
基于大豆原料蛋白质和氨基酸组成的豆浆甜度预测模型研究
2019-07-10 10:46陈俊伸沈新春
食品工业科技 2019年10期
孟 骏,汪 芳,孙 璐,陈俊伸,沈新春
(南京财经大学食品科学与工程学院,现代粮食流通 与安全协同创新中心,粮油质量安全控制及深加工重点实验室,江苏南京 210023)
长期以来,大豆一直是亚洲地区人们的主要副食,大豆制品如豆腐、豆浆、豆干等,食味鲜美,营养丰富,是东亚国家的传统食品[1]。其中豆浆因为具有高蛋白,富含亚油酸、亚麻酸、花生四烯酸等人体必需脂肪酸等优点,更加受到消费者的青睐。
豆浆的风味特性受多种因素影响,不同大豆品种,种植环境,加工工艺都会影响豆浆的风味。传统对于豆浆风味的分析多采用感官评价的方法[2],感官评价能较客观地反映人类对于相关食品的味觉,嗅觉和视觉感受,但其存在重现性较差,个体差异大等缺点。而电子舌技术是20世纪80年代发展起来的一种分析、识别液体“味道”的新型检测技术[3]。其优点尤为突出:首先,待测样品不需经过任何前处理,其次,检测速度快,从样品检测开始到完成只需要花费几十秒到几分钟的时间。同时,电子舌具有较高的灵敏度和重复性,测量结果可靠,从而避免了在感官评价中因为不同人群的主观倾向性造成的误差[4]。
豆浆的主要风味为甜味和苦味,据报道,豆浆中的苦味主要是由于大豆种子中的酚酸、异黄酮、皂苷以及脂肪氧化酶或不饱和脂肪酸的氧化酸败引起[5-9]。豆浆的甜味除了和大豆中的糖类物质有关,也和大豆中的其他组分有密切的关系。氨基酸作为重要的呈味物质[10-11],广泛存在于大豆种子中,有研究指出,氨基酸种类和含量影响着食品的风味[12-13]。而有关大豆蛋白质、氨基酸组成对豆浆甜味的研究鲜有报道,这将阻碍育种专家选育用于豆浆加工的专用大豆品种,因此,有必要从大豆原料的蛋白质、氨基酸组成层面上研究它与豆浆甜度之间的关系。
本文采用电子舌分析了豆浆的甜味属性,并检测了大豆原料中的蛋白质及氨基酸组成,通过相关性分析和回归分析建立了基于大豆蛋白质和氨基酸组成的豆浆甜度预测模型,并期望通过此模型快速地预测未知大豆品种加工成豆浆的甜度,达到为豆浆生产筛选优质的大豆种子,为豆浆加工的原料优化提供理论依据的目的。
1 材料与方法
1.1 材料与仪器
实验选取36种大豆原料 均由南京农业大学国家大豆改良中心提供,这些试验品种种植于南京农业大学江浦试验站,并于2015年秋收获,从36种大豆原料中随机选择30种用于预测模型的构建,剩余的6种用于预测模型的验证,具体品种名称见表1;PBS缓冲液、样品缓冲液、4%~15%变性蛋白梯度分离胶、考马斯亮蓝G-250染色液、电泳脱色液、截留分子量3500 Da透析袋、11~180 kDa蛋白Marker 北京索莱宝科技有限公司;石油醚、盐酸、硫酸、氢氧化钠、无水硫酸铜、硫酸钾等 均为分析纯,国药集团化学试剂有限公司。
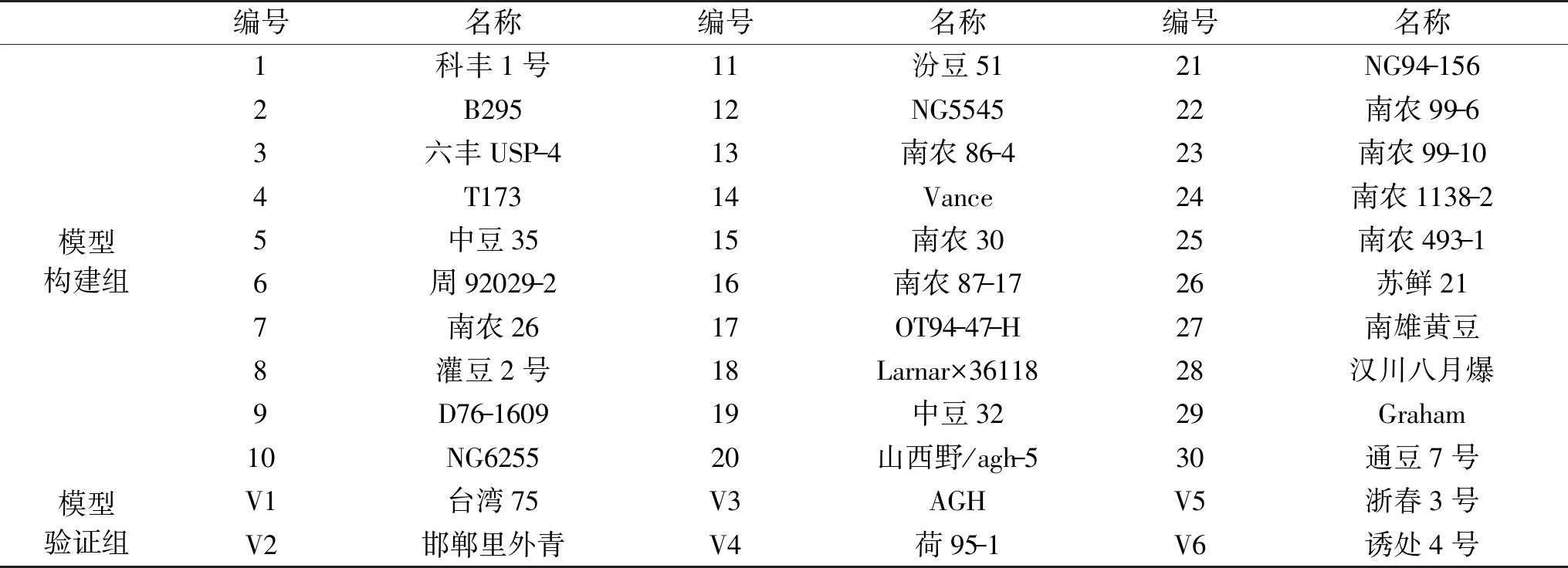
表1 36个大豆品种Table 1 36 soybean varieties
高速万能粉碎机 天津市泰斯特仪器有限公司;SL-N电子天平 上海民桥精密科学仪器有限公司;AD-G858搅拌机 深圳正向电器实业有限公司;HH-2数显恒温水浴锅 常州国华电器有限公司;K-360全自动凯氏定氮仪 瑞士Buchi公司;L-8900全自动氨基酸分析仪 中国天美科学仪器有限公司;小型垂直电泳仪 美国Bio-Rad公司;凝胶成像仪 美国Bio-Rad公司;ASTREE电子舌 法国Alpha MOS公司;THZ-C恒温振荡器 太仓市实验设备厂;H1850R离心机 湖南湘仪仪器有限公司;ALPHA 1-4/2-4 LD plus冷冻干燥机 德国Christ公司。
1.2 实验方法
1.2.1 大豆蛋白质及氨基酸含量的测定 蛋白质含量测定参照GB 5009.5-2016进行测定[14];水溶性蛋白含量的测定参照NY/T 1205-2006进行测定[15];氨基酸含量参照GB 5009.124-2016,使用氨基酸自动分析仪进行测定[16]。
1.2.2 大豆蛋白亚基组成分析
1.2.2.1 脱脂豆粉的制备 将不同品种的大豆种子经粉碎机粉碎后过80目筛,所得的豆粉与石油醚按照1∶8的比例(质量体积比)在具塞锥形瓶中混合,放入恒温振荡器中以25 ℃的条件振荡8 h,静置1 h待混合液分层后弃去上清液,保留豆粉;重复加入石油醚,25 ℃振荡8 h,静置1 h后弃去上清液3次,最后将剩余脱脂豆粉风干,即得到脱脂豆粉,-20 ℃保存。
1.2.2.2 大豆分离蛋白的提取 参考李淑芬等[17]的方法,提取大豆分离蛋白,具体操作为:将脱脂大豆粉与蒸馏水按1∶10的比例(质量体积比)混合,用1 mol/L NaOH溶液调pH至8.0,40 ℃恒温搅拌30 min,将悬浮液在4 ℃,3100×g条件下离心20 min,取上清液用1 mol/L HCl溶液调pH至4.5,将悬浮液在4 ℃,3100×g条件下离心20 min,取沉淀复溶于蒸馏水中,用1 mol/L NaOH溶液调pH至7.0,透析24 h,冷冻干燥后得大豆分离蛋白。
1.2.2.3 SDS-PAGE分析 将大豆分离蛋白与1 mol/L PBS溶液配制成浓度为2 mg/mL的溶液,并按4∶1的比例与样品缓冲液混合(样品缓冲液包含12.5% Tris-HCl,5%巯基乙醇,10% SDS,50%甘油,0.5%溴酚蓝),90~95 ℃水浴加热5 min,冷却至室温后将5.0 μL溶液加载到4%~15%的梯度分离胶中,在120 V的电压下进行SDS-PAGE直到溴酚蓝指示剂迁移到凝胶的底部边缘[18]。电泳结束后,使用考马斯亮蓝G-250(0.1%)染色,然后在脱色液中(10%甲醇,10%乙酸)脱色直到条带清晰。采用Image LabTMAnalysis Software软件对11S(大豆球蛋白)、7S(β-伴大豆球蛋白)以及相应亚基(α′亚基、α亚基、β亚基、A3亚基、酸性亚基组AS、碱性亚基组BS)的含量进行定量分析。
1.2.3 豆浆的制备 采用传统的豆浆加工方法[19],将100 g大豆种子在室温下漂洗,并在300 mL蒸馏水中浸泡10 h,将浸泡过的大豆种子沥干,以8倍大豆质量的水进行磨浆,所得豆浆经过150目筛过滤后,加热至沸腾并保持5 min,即得试验所用鲜豆浆。
1.2.4 豆浆甜味电子舌分析 将20 mL不同品种大豆制成的鲜豆浆转移至电子舌专用样品烧杯中,样品与校准溶液(超纯水)交替检测。甜味的检测方法采用标准添加的方法,具体操作为:选取5份20 mL同一品种大豆种子所制成的鲜豆浆,依次向每份鲜豆浆中加入0.0、0.4、1.0、2.0、4.0 mg标准葡萄糖,使每份鲜豆浆中的标准葡萄糖浓度分别为0.00、0.02、0.05、0.10、0.20 mg/mL,将5份添加有不同浓度葡萄糖的鲜豆浆选择为标准添加物(Standard addition products),与其他不添加葡萄糖的鲜豆浆样品共同进行味觉分析。各样品平行测定6次,选取较稳定的后3次测定数据进行分析。
1.2.5 豆浆甜度预测模型的建立 利用SPSS 22.0软件,采用回归分析的方法将豆浆甜度值与大豆种子蛋白质及氨基酸含量进行关联分析。首先将36个用于建立豆浆甜度预测模型的样品分为两组,第一组随机选取30种样品(总样本数的83%)用于构建豆浆甜度预测模型,第二组将剩余的6种样品(总样本数的17%)作为验证模型可靠性的测试样品集。利用建立的模型对6个测试样本集进行预测,比较预测值和真实值(电子舌测定的豆浆甜味数值)之间的差异,以此来验证模型的可靠性。
1.3 数据处理
每项实验均设计进行3组平行。实验数据通过SPSS 22.0软件和Origin9.1软件进行分析,通过单因素方差分析评估差异的显著性。以p<0.05作为具有显著性差异。
2 结果与分析
2.1 不同品种大豆蛋白组成及豆浆甜度分析
豆浆的主要成分是大豆蛋白,大豆蛋白主要由大豆球蛋白(11S)和β-伴大豆球蛋白(7S)组成。这两种类型蛋白质组分占总蛋白质的70%以上[1],11S为六聚体形式,由通过二硫键连接在一起的酸性亚基组(AS)和碱性亚基组(BS)组成[20]。7S主要成分包括三个通过疏水相互作用和氢键连接的亚基α′,α和β[1]。本实验随机选择的30个不同品种大豆,其蛋白质含量、蛋白亚基组成及含量、水溶性蛋白含量及其豆浆制品甜度测定结果见图1、表2。
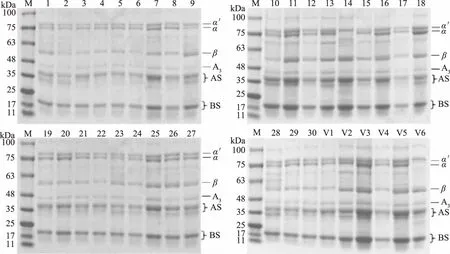
图1 36个品种大豆的蛋白亚基的电泳图Fig.1 Electrophoresis of protein subunits in 36 soybean varieties
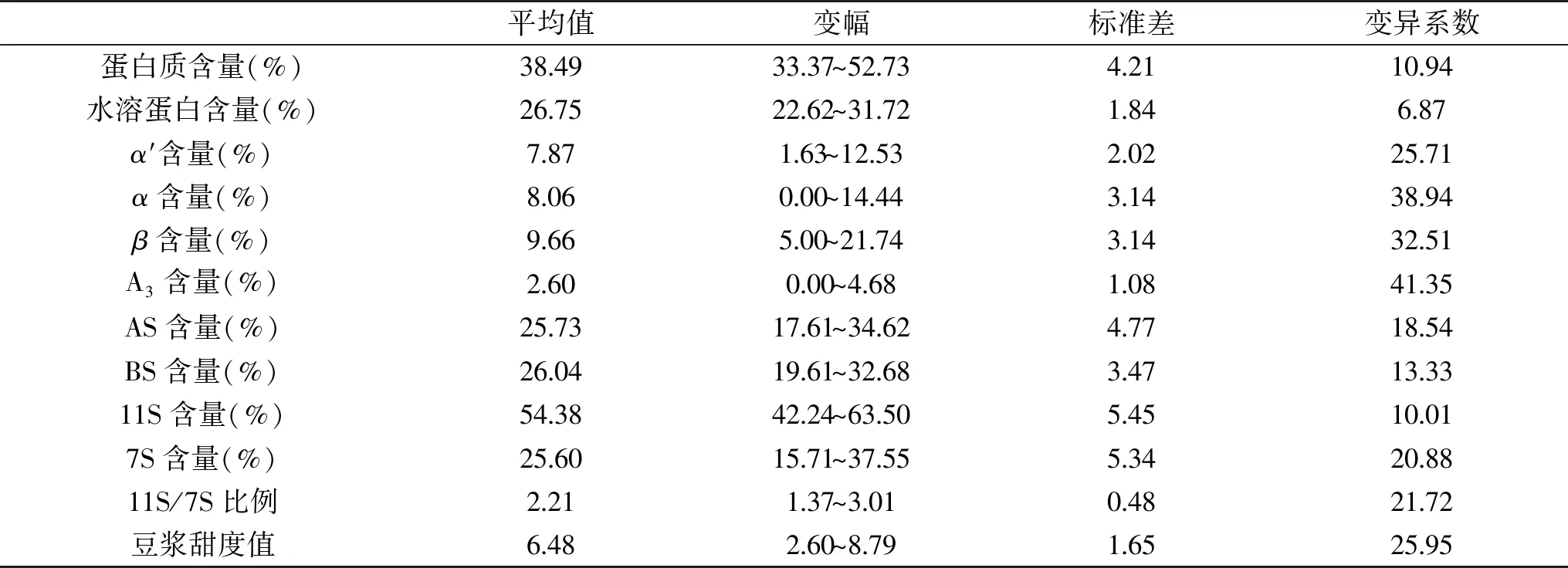
表2 30种不同品种大豆原料蛋白质组成及其豆浆甜度分析Table 2 Analysis of protein composition and the sweetness value in soymilk produced from 30 soybean varieties
图1为模型构建组及验证组共36个大豆品种的蛋白亚基图谱,由图1可知,不同品种大豆原料的蛋白亚基组成种类基本相同,而相同蛋白亚基的组成含量却存在很大差异,不同的贮藏蛋白组成将会导致大豆蛋白具有不同的功能特性。
表2则显示了模型构建组中30个大豆原料蛋白质及其亚基的含量组成,以及采用这30种大豆原料所制备的豆浆甜度。从表2中可以看出,本实验随机选择的30种大豆品种,其蛋白质含量,11S、7S含量及亚基组成、11S/7S比例之间存在着广泛变异。除了水溶性蛋白含量之间差异不显著(变异系数6.87%),其余指标的变异系数均大于10%,表明本实验所选取的实验品种之间具有丰富的遗传多样性。不同品种间蛋白质组成亚基种类基本相同,而各个亚基之间含量差异较大,尤其是7S中的α′、α、β亚基,变异系数均大于25%,这说明不同大豆种子中7S亚基的组成差异十分显著。而7S含量的变异系数为20.88%,11S含量的变异系数为10.01%,表明在大豆种子的贮藏蛋白中,11S的稳定性高于7S的稳定性。这和周宇峰等[21]、黄明伟等[22]关于大豆品种间蛋白亚基含量差异性的研究结果一致。
通过对不同品种大豆制得的豆浆进行电子舌分析后发现,不同品种大豆所制备的豆浆甜度测试平均值为6.48,而测试值从2.60变化到了8.79,变异系数为25.95%,不同品种大豆在制得豆浆的甜度属性方面存在着明显差异。以上结果说明,不同品种大豆因为其化学组分及组分含量不同,从而导致不同品种大豆制作的豆浆在甜度指标方面上有很大差异。
2.2 不同品种大豆氨基酸组成分析
表3显示了30种大豆品种的氨基酸组成,可以看出,大豆种子中天冬氨酸、谷氨酸、赖氨酸的含量高于其他种类氨基酸。不同大豆品种间,所有氨基酸种类的变异系数均大于10%,而丝氨酸、甘氨酸的变异系数达到了40%以上,这表明,不同品种大豆种子中氨基酸含量的分布差异较大,丝氨酸、甘氨酸含量的差异最为明显。
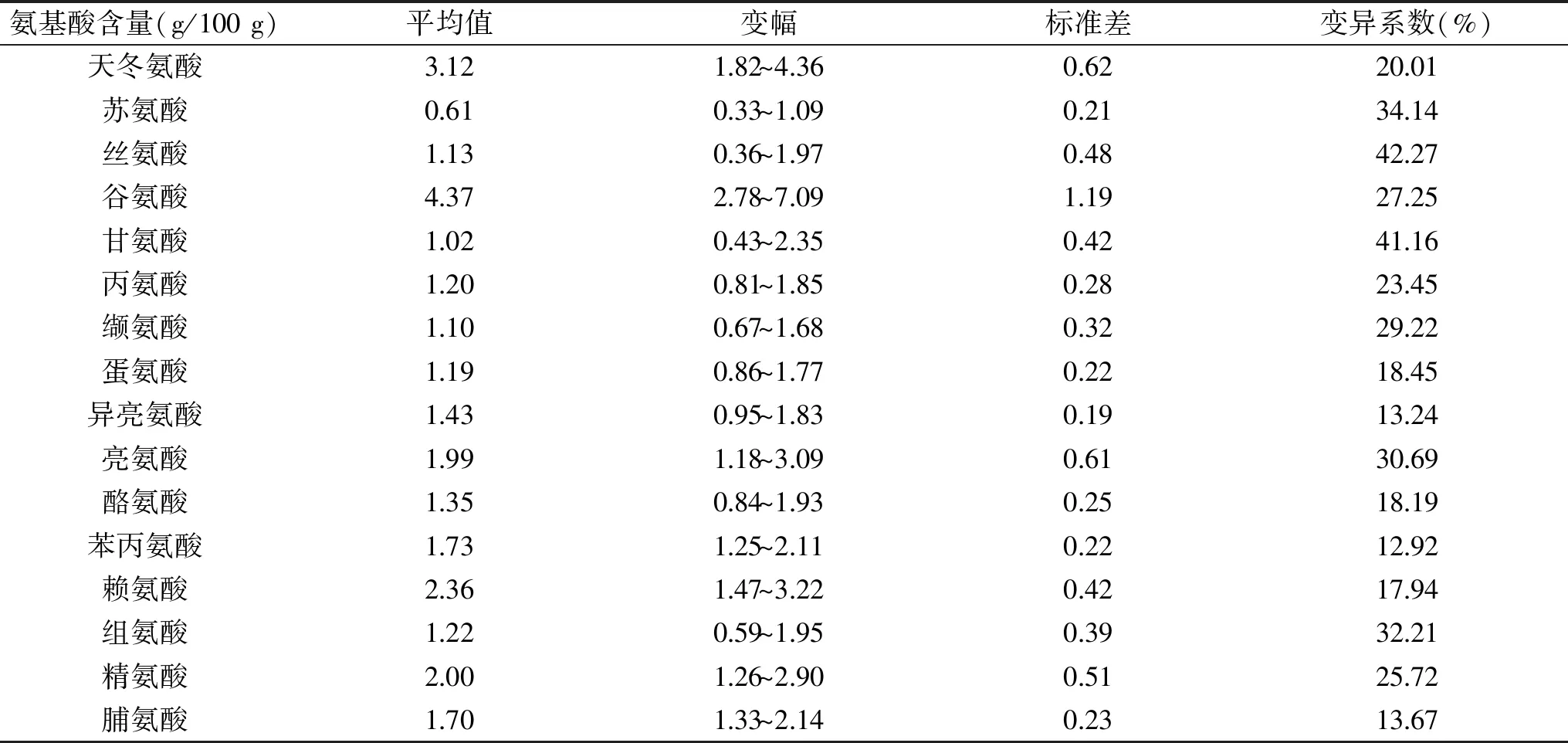
表3 30种不同品种大豆原料氨基酸组成分析Table 3 Analysis of amino acid composition in 30 soybean varieties
2.3 大豆蛋白、氨基酸含量与豆浆甜度相关性分析
豆浆甜度值在很大层面上影响着豆浆的整体食用品质,甜味较浓厚的豆浆更易于被广大消费者所接受[18]。豆浆甜味与大豆蛋白组分、氨基酸组分的相关性分析结果见表4。
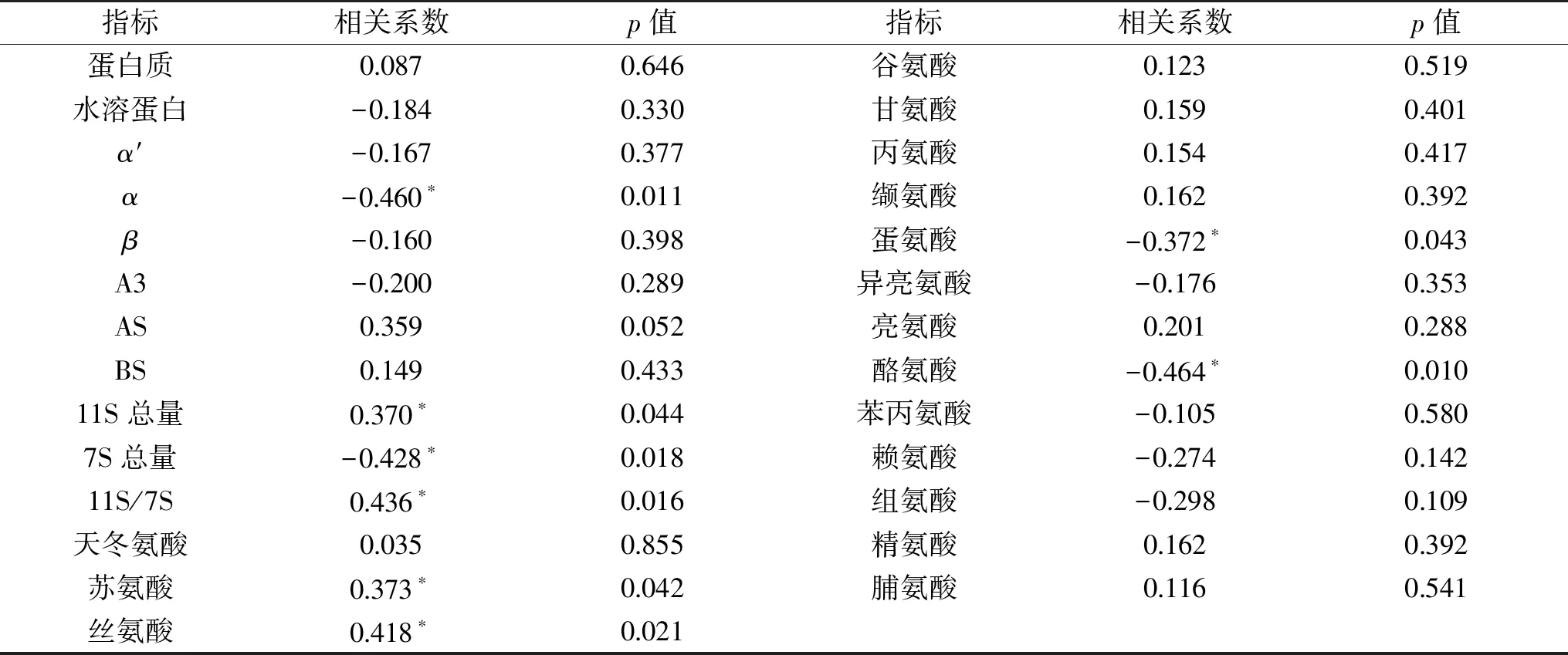
表4 豆浆甜度值与大豆蛋白及氨基酸含量的相关系数和回归系数Table 4 Correlation coefficient and regression coefficient in soymilk sweetness value with protein and amino acid contents of soybean materials
本实验统计了大豆蛋白组分、氨基酸组分共27个指标与豆浆甜度的相关性,其中α亚基含量、11S含量、7S含量、11S/7S比例、苏氨酸、丝氨酸、蛋氨酸、酪氨酸等8个指标与豆浆甜度显著相关(p<0.05)。在大豆的蛋白组成方面,并没有发现大豆蛋白质含量、水溶性蛋白含量和豆浆甜味间显著的相关性(p>0.05),而在蛋白亚基组成层面,α亚基含量(r=-0.460,p=0.011)、7S含量(r=-0.428,p=0.018)与豆浆甜度呈显著负相关(p<0.05),而11S含量(r=0.370,p=0.044)、11S/7S比例(r=0.436,p=0.016)则与豆浆的甜度值呈显著正相关关系(p<0.05)。这表明,在大豆的主要贮藏蛋白中,11S含量的增加将更有利于豆浆的甜度,这可能是由于11S中含硫氨基酸比较丰富,更有利于豆浆的整体甜味,相比于11S含量,7S含量增加则不利于豆浆的甜度。在氨基酸组成方面,苏氨酸(r=0.373,p=0.042)、丝氨酸(r=0.418,p=0.021)与豆浆甜味呈现显著正相关(p<0.05),蛋氨酸(r=-0.372,p=0.043)、酪氨酸(r=-0.464,p=0.010)与豆浆甜味之间呈显著负相关关系(p<0.05)。
2.4 豆浆甜度预测模型
2.4.1 豆浆甜度预测模型的构建 逐步回归是一种多元线性回归方法,可以选择具有最佳拟合度的自变量组合来进行因变量的预测[23],首先,逐步回归过程定义了整体模型,之后向先前模型中添加或删除变量。然后通过临界p值验证添加或删除变量的合格性,从而达到最优的预测效果。本研究以α亚基、11S总量、7S总量、11S/7S比例、苏氨酸、丝氨酸、蛋氨酸、酪氨酸等8个与豆浆甜度显著相关的大豆品质指标为自变量,以豆浆的甜度值为因变量,通过逐步回归的方法建立了豆浆甜度预测模型,如图2所示。
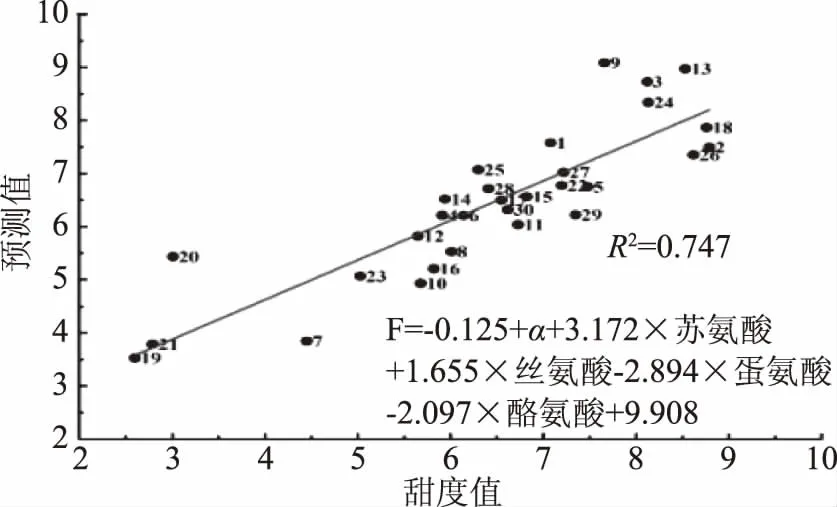
图2 豆浆甜度值预测模型Fig.2 Predictive model of soymilk sweetness value注:图中样品编号与表1相同。
由图2可知,逐步回归过程中对原本的8个自变量进行了选择优化,分析了每种自变量组合对豆浆甜度的预测效果,最终发现用α亚基、苏氨酸、丝氨酸、蛋氨酸、酪氨酸等五种指标建立的豆浆甜度预测模型具有最佳的预测效果,其模型的决定系数R2=0.747。
预测方程为:F(甜度预测值)=-0.125×α亚基+3.172×苏氨酸+1.655×丝氨酸-2.894×蛋氨酸-2.097×酪氨酸+9.908
式(1)
从模型的权重系数可以看出,在有利于豆浆甜度的指标中,相较于丝氨酸,苏氨酸含量对豆浆甜度的影响更加显著(p<0.05),而在不利于豆浆甜度的指标中,蛋氨酸比酪氨酸发挥着更加突出的作用。这与赵静等[10]有关猪骨汤中游离氨基酸呈味特性的研究结果相近,在其研究中指出,苏氨酸、丝氨酸、甘氨酸和丙氨酸对猪骨汤的甜味有突出贡献,酪氨酸、亮氨酸、蛋氨酸则会使猪骨汤呈现苦味。而本研究的结果显示,丝氨酸和苏氨酸有利于豆浆的甜度值,而酪氨酸和蛋氨酸则不利于豆浆的甜度值。整体而言,具有高含量丝氨酸、苏氨酸以及低含量α亚基、蛋氨酸、酪氨酸的大豆种子将更加适合生产甜味浓郁的豆浆。
2.4.2 豆浆甜度预测模型的验证 为了验证豆浆甜度预测模型的精确性,本研究测定了模型验证组中6个大豆品种(编号V1~V6)的甜度值,以及α亚基、苏氨酸、丝氨酸、蛋氨酸、酪氨酸的含量,并将测定的5种指标数值带入公式1,计算出模型验证组6种样品的豆浆甜度预测值,并将豆浆甜度预测值与电子舌测定的甜度值相比较,结果见表5。
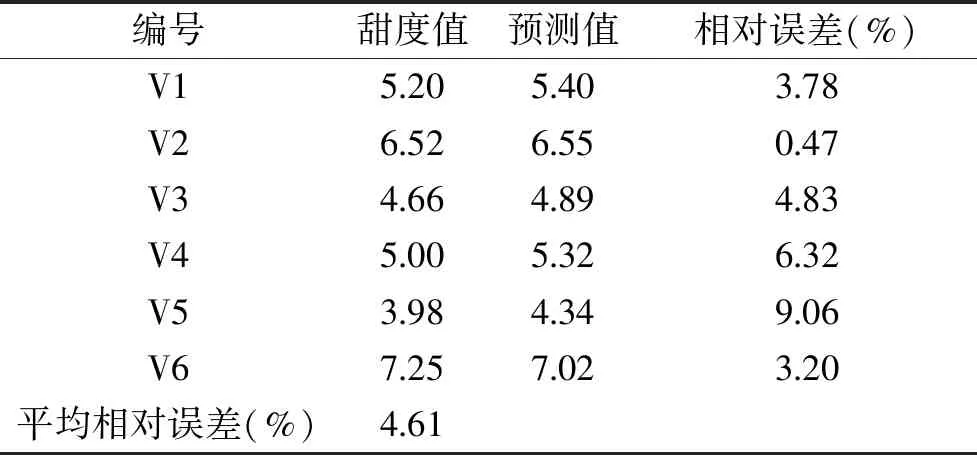
表5 模型验证组中豆浆甜度的实测值与预测值的误差分析Table 5 Relative error analysis between actual and predicted values of soymilk sweetness in model verification group
由表5可知,通过逐步回归建立的豆浆甜度预测模型,可以较为准确地预测豆浆甜度,通过公式1计算出模型验证组中6个样品的豆浆甜度预测值,并与电子舌测得的豆浆实际甜度值相比较,其相对误差均小于10%。其中,V1、V2、V3、V6的相对误差均小于5%,6个验证样品的平均相对误差为4.61%,这些结果表明了本研究建立的豆浆甜度预测模型对豆浆实际甜度有良好的预测功能,可以作为豆浆甜度预测的一种有效方法。
3 结论
本文研究了30种大豆原料蛋白质,氨基酸组成及其所制作豆浆的甜度值。不同大豆品种的各项品质指标和豆浆的甜度值均有较大差异。对于豆浆的甜度,11S、11S/7S、丝氨酸、苏氨酸含量与豆浆的甜度呈显著正相关,α亚基、7S、蛋氨酸、酪氨酸含量与豆浆的甜度呈显著负相关。通过逐步回归建立的豆浆甜度预测模型具有良好的预测能力,模型的决定系数R2=0.747,预测结果的平均相对误差为4.61%,该模型可以作为豆浆甜度预测的一种有效方法。此方法方便快捷,无需原料加工和仪器分析,便可预测未知大豆品种所加工的豆浆甜度。因此,该方法可以广泛应用于豆浆生产,具有较高的实际应用价值。
猜你喜欢
世界最新医学信息文摘(2020年68期)2020-12-25
科教新报(2020年40期)2020-12-03
烟台大学学报(自然科学与工程版)(2020年1期)2020-02-08
小哥白尼(趣味科学)(2018年9期)2018-12-18
中国生殖健康(2018年1期)2018-11-06
小哥白尼(趣味科学)(2018年4期)2018-06-21
小哥白尼(趣味科学)(2018年2期)2018-05-25
作文评点报·作文素材小学版(2017年28期)2017-08-22
科学大众(中学)(2016年10期)2016-12-29
科学种养(2016年6期)2016-06-21
