
基于指令交换的代码混淆方法*
2019-07-08 08:55祝跃飞
软件学报 2019年6期
潘 雁, 祝跃飞, 林 伟
(数学工程与先进计算国家重点实验室,河南 郑州 450001)
据2016年软件联盟(the software alliance,简称BSA)发布的全球软件调查显示,2015年,全球范围内有高达39%的已安装软件未经合法授权,这些非法授权软件导致的损失高达几千亿美元.与此同时,代码逆向分析技术的发展,使得软件保护技术的不断发展与创新尤为重要.
Collberg于1997年提出通过将源代码中逻辑相近的变量、数组等进行物理分离[1],物理分离的思想迅速被应用于二进制代码混淆算法中.Wroblewski提出了指令与指令序列乱序的思想[2],但其给出乱序的充分条件不够准确;Birrer等人提出了基于程序切分的代码混淆方法,将代码块切分成多个指令片段,并将其随机打乱分布在物理地址中,利用跳转地址表保存切片的保存顺序[3].而在工程实现中,指令乱序是通过无条件跳转的jmp、变形的短跳转 call等连接指令片段,能较大程度影响逆向分析人员的逻辑.但随着自动化逆向分析工具的不断发展,Ollydbg等工具的Trace功能能够较好地还原执行流程,辅助逆向人员进行分析.其中,指令序列交换的思想被多次提出[2,4],但是未进行系统化地分析与实现,直至2012年,z0mbie提出了基于X86指令架构的对象集的概念,开发了XDE反汇编引擎分析X86指令的对象集,并简单探讨了相邻指令交换的条件,但是不够完善和准确.
软件程序是由指令构成的序列,序列不同使得程序语义不同,代码混淆即通过将指令替换、乱序、膨胀等实现与原始程序相同的语义.本文的指令乱序是通过改变一些物理相邻但相互逻辑独立的指令执行序列来混淆原始程序,为了区分传统的指令乱序方法,本文将传统方法称为代码切分乱序.X86指令序列中,存在部分独立的指令或运算逻辑可交换的指令,即相邻的指令互换后不影响序列语义,其既与程序编写思路又与编译器编译优化相关.通过迭代交换指令,尽可能地将相邻指令距离增大,也即通过物理分离逻辑.
本文基于Wroblewski构建的计算机架构的形式化定义并予以改进,论证相邻指令序列交换的充分条件;在分析 X86指令的基础上改进 XDE反汇编引擎,实现了相邻指令交换充分条件的判断;同时,以基本块内的指令序列为对象实现了指令乱序算法,使得每次生成的二进制代码具有随机性,且能较大程度地保持与原始程序的差异性.更进一步,将指令乱序混淆算法应用于虚拟机代码保护技术,对虚拟机解释函数进行随机乱序,增强其随机性,以此为基础设计,并实现了改进型虚拟机软件保护系统 IS-VMP(VM-based protection with instructions swapping).
本文的主要贡献在于:
(1) 改进Wroblewski提出的形式化定义,论证相邻指令序列交换的充分条件;
(2) 改进 XDE反汇编引擎,采用随机化算法实现基本块内的指令乱序,通过实验验证其可行性及其效果,为代码克隆提供了一种新的自动化实现方法;
(3) 对虚拟机解释函数进行指令乱序,实现两种混淆算法的融合,增强了虚拟机保护技术的随机性,并通过实验验证了其可行性及其抗逆向分析的效果.
1 相关工作
现阶段软件保护的方法主要为源码混淆和二进制代码混淆.对于软件保护者,源代码是难以获得的,为了更好地实现功能与混淆的剥离,研究者更多地将精力集中于二进制代码混淆.但由于逆向分析技术及工具的发展,使得传统的代码混淆算法有效性大大降低.虚拟机代码保护技术的出现,使得代码保护进入了一个新的阶段,也被认为是未来发展的主要方向.
虚拟机代码保护系统首先将PE文件反汇编为X86指令流,并从中提取目标指令(KeyCode)序列,而后将目标汇编指令流转换成字节码(ByteCode).转换之后,PE文件中被保护代码的正确运行需要虚拟机解释器对字节码解释执行,因此,整个虚拟机其实是内嵌在PE文件的,它包括跳转表、虚拟指令调度器(dispatcher)、字节码和虚拟指令解释函数(handler),各模块名称及意义分别如下.
· 目标指令:目标指令为待保护程序中被保护的X86指令序列;
· 字节码:虚拟机系统定义的一套指令构成的指令序列;
· 虚拟指令解释函数:用于解释字节码的X86指令序列;
· 虚拟指令调度器:调度虚拟指令解释函数的执行程序;
· 跳转表:虚拟指令解释函数与字节码的对应关系;
· 虚拟机上下文(VMcontext):用于存储真实寄存器、虚拟寄存器、跳转表的结构.
虚拟机保护机制如图1所示,具体保护步骤如下.
Step 1. 提取待保护程序P中使用SDK标识的KeyCode;
Step 2. 将KeyCode转化成ByteCode;
Step 3. 构造Handler集合和跳转表;
Step 4. 重建可执行程序文件,将VMContext,ByteCode,Handlers,Dispatcher重新构成新节或加至最后一节,并在KeyCode指令处填充垃圾代码.
随着逆向分析技术的发展以及逆向分析者对虚拟机结构、解释函数的持续分析,虚拟机代码保护技术也逐渐被攻破[5-7].与此同时,正向保护研究人员不断将传统代码混淆技术与虚拟机代码保护技术进行融合:房鼎益等人提出通过设计数据流混淆引擎对Handler进行数据流混淆,增大数据流结构的复杂性[8];Sebastian等人提出添加依赖于程序输入的分支指令,以增大符号执行的难度[9];谢鑫等人对所有 Handler进行变长切分和随机乱序[10];吴伟明等人借鉴传统混淆技术,提出虚拟花指令序列与虚拟指令模糊变换技术,对虚拟机的虚拟指令系统做了改进[11].都在一定程度上加强了对关键代码的保护.
除此之外,研究人员基于虚拟机代码保护技术的结构,提出将随机化、动态多样化思想应用于虚拟机代码保护技术,如图1中字体为斜体的模块,其中包括:
(1) Handler多样化:采用代码克隆、语义等价等方法生成多个形态不同但语义等价的Handler序列,来增强多handler序列间的差异性,并通过随机选择路径以抵御累积攻击[6,12,13];
(2) 虚拟寄存器多样化:使用多个虚拟寄存器代替单个,模糊虚拟寄存器与主机寄存器的关系,增大数据流分析难度[14];
(3) 指令集随机化:每次执行保护时打乱字节码与解释函数的对应关系,使得不同的保护程序中字节码语义不同,延长攻击者的分析时间[15,16];
(4) 调度器多样化:使用多个虚拟机调度器,将单一的循环调度结构扩充为循环结构与链式结构混合调度结构[14].
本文研究基本块内的指令乱序,并将此随机化因素添加到Handler构造中,尽可能地减少攻击者分析同一个虚拟机代码保护系统保护的不同软件时所拥有的先验知识.
2 指令序列交换的基础理论
X86架构下的软件程序是由 X86指令集中的指令构成的序列,千变万化的指令序列构成了不同的程序语义,代码混淆即通过指令序列替换、乱序、膨胀等实现与原始程序相同的语义.本文通过对基本块中的指令进行分析,在仅改变指令序列顺序的情况下保持原始程序语义,增加序列的差异性.在详细描述指令序列交换的算法之前,先给出相关定义.
2.1 相关定义
Wroblewski构建了基于系统指令的形式化定义[2],此形式化定义使用数学定义:集合、变量、函数、笛卡尔积、向量等描述代码语义.为了更好地描述基于X86系统指令的混淆算法,本文将其定义的外沿缩小为X86系统,并由此给出相关的形式化定义、定理与相关推论,表1是该定义中使用到的相关符号.

Table 1 Description of used notation表1 符号描述表
2.1.1 基础定义
X86体系架构是冯·诺依曼体系架构中应用极为广泛的一种,其核心思想在于通过二进制指令执行处理系统存储的数据,其核心的两个要素为指令与数据.因此,可以进行如下定义.
定义2.1(计算机体系架构A(I,S)). 在计算机体系架构A(I,S)中,I={I1,I2,…,IM}为指令集合,指令实际为映射I:S→S,其中,S={(v1,v2,…,vN)|v1∈W1,…,vN∈WN}=W1×W2×…×WN是v1,v2,…,vN所有可能值构成的向量空间.
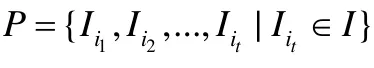
本文中,S是指令操作所依据和影响的对象构成的向量空间,简称对象空间,包含所有通用寄存器、标志寄存器和内存引用标志等.以X86体系架构的32位指令为例,其对象空间即为S=EAX×EBX×ECX×EDX×ESI×EDI×ESP×EBP×flags×memory,是一个 10 维向量空间.
定义2.3(输入对象空间SI(P)). 输入对象空间是一段程序P操作所依据或读取的所有对象的向量空间,记为SI(P)=V1×V2×…×VN,其中,
当输入的第i个分量经过程序P执行后影响了某个分量的输出,或者输出的第i分量与输入的第i个分量不等,则认为其在输入对象空间重要,否则认为该分量是不重要的,即为{α}.
定义2.4(输出对象空间SO(P)). 输出对象空间是一段程序P执行后影响或写入的所有对象,记做SO(P)=V1×V2×…×VN,其中,
如果第i个分量的输入/输出相同,则认为其在输出对象空间中是不重要的.
例2.1:假设计算机的状态空间为S=W1×W2×W3,假设一段程序为如下映射:
其中,v1∈W1,v2∈W2,v3∈W3.简单的,可以得到该程序的输入对象空间和输出对象空间:
根据上述定义,当程序为单条指令时,可以得到指令的输入/输出对象空间.本文将z0mbie提出的X86指令的对象集进行修正,为了简洁,将对象空间简化后结果见表2.X86指令按照功能可以分为算术运算、逻辑运算、数据传送、串操作、控制转移、处理器控制、保护方式指令,本文将后 3类指令视为特殊指令,其输入/输出对象空间均为EAX×EBX×ECX×EDX×ESI×EDI×ESP×EBP×flags×memory.

Table 2 Input context and output context of commonly used X86 instructions表2 常用X86指令的输入对象空间和输出对象空间
2.1.2 对象空间操作
为了分析程序与指令的输入对象空间和输出对象空间的关系,首先定义对象空间的并、交、差操作.
定义2.5(对象空间的并).设S1和S2是两个对象空间,则对象空间的并可记做S1∪S2=V1×V2×…×VN,其中,
定义2.6(对象空间的交).设S1和S2是两个对象空间,则对象空间的交可记做S1∩S2=V1×V2×…×VN,其中,
同时,利用对象空间的交定义对象空间的包含关系.
定义2.7(对象空间的包含).对象空间的包含即为集合的包含,记做S1⊂S2⇔S1∩S2=S1.
定义2.8(对象空间的差).对象空间的差即为集合的差,记做S1-S2=V1×V2×…×VN,其中,
为了便于理解,集合{α}具有空集的运算性质,也即{α}∪Wi=Wi,{α}∩Wi={α},Wi-{α}=Wi.
性质 2.1.若假设S1=V1,1×V1,2×…×V1,N,S2=V2,1×V2,2×…×V2,N,则有:
定理2.1.给定程序P=P1|P2,每段程序的输入对象空间分别为SI(P1),SI(P2),输出对象空间为SO(P1),SO(P2),则程序的输入对象空间为
定理2.2.给定程序P=P1|P2,每段程序的输出对象空间为SO(P1),SO(P2),则程序的输出对象空间为
特别地,当P1,P2同时为指令时,也即P=I1|I2,程序的输入/输出对象空间分别为
恰为文献[2]中描述的两条指令的输入/输出对象空间.
例2.2:假设一个计算机的状态空间为S=W1×W2×W3×W4,两条指令的映射分别如下:
其中,v1∈W1,v2∈W2,v3∈W3,v4∈W4,则两条指令的输入对象空间分别为
输出对象空间为
给定程序P=I1|I2,由定理2.1和定理2.2,可得程序P的输入、输出对象空间分别为
即程序P使用输入v1,v2,v4改变了v2,v3.
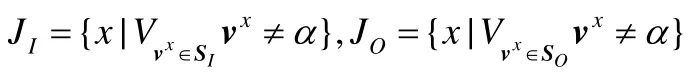
程序语义相同的公式描述的是当状态变量在当前程序所引用的分量上相等,则输出的状态变量在所影响的分量上一定相等,即相同语义的程序在其所关注的输入相同时,输出一定相同.
定理 2.3(程序交换充分条件).假设程序P1,P2的输入/输出对象空间分别为SI(P1),SI(P2),SO(P1),SO(P2),如果:
则有P12=P1|P2≡P21=P2|P1.也即:相邻两段程序不会引用另一段程序所影响的分量,同时两者所影响的分量也正交,那么两者交换不影响程序语义.
证明:定义如下集合:
由于SO(P1)∩SO(P2)=SO(P1)∩SI(P2)=SI(P1)∩SO(P2)={α}×{α}×…×{α},
对于P12和P21,其输入对象空间和输出对象空间相同,同为:
证明完毕.特别地,当程序为一条指令时,可以得到指令交换的充分条件.
定理2.4(指令交换充分条件).假设指令l1,l2的输入、输出对象空间分别为SI(l1),SI(l2)和SO(l1),SO(l2),如果:
则有P1=I1|I2≡P2=I2|I1.
例2.3:如图2中的粗斜体指令,指令I1=movesi,eax与I2=addedx,ebp的输入对象空间与输出对象空间分别为(为了运算简洁,省略特殊值{α}):
满足条件:
也即P1=I1|I2≡P2=I2|I1.
2.1.3 讨 论
定理 2.3与定理 2.4仅从输入/输出对象空间考虑程序语义相同的充分条件,没有考虑指令的映射语义.而X86指令中的算术、逻辑运算等具有其特定的语义,可能满足指令交换后语义不变的条件.
考虑到 X86指令中加减法具有交换律,因此,分析当两条指令的操作码为 ADD,输出对象空间相同时,是否具有可交换的性质,以扩展指令交换的充分条件.
在输入、输出对象空间的指导下,本文将输出对象空间相同的ADD指令分为3类,见表3.

Table 3 Input context and output context of the instruction ADD表3 ADD指令的输入/输出空间
其中,函数f是有关标志寄存器的映射关系.由指令的映射可知:I1与I2是不能交换的.而:
I2与I3是可交换的.同理,I2与I2、I3与I3也是可交换的.同时,INC指令是ADDreg1,imm的特殊情况,可以归为ADD指令.
同理,SUB与DEC指令也满足同样的性质.
由于第1类指令与第3类指令的输入/输出对象空间条件相同,因此必须结合X86指令的操作码进行判断.不妨设表 3中的第 1类指令为 ADD1,第 2类指令为 ADD2,第 3类指令为 ADD3,对于 SUB指令,同样定义SUB1,SUB2与SUB3,则ADD1与ADD2的区分条件为SI⊂SO;而ADD1与ADD3的区分条件为操作码,在X86指令中,ADD1的操作码范围为0x00~0x05,ADD3的操作码范围为0x80~0x83.
而在逻辑运算中,与、或运算所满足的结合律使得其也具有一定的可交换性,且由于任意二进制数与自身的与或结果都为自身,因此不需要如加减指令进行分类.输出对象空间相同的AND指令或OR指令可以互换.
2.1.4 指令序列距离
为了描述经过指令互换后指令序列的差异性,借鉴汉明距离(Hamming distance),给出指令序列距离的定义.
定义2.10(指令序列距离).设P1为一个X86指令构成的基本块:I1|I2|…|In,经过指令乱序的指令序列为P2:Ii1|Ii2|...|Iin,其中,i1,i2,…,in是1到n的一个有序排列,且满足P1≡P2(vI)=vO,则指令序列距离为
指令序列距离并未选取距离的绝对值作为指标描述其差异性,原因在于差异性需强调经过混淆前后指令序列的距离,例如原始序列的为 1-2-3,经过混淆后有两个序列 3-2-1与 3-1-2,若用距离的绝对值作为衡量标准,则认为两个序列具有相同的差异度,而使用距离的平方值作为衡量标准,则认为序列3-2-1与原始序列的差异度更高,这更符合实际.
3 指令乱序混淆方法
本文研究的对象为指令基本块,是静态分析的结果.混淆分为两个步骤:一是对每条指令的输入/输出对象空间进行分析,以判断是否可以进行指令交换;二是通过模拟退火算法最大化指令序列距离,寻找最优交换策略.
3.1 指令交换
图3为相邻指令交换的具体流程.
Step 1. 通过反汇编引擎将二进制代码反汇编为汇编代码,也即指令序列;
Step 2. 对基本块中指令序列的每条指令,使用改进后的XDE引擎分析其输入、输出对象空间;
Step 3. 判断两条相邻的指令是否满足交换条件.
其中,指令交换的充分条件由定理2.4和第2.1.3节构成,可进行如下定义:
则指令交换的充分条件为[4]&&[8].
3.2 指令乱序算法
为了最大化混淆前后指令序列的差异性,问题可抽象为最优化问题.给定由 X86指令序列构成的基本块P=I1|I2|…|In,则问题转化为
根据定义 2.10,该优化问题的变量为(i1,i2,…,in),其满足的条件为由此变量构成的序列P1≡P2,即该问题为非线性优化问题,可以通过遍历可行解集合求解最优值.为了更好地判断可行解集合的大小,本文任意选取基本块指令,指令数分别为 40,45,50,55,60,65,遍历以求得可行解集合大小,实验环境为 Win7操作系统,Intel(R) Core(TM) i7-6700 CPU@3.40GHz处理器,32G内存.计算结果如图4,解空间与遍历时间随着指令数的增长呈指数型增长,如果指令数超过80,遍历时间则难以满足要求.
具体分析遍历算法的复杂度,以n条指令为分析对象,其中,判断两条相邻指令的交换条件为基本操作,若满足条件则解空间增加2倍,也即基本操作增加2倍,因此,遍历算法的时间复杂度为O(2k×n)=O(2n),其中,k×n为n条指令中可相互交换的指令数;关于空间复杂度,遍历过程中只需额外维护一个当前最优值的结构体,也即空间复杂度为O(n).复杂度分析结果与实验结果相符合.
为了解决上述最优化问题,同时增加指令乱序的随机性,本文采用模拟退火算法的思想对指令乱序进行最优化求解,也即:在指令交换过程中,以Metropolis准则接收新解,使用的符号见表4,具体算法步骤如下.
Step 1. 初始化温度参数T=1,r=0.95;
Step 2. 以原始序列P为初始解,计算目标函数D(P,P)=0;
Step 3. 分析指令序列P(i)中所有可交换的相邻指令,以第一条指令为起点,判断是否可与后一条指令交换,若可交换,则产生新解P(i+1),计算目标函数差值ΔD=D(P,P(i+1))-D(P,P(i));
Step 4. 若差值大于0,则接收新解,仍以当前指令为对象进行Step 3;否则,以Metropolis准则接受新解:P(i)=P(i+1),同时进行降温:T=r×T,以当前指令的下一条指令为对象进行Step 3;
Step 5. 直到所有指令分析结束,跳出循环.
对于每次分析过程,对象仅为两条相邻语句,基本操作为判断两条相邻语句的交换条件,内循环次数不超过2,大循环的次数是指令序列中指令数n,即算法复杂度为O(n);算法分析过程中所需额外内存都是以指令数为单位,因此其空间复杂度为O(n).该混淆算法能在可接受时间内获得局部最优解,并为算法增加一定的随机性.

Table 4 Description of used notation in the disorder algorithm表4 指令乱序算法符号描述表
3.3 解释函数指令乱序
在虚拟机代码保护的各个阶段,都可融合指令乱序混淆算法.本文以解释函数构造为例,对解释函数进行指令乱序,这样每次保护便能得到语义相同但序列不同的解释函数,增加了虚拟机代码保护的随机性和动态性,增加了攻击者的分析时间.
4 实验及分析
4.1 理论分析
虚拟机代码保护技术的出现,使代码保护算法的评价更加复杂.目前,学术界并没有统一标准的方法或指标来评价某种方法或某个系统的保护效果,大多采用Collberg提出的强度、开销、抗逆向、隐蔽性这4个定性描述[1,17]来分析保护算法是否有效.本文基于这4个定性描述,对解释函数指令乱序方法进行定性分析.
指令乱序的对象为代码基本块,混淆前后的指令数量维持不变,因此在强度属性上无变化,例如强度属性中的指令执行率、控制流基本块指标等,指令乱序混淆算法不会改变上述指标.同样,对于空间开销和时间开销,由于经由混淆算法生成的保护后程序没有增加或修改指令,只是修改指令的执行顺序,因此相较于原始程序,保护后程序几乎不会改变任何时间和空间上的开销.
虚拟机代码保护技术的逆向分析集中在虚拟机保护技术的结构分析、解释函数语义还原,而现有的商业软件,如Themida,Code Virtualizer等,每个解释函数的指令数为百千数量级,针对解释函数的语义还原显得困难重重.现有的主要方法是尽可能自动化地压缩 Handler,而后通过符号执行对约减后的指令进行语义分析[18],其中,自动化压缩算法主要为模式匹配.Guillot提出:由于 Handler中大部分为算术运算与堆栈操作指令,可以通过常量传播、常量合并、运算合并、堆栈优化等方法对Handler进行压缩[19].如图5所示,可以对3条add指令进行约减.而指令乱序可能将图中可合并的指令打乱,如图6所示,原始程序中的add指令约减变得复杂,也即:指令乱序对此类基于模式匹配的自动化约减有较好的抵抗效果,增加了自动逆向分析的难度.
同时,对Handler指令序列进行随机化指令乱序,使得每次保护后程序的Handler不同,结合指令集随机化技术,极大地消除攻击者对Handler的先验知识,进一步延长攻击者逆向分析的时间.
隐蔽性强调混淆后程序与原始程序的相似度,其中,谢鑫等人[9]将指令序列之间的相似度作为隐蔽性属性的度量指标之一.而指令乱序能在对原始程序不进行语义分析的基础上增大指令序列的差异性,结合垃圾代码、等价指令替换等混淆方法,能极大地增大隐蔽性.
4.2 实验验证
本文实验环境为Win7操作系统,Intel(R) Core(TM) i7-6700 CPU@3.40GHz处理器,32G内存,选用的实例指令序列为CV的一个Handler,以此分析指令乱序的效果.
由于CV的Handler序列长度过长,考虑到篇幅限制,本文截取了某个Handler的前40条指令,属于一个基本块,对40条指令执行指令乱序混淆算法,其中,图7(a)所示为通过BeyondCompare工具对比混淆前后指令序列的差异,由图可知:两个指令序列差异较大,约一半的指令进行了指令交换操作.
由图 7(b)可知,部分指令与原始指令序列的位置距离较远.例如第 1条指令经过交换后移至第 20条指令,混淆前后的指令序列距离为17.8,以逆向分析者的角度来说,两段指令序列已经是语义不同的指令序列.
同时,本文采用的指令乱序算法是在保证局部最优值的前提下增加了一定的随机性,使得同一段指令序列每次经过指令乱序混淆得到的结果都不尽相同,如图8所示,若原始指令序列长度更长,效果更为显著.
上文主要阐述了指令乱序算法对指令乱序的效果,而代码混淆算法的优劣更应该从逆向分析人员的角度进行思考与分析[20-23].本文则借助IDA自动化分析逆向工具对指令乱序前后的程序进行比较,分析指令乱序抗逆向分析的效果.
以MD5.exe(标准的MD5加密算法执行程序)为输入,经过指令乱序算法生成MD5-IS.exe,借助IDA工具分析MD5-IS.exe相较于MD5.exe丢失的信息.经指令乱序模块分析,MD5.exe共有10 130条汇编语句,共进行了1 027次指令交换过程,指令距离为0.3,输出为MD5-IS.exe.
图9是MD5String函数经过IDA还原后的伪代码,经过指令乱序后的函数参数以及名字都有较大的信息丢失,以加大逆向分析者的还原难度.而以SHA1.exe(标准的SHA1加密算法执行程序)为输入时,IDA的反编译功能对 SHA1-GO函数的伪代码还原度极高,基本与 C++源代码相同,对于逆向分析者的后续工作有极大的帮助;而对于SHA1-IS.exe,反编译功能则不能执行,对其汇编代码无法进行转换.
4.3 性能分析
将指令乱序混淆算法与虚拟机代码保护技术融合,本文采取的融合方法为对每条 Handler进行指令乱序,在虚拟机代码保护系统My-VMP的基础上实现IS-VMP系统.实验环境同上,测试用例选用了标准的加密算法MD4,MD5与 SHA1为测试用例,见表 5.在同样的实验环境下,对测试实例分别用商用软件 Code Virtualizer(CV),VMProtect以及IS-VMP系统保护.其中:CV版本号为2.2.1.0,使用的虚拟机类型为Tiger32 White;VMP版本号为2.13.8,采用最快速度策略进行虚拟机保护.表6为保护前后文件大小变化,表7为保护前后KeyCode执行时间变化.由于每次执行时间都有所不同,图表中执行时间为 10次执行时间的平均值.其中,MyVMP与IS-VMP的区别在于是否融合了指令乱序算法.

Table 5 Test case description表5 测试用例描述

Table 6 Comparison of file size表6 保护前后文件大小变化

Table 7 Comparison of exection time表7 保护前后KeyCode执行时间变化
为了更加直观地比较不同方法之间的差别,如图10所示.
由上述图表可知,
· IS-VMP与商用保护软件的纵向对比:其膨胀比例与时间开销都处在CV与VMProtect两者之间;
· IS-VMP与MyVMP的横向对比:融合指令乱序算法后,膨胀比例与时间开销几乎不变;而根据前文的分析,IS-VMP在抵抗逆向分析与消除攻击者的先验知识上都具有一定的效果.
5 总结与展望
本文基于Wroblewski提出的形式化定义并加以改进,论证了相邻指令序列交换的充分条件,并在此基础上采用模拟退火算法实现了随机性的指令乱序算法,并以基本块内的指令序列为对象予以实现.通过实验验证了混淆算法的可行性与有效性,为代码克隆提供了一种新的自动化实现的方法.同时,分析现有的虚拟机代码保护技术的随机化与动态化思想,提出将指令乱序算法应用于解释函数的混淆,并实现了 IS-VMP系统.测试实例结果表明:指令乱序算法能有效增强解释函数的随机性,且不增加性能开销.
指令乱序混淆算法属于传统代码混淆算法,其面向对象为代码基本块,因此,其可融合的方向不仅仅解释函数,研究其应用的场景将是本文未来研究的方向.针对相邻指令交换,本文所求取的是相邻指令交换的充分条件,其充要条件仍需更多的研究.同时,研究相邻指令序列的交换的实现也具有很强的实际意义,也为恶意代码多态变形技术的研究提供了借鉴意义.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
学校教育研究(2020年11期)2020-06-08
科技与创新(2019年2期)2019-02-14
船海工程(2018年6期)2019-01-08
新高考·高二数学(2016年7期)2017-01-23
股市动态分析(2016年17期)2016-10-20
太空探索(2016年6期)2016-07-10
长江学术(2016年4期)2016-03-11
股市动态分析(2015年16期)2015-09-10
人间(2015年21期)2015-03-11
