全部预约仪器记录,这样导致了以下两个问题:
(1)随着请求并发量的提高,由于系统在处理预约操作的时需要对数据库进行并发场景下的读写操作,千级并发量导致系统整体性能明显下降.
(2)当预约表数据量达到百万级别时,对预约表进行查询操作将消耗大量系统资源与时间.
由此可见,用户对仪器的预约操作以及后续对该预约委托单状态的维护将使应用服务器与数据库之间发生频繁的读写操作,因此用户对仪器的预约操作使得系统整体性能受到影响.
1.3 待解决的核心问题
从数据库层面去考虑处理高并发与海量数据存储问题的基本的解决方案[1],国内外现有的研究普遍从如下数据存储结构与数据查询性能两个方面出发提出一系列解决方案.例如文献[2]中作者提出了一种基于哈希算法的数据库切分(sharding)策略,并试图从数据存储结构方面解决海量数据存储问题并减少数据库的负担,缩短大数据量表的查询时间,从而达到提升系统整体性能的目的.文献[3]中作者提出了通过在MySQL数据库中合理地设置索引与游标的方式达到提高数据表的查询效率.而在这之前,还需要解决如下问题[4-7]:
(1)确定切分规则,即采用何种策略能够将数据合理的切分开,使得在后续从不同维度对预约表进行查询时都能保证查询性能.预约表与用户表和仪器表之间存在主外键关系,因此预约表中的主键为自动递增的整数,并没有实际意义.现有研究中通常采用的Hash 取模切分算法将不再适用,必须根据预约表的特点制定合理的切分规则[8-11].
(2)对数据库进行切分后,处理查询请求时必须准确定位该请求需要查询的子库或子表.
(3)当各个子库和子表的容量达到阈值时采取何种策略进行扩容.
根据目前SAMP 系统中对区域中心的定义和划分以及系统架构中的各个所级服务器与中心服务器之间的关系,可以看出用户对仪器的预约操作存在一定的聚集性.因此,核心问题被定义为:选取合适的特征变量对预约记录进行聚类分析,并根据聚类结果选取合理的切分规则对数据库进行水平切分,使得切分后的数据库能够提升预约表的查询性能,从而提高整体系统的性能[12-15].
2 基于聚类的数据库分表
根据SAMP 系统实体关系概念模型可知,对预约表进行聚类分表时特征变量的选择需要结合用户表与仪器表共同分析.用户表、仪器表以及预约表的核心表结构如表1、表2和表3所示.

表1 用户表核心表结构

表2 仪器表核心表结构

表3 预约表核心表结构
根据上面对用户表、仪器表和预约表的核心表字段结构的分析,根据聚类划分标准的不同,可以分为按照所属研究所划分或按照所属区域中心划分.但是无论采用哪种方法进行聚类分析,特征变量均包含以下两个方面.
(1)能够标识用户,例如用户所属研究院ID 和用户所属区域中心ID.
(2)能够标识仪器,例如仪器所属研究院ID 和仪器所属区域中心ID.
同时,在聚类时不仅需要选取合理的特征变量,而且还需要在数据清洗和数据预处理阶段保证数据的正确性.例如,需要保证用户具有预约权限、仪器能够被预约、预约的时间段有效等.
2.1 聚类分析分表
根据选取的特征变量可以将预约表中的每一条数据使用一个二维向量表示.根据SAMP 系统实际业务架构可知,预约用户与被预约的仪器均以区域中心为基准呈现一定的聚集性,因此本文采用K-means 聚类算法按照区域中心对预约数据进行聚类.
K-means 聚类算法通过迭代计算各个点与质点之间欧氏距离的平均值,将数据集D 中的数据划分到K个簇C1,…,Ck中,使得对于1≤i,j≤k,Ci⊂D且Ci∩Cj=Φ.这样的划分结果使得每一个簇内的对象相互相似,而簇与簇之间对象存在差异得到最终分类结果.K-means 聚类算法是一种基于形心的划分算法,在得到最终K个类的同时也得到K个形心Ci,数据对象P∈Ci与该簇的代表Ci之差用dist(P,Ci)度量,其中dist(x,y)是两个点x和y之间的欧式距离,因此聚类目标是使得各类的聚类平方和最小,即最小化公式如下:
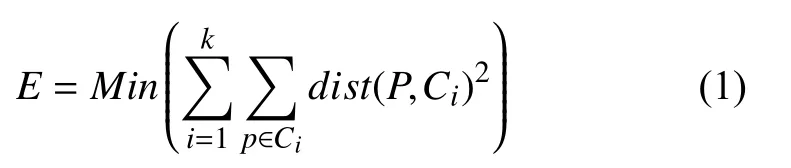
K-means 聚类算法的时间复杂度与预约表中的数据总量N,聚类后的簇数K,以及程序的迭代次数t具有线性关系.结合实际应用场景中的数据规模可知,K和t为常数级别且均远小于N.因此当预约数据总量N逐渐变大时,K-means 聚类算法相对可伸缩且有效[13].
根据聚类结果将预约表数据依次划分到各个分表中.为保证预约表数据读写请求能够准确定位到各个分表,需要在划分的过程中动态构建分类映射和分类路由.分类映射由分类结果表和分表结果表构成.其中分类结果表的数据在聚类完成后填充的,记录了聚类结果的类标号、核心点坐标以及聚集类的规模.分表结果表是在聚类的过程中动态填充的,主要记录了子表标号、子表表名、分类标号以及子表规模.而分类结果表中的类标号与分表结果表中的类标号具有主外键关系.分类结果表和分表结果表的表结构如表4、表5所示.
由于分表的策略是根据区域中心ID 进行聚类划分,因此无论从何种实体角度对预约表进行查询最终都会将查询对象按照其所属的区域中心转换成去相应分表中查询的方式.因此分表路由表保存了每一个区域中心被哪些簇所包含,分表路由表结构如表6所示.

表4 分类结果表表结构

表5 分表结果表表结构

表6 分表路由表表结构
当预约表中插入新数据时,要对新插入的数据利用聚类模型进行聚类,步骤如下:
(1)获取新数据的聚类二维特征点P(x,y).
(2)计算P与聚类模型中各个形心C1,…,Ck的欧式距离d1,…,dk,将P划分到与各个形心欧式距离最小的簇Cp中,并更新Cp的形心坐标.
(3)更新分类映射和分表路由数据.如果该条预约记录中涉及到的区域中心ID 与簇Cp的映射在分表路由表中不存在,则将映射关系添加到分表路由表中.
(4)更新分类结果中簇Cp的形心坐标(xp,yp)和该簇的聚类规模Mp如下:

2.2 分表后的扩容策略
即使将预约表进行分表处理后,每一张子表的数据量也会随着时间增加而增加,当子表的数据量增加到一定的数量级后,子表的查询性能仍然会下降.因此在分表的同时也需要为子表制定合理的扩容策略来解决由于子表数据量的增加而导致的查询性能下降问题.
评判分表扩容策略的标准是扩容过程中的数据迁移量.在分表的过程中,维护了分类映射和分表路由,并且设置子表的负载因子f,若每一张子表的数据规模为M,则子表的阈值S与负载因子f和数据规模M具有如下关系:

假设当前存在预约子表T,T所属的类标号为C,当T的数据容量达到阈值N后需要对T进行扩容处理.系统的扩容策略为:新建预约子表T’,将其添加到子表结果表中,设置T’—所属的类标号为C,重置T’的数据容量为零,并将T在分表结果表中的数据添加标志位置零,表示不再向T中添加数据.这样当再有类标号为C的预约数据插入时,会直接分配到T’中,而T中的原始数据仍然保存在T中,从而达到了原始数据零迁移的分表扩容目的.
而当出现新的分类标号导致分表需要增加时,首先将分类结果添加到分类结果表中,创建与之映射的子表,再将子表记录添加到分表结果表,并更新分表路由,最后将涉及到的区域中心ID 与分类结果ID 添加到分表路由表中,同样也能实现零数据迁移扩容.
3 实验分析
本实验使用SAMP 系统开发环境中仿真镜像数据库中存储的预约记录、用户信息及仪器信息.服务器系统为CentOS7,数据库使用MySQL 5.5,默认存储引擎InnoDB.
3.1 实验数据说明与处理
数据分为两部分使用,部分数据用于构建最小训练样本数据集,对预约记录进行聚类分析;剩余数据用于测试基于区域中心的聚类分表策略对系统查询性能的提升效果.经过实验测试发现当预约记录的数据达到四万条即可对预约数据集进行有效划分,因此用于构建最小训练样本数据集的数据量N的值为:

实验对用户表、仪器表和预约表进行聚类分析时,重点采集了包括用户ID、用户所属区域中心ID、用户权限标志位、仪器ID、仪器所属区域中心ID、仪器状态标志位、预约单开始时间、预约单结束时间和预约记录ID 在内的九维特征属性共同对训练样本数据集进行处理和分析,并分析得出这些特征属性具有以下特点:
(1)区域中心ID 为一个取值在[10,24]内的整数,其中处于[10,23]区间内的整数表示现有的14 个区域中心ID,区域中心ID 值为24 表示院外单位.
(2)用户ID 号是一个八位整数,其中前两位是用户所属的区域中心ID,中间两位是用户所属的研究院ID,后四位是递增的数字.
(3)仪器ID 同样是一个八位整数,不同于用户ID,仪器ID 的前两位是仪器所属区域中心ID 乘以四,后六位表示的含义与用户ID 号相同.
在聚类前需要对样本数据进行数据清洗与预处理确保数据的正确性,具体过程如下:
(1)去除用户权限标志位为0 的预约记录,即去除无预约权限用户的预约记录.
(2)去除仪器状态标志位为0 的预约记录,即去除预约无效仪器的预约记录.
(3)根据每一条预约记录的开始时间和结束时间,去除预约时间少于0.5 小时的预约记录.
最终每一条预约记录由一个三维向量(预约记录ID,用户ID,仪器ID)唯一表示,并使用其中的后两维属性进行聚类.
3.2 实验方法设计
本实验对训练样本集使用K-means 算法根据用户所属区域中心ID 和仪器所属区域中心ID 进行聚类分析并根据聚类结果将数据库中的预约表进行水平切分.实验构建的训练样本集数据量为669010.同时根据每一条预约记录的预约ID 在聚类的过程中动态构建分类结果表和分表结果表,并在完成聚类后构建分表路由表.其初始聚类结果如图2所示.

图2 初始聚类结果图
完成聚类模型的构建后,配合分类映射与分类路由以及分表扩容策略对全部预约数据表进行分表.为了测试分表对整体数据表查询性能的提升,实验定义三组查询测试语句分别从用户、仪器以及并发预约查询三方面进行测试.设计实验测试如下.
分表前,查询事件在预约总表中查询,获取查询结果,记录查询时间.分表后,查询事件通过以下几步获取查询结果,记录查询时间:
(1)获取查询对象所属区域中心ID.
(2)在分类路由中查询包含此区域中心ID 的子表ID.
(3)在各子表中进行查询.
在同等实验条件前提下,通过对三组查询测试语句执行时间的比较来分析聚类分表对查询性能的提升效果,设分表前查询平均执行时间为t1,分表后查询平均执行时间为t2,则分表查询提升效率f为:

本实验对查询时间及查询性能的测试均忽悠数据库对相同查询结果的缓存影响,即在MySQL 数据库中对查询语句添加“sql_no_cache”关键字来禁用查询缓存,从而多次实验取平均执行时间.
3.3 实验结果分析
实验从用户角度进行查询测试,选取查询事件:查询用户ID 为userID 的用户预约的所有仪器.分表前实验设置在禁用查询缓存的条件下执行该查询100 次,平均查询时间0.364 秒,具体查询时间分布如图3所示.

图3 分表前用户预约记录查询时间分布图
将预约表进行分表处理后,在同等实验条件下设置执行该查询100 次,平均查询时间0.111 秒,具体查询时间分布如图4所示.
实验从仪器角度进行查询测试,选取查询事件:查询仪器ID 为apparatusID 的仪器所有被预约记录.分表前实验设置在禁用查询缓存的条件下执行该查询100 次,平均查询时间0.355 秒,具体查询时间分布如图5所示.

图4 分表后用户预约记录查询时间分布图
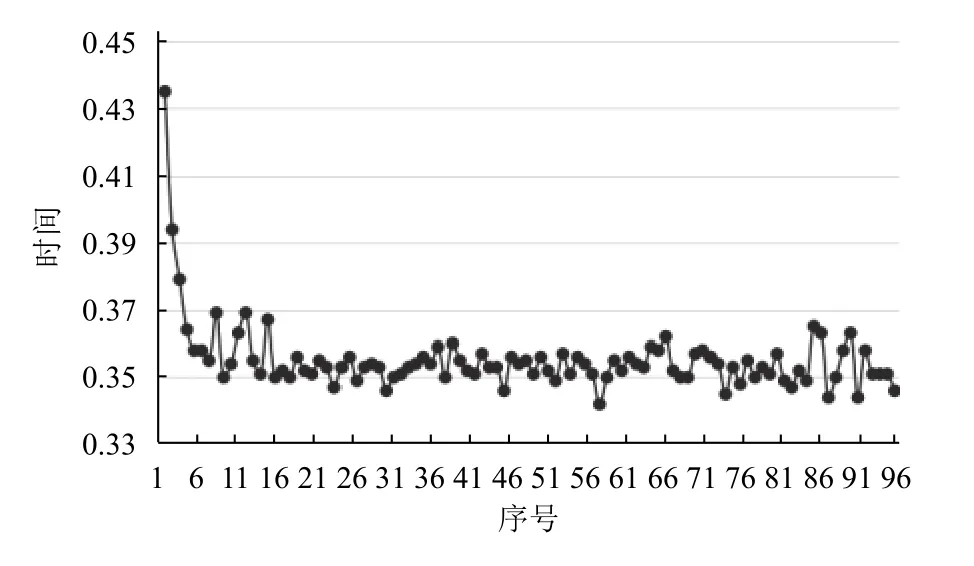
图5 分表前仪器被预约记录查询时间分布图
将预约表进行分表处理后,在同等实验条件下设置执行该查询100 次,平均查询时间0.075 秒,具体查询时间分布如图6所示.
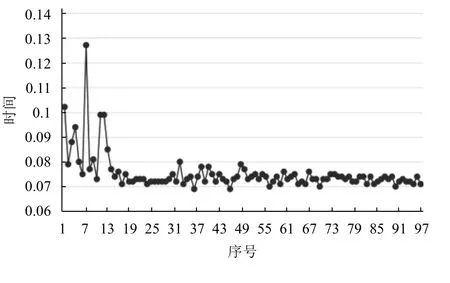
图6 分表后仪器被预约记录查询时间分布图
实验选取并发查询事件为:并发查询仪器ID 为apparatusID 的仪器被预约的记录.实验使用Apache JMeter 工具模拟多用户同时预约的并发场景,设置所有线程数在一秒内全部启动,设置数据库连接池的最大连接数为50,最大等待连接时间为120 秒,并配置数据库驱动与JDBC 连接参数.根据实际SAMP 系统运行经验,设置线程并发数为1000,即设置了在同一时间段中的最大并发量为1000.则分表前后对并发查询事件的查询性能统计如表7所示.

表7 分表前后对并发查询事件的查询性能统计
表7中各个字段的含义如下:
(1)Average:查询的平均响应时间.
(2)Median:响应时间的中间值,即在全部请求中一半请求的响应时间低于该值,一半请求的响应时间高于该值.
(3)Min:请求的最短响应时间.
(4)Max:请求的最长响应时间.
(5)Throughput:吞吐量,即每秒处理的请求数.
由上述实验可知,根据SAMP 系统实际区域中心ID 进行聚类分析并按照聚类结果对预约表进行分表处理后,从预约用户角度对预约表进行查询操作的查询性能提升率为69.5%;从被预约的仪器设备角度对预约表进行查询操作的查询性能提升率为78.9%;从并发查询角度对预约表进行查询操作的查询性能提升率为88.9%.
4 结论与展望
在SAMP 系统开发环境仿真数据库中应用基于K-means 聚类的数据库分表策略,其中包含的的聚类策略以及分表扩容策略均在SAMP 系统的应用中具有实际意义,因此弥补了当前主流数据库分表策略(例如Hash 取模分表策略)在切分预约表时的不足,对预约表数据的查询性能提升了70%,达到了优化数据库查询性能的目的,解决了SAMP 系统整体系统性能不高的问题.由于现运行的SAMP 系统每天所处理的并发请求以及对数据的读写操作较仿真系统而言规模更加庞大复杂,因此将该分表策略应用于现运行的SAMP 系统时对系统性能的提升率要通过系统运行状态做进一步分析.
猜你喜欢
现代仪器与医疗(2022年4期)2022-10-08
现代仪器与医疗(2022年4期)2022-10-08
北京航空航天大学学报(2022年8期)2022-08-31
现代仪器与医疗(2022年3期)2022-08-12
现代仪器与医疗(2022年2期)2022-08-11
计算机应用与软件(2021年7期)2021-07-16
中国传媒大学学报(自然科学版)(2021年5期)2021-02-24
财经(2017年2期)2017-03-10
财经(2016年15期)2016-06-03
互联网天地(2016年1期)2016-05-04
