
半监督自训练的方面提取
2019-07-16 08:49曲昭伟吴春叶王晓茹
智能系统学报 2019年4期
曲昭伟,吴春叶,王晓茹
(1. 北京邮电大学 网络技术研究院,北京 100876; 2. 北京邮电大学 计算机学院,北京 100876)
随着互联网的发展,用户逐渐借助网络平台来发表自己对于产品和服务的意见。这些评论往往由句子组成的短文本的形式出现,涉及产品的一个或者多个方面意见。因此句子级别的观点挖掘[1]任务一直是研究的热点。观点由4个元素组成:方面、持有者、观点内容及情感。这四者之间所存在的联系为:观点的持有者针对某一方面发表了具有情感的观点内容。方面提取[2]是观点挖掘任务的子任务之一。简短专注于观点句子中的实体部分提取,例如:“口味很好,服务周到,值得推荐”。这里的“口味”和“服务”就是方面术语,在方面提取中又涉及两个子任务:1)提取评论句子的黄金方面也叫做主体方面,是评论中各个方面表示的总称,例如美食评论包括黄金方面“食物”“服务”等,黄金方面“食物”包含多种多个方面表示词如“味道、口味”等;2)从评论语料库中学习所涉及的方面表示词。
近年来,潜在狄利克雷分布(LDA)[3]及其变种[1,4-5]已成为用于方面提取的主导无监督方法。LDA将语料库建模为主题(方面)的混合,并将主题作为词类的分布。尽管基于LDA的模型发现的各个方面可能会很好地描述一个语料库,但发现提取出的各个方面质量差,通常由无关或松散相关的概念组成。因为基于LDA的模型需要估计每个文档的主题分布,但是评论语句通常是由句子组成的短文本,对于主体分布的评估造成困难,所以效果不好。
监督学习的方法是近年来流行的研究方法,深度学习中卷积神经网络(convolutional neural network, CNN)[6-7]被应用于方面提取任务,并展现出卓越的效果。文献[8]提出一种基于7层深度卷积网络的模型来对句子进行标记训练,从而对评论进行方面提取,而且效果比较理想。然而,监督学习需要大量的标注文本作为训练数据,人工标签成本太高,而且主观性太强。
本文利用提出了一种新的半监督自训练的方法确定黄金方面[9]后利用少量标注的方面种子词,在未标签数据集上提取方面表示相似词,建立多个方面表示词集合,解决方面表示词集问题,利用丰富的方面词集合来识别文本的,能够避免大量的人工标注,并且本文方法在实际中文数据集和英文数据集上都产生了理想的效果。对实际的数据集进行了如下3个方面的研究:
1)根据研究评论数据,发现评论的针对性很强,基本是针对某项产品或者服务给出自己的体验和建议。而且数据结构具有鲜明的产品特色,句子语言简短观点明确,会经常使用到明显的方面表示词来发表意见。
2)评论往往涉及一个或者多个方面,以下一个简单的例子来自美团网(http://bj.meituan.com/meishi/)美食评论数据来说明研究的意义。例如:“口味清淡,服务员态度很好,就是价格有点贵”。这句评论涉及了对餐厅食物的“口味”“服务”以及“价格”3个方面的评价,而且对于不同的方面给出了不同的意见。采用方面表示向量来对涉及的方面进行向量表示。方面提取作为观点挖掘的第一步,来确定评论涉及的多个方面。
3)考虑到评论中涉及的含蓄表达,例如:“还挺好吃的,排队等了半小时,不过还是很好吃”。句子中并没有明确的方面表示词,但是根据关键词“好吃”可以确定是针对食物的方面意见。针对这种没有明确方面表示名词的提取方面形容词来识别方面。
基于以上的研究,本文提出的半监督自训练方法能够确定方面表示词并且自动对评论进行方面识别。首先通过计算数据集中每个词的TFIDF值,确定数据集的黄金方面,进一步从部分标签数据中获取方面表示种子词,利用词向量模型在实际未标签的数据集中寻找相似词,获得的与种子词相似的方面表示词,补充到对应的黄金方面词典里,扩充方面词典。并对目标文本进行方面识别,得到文本的方面表示向量。
1 相关工作
方面提取[10]是观点挖掘任务的基础性工作,在过去的十几年间,许多学者已经在方面提取上做了很多研究工作。主要专注于两个方向的研究,无监督和有监督方法方面提取过程可看作一个文本序列标注问题,因此可利用带监督的统计模型对序列标注过程进行训练从而提取句子的方面表示。适用此问题的典型带监督学习的方法有隐马尔可夫模型(hidden Markov model, HMM)[10]、条件随机场模型(conditional random rield,CRF)[11]等,文献[10, 12-14]采用一种编入词汇的HMM模型来提取显式方面。 最近,提出了不同的神经模型[15-16],以自动学习基于CRF的方面提取的特征。但是监督学习需要大量的标签数据作为训练集,数据标注需要耗费大量的人力成本。
无监督的学习方法可以避免标签依赖问题。潜在狄利克雷分布(LDA)[3]已成为方面提取的主导无监督方法。LDA将语料库建模为主题(方面)的混合,并将主题作为词类的分布。虽然基于LDA的模型挖掘到的各个方面得到一个很好的描述,但提取出的各个方面质量不好,通常由无关或松散相关的概念组成。因为基于LDA的模型需要估计每个文档的主题分布,但是评论语句通常是由句子组成的短文本,对于主体分布的评估造成困难。文献[17]以Apriori算法为基础采用关联规则挖掘方法找出频繁出现的名词并名词短语作为候选方面,然后,将错误的词语通过剪枝算法进行过滤,最终形成方面集合。大多数方法是基于LDA,文献[18]提出了一个生成共现词对的主题模型(BTM)。
半监督模型在方面提取中既避免了大量的文本标注,也可以利用数据的内部大量的信息来进行方面提取。文献[19]提出了两个半监督模型:SAS(seeded aspect and sentiment model)和MESAS(maximum entropy-SAS model)。SAS 是个混合主题模型在提取方面后提取观点内容,后者将方面与内容联合提取。同时,模型中加入相应种子词汇,但是可移植性较差。
本文提出的基于半监督自训练的方法进行方面提取,不仅避免监督学习中的大量的标签数据依赖问题;而且,解决了无监督主题模型中存在的短文本的方面提取结果不稳定的问题,并且在中文和英文数据集上都产生很好的性能。
2 半监督自训练模型的构建
2.1 半监督自训练模型
自训练的过程中从未标签的训练数据集上学习到贴近数据集合的方面表示词。首先计算数据集单词的TF-IDF,并对结果进行排序以便确定黄金方面。对于确定的黄金方面结果,随机选择少量的数据进行人工方面标注,从标注结果中选取黄金方面表示词作为方面表示种子词。基于方面种子词,利用词向量模型进行方面表示词学习,扩充方面表示词集合。利用新生成的集合对部分标签数据进行方面识别验证,并生成对应的方面向量。直到交叉验证的结果的正确率不再上升,则得到了最终的方面表示词集合。自训练模型架构如图1所示。

图 1 自训练模型架构Fig. 1 Self-training model architectural overview
2.2 黄金方面确定方法
为了获得数据集上的黄金方面,计算了数据集中单词的TF-IDF值。用以评估一个单词对于一个语料库中的其中一份文档的重要程度。单词的重要性随着它在该文档中出现的次数增加,但同时会随着它在语料库中出现的频率下降。其中词频(term frequency, TF)指的是某一个给定的词语在该文件中出现的次数,逆向文件频率(inverse document frequency, IDF)是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到。对于在某一特定文件里的词语ti来说,它的重要性可表示为

式中:ni,j是该词ti在文件dj中出现的次数,而分母是在文件dj中所有单词出现次数之和。逆向文件频率是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到:


2.3 方面表示词集的建立
为了获得方面表示词集合,引入词向量模型,利用模型学习到与数据集相关的丰富准确的方面表示词集。在每次方面词的学习过程中计算与已经确定的词集合的相似性,保留每个方面不重复的前10个词,扩充方面词典,学习的过程在交叉验证结果的正确率下降前停止。这是一个自训练的过程,来确定方面表示词集。因此,构建词向量[20]模型是非常重要的。
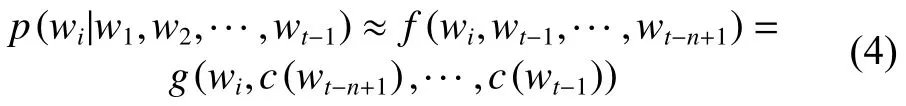
模型参数可以通过最小化交叉熵规则化损失函数来拟合:

模型参数θ包括嵌入层矩阵C的元素和反向传播神经网络模型g中的权重。这是一个巨大的参数空间。

图 2 词向量生成模型Fig. 2 Word embedding generation model
为了从上下文中预测目标词的过程中学习词向量。Skip-gram[21-22]模型的正向计算在数学上构造为

考虑到上下文,目标单词属于一个子集的概率服从以下逻辑回归函数分布:
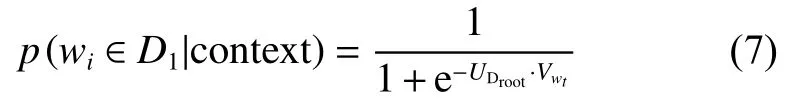
划分子集并重复上面的过程,使用二叉树可以获得logV的深度。叶节点逐一对应原始字典词,非叶节点对应于类似类集的词。从根节点到任何一个叶节点只有一条路。同时,从根节点到叶节点的方式是随机游走过程。因此,可以基于这个二叉树来计算叶节点出现的概率。例如,如果样本及其二叉树中的目标词编码为则似然函数为

每个项目是方程中的逻辑回归函数,并且可以通过最大化似然函数来获得非叶节点向量。一个词条件概率的变化会影响其路径中所有非叶节点的概率变化,间接影响其他词汇出现在不同程度的条件概率。因此,为了准确地获得方面词的向量,n(黄金方面数)个skim-gram模型构建并输入已经由模型上一次迭代产生的数据。该模型的n个部分分别基于n个语料库构建词向量,避免了词向量的交互。单词嵌入可以很容易地获得类似的单词。
3 实验
本节描述实验的建立过程,以及本文实验在实际的中文和英文数据集的效果,并且与已有的经典方法进行对比,最后对实验结果进行了分析评估。
3.1 实验的建立
数据集:采用一个中文数据集和一个英文数据集来评估本文方法。对于中文数据集,爬虫从美团网获取的71万条美食评论。英文的公共数据集Citysearch corpus是一个餐馆评论语料库,以前的研究文献[5, 23-24]也广泛使用,其中包含超过5万个来自Citysearch New York的餐厅评论。文献[23]还提供了一个从语料库中手工标记的3 400个句子的子集。这些有标签的句子用于评估方面识别。有6个手动定义的方面标签:Food、Staff、Ambience、Price、Anecdotes、Miscellaneous,数据集分布见表1。

表 1 数据集描述Table 1 Data set description
数据预处理:为了获得中文方面表示词的集合,将随机选择的1 500份美食评论平均分成5组,5位评估者被要求按照涉及的方面进行手动标注评论。所有的中文评论都被分词工具jieba分割。并且去除标点符号和停用词。英文数据集只选取了Food、Staff、Ambience三个方面黄金方面的数据,去除停用词和标点符号,并且把单词的变形转换成最原始的形态。2个数据集的单词分布结果见表2,黄金方面和部分方面表示词的示例见表3。
基准方法:为了评估本文模型,选择了两个基准方法。

表 2 数据单词集描述Table 2 Data word set description
LocLDA[23]:该方法使用了LDA的标准实现。为了防止全局主题的提取并将模型引向可评价方面,将每条评论作为一个单独的文档处理。模型的输出是对数据中每条评论的方面分布。
SAS[19]:该方法是一个混合主题模型,在用户感兴趣的类别上给定一些种子词,自动地提取类别方面术语。这个模型在已知的主题模型上,对于方面提取具有很强的竞争性。

表 3 黄金方面和部分方面表示词Table 3 Gold aspects and representative words
评估方法:把每个方面识别的过程看作一个二分类的过程,因此方面提取的效果通过precision、recall率和F13个指标来衡量,precision=对于每个二分类过程,存在4种可能的情况,正类被预测成正类(TP),负类被预测成正类(FP),负类被预测成负类(TN),正类被预测成负类(FN)。
3.2 评估和结果
对于英文餐厅的数据集,评估“Food”“Staff ”和“Ambience”3个主要方面,因为其他方面的数据在词语使用或写作风格上都没有表现出明确的模式,这使得这些方面甚至很难被人类识别。中文数据集评估了“食物”“价格”“服务”和“环境”4个方面,根据计算数据集的各单词的TF-IDF来确定数据集的黄金方面。本文模型在英文数据集和中文数据集上的结果如表4、表5和图3、图4所示。
通过图表的对比可以观察到:1)在英文数据集上,本文方法(AESS)在3个方面的召回率都高于其他方法,本文方法在员工和环境方面识别的F1分数高于其他2种方法。AESS食物的F1比SAS差,但其召回率非常高。分析了原因,发现大多数句子没有提及到味道或者食物的名词。例如,“挺好吃的”这个句子的真实标签就是食物。
2)在中文数据集上,本文方法(AESS)在食物、价格和环境方面识别的F1分数高于其他方法,4个方面的召回率都高于其他方法。本文方法在中文数据集上明显优于其他2种方法,可能的原因有中文数据集是具有特色的美食评论数据,中文在语法表达上和英文不同,语句简短甚至没有固定的语法,对于主题提取比较困难,基于数据集创建词典,避免这类问题,因此效果比较好。

表 4 3种方法在相同的英文数据集上的3个黄金方面确定的结果对比Table 4 Comparison of results determined by the three methods on the three gold aspects of the same English data set

表 5 3种方法在相同的中文数据集上的4个黄金方面确定的结果对比Table 5 Comparison of results determined by the three methods on the four gold aspects of the same Chinese data set

图 3 3种方法在相同的英文数据集上的3个黄金方面确定F1结果对比Fig. 3 The F1 results that three methods determine the three gold aspects on same English data set

图 4 3种方法在相同的中文数据集上的4个黄金方面确定结果对比Fig. 4 The F1 results that three methods determine the four gold aspects on same Chinese data set
4 结束语
本文提出一种基于半监督自训练的方面提取方法,避免了监督学习的标签数据依赖问题,并且在方面提取的结果中解决了以往无监督模型的方面聚类效果不一致的问题。本文有3个方面的贡献:1)人工标注少量的方面,作为方面表示的种子词,利用词向量获得与语料相关的丰富的方面表示词典集合,确定方面表示单词集合,解决方面表示单词确定的困难;2)通过计算数据集单词的TF-IDF值来确定数据集黄金方面,对每个句子进行多个方面的识别,并采用方面向量表示文本的包含的方面;3)本文方法同时应用到中文美食评论和英文公开评论数据集,并对比了两种经典的方面提取方法。但是本模型对单词种子词比较敏感,未来可以进一步在方面提取的基础上基于方面对内容进行挖掘,将具有更重要的意义。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
四川大学学报(自然科学版)(2021年6期)2021-12-27
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
计算机应用(2020年12期)2020-12-31
阅读(快乐英语高年级)(2020年8期)2020-01-08
智慧少年·故事叮当(2018年11期)2018-05-14
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
文苑(2015年9期)2015-09-10
小学生时代·大嘴英语(2014年9期)2014-11-04
