
基于非常规特征的Android恶意软件检测方法
2019-07-15 01:52鲁倩吴向前
现代计算机 2019年16期
鲁倩,吴向前
(1.新疆大学信息科学与工程学院,乌鲁木齐 830046;2.新疆大学网络中心,乌鲁木齐 830046)
0 引言
为了降低Android恶意软件的攻击危害,目前已经提出了各种研究方法。恶意软件检测方法可分为两类:基于静态分析的检测和基于动态分析的检测。基于静态分析的方法可以在不执行应用程序的情况下提取应用的语法功能,而基于动态分析的方法使用可以在受控环境中执行应用程序,并监控的语义功能。静态分析的优点是不需要设置执行环境,且计算开销相对较低。动态分析的优点是可以处理恶意应用程序,这些应用程序使用一些混淆技术,如代码加密或打包。
本文主要讨论基于静态分析的方法,静态分析的关键点在于对应用程序的特征提取,许多研究者已经提出并测试了许多针对恶意软件检测的特征库,但这些特征多基于操作码、权限以及API调用等,而针对界面文件以及代码方法的特征研究还比较少,而本文则基于文件熵、界面布局文件与代码方法进行特征提取,并结合机器学习算法进行研究。
本文的贡献在于:首次提出文件熵、界面布局、代码方法这些非常规作为区分Android恶意软件的特征,并结合传统的权限特征,利用Random Forest算法做分类对比实验。实验证明采用非常规特征和传统特征结合比只采用非常规特征或传统特征的效果要好。
1 本文研究方法
1.1 特征提取
(1)文件熵
上文已经提到了在APK文件里的assets文件夹下的存放的文件恶意行为可能通过更为高级的方法进行伪装或隐藏。在信息安全行业中,检测隐藏在可移植可执行文件下的加密或压缩文件的常见做法是熵分析。一般来说,压缩或加密的代码段的熵往往高于本地代码[1]。根据此属性,将PC端的思想引入Android恶意代码检测,有助于进一步搜索APK中的可疑内容,基于此提出文件熵。
在信息论中,熵(更具体地说,香农熵)是包含在一条消息中的信息的期望值。一般来说,序列的熵会受到不确定性或统计变量的大小的影响。如果所有值的出现都是相同的,那么熵将是最大的。相反,如果某个字节值出现的概率很高,那么熵值就会更小[1]。由于对任意长度的信息输入,MD5都将产生一个长度为128bit的输出[2]。为了便于计算大小不一的APK文件的文件熵,我们引入消息摘要算法(MD5)。由此,我们定义文件熵为对APK计算所得的消息摘要进行熵值计算所得的值。公式为:
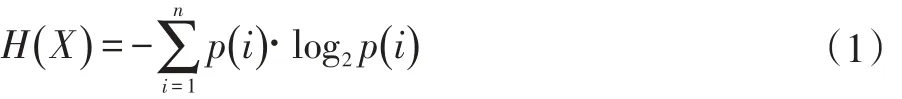
其中H(X)是对离散变量X在值为x1,...,xj的熵,j是X可能的取数值,pi代表随机事件X取值为xi的概率。
(2)界面布局特征
对界面布局的分析,类似于人们对朋友和陌生人的区别一样。界面布局属性提取自布局和定义应用程序的图形用户界面结构的XML文件。这些XML文件中包含层次化布局控件如LinearLayouts,Button以及View等。我们在这里把特征定义为APK中所有XML文件包含各种控件的总和以及每种控件的平均数量。
(3)方法/指令数量
提取方法/指令数量特征可以帮助识别那些有相同代码结构的已知App。基于此,我们对每个APK文件提取以下特征值:代码中的方法总数,每个方法包含的平均操作码数量,以及每个方法操作码数量的标准差和方差。当一个方法包含小于3个操作码的时候我们将其剔除掉。
1.2 随机森林算法
随机森林算法是一种集成式机器学习算法,其核心思想是:通过Bootstrap方式抽取数据独立训练多个基础决策树,每棵决策树都是一个分类器(假设现在针对的是分类问题),那么对于一个输入样本,N棵树会有N个分类结果。而随机森林集成了所有的分类投票结果,将投票次数最多的类别指定为最终的输出。研究表明随机森林算法在恶意代码检测分类中有较好的效果[3]。
决策树分裂或特征选择的依据是:基尼系数和信息增益。基尼系数用来度量数据的不纯度,假设有数据集D,则计算公式为:

其中c表示数据集类别数量,pi表示类别i样本数量占所有样本的比例,数据混合程度越高,基尼指数也越高。
信息熵表示了信息的混乱程度,熵值越大信息的不确定性就越大。节点的信息熵计算公式如下:

若对数据集D进行特征子集划分,划分成k个Dj子集,其子集的期望信息计算如下:
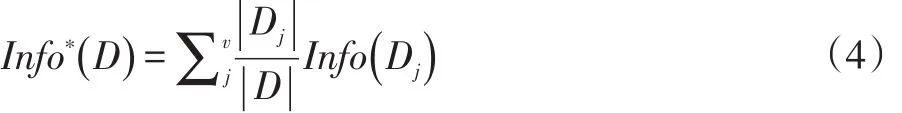
子集的信息增益则为:
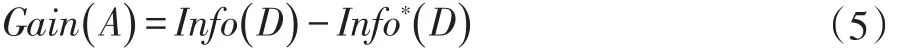
选择具有最大信息增益的特征进行分裂。
2 实验与分析
2.1 实验环境
在对样本分类时使用WEKA[4],整个实验在Androguard框架下运行[5]。测试环境为Intel i7 4810MQ,8GB内存并运行64位Ubuntu 16.04的操作系统。Androguard为开源框架且具备对字节码、AndroidManifest文件以及APK中其他XML文件的处理能力。WEKA中包含了高性能的Android恶意软件检测算法,如Random Forest、Bayesian Network、K-Nearest Neighbors等。
2.2 实验数据集
在样本集方面我们的样本集来自Malware Genome Project[6]、VirusTotal Malware Intelligence Service[7]和Google Play[8],总计5000个样本,其中包括2500个正常App和2500个恶意App。我们根据8:2的比例进行训练集和测试集的分配。为了更客观的反应测试结果,测试集中的App不包含任何来自或相似于训练集的App。
2.3 实验过程
首先对收集的样本集进行数据预处理,通过Androguard工具,通过analysis.py库提供APK.get_permissions()、get_file()、get_activities()等方法结合 Python,写批量提取文件MD5值并直接计算文件熵、计算布局文件<xml>数量、计算方法指令数量等提取APK文件各特征的代码,运行得到特征数据集。根据得到的特征数据集以8:2的比例划分训练集和测试集,先将各特征的训练集导入WEKA中进行分类器的训练,然后再用测试集进行测试。如此反复进行,从单一特征到组合特征逐一实验。实验的流程图如图1。
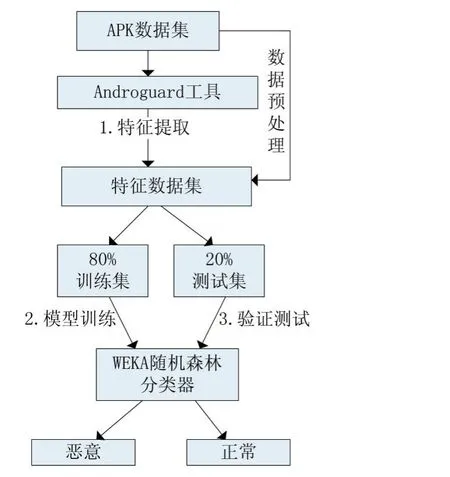
图1 实验流程图
3 实验结果与分析
3.1 性能测试标准
下面我们对测试结果的参考标准作如下说明,True Positive(真正,TP)被模型预测为正的正样本;True Negative(真负,TN)被模型预测为负的负样本;False Positive(假正,FP)被模型预测为正的负样本;False Negative(假负,FN)被模型预测为负的正样本,如表1混淆矩阵所示。True Positive Rate(真正率,TPR)和True Negative Rate(真负率,TNR)分别表示恶意App样本和正常App样本的正确识别率。相对的False Positive Rate(假正率,FPR)和 False Negative Rate(假负率,FNR)分别表示正常App被预测为恶意App和恶意App被预测为正常App。TPR有时也叫召回率,表示被正确检测出的恶意软件数量与被标记为恶意软件的总数量的比值,与其相对的是特异度,即被检测为正常的正常App数量除以被标记为正常App的数量总和。正确率被定义为真正和真负的总和除以样本集的总数,如公式(6-9)所示。此外,我们还会对训练模型用时和测试用时分别进行了统计,结果在表2、表3中显示。

表1 混淆矩阵

3.2 单一特征测试结果
在此小节中,我们会对第一节中列出的每一个单一属性集进行测试,测试结果如表2所示。对实验数据进行点线图分析,从图2中可以看出,Android权限信息是在使用单一特征的条件下性能表现最好的,能够达到96%的正确率。此外,操作码特征和App组件特征在使用单一条件的情况下也能够达到90%的正确率,本文提出的文件熵、界面布局文件以及方法/指令数量特征在单一条件情况下正确率也略高于Intent特征和统计学特征。而权限、操作码、App组件特征虽然正确率高,但本文提出的三个非常规特征的训练时间要优于其许多,尤其是App组件特征的训练时间,训练时间几乎是非常规特征的100倍。对于以上以及其他大部分特征都是在Random Forest算法的条件下表现出了最佳的性能。相比较而言,Intent特征和统计学特征在单特征条件下的检测正确率相对较低。

表2 单特征测试结果
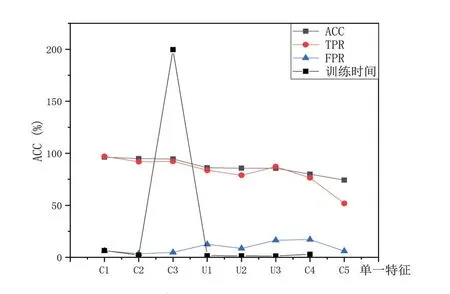
图2 单一特征测试结果
表中 C1-权限,C2-操作码,C3-App组件,C4-统计学特征,C5-Intents,U1-文件熵,U2-界面布局文件,U3-方法/指令数量。
常规特征的训练时间要优于其许多,尤其是App组件特征的训练时间,训练时间几乎是非常规特征的100倍。对于以上以及其他大部分特征都是在Random Forest算法的条件下表现出了最佳的性能。相比较而言,Intent特征和统计学特征在单特征条件下的检测正确率相对较低。
3.3 组合特征测试结果
本小节为测试评估的第二部分,基于单特征值属性的测试结果下,我们尝试对不同特征进行组合之后进行测试,测试结果在表3中进行了汇总,在图3中进行了直观展示。其中表现最佳的组合正确率超过97%,这些特征均提取自AndroidManifest文件,包括权限信息和Intents,以及本文提出的文件熵特征。在实验中我们有以下发现:
(1)在使用权限信息为基础的单一检测策略上结合文件熵,方法指令特征或者布局特征作为辅助时能够提升检测正确率。
(2)当结合Intents特征进行检测时,会成倍增加训练消耗的时间。这与对Intents进行单一特征测试时表现一致,究其原因在于Intents文件是用于组件之间的意图通信,并不直接表现为行为,因而在判别到具体行为时,是需要根据其文件进行分析之后才能判定,故而耗时。
(3)权限信息与非常规特征的组合正确率与最佳组合相差不大,但训练耗时却并未显著增加,说明非常规特征在分辨恶意软件方面具有一定的辨识度。
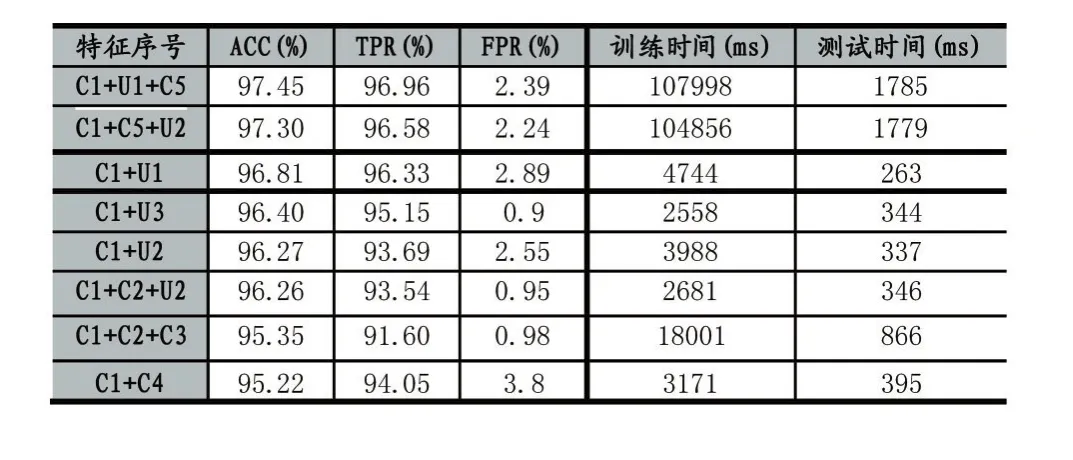
表3 组合特征测试结果

图3 组合特征测试结果
表中 C1-权限,C2-操作码,C3-App 组件,C4-统计学特征,C5-Intents,U1-文件熵,U2-界面布局文件,U3-方法/指令数量。
3.4 结果对比分析
根据以上实验结果数据,我们根据从正确率、误报率和训练耗时三个方面对结果进行分析。从图4、图5、图6可以看出,无论是单特征测试还是组合特征测试,从AndroidManifest文件中提取的权限特征相比从实际代码中提取的方法指令特征而言拥有更佳的性能表现。究其原因应该是Android权限的性质很大程度上能够准确说明一个App可能执行的行为是否存在安全问题或潜在的安全隐患。更重要的是,在不使用静态分析或动态分析的情况下,AndroidManifest文件特征能够为恶意软件检测提供一个简单有效的方法。
本文提出的非常规特征在单一特征检测时整体正确率略低于AndroidManifest文件中提取的特征,但高于统计特征和Intents特征。虽然表现平庸,但其在训练时耗上无论是单一测试还是组合测试都表现良好。在和权限特征组合之后,则优势发挥的更加明显,无论是正确率、误报率还是训练时耗都表现很好,依然在时耗方面的表现最出色。究其原因,一方面是因为文件熵特征摘取的信息过程中压缩了信息量,减少了模型训练的训练负荷,另一方面是界面布局文件种类有限,比AndroidManifest文件易于训练。理论上,恶意行为都较隐蔽,其方法指令也相对复杂,而方法指令特征的提取由于排除了指令数小于3的方法,也更加便于模型识别恶意行为。
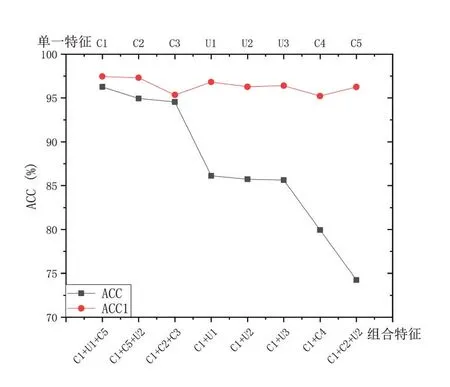
图4 单一/组合特征正确率对比
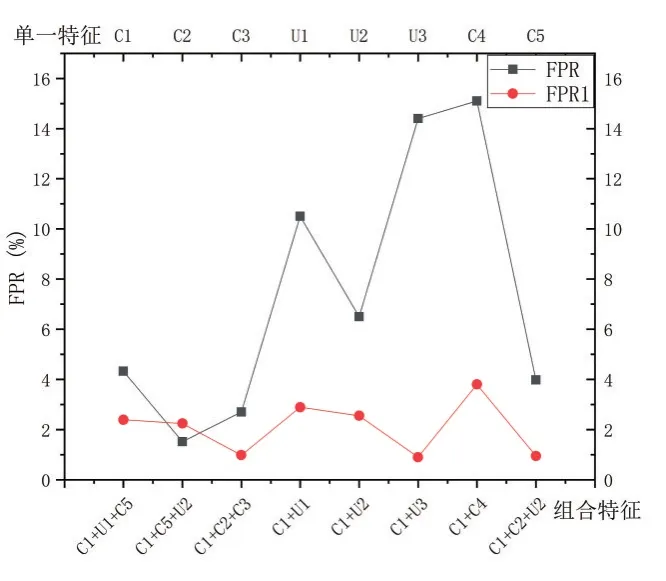
图5 单一/组合特征误报率对比

图6 单一/组合特征训练耗时对比
4 结语
在本文中,我们对基于机器学习的Android恶意检测方法中5个已知特征和3个新特征分别在单特征和组合特征条件下的性能表现做了测试。结果证明,在单特征模式下基于权限信息的检测正确率最高达到了96%左右,但存在较高的误判率;而在组合模式下,基于权限、Intents、文件熵构成的组合性能最佳能够达到97%左右的正确率和恶意App识别率的同时保证较低的误判率,因此可以被用来单独实现一个完整的静态检测方案,或者将其嵌入已有的动态Android恶意软件检测工具从而使其达到更高的检测正确率。而权限与本文提出的非常规特征的组合虽然在正确率上略低于最佳组合,但在训练时耗上远低于最佳组合,这在实际检测中是个非常重要的指标。但无论在单模式还是组合模式,最佳正确率都是在Random Forest聚合算法下实现的。未来我们会增加测试样本并对Androguard框架进行改进,增加非常规特征在其他分类算法中的检测,进一步验证其有效性。
猜你喜欢
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
医学食疗与健康(2022年3期)2022-04-23
健康体检与管理(2021年6期)2021-11-17
初中生世界·七年级(2019年5期)2019-06-22
当代陕西(2019年10期)2019-06-03
领导决策信息(2018年16期)2018-09-27
人大建设(2017年10期)2018-01-23
数学学习与研究(2017年3期)2017-03-09
家教世界·创新阅读(2016年11期)2016-12-27
故事会(2016年15期)2016-08-23
