
高性能联盟区块链技术研究*
2019-07-08 08:54:34詹士潇邱炜伟李启雷
软件学报 2019年6期
朱 立, 俞 欢, 詹士潇, 邱炜伟, 李启雷
1(上海证券交易所 技术规划与服务部,上海 200120)
2(杭州趣链科技有限公司,浙江 杭州 310000)
3(浙江大学 软件学院,浙江 杭州 310000)
区块链是由中本聪于2008年提出的一种支持比特币运行的底层技术,其去中心化、可追溯、信息不可篡改等特性,给金融服务等一系列行业带来了重大影响.区块链本质上是一个去中心化的数据库,是分布式数据存储、点对点传输、共识机制、加密算法等计算机技术的新型应用模式.区块链将给金融业、社会生活、政府管理等各方面带来变化,尤其是在金融服务业,区块链技术可能会是金融业下一个拐点.2016年,Oliver Wyman国际咨询公司在一份报告“区块链在资本市场”[1]中指出:目前,银行每年的IT和运营支出接近1 000亿~1 500亿美元.此外,交易后和证券服务费用也在1 000亿美元左右.由于目前市场运作低效率问题,导致了严重的资金损失和流动成本.
分布式账本技术通过减少重复流程、结算时间、抵押要求和业务开销,为涉及的实体节省开支.近年来,各国证券交易所都在积极探索区块链技术在市场基础设施领域上的应用,旨在利用分布式账本技术来大幅度降低交易成本和系统复杂性,并提高交易和结算速度,从而彻底改变全球资本市场的基础设施体系,带来更大的透明度和交易效率.
2016年12月,日本银行(BoJ)和欧洲央行(ECB)成立了Stella项目,目的是为了研究分布式账本系统是否能够取代当前日本央行和欧洲央行部署的实时全额结算系统(RTGS).2017年9月发布了对分布式账本技术(DLT)的评估报告[2],报告指出:当节点数量增加,DLT方案将会导致网络中交易结算时间的延长,验证节点之间的距离也会对性能产生影响.两家银行基于Fabric进行了相关测试,使用正常智能合约时,其TPS是10~70之间,最高可达到250TPS.报告得出结论:目前,DLT方案能够符合大额价值支付系统的性能需求,但当前DLT技术还不够成熟,不应被用于替代两家央行的现有系统.
日本交易所集团(JPX)联合东京股票交易所、大阪交易所以及日本证券清算集团组建了区块链联盟,旨在测试一种区块链基础设施概念验证.2016年2月,JPX宣布与IBM(日本分部)合作测试区块链技术,将使用IBM的 Fabric区块链平台作为测试实验的基础.2016年 8月底,JPX发布了相关工作报告[3],JPX分析并对比了HyperledgerFabric,R3Corda等不同的分布式账本技术如何帮助公司提高交易效率,以及该技术在金融服务领域的可行性.
2015年,证券交易巨头纳斯达克推出了他们的区块链产品——Nasdaq Linq.2017年5月,纳斯达克和花旗银行宣布采用初创企业Chain的分布式账本技术来整合支付方案.Linq能够展示如何在区块链技术上实现资产交易,同时也是一个私人股权管理工具,是纳斯达克私人股权市场的一部分.目前,Linq还处于概念探索阶段,性能还不能满足Nasdaq主流业务的需求.
2016年初,主流区块链的吞吐量依然比较慢,比如,比特币一秒钟只能完成 7笔交易.目前,以太坊真实吞吐量大约是10笔/s左右.通过调整区块大小,其吞吐量可以达到30~40笔/s.但与此同时,调整区块大小也会带来一系列负面影响,比如叔区块率增加以及矿工收益降低等.随着一年以来的技术发展,尤其是共识算法和分片(sharding)技术的逐步成熟,使得区块链的性能得到了较大的提升.一些项目组宣称,自己可以达到上万级别的吞吐量,但离开业务背景和测试环境配置,单纯提TPS大小是不具备说服力的.因为证券交易业务是一个很好的压力测试场景,因此,本文将以集中交易的订单簿的撮合作为业务背景,然后通过控制各种软硬件配置,尽可能去探索联盟区块链的性能上限.
本文旨在研究高性能联盟区块链的优化算法,结合上交所主板证券竞价交易系统的业务和现有联盟链技术,针对实际业务场景,对联盟链的共识架构、数字签名验证和存储进行优化,并进行性能基准测试,验证优化手段的效果.本文的主要贡献如下.
(1) 采用了业务逻辑与共识分离的架构,将最为耗时的交易执行操作转交给上交所现有的撮合系统,不再采用耗时的智能合约来执行业务.与此同时,共识过程不再包括业务逻辑的执行,只需负责交易的定序和交易内容的校验,从而简化了共识流程,并提升了执行的速度;
(2) 我们对存储模块进行了优化,由于本文采用了业务执行和共识分离策略,并使用上交所外部业务系统来执行交易,外部系统数据库将存储订单流水和账户信息,故区块链底层平台不再存储这部分信息(只需存储区块信息),用户交易流水和账户信息的查询功能也相应地转移给了上交所的外部系统.机构查账或审计时才会从区块中解析出交易信息.考虑到机构查账或审计是一种低频率事件,且延时要求低,所以我们对区块信息的存储方式进行了优化.不再采用levelDB存储区块信息,而是使用顺序写文件的方式存储区块信息,从而大幅度提高了写性能,更加符合业务场景的需求;
(3) 提出了两种数字签名验证的优化策略,分别是多订单打包验签和基于 GPU加速的椭圆曲线验签算法.证券交易存在 OPS(orders per second)的概念,一个交易(transaction)里面通常打包了若干笔订单(order),对这些订单只需要进行一次签名,并打包成单个交易一起发送.同时,我们还发现,验证交易的签名是整个系统处理流程中较为耗时的一个步骤.故多订单打包验签可以将共识节点签名和验签的开销平摊在交易中的每笔订单上,从而降低总体的开销.同时,合并订单还减少了节点间的通信量,降低网络带宽的负担.此外,经过对椭圆曲线验签算法的分析,我们从有限域运算和椭圆曲线标量乘法运算这两方面进行了优化,提出了一种全新的快速有限域求模运算,并在此基础上实现了椭圆曲线标量乘法的并行运算.
本文第1节对区块链(尤其是联盟链)相关工作进行回顾.第2节介绍基本算法和实现.第3节展示实验结果并进行实验结果分析.第4节总结本文工作内容,并规划未来的工作.
1 相关工作
共识算法和安全机制是联盟链的核心要素,下面我们将介绍这两方面的相关研究.
(1) 共识算法
1982年,Lamport等人提出了拜占庭将军问题(Byzantine generals problem)[4],它是一个分布式计算领域的问题,设法建立具有容错性的分布式系统,即:在一个存在故障节点和错误信息的分布式系统中,正常节点达到共识,保持信息传递的一致性.区块链共识层的作用就是在不同的应用场景下,通过使用共识算法,在决策权高度分散的去中心/多中心化系统中,使得各个节点高效地达成共识.
最初,比特币区块链选用了一种依赖节点算力的工作量证明共识(proof of work,简称 POW)机制来保证比特币网络分布式记账的一致性.随着区块链技术的不断演进和改进,研究者们陆续提出了一些不过度依赖算力而能达到全网一致的算法,比如权益证明共识(proof of stake,简称POS)机制、授权股份证明共识(delegated proof of stake,简称DPOS)机制、实用拜占庭容错(practical Byzantine fault tolerance,简称PBFT)算法等.
然而,POW,POS和DPOS等共识机制不太适合联盟链的应用场景,联盟链中通常采用BFT(Byzantine fault tolerance)类共识机制.这是因为在恶意节点数不超限制的前提下,BFT类算法可以支持较高的吞吐量和极短的终局时间,其正确性和活动性又可被严格证明,非常符合大机构的需求.经典的 PBFT算法及其变体是最为常见的联盟链共识算法,PBFT算法最初出现在学术论文中[5],初衷是为一个低延迟存储系统所设计,降低算法的复杂度.它解决了原始拜占庭容错算法效率不高的问题,将算法复杂度由指数级降低到多项式级,使得拜占庭容错算法在实际系统应用中变得可行.PBFT可以应用于吞吐量不大但需要处理大量事件的数字资产平台,它允许每个节点发布公钥,任何通过节点的消息都由节点签名,以验证其格式.PBFT是首先得到广泛应用的BFT算法,随后,业界还提出了若干改进版的BFT共识算法[6-10].
文献[6]提出了一种可伸缩的故障容忍方法,系统可根据需要配置可容忍的故障数量,而不会显着降低性能.Q/U是一种quorum-based协议,可用于构建故障可扩展的拜占庭式容错服务.相较使用agreement-based的副本状态机协议,Q/U协议可以提供更好的吞吐量和故障可伸缩性.使用Q/U协议构建的原型服务在实验中优于使用副本状态机实现的相同服务,使用Q/U协议时,性能减少了36%,而拜占庭式容错的数量从1增加到5,使用副本状态机协议时,性能下降了83%.
文献[7]提出了一种混合拜占庭式容错状态机副本协议,在没有争用的情况下,HQ采用轻量级的基于仲裁的协议,节省了副本间二次通信的成本.一旦出现争议,HQ则使用BFT解决争用.此外,总共仅使用3f+1个副本来容忍f个故障,为节点故障提供了更加优秀的恢复能力.
文献[8]提出了一种高吞吐量的拜占庭式容错架构,它使用特定应用程序的信息来识别和同时执行独立的请求.该体系结构提供一种通用的方法来利用应用程序间的并行性,在提高吞吐量的同时,还不损害系统工作的正确性.
文献[9]提出了一种使用推测来降低成本并简化拜占庭容错状态机副本的协议.在 Zyzzyva中,副本可直接响应客户端的请求,而不需要首先运行 PBFT的三阶段共识协议来完成请求的定序处理.副本节点可采用主节点提出的请求定序,并立即回应客户端.副本节点可能会出现不一致,一旦客户端检测到不一致,将帮助副本节点收敛在单一请求定序上.同时,Zyzzyva将副本节点开销降低到了理论最小值附近.
Aardvark算法[10]提出了一种实用的BFT方法,通常被称为RBFT(robust BFT)算法,RBFT算法使得系统在面对最好和最坏的情况下,性能都能大致保持不变,极大地提高了系统的可用性.
(2) 安全机制
区块链系统通过多种密码学原理进行数据加密及隐私保护.目前,区块链上传输和存储的数据都是公开可见的,仅通过“伪匿名”的方式对交易双方进行一定的隐私保护.但对于某些涉及大量商业机密和利益的联盟链业务场景来说,数据的暴露不符合业务规则和监管要求.同态加密、环签名和零知识证明等技术被认为是解决区块链隐私问题的重要技术手段.
· 同态加密技术允许区块链节点在不知道原始数据的情况下完成对交易信息的验证,即验证运算是在加密后的数据之上进行的,得到的结果仍然是加密的,而交易发起方对运算得到的加密结果进行解密,从而得到原始运算结果[11-13];
· 环签名技术允许节点在不知道交易双方是谁的情况下完成对交易的验证和存储[14];
· 零知识证明技术允许证明者向验证者证明,并使其相信自己知道或拥有某一消息,但证明过程不能向验证者泄漏任何关于被证明消息的信息.大量事实证明:如果能够将零知识证明用于区块链,将很好地解决区块链的隐私保护问题[15].
此外,联盟链中常见的非对称加密算法有RSA、Elgamal、背包算法、Rabin、D-H、ECC(椭圆曲线加密算法)[16,17]和ECDSA(椭圆曲线数字签名算法)[18].对部分投产使用的区块链产品,要求使用国密级别的安全算法.
2 高性能联盟区块链架构设计与实现
本节将介绍提升我们区块链平台(以下简称 Hyperchain)性能的几种优化策略,包括业务逻辑和共识分离、存储优化、数字签名验证优化这3个部分.
2.1 系统架构
一个典型联盟链系统的工作流如图1所示.
一笔交易最初从客户端发起,在签名后发送给联盟链的节点.服务器端(Http服务器)在收到交易请求后,会校验交易签名和交易证书等信息.校验通过后,再将交易推送给共识模块,并通过P2P模块进行广播,随后开始节点间的共识.
执行模块和虚拟机模块在收到共识模块的交易信息后,会基于区块号调取执行环境,并执行交易.执行内容包括签名验证和交易执行等过程.验签确认了交易的来源和内容的完整和安全性,该过程在执行模块中进行,而具体的交易执行则会以智能合约等形式在虚拟机中进行.交易执行结束后,变化量会被保存在执行模块缓存中,供后来的交易或账本持久化使用.交易结果的Hash会返回给共识模块用于和其他节点的执行结果进行比对.
图 2是改进后的系统架构,相较图 1的典型联盟链系统架构,该架构最大的不同在于将业务逻辑执行模块与共识验证模块解耦合.由于本文是以“去中心化主板证券竞价交易系统”为应用场景,上交所现有业务系统的TPS可以达到10万~30万.而我们在实际测试中发现,在Hyperchain上使用智能合约执行交易时,TPS仅为几千,这个吞吐量远不能满足主板证券交易的需求.
优化后的联盟链系统架构将交易的执行和共识进行了解耦,使得交易执行任务的转移和并行变得可能.如果将交易执行的任务交由上交所现有的外部业务系统完成,而不是采用智能合约的形式,区块链底层平台只负责交易定序及合法性验证工作,那么系统的吞吐量则可以有很大的提升.故优化后的系统架构更加适合证券交易这类较高频的业务场景.
下文中,第2.2节针对的是共识模块的优化,第2.3节是关于账本模块的存储优化,第2.4节提出了两种优化验签模块的方法.
2.2 业务逻辑和共识分离
在联盟链中,使用智能合约执行交易,并将执行结果加入共识流程是一种较为通用的模式(如图 3所示).将执行结果加入共识可以保证节点间数据的一致性,而使用智能合约可以增强整个联盟链的通用性.针对不同的业务场景,只需要设计不同的智能合约,而不需要更改架构本身.
在模拟上交所证券撮合业务场景的过程中,我们发现最为耗时的步骤是交易的共识和执行.表 1中,交易的共识和执行占一个区块生成时间的90%.生成一个区块的流程大致可以分为区块打包、区块共识和区块提交这3个部分.
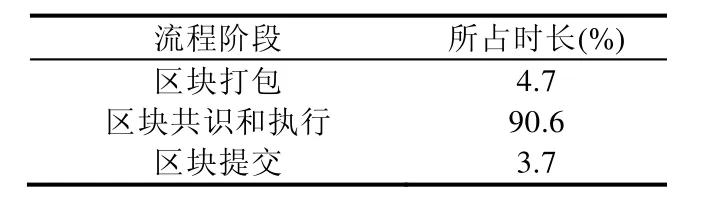
Table 1 Duration of each phase表1 每阶段占用时长
区块打包的耗时与客户端发送交易的内容相关,区块共识和执行、区块提交的耗时则与区块大小和智能合约代码相关.Hyperchain采用的 PBFT共识一般可以分为 3个阶段,分别是 Pre-prepare阶段、Prepare阶段和Commit阶段.
因为区块执行是按序串行执行的,交易执行大大增加了区块生成所用的时间,是整个系统的性能瓶颈.为了提高交易执行的效率,首先需要解决智能合约运行效率的问题.在实际研究中,我们发现很难用智能合约进行证券交易撮合的业务.一是证券撮合相对一般业务更为复杂,设计一个高效完备的智能合约难度较大;二是智能合约架构设计本身和证券撮合这类业务没有很好地适应.智能合约运行的生命周期是完成一笔交易所用的时间,每处理一笔新的交易,系统都要重新从内存或者数据库中将数据加载进合约,合约处理效率低,无法满足证券交易所需的吞吐量.
为了解决这一问题,我们采用了一种新的架构——业务逻辑和共识分离(如图4所示).这是一种在联盟链中越来越流行的架构,如著名开源项目Fabric 1.0(https://hyperledger-fabric.readthedocs.io/en/release-1.3/arch-deepdive.html#system-architecture).采用该架构,交易的执行不再受到节点共识的影响,交易可并行执行.
交易到达节点后,共识节点只负责共识交易的排序和交易的内容,不再执行交易和共识执行结果.定序以后的交易通过网络通信发送给外部业务系统,由外部业务系统执行具体的交易,并保存交易结果.不同的外部业务系统可以根据需求,决定是否返回执行结果.由于共识节点不再负责交易的执行和执行结果的共识,Hyperchain会在区块到达检查点(checkpoint)时再对执行结果进行共识,以保证节点之间数据的一致性.这种架构下,共识节点的功能更倾向于定序和存证.
在这种系统架构下,Hyperchain共识过程不再包括业务逻辑的执行,简化了共识流程,提升了共识速度.此外,将业务逻辑从共识剥离出来后,交易执行模块的可扩展性大大提高.Hyperchain可以根据业务需求选择使用内嵌的 EVM/JVM 虚拟机,或者使用网络通信对接企业原有的业务系统,不仅降低了开发成本,还能真正实现交易的并行执行.
从图 4可知:Hyperchain平台是先进行共识定序和校验,再调用执行模块或外部系统来执行交易.而 Fabric是先由客户端指定所需的背书节点提前执行交易,再由共识(order)节点进行定序和交易合法性校验.采用先执行后定序的方式必须保证有关联性的交易可以按序执行,否则会导致交易失败.先执行后定序的方式并不适合证券交易场景,因为在该场景下,订单的先后顺序直接影响成交,订单之间的相关性较强.
此外,由于使用网络通信,交易执行模块的插拔可以跨语言和平台,不再限于 Go语言,各模块可以部署在一台服务器上以降低成本,也可以选择分别部署在不同服务器上,让业务逻辑和共识逻辑可以分布在不同的物理机上,降低IO和CPU的抢占.交易执行模块可以针对不同业务场景编写特定交易处理系统,提升效率.以去中心化主板证券竞价交易系统为例,简易 Java撮合系统每秒可以撮合几十万笔交易,远远超过了目前所有智能合约执行器能达到的效率,使得交易执行的速率可以满足实际生产中的高频交易处理需求.
2.3 存储优化
在Hyperchain运行过程中,我们一般会存储3部分内容.
(1) 区块信息:包括区块内的交易信息、交易执行的顺序、交易到达区块的时间戳、区块打包时间戳、区块执行时间戳和区块哈希等信息,区块信息包含了区块上链所需的所有内容;
(2) 单笔交易信息和交易回执:Hyperchain为了提供快速的交易查询功能,交易信息除了储存于区块中,也会独立存储于数据库中(如levelDB).交易哈希作为存储的key,交易内容作为存储的value.以空间换时间,一次数据库读取操作就可以完成交易信息的查询.交易回执在数据库的存储方式和交易信息类似,key是交易哈希加特定前缀,value则记录了交易执行的结果.用户通过查询交易回执可以快速获知交易结果;
(3) 账户数据:区块链是一个分布式的大账本,每个节点共同参与大账本的记账.Hyperchain系统支持使用智能合约执行交易,因此和以太坊一样,采用账户模型来组织数据.每执行一笔交易,都会读/写相关账户的状态数据.比如,一个模拟银行转账的合约会生成或者改变用户余额、转账信息等数据.执行结束,会将期间所有的改动统一写入.
由第 2.2节可知:针对上交所的证券交易业务场景,Hyperchain采用了业务执行和共识分离的策略,不再使用智能合约来执行交易,而是直接使用上交所 Java撮合系统来执行交易,交易流水和账户信息会储存于上交所的数据库中,所以Hyperchain不再存储交易流水和账户信息.与此同时,用户的交易流水和账户信息的查询功能也相应地转移给了上交所外部业务系统.从图 5虚线条可知:当用户需要查询订单信息或账户信息时,我们会默认从上交所数据库中读取信息并返回给用户.如果普通用户指定要从 Hyperchain查询订单信息时,我们会从内存(内存中只保存近期的订单信息)中读取该笔订单信息并返回给用户,仅当用户需要查询历史订单信息时,我们才会从区块中解析出该笔订单信息并返回给用户.采用该存储方式,是因为我们发现证券业务具有很强的时效性,这样不仅减少了I/O消耗,也节省了磁盘空间.
值得一提的是,智能合约为了满足通用性,Hyperchain统一使用了NoSQL类型数据库去存储数据,故在性能上会逊色于上交所定制化的外部业务系统.一般使用智能合约执行交易时,TPS仅为几千,但上交所现有业务系统的 TPS可以达到 15万,深交所新系统 TPS可以达到 30万左右,在这种高频业务场景下,I/O可能会成为Hyperchain的性能瓶颈.所以,交易执行和存储任务的转移,缓解了Hyperchain的数据库读写压力.
由上可知,Hyperchain不再单独存储每笔交易的信息和回执以及用户的账户信息,只存储了区块信息.一段时间后,再向Hyperchain请求交易信息的,可能是机构为了查账或审计,这时,可从区块中还原出订单信息(见图5实线条).尤其在多中心的业务场景下(如深交所和上交所合作的交易场景),由于区块链具有区块数据不可篡改的特性,审计单位可以从节点回溯到原始数据,避免了多中心数据不一致的问题.
一般情况下,由于LevelDB有很多和Hyperchain相适应的特性,Hyperchain会选择LevelDB作为默认数据库.LevelDB是Google实现的一个高效KV数据库,支持多条操作的原子批量操作,满足Hyperchain对原子性写入区块信息的需求.借助LSM(log-structured merge tree)树和WAL(write-ahead logging)的设计,LevelDB写性能较为出色,随机写性能达到每秒40万条记录,可以支持Hyperchain快速存储大量的区块信息.
考虑到机构查账或审计是一种低频率事件,且延时要求低,所以我们对区块信息的存储方式进行了优化.不再采用 levelDB存储区块信息,而是以一定形式组织区块,然后存储在特定后缀的文件中.每个文件存储固定数目的区块,在文件被关闭时,文件头部预留处将添加区块索引.采用这种形式存取区块的时间复杂为O(1),不会随着数据量改变而变化.区块按序存储的特性也使得待写入的数据会在缓存中连续存储,磁盘 IO多为顺序写,以提高IO效率.这种存储方式大幅度提高了写性能,更加适合本文的业务场景.
2.4 数字签名验证优化
区块链所有交易都带有交易签名,区块链节点通过验证签名,确保交易的有效性.在证券交易这种高频业务场景中,交易数目大,要求程序能快速完成验签运算,系统才能具备较低的响应延迟和较高的吞吐量.Hyperchain对验签策略进行了优化,加快了签名运算.Hyperchain对数字签名验证优化包括两方面:多订单打包验签和基于GPU加速的椭圆曲线验签算法.
2.4.1 多订单打包验签
由于本文是以去中心化主板证券竞价交易系统为应用场景,我们了解到证券交易是一个B2B的市场,证券交易存在 OPS(orders per second)的概念,即:订单数(order)跟交易(transaction)并不是一一对应的关系,一个transaction里面可以打包若干笔 order.对这些订单只需要在一次签名后打包到单个交易中一起发送.实际业务场景中,券商报单就是十几笔、二十几笔订单一起打包发送.
在研究过程中,我们发现交易的签名验证是整个系统处理流程中最为耗时步骤之一.在分析了上述证券交易的实际情况以后我们发现,合并验签的方式可以提升系统效率.因为单个区块通常包含不止一笔交易,而共识是按块进行的,所以打包验签是最为直接的优化方案.
打包签名和验签可以将共识节点签名和验签的开销平摊在块中的每笔交易上,从而降低总体的开销.尤其是在证券竞价高频交易的情况下,客户端往往会一起发送大量的订单,如果客户端可以将若干笔订单合成在一笔交易中,并进行签名,就会减少大量的验签次数.同时,由于网络带宽是限制联盟链吞吐量的另一个重要因素,合并订单还可以减少节点间的通信量,降低网络带宽的负担.
多订单打包验签即在用户发送交易时候,将多个交易打包成为一个整体,然后通过对应的加密算法(ECDSA或者国密)来进行统一的签名,随后发送给服务器进行统一验签(如图6所示).
多订单打包的内容会被当成一条交易,但在交易验证的过程中,节点会把交易进行反序列化,并按订单打包的顺序,按序执行订单内容.
2.4.2 基于GPU加速的椭圆曲线验签算法
Hyperchain可支持SM2椭圆曲线公钥密码算法[19],椭圆曲线密码体制的安全性基于椭圆曲线离散对数问题(ECDLP)的难解性.因此,椭圆曲线密码系统的单位比特强度要远高于传统的离散对数系统.因为区块中所有的交易都带有签名,所以签名速度直接影响了系统响应延时和吞吐量.经过对椭圆曲线验签算法的分析,我们提出了用GPU进行硬件加速,实现快速的验签运算的方案.
本文使用Tesla M40加速卡来加速SM2算法的签名验证.Tesla M40为NVIDIA在2015年推出的针对高性能计算领域的通用图形处理(GPGPU),其拥有3 072个处理器核心,单精度浮点峰值性能7Tflops.
任何并行系统为了达到最佳性能,程序的并行度都必须大于等于并行系统的物理并行线程数.对于NVIDIA Tesla K40,其拥有3 072个核心,可以同时并行执行3 072个线程,故程序至少应达到3 072的并行度.但对于数字签名的验证与签名等密码学操作,其本身运算量庞大并且难以并行.经过数学变换后可以得到签名操作为6的并行度、签名验证操作为12的并行度.为了完全利用并行系统的性能,需要将多个运算请求打包统一发送同时执行,以平摊并降低单个运算的时间,这个最低的包大小即为
故对于物理并发度为3 072的Tesla K40,最优区块大小为
关于椭圆曲线运算具体理论见文献[20],SM2算法的具体理论见文献[19].Hyperchain以相关理论为基础,对现有的有限域运算和椭圆曲线标量乘法运算进行了优化,实现了基于硬件加速的椭圆曲线加密算法:
· 优化1:提升有限域运算性能
为了提升有限域运算的性能,在工程实现上我们采用了CUDA汇编语言PTX来实现.在算法层次上,我们则提出了一种全新的快速有限域求模运算.
有限域元素Fp在计算机中的表达方式,用整数表达单个域元素需要用 256位,在目前计算机体系结构下,必须使用多个整数来表达一个域元素.根据目前多数CUDA设备的计算能力,32位整数的每位均摊运算性能远高于64位整数[21],故本文采用8个32位整数来表达一个有限域Fp元素:
SM2算法所有的椭圆曲线运算都在Fp中进行,每一步基本运算都需要对p求模.推荐参数中给出的p为:p=0xFFFFFFFEFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF00000000FFFFFFFFFFFFFFFF,p为256位.
直接使用普通的求模运算,开销十分巨大.为了解决这个问题,Hyperchain提出了一种全新的快速求模算法.快速有限域求模运算的推导过程如下:
对p进行变换,得到P=2256-2224-296+264-1,并参考公式(4)得到:
任意ω=χ·(232-1)2224+γ,γ<(232-1)2224,可以使用公式(4.2)得到:
或者是另一种变体:
若ω1仍然超出了(232-1)2224,再次使用公式(4.3)或公式(4.4)即可.
算法1. 快速有限域求模运算.
输入:标量ω;
输出:标量ω′<(232-1)·2224,且ω′≡ωmodp.
1. 当ω>(232-1)·2224,执行循环:
2. 求得γ,x满足ω=x·(232-1)·2224+γ
3. 令ω=γ+x·(232-1)·264+x
4. 输出结果ω′=ω
· 优化2:以并行方式实现椭圆曲线标量乘法运算
椭圆曲线标量乘法很难直接并行,且包含除法等在 256位有限域内开销极大的运算.Hyperchain拟采用Ficher等人在文献[22]中提出的方法,使用Montgomery阶梯算法将一次椭圆曲线数乘运算分解成256次加法与加倍运算的迭代,通过将椭圆曲线点坐标投影到仿射坐标系,以变换每次加法与加倍运算,进而消除除法运算,只留下加法与乘法运算,从而可以并行化实现椭圆曲线标量乘法运算.
算法2. Montgomery阶梯算法.
输入:标量K,曲线C上的点P;
输出:椭圆曲线标量乘法的结果K×P.
1. 令P1=P,P2=2P
2. 令i从n-2到0循环,n为K的位长
3. 如果K的第i个二进制位为1
4. 那么令P1=P1+P2,P2=2P2
5. 否则,P2=P1+P2,P1=2P1
6. 输出结果P1
Montgomery阶梯算法拥有一个重要的特殊性质,它保证了任何点加与倍操作时,操作数P1,P2间的差值始终为P.而这一重要的性质将允许椭圆曲线点加与倍操作能被并行执行.至此,对椭圆曲线标量乘法的运算已被归约为并行快速地完成椭圆曲线点加与加倍运算.
· 并行椭圆曲线点加与加倍算法
首先对椭圆曲线上的点进行仿射变换,将点P=(x,y)变换成
参见文献[22],点加公式可以被变形为P=(Px,Pz),Q=(Qx,Qz)为两个点,那么:
由此可见:原椭圆曲线运算的加法运算[20]中不可被并行化并包含除法运算的操作,被变形为了可以被并行化并且只有有限域加法与乘法运算的形式.综上,我们得出了并行的椭圆曲线标量乘法算法.
3 实验结果与分析
本节通过多个对比实验来验证优化策略对系统性能提升的有效性.下文中,第 3.1节详细介绍了本次实验的具体配置和指标,第3.2节~第3.4节分别是关于业务逻辑与共识分离、存储优化和数字签名等优化策略对性能影响的对比实验,第3.5节~第3.9节展示和分析了节点数、打包时间、区块大小、网络延迟和带宽等因素对联盟链性能的影响.
3.1 实验设置
3.1.1 集群环境
(1) 客户端节点配置(见表2);
(2) Hyperchain节点配置:本次实验将采用腾讯的云服务器,根据不同场景,实验会采用多种类型的服务器,具体配置如下.
· 配置1:4台服务器,Hyperchain默认记账节点服务器配置.型号:16核32G云服务器(标准型S2,见表3);
· 配置2:大于4台服务器,用于多节点测试.型号:16核16G云服务器(标准型S1,见表4);
· 配置3:用于国密GPU验签测试,型号:CPU 28核56G计算型(GN2).

Table 2 Test environment of the client side表2 客户端测试环境

Table 3 Standard S2 server configuration表3 标准型S2服务器配置

Table 4 Standard S1 server configuration表4 标准型S1服务器配置
3.1.2 网络拓扑图
本次实验的服务器网络拓扑图如图7所示,左边部署了Hyperchain平台节点,右边的客户端节点用于发送交易请求,终端节点用于控制Hyperchain节点和客户端节点.
3.1.3 参数设置
· 记账节点服务器数量:4台(标准型S2);
· 客户端并发度:100×4(4节点,每个节点并发度为100);
· 区块大小(batch size):500;
· 打包时间(batch time):500ms;
· 合并验签数:10.
注:区块打包有两种情况,一种是按时间打包(batch time),一种是按交易数目打包(batch size).
3.1.4 性能指标
本实验拟采用的性能指标包括吞吐量(TPS)和延迟(Latency,默认单位为ms).
(1) 吞吐量计算方式:交易发送完毕后,遍历测试中间三分之一时间区块:
(2)Latency计算方式:遍历测试中间三分之一时间的区块,计算平均时间:
注 1:遍历测试中间三分之一时间的区块是为了统计系统处理能力处于相对稳定状态时的实验数据,避免负载不足对实验结果的影响;
注2:Commit时间为Commit阶段(即共识流程的Commit阶段)写数据的时间.
3.2 业务逻辑和共识分离架构对比实验
本节将分别使用传统共识架构与业务逻辑和共识分离架构来执行系统交易.采用传统共识架构时,我们将使用Hyperchain实现的EVM虚拟机来执行交易.
从表5和表6可知,采用业务逻辑和共识分离架构的Hyperchain平台其系统性能明显提升.系统运行1分钟时,TPS和Latency性能效果分别提升了18.5倍和17倍;系统运行5分钟时,TPS和Latency分别提升了18.7倍和 17.5倍.由此可见,采用业务逻辑和共识分离架构,节点只共识区块链上交易的排序和交易的内容,具体交易交由外部业务系统执行,提升了系统性能.

Table 5 Impacts of separation architecture of business logic and consensus on system throughput表5 业务逻辑和共识分离架构对系统吞吐量的影响

Table 6 Impacts of separation architecture of business logic and consensus on system latency表6 业务逻辑和共识分离架构对系统延迟的影响
3.3 存储优化对比实验
Hyperchain采用区块业务执行和共识分离策略,并使用外部业务系统执行交易,节点不再执行交易,所以数据库只存储区块信息,不再存储交易执行结果的相关数据.本节通过对比存储优化前后系统的 TPS和 Latency,来验证存储优化对系统性能提升的效果.
从表7和表8可知,系统运行1、5、10、15和30分钟时,系统的TPS和Latency较为稳定,并无明显波动.采用存储优化策略后,TPS和Latency的性能效果平均提升了27.3%和28.7%,系统性能得到了较为明显的提升.
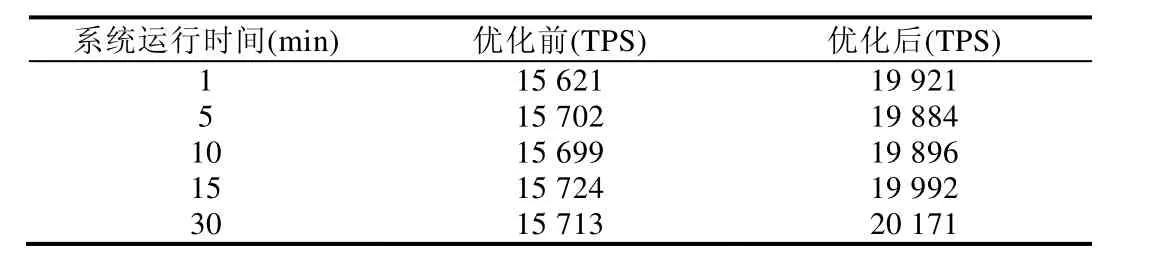
Table 7 Impacts of storage optimization on system throughput表7 存储优化对系统吞吐量的影响

Table 8 Impacts of storage optimization on system latency表8 存储优化对系统延迟的影响
3.4 数字签名验证优化对比实验
3.4.1 多订单打包验签对系统性能的影响
本节我们将改变每个交易包含的订单(order)数量,来验证统一验签功能对系统性能提升的有效性.
每笔交易只包含一个订单(1 order)时,系统的瓶颈在于验签.由表 9可知:每笔交易分别包含 10 order、20 order、30 order进行统一验签时,系统交易的吞吐量逐渐下降.一方面是因为网络带宽的压力增加,转发时间变长;另一方面是因为节点处理 order数增加,反序列化存在内存中更加缓慢.但系统订单的吞吐量在增加,因为验签是系统的瓶颈,打包验签将低了验签的次数.

Table 9 Impacts of multi-order packaging verification on system throughput and latency表9 不同订单数量的打包验签对性能的影响
3.4.2 基于GPU的国密签名对性能的影响
本节对Hyperchain平台实现的CUDA并行版本的SM2算法与GmSSL库进行对比.GmSSL是一套基于OpenSSL使用纯CPU实现的SM系列算法库,是目前工业界常用的SM2算法实现.
测试环境:服务器类型为配置3(GN2),在本次实验中,平台的记账节点是4.
由表10可知,GPU验签的吞吐量是CPU验签的4.5倍左右.由表11可知,GPU验签的延迟时间只有CPU验签的一半.

Table 10 Impacts of GPU Optimization on system throughput表10 GPU优化对系统吞吐量的影响

Table 11 Impacts of GPU optimization on system latency表11 GPU优化对系统延迟的影响
3.5 节点数对系统性能的影响
当节点数量增加,联盟链方案将会导致网络中交易结算时间的延长.本节将测试不同节点数下的系统性能.
在服务器配置2的情况下,由图8和图9可知:随着节点数的增加,系统性能略有提升.这是因为节点数在一定范围内增加时(系统带宽还未成为瓶颈的范围内),发起共识之前的验签压力可以分摊给各个节点,每个节点可以拥有更多的资源用于共识.在 8节点后,系统性能略有下降.这是由于共识节点之间需要相互通信(发送request,pre-prepare等消息),节点数过多后,系统带宽会逐渐成为性能瓶颈.
由于课题经费有限,我们没有测试更多节点的场景.总的来说,从4个节点~10个节点,系统吞吐量变化不大.这是由于此时系统带宽还没碰到瓶颈.
3.6 Batch time对系统性能的影响
在服务器配置1的条件下,由表12可知,区块打包时间对系统性能没有显著影响.
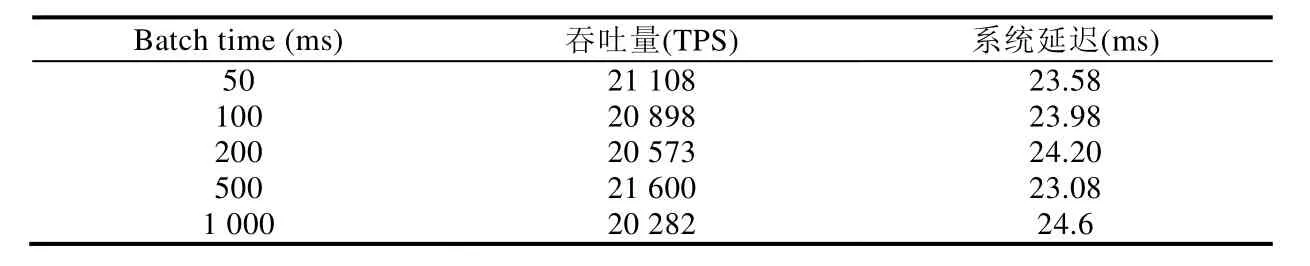
Table 12 Impacts of batch time on system throughput and latency表12 区块打包时间对系统性能的影响
3.7 Batch size对系统性能的影响
在服务器配置1(4节点)的条件下,由图10可知,Batch size小于200后TPS较显著下降.由图11可知,Batch size越大延迟越高.这是因为区块需要在共识节点间进行流转,受网络带宽的限制,造成Batch size越大延迟也越高.选用200~500笔交易作为区块大小为佳.
3.8 网络延迟对系统性能的影响
验证节点之间的距离也会对性能产生影响,物理距离太近使得吞吐量会变得很高,所以我们人为地用LINUX的工具软件增加了网卡延迟.
由表13可知,随着网络延时的提升,系统TPS略有下降,Latency急剧提升.在网络延时大于等于500ms以后,节点间的共识会超时,使交易无法正常执行.
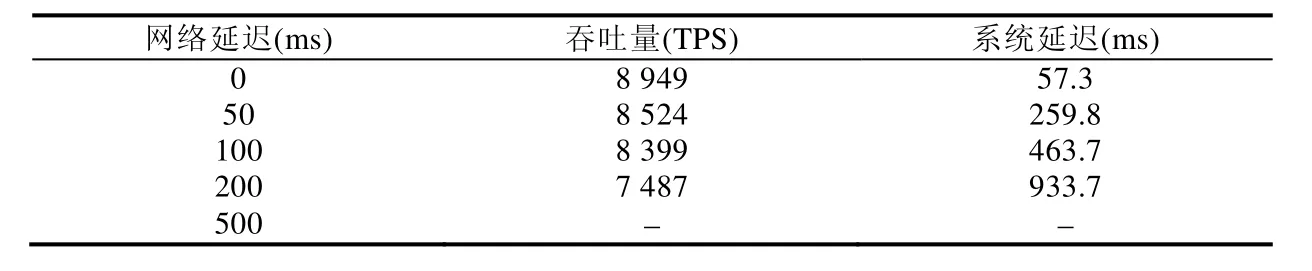
Table 13 Network delays impacts on system throughput and latency表13 网络延迟对系统性能的影响
3.9 带宽对系统性能的影响
在服务器配置1的条件下,由图12可知,带宽对TPS有显著影响.在4节点情况下,10MB带宽仅有642TPS;500MB带宽时,带宽瓶颈不再显著.由图13可知:随着带宽的增加,系统延迟显著减小.目前,网络带宽是限制联盟链吞吐量的最主要因素之一.
4 总结与展望
我们已经研究了联盟区块链技术应用于证券撮合系统的技术难点,并提出了高性能撮合系统解决方案.课题组对接了 Java撮合系统并进行了性能测试、可靠性测试和部分调优等工作.针对证券交易的订单,整个系统的处理速度可以达到20万/s.在不同节点数量、区块大小和网络延迟的条件下,也能保证正确性和较高的性能.
未来我们将继续探索FPGA、微服务架构等技术在区块链领域的相关应用.微服务架构是一个分布式的技术架构,可对应用进行模块拆分,具备敏捷开发、快速演化和弹性伸缩等特性.使用微服务架构可进一步提升联盟链系统性能.目前,我们已经将共识模块和业务逻辑执行模块进行分离,执行过程比较耗时;而共识模块比较稳定,拆分之后的共识模块可不受执行效率的影响.在执行模块中,虚拟机和存储模块也可做进一步拆分.未来还可以使用 FPGA对更多加密算法与其他功能函数进行更高性能的优化.由于密码学模型与电子电路模型的天然相似性以及FPGA模型的流水线并行模式,密码学算法在FPGA上的实现能够轻松地发挥FPGA的全部性能,同时保持足够的并行度.而且FPGA本身的性能上限并不输于CPU与GPU,甚至在整数计算上拥有更强的能力.因此,使用FPGA实现密码学算法能够提升更快的性能.
猜你喜欢
数学杂志(2022年5期)2022-12-02 08:32:10
中学生数理化(高中版.高考数学)(2022年1期)2022-04-26 14:09:30
小学生学习指导(当代教科研)(2021年6期)2021-05-23 13:24:38
中学生数理化(高中版.高二数学)(2021年12期)2021-04-26 07:43:38
马克思主义哲学研究(2020年1期)2020-11-26 07:25:48
数学小灵通(1-2年级)(2020年6期)2020-06-24 05:57:54
人大建设(2019年12期)2019-11-18 12:11:06
中学数学杂志(2019年1期)2019-04-03 00:35:42
中学生数理化·八年级数学人教版(2017年2期)2017-03-25 16:12:51
中学生数理化·七年级数学人教版(2016年9期)2016-12-07 08:18:09
