
一种改进的TLD目标跟踪算法
2019-07-08 00:54胡春海查琳琳
燕山大学学报 2019年3期
胡春海,查琳琳,陈 华
(燕山大学 河北省测试计量技术及仪器重点实验室,河北 秦皇岛 066004)
0 引言
对运动目标的跟踪是视频监控中重要的环节,即在各种情境下对每一帧中运动目标进行快速精准的定位,也是机器视觉方向最活跃的研究领域之一。近年来,目标跟踪技术已广泛应用于智能监控、高级人机交互等领域中,具有很高的商业价值。文献[1]对多种目标跟踪算法进行了对比,在诸多跟踪算法中TLD算法脱颖而出,在照明变化、遮挡等诸多复杂因素影响下,其平均水平被指定为“优秀”,在2016年VOT竞赛中,该算法也取得了相当卓著的研究成果[2]。因此,如何能使优秀的跟踪算法具有更优良的应对能力在当下的研究中仍然具有很重要的意义。
跟踪-学习-检测算法(Tracking-Learning-Detecting,TLD)广泛应用于视频监控的检测和跟踪系统中。在相机抖动、目标被遮挡以及视频序列较长等因素存在时,由于将检测器和跟踪器有机结合,使TLD算法的性能较为突出[3-5]。文献[6]提出一种基于关键特征点检测的改进TLD算法并且引入了在线位置预测机制,提高了跟踪算法的精度;文献[7]中提出Brisk特征点和均匀分布点集代替TLD中均匀分布跟踪点,可以在一定程度上减少跟踪点的数量,保证跟踪的准确性。2011年Rublee等[8]提出了ORB算法(Oriented FAST and Rotated BRIEF,ORB),改善特征点对噪声的敏感程度。在此基础上,文献[9]将ORB特征点应用于检测动态场景下的运动目标,该方法不但提高了检测精度,而且保证了跟踪的实时性,目前用ORB算法对目标进行跟踪的方法较少,较为新颖的论文参考文献[10-11]。
基于ORB算法的优良性能,并且为了增加算法的实际应用,本文对原始TLD目标跟踪进行两点改进:首先,在搭建图像金字塔光流法跟踪模型基础[12]上,利用ORB算法对原算法进行优化,将检测出的目标关键离散特征点代替原始算法网格中待跟踪目标规则特征点,以减少匹配特征点的数量;其次,利用Kalman滤波器对丢失或被遮挡的目标位置预测,进而对预测结果进行跟踪,缩小TLD算法的检测区域。
1 TLD算法原理
TLD算法[3,13]是Kalal Z在2011年提出的一种鲁棒性较强的单一目标跟踪算法。
该算法先将视频输入到并行工作的跟踪和检测模块中,实现对目标的跟踪与检测;其次,学习模块根据跟踪模块的结果对检测模块的样本进行评估,并根据评估结果生成训练样本对检测模块的目标模型和跟踪模块的“关键特征点”进行更新,并及时反馈给并行检测模块和跟踪模块;最后通过综合模块的信息整合,得到目标实时状态,以实现持续跟踪,算法流程如图1所示。
图1 TLD算法流程图
Fig.1 TLD algorithm flow chart
2 改进的TLD目标跟踪算法
TLD是面向任意运动目标开发的一个长期跟踪系统,且在实际跟踪中有着较好的鲁棒性。但由于TLD目标跟踪算法存在对光线变化敏感导致目标漂移、目标旋转致使跟踪失败以及实时性较差等问题。因此在本节中提出了一种改进TLD目标跟踪的算法。
2.1 图像预处理
在TLD算法中,检测模块采用多尺度滑动窗口的方法在原始图像中逐行扫描检测目标存在与否,对于QVGA图像来说,一幅图片的扫描窗口数可以达到5万之多。因此,本文在预处理时,用直方图均衡对图像目标进行增强,与背景形成较大反差;对于背景中有噪声的图像,用中值滤波对噪声进行抑制;在保证图像中的目标区域能识别的情况下,降低图像分辨率[14]。由于每个跟踪窗口中像素量一定,扫描样本的数量可以大大减少。预处理结果对比图如图2所示。
2.2 L-K金字塔光流法
TLD算法跟踪模块中采用L-K光流法(Lucas-Kanade,L-K)。由于光流约束方程不能确定唯一光流,对于跟踪亮度变化大或运动较快的目标会产生跟踪窗口漂移的现象,因此需引入其它约束条件,本文思路是将图像金字塔分层与L-K光流法相结合,其原理如图3所示。

图2 预处理结果与原图像
Fig.2 Preprocessing results and original images
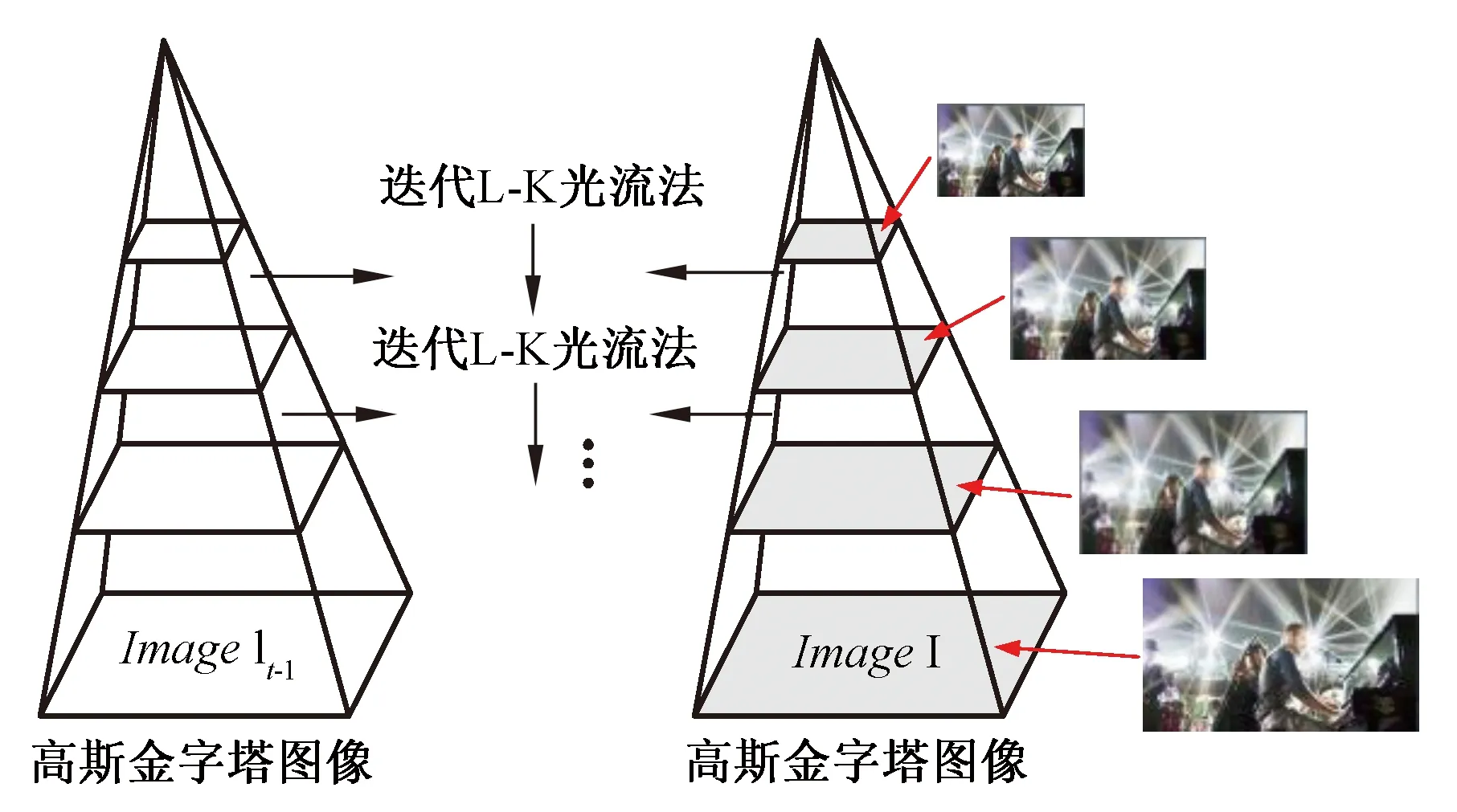
图3 金字塔光流法原理
Fig.3 Schematic diagram of pyramid optical flow method
首先,建立一个图像高斯金字塔,要求是分辨率从上到下逐层减少;通过最小化每个点邻域范围内匹配误差和的方法来得到图像中每个点的光流,如式(1)所示:
ε(d)=ε(dx,dy)=
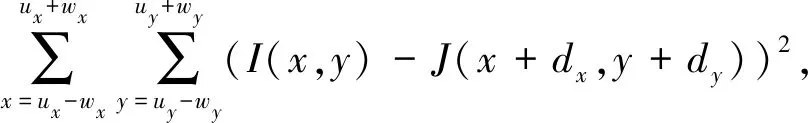
(1)
其中,选取图像I上任意点u=[ux,uy]T,x和y表示该点的两个像素坐标,目标图像在下一帧图像J中的位置v=u+d=[ux+dx,uy+dy]T,矢量d=[dx,dy]T是x处的图像速度,wx和wy为两个整数。
本文中上下层间图像为1/2关系,共分解4层,第0层为原始图像。通过计算上层光流,并对上层光流点进行映射,直到映射到底层的方法,可得该点灰度值:
I(x0,y0)⟹J(x0+dx,y0+dy),
(2)
由此可得,向量d是图像在点(x0,y0)处的位移,也就是像素点(x0,y0)的光流。
金字塔光流法相比于原始光流法的突出特点是,每层光流位移保持很小,将小位移光流向下层映射,直至底层,该方法可以对单层小位移光流进行累积,以便跟踪较大幅度运动。
2.3 结合ORB特征提取的TLD算法
ORB特征点检测算法是在著名的FAST特征检测和BRIEF特征描述子的基础上提出来的,FAST特征点检测算法如图4所示。ORB特征检测具有尺度和旋转不变性,对于噪声及其透视变换也具有不变性。ORB特征检测主要包含方向FAST特征点检测和BRIEF特征描述两个部分。

图4 FAST特征点检测原理
Fig.4 Detection principle of FAST feature points
ORB特征点检测及生成描述子的具体步骤如下:
1) 对提取的FAST角点进行高斯金字塔分层:每层金字塔都会产生若干相关联角点,金字塔共n层,每层搭建一幅图,第s层的规模为scales=Fators,Fator初始规模默认为1.2,将原始图像放在金字塔的底层,则第s层图像大小为
(3)
2) oFast算法计算每个特征点的主方向:图像中某相邻特征点的邻域(p+q)阶距定义为
(4)
其质心位置为
(5)
以选定的特征点为中心,向量的角度(即该特征点的方向)为
(6)
3) 生成BRIEF描述子:将角点附近邻域内部分像素灰度的差通过二进制数字串来描述。定义S×S大小的图像邻域P的测试准则τ为
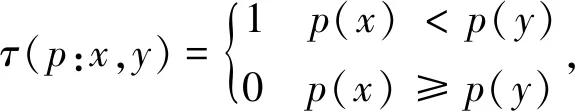
(7)
式中,p(x)是图像邻域P在x=(u,v)T处的灰度值。通过对n个(x,y)点进行灰度比较,生成非1即0的二进制数字串,即
(8)
4) rBrief算法解决旋转不变性:通过灰度差值生成的简单描述子,其本身不具备旋转不变性,可以选择依据角点灰度与质心间建立的向量,给描述子增加具有旋转不变性的方向信息,确定一个2×n的矩阵:
(9)
用(xi,yi)表示任意测试点,通过结合θ(特征点方向)和S0(该特征点的旋转矩阵)对矩阵S加以修正,可以构造出矩阵S的校正版本Sθ=RθS。
可以得到Steered BRIEF描述子:
gn(p,θ)=fn(p)|(xi,yi)∈Sθ。
(10)
5) 为了减少方差的亏损,引入贪婪算法对所有具有高方差又具有非相关性的点进行筛选。
本算法在特征点检测及跟踪部分的改进如下:将TLD目标跟踪窗口内规则特征点Grid清空,采用ORB算法提取该区域内离散特征点,对特征点按相似性聚类后跟踪,可以大大减少扫描窗口的工作量;接下来各帧中,如果局部跟踪器未超出目标圈定的跟踪框,则应用金字塔光流法对当前帧从目标位置进行跟踪,若局部跟踪超出选定跟踪目标框的范围,则利用ORB特征点匹配算法,与上一帧中相应特征点进行匹配,直接定位当前帧中目标尺寸和位置,防止误差累计,以做备用方案,改进后扫描窗口与原算法扫描窗口对比图如图5所示。

图5 改进后扫描窗口对比图
Fig.5 Comparison of improved scan window
2.4 Kalman预测器引入TLD算法
Kalman滤波器[15]是从已知信息开始,获取新的信息,然后根据对已知信息和新信息的确定程度,用新旧信息带权重的结合对已知信息进行更新[15]。
在TLD算法的检测器结构中,输入级联分类器的样本是由扫描框对每一帧图片进行全局扫描产生的,则说明TLD算法并没有确定目标窗口的位置范围,通过Kalman预测器的选用,可以将目标框的范围缩小到TLD的目标待检测区域,解决目标丢失后跟踪失败的问题。
3 实验及结果分析
3.1 实验算法流程
整体算法流程如图6所示,其中图6(a)为本文整体运算流程,图6(b)为改进TLD算法程序,即图6(a)中子模块部分。
主程序中,通过对输入视频中随机目标的选择,对图像序列进行初步处理,结合Kalman预测器对目标大致位置的预测,进入TLD算法的主模块,对目标进行检测和跟踪,并且不断更新模型,若图像序列不是最后一帧,则重复步骤,并输出位置。
对于子程序模块中,跟踪器读取Bounding Box的图像参数后,对ROI区域进行图像增强,图像去噪,降低分辨率等预处理,并重新构建跟踪框内特征点检测机制,结合ORB特征点检测算法,经过聚类后对其进行训练和跟踪,对于不能准确找到目标的图像,采用ORB算法直接进行匹配。
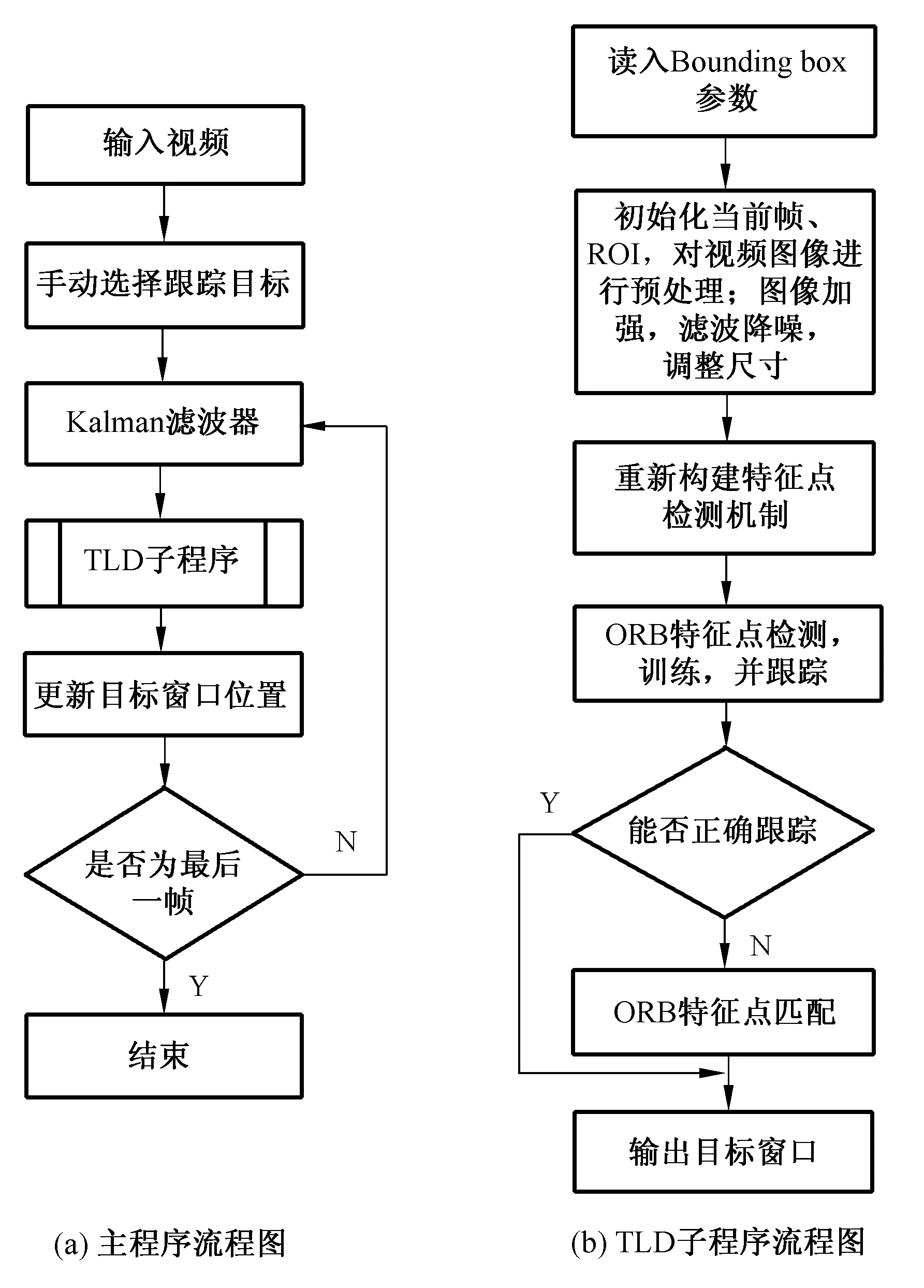
图6 算法整体流程图
Fig.6 Overall flowchart algorithm
3.2 实验环境
为了验证算法的有效性,将改进后的TLD算法(以下简称TLD+)与原始TLD算法以及TLD结合Kalman预测算法(下简称TLD+K)进行比较,采用六组视频进行测试,包括公开的David、David3、Deer、Shaking以及笔者采集的视频car、feet,这些视频主要挑战包括:光照变化,目标运动速度快以及目标消失重现、目标遮挡等情况。实验环境的构建是在Windows 7操作系统下,由Visual Studio 2015 Community集成环境和Intel公司开发的计算机视觉库OpenCV 3.4构成。本文的PC机配置为Intel Core i7-3632QM 3GHz CPU,4GB内存。
3.3 实验结果定性分析
在“David”序列(共770帧,目标存在770帧,分辨率为320×240)中,实验结果如图7所示,视频中目标从光线较暗处走至光线较强处(a)~(c),其中有身体旋转(d)和面部遮挡(f)情况。实验结果表明,本文算法都可正确跟踪光线发生大变化的选定的目标区域。

图7 David序列测试结果
Fig.7 David Sequence test results
在“David 3”序列(共252帧,目标存在250帧,分辨率为640×480)中,实验结果如图8所示,视频中目标先后经过四次粗细不同的遮挡物,当目标进入汽车区域(b),进入复杂背景区域时,容易造成前景背景目标混淆,当目标进入大树区域时,本身目标丢失,但是通过Kalman预测出目标区域(d),且当目标转身后,跟踪还是能正常进行。实验结果表明,本算法可以正常跟踪被短暂遮挡的运动目标。
在“Deer”序列(共71帧,目标存在71帧,分辨率为200×150)中,实验结果如图9所示,视频中目标背景中干扰项较多,且目标运动剧烈,速度较快,在第7~9帧中,目标进行一个急速的轨迹变化,在26~28帧中,目标被遮挡物遮挡且急速运动,虽然检测的特征点发生部分漂移,但是跟踪框仍能正确的预测跟踪轨迹,且在遮挡物消失的时候可以正确跟踪目标。
在“Shaking”序列(共365帧,目标存在365帧,分辨率为624×352)中,实验结果如图10所示,视频中整体光照较为昏暗,目标从遮挡走到前方,过程中有剧烈抖动情况,并且经过一次强光突然照射,在第162帧附近,特征点未进行检测,但是预测器的定位窗口仍然锁定目标,并且在后续帧中仍可继续跟踪。
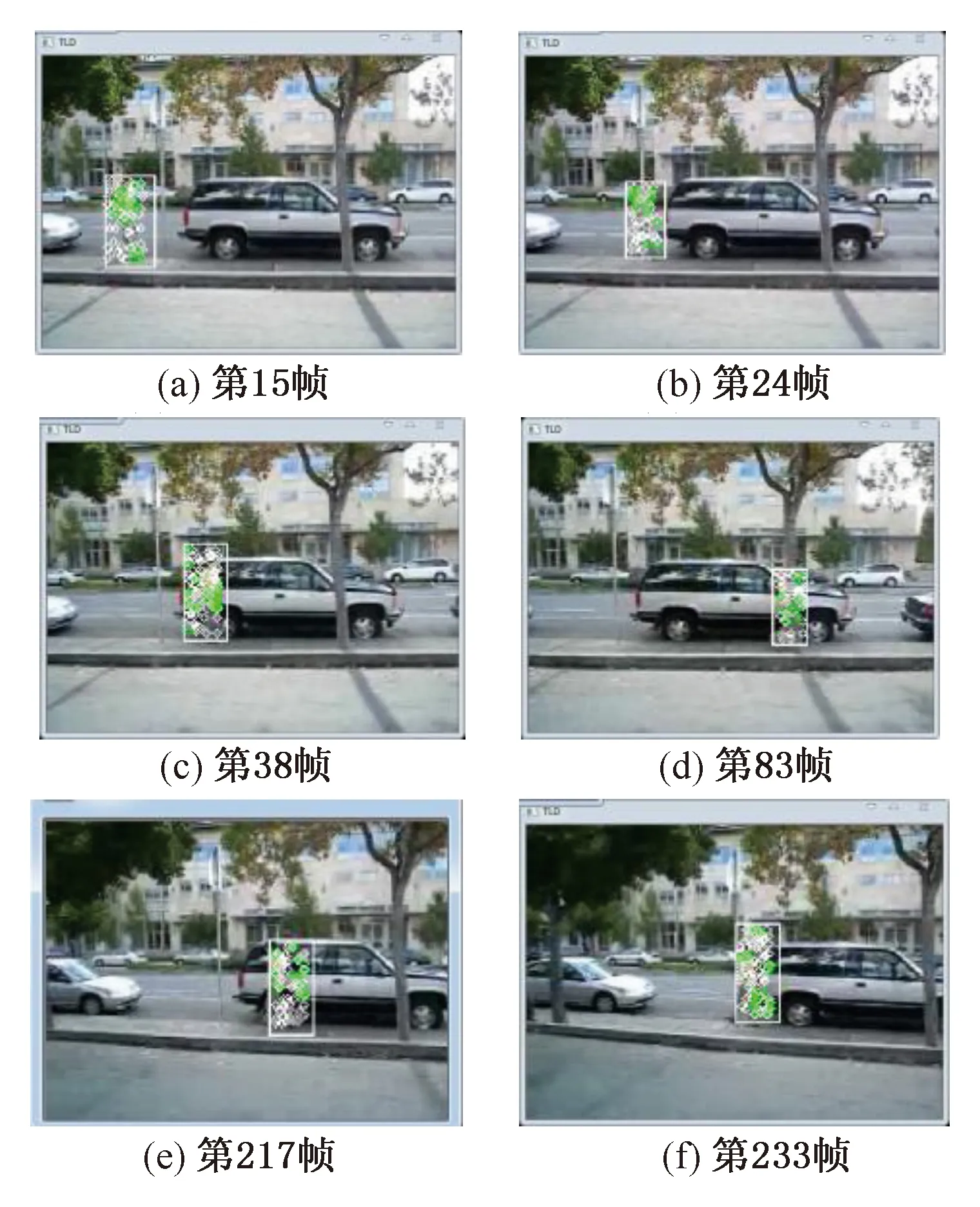
图8 David3序列测试结果
Fig.8 David3 Sequence test results

图9 Deer序列测试结果
Fig.9 Deer Sequence test results
“car”序列(共305帧,分辨率为640×360)中,视频选取自网络中交通路口车辆行驶的情况,场景特点包括:目标选定小,运动速度较快,来往车辆行人较多,实验结果如图11所示。根据实验表明,本方法对目标运动环境复杂且多重遮挡的情况依旧能正确跟踪,尤其是针对交通系统监控中,本算法仍能保持较好的实时性。

图10 Shaking序列测试结果
Fig.10 Shaking Sequence test result

图11 Car序列测试结果
Fig.11 Car Sequence test result
“feet”序列(共101帧,分辨率为1920×1080)中,该跟踪是笔者用手机记录下来的视频,分辨率要大于一般测试视频,特点是视频中存在相似物体,且有光线的变化,实验结果如图12所示,第21帧中左脚搭上右脚,检测到的目标存在于跟踪框的右端,第60帧中右脚搭上左脚,当两脚分开的时候,跟踪框还是能正确跟踪选取的目标,由此可见,对于光线较暗情况下的相似目标,本文算法依旧能正确跟踪。

图12 Feet序列测试结果
Fig.12 Feet Sequence test results
3.4 实验结果定量分析
引入算法准确率和运行速度作为评价指标对算法进行对比分析。实验数据如表1和表2所示。表1给出各个算法对不同视频的处理,能够正确跟踪目标的帧数,结果显示改进的TLD算法与原始TLD以及TLD+K算法相比,正确跟踪的帧数各有高低。
首先对表格中查全率和速度增长率进行介绍,表1中各视频实验结果查全率rR定义为
(13)
其中,numTP表示正确处理帧数,numCP为视频序列总帧数。
表2中各视频跟踪速度增长率gR定义为
(14)
其中,vE表示改进后TLD+算法处理速度,vS表示相应对照算法处理速度。

表1 视频序列跟踪精度实验结果Tab.1 The experiment results of Video sequence tracking accuracy

表2 视频序列跟踪速度实验结果Tab.2 The experiment results of Video sequence tracking speed
对于算法精度来说,由表1可直观地看出:对于原始TLD算法,在6个视频序列中,平均正确处理帧数为263帧,查全率为83.71%,其中在Deer序列中由于遮挡以及背景杂波较多,导致目标窗口漂移,检测到的帧数较低,在Shaking序列中,由于背景较暗,且出现光线强烈变化的情况,使得跟踪窗口多次无法检测到目标;对于TLD+K的算法来说,在预测目标位置的情况下,检测帧数较原始算法有明显提升,平均检测帧数可以达到288.17帧,较TLD算法提升了9.6%;而在TLD+算法中,由于检测模块是通过关键特征点检测,对于背景颜色和纹理较为接近的视频,测试结果不是很理想,但是也趋于平均水平,通过引进预测器,对模糊以及遮挡的目标有了较大的改进,平均正确处理帧数达到了290.33帧,相较于原始TLD算法提高了10.39个百分点。
对于速度的分析,需要对6个样本视频的平均帧率作为参考基础,由表1可直观地看出:原始TLD算法采用逐行扫描方式,对比直接定位的方法来说,速度相对较慢,平均处理速度大约为8.85帧/s,而Kalman预测的引入,可使算法在速度上有一定提高,平均速度可以达到10.94帧/s,较原始算法提高了23.61%,但两种算法对分辨率较高的视频处理速度还是较慢;而改进算法TLD+,对视频先进行预处理,降低了高分辨率视频的分辨率,使光流算法运行的区域范围减少,在特征点检测机制中加入了速度较快的ORB特征点检测,再次提高了算法的处理速度,可以达到平均帧率为13.86帧/s,较原始算法提高了56.61%,较TLD+K算法提高了26.69%。
从表格中可以更直观地比较出本文改进算法相比前两种算法的优势,虽然在精度上只有小幅改善,但在检测和跟踪速率上有着大幅提高。
4 结论
视频跟踪已经成为机器视觉中较为重要的一个部分,各种跟踪场景的复杂程度也越来越考验算法本身的适应能力。本文提出一种ORB算法改进的TLD目标跟踪算法,该方法在TLD算法基础上,通过ORB算法重建检测和跟踪机制,采用金字塔分层的方式对特征点进行跟踪,最后引入Kalman滤波器,对丢失或者被遮挡目标帧间位置进行预测。实验结果表明,所提方法可通过关键特征点对目标进行跟踪,在一定程度上减少了特征点的数量,能有效地应对光线环境较差、运动目标被遮挡等复杂情况,其跟踪结果较为准确且在跟踪速度方面得到了较大的提升,在保证跟踪精度的情况下,使实时性达到原来的1.5倍。但目标在前景背景颜色区分较差的序列中还存在一定问题,这也是下一步研究重点。
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
中学生数理化(高中版.高考理化)(2022年5期)2022-06-01
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
成都信息工程大学学报(2021年3期)2021-11-22
中学生数理化(高中版.高考理化)(2021年5期)2021-07-16
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
初中生世界·七年级(2019年5期)2019-06-22
当代陕西(2019年10期)2019-06-03
中学生数理化·高一版(2016年6期)2016-05-14
意林(2011年10期)2011-05-14
