
视频目标跟踪技术综述
2019-07-08 00:54李均利储诚曦汪鸿年
燕山大学学报 2019年3期
李均利,尹 宽,储诚曦,汪鸿年
(1.四川师范大学 计算机科学学院,四川 成都 610101;2.宁波大学 信息科学与工程学院,浙江 宁波 315211)
0 引言
目标跟踪是在给定的视频序列中,对感兴趣的目标进行检测,并在整个视频序列中对该目标的位置进行实时跟踪,找到目标物体并提取出目标位置后进行进一步的分析应用。跟踪系统通常会给出目标在给定视频序列初始帧中的位置框,根据目标的初始状态进而对其进行跟踪。目标跟踪中主要有以下几个模块:1)目标检测;2)目标分类;3)目标跟踪,如图1所示。目标跟踪在军事领域、视频监控、人机交互和交通监测等领域都发挥着重要的作用[1-2]。在目标跟踪中,由于物体形态的多变性、运动速度过快、光照变化、背景变化以及物体被遮挡或多个目标相互遮挡[3]等复杂情况,目前尚未找到一个鲁棒的算法能够完美地解决这些复杂情形。
经典的目标跟踪方法往往分为基于生成式的跟踪和基于判别式的跟踪。生成式跟踪算法是通过提取目标特征找到能够表征目标的外观模型,利用生成的模型在图像区域进行匹配,找到与其最匹配的区域,即为目标[4];常见的基于生成式的跟踪算法有meanshift[5-6]、粒子滤波[7]、卡尔曼滤波[8]以及基于特征点的光流算法。而在目标跟踪的过程中,经常会有目标特征与背景相似的情况出现,仅仅对跟踪目标进行建模已经不能满足目标跟踪算法的需求。S Avidan[9]提出了基于判别式的目标跟踪算法,把目标跟踪问题转换成为一个对目标和背景进行区分的二分类问题,通过在线或离线学习的检测器对目标和背景进行区分,进而找到目标的位置。判别式算法在跟踪过程中能够很好适应复杂的变化,因此,基于判别式的跟踪逐渐成为主流。

图1 目标跟踪主要模块
Fig.1 Main module of object tracking
Collins和Lin在早期提出过一种基于检测的跟踪(Tracking by detection)[10],也是一种有效的基于判别式的跟踪算法。基于检测的跟踪首先要对目标进行检测,提取出目标物体的几何物理信息后对其进行位置的跟踪,因此,目标检测和目标跟踪通常都会联系在一起出现。典型的基于检测的目标跟踪算法包括基于支持向量机(SVM)[11]的算法,基于随机森林分类器[12]的算法和基于boosting[13-14]的算法。这些算法为了更好的适用于跟踪,都采取了在线学习的策略。为了能够直接预测目标的位置,在基于大量图像特征的情况下,采用了一种Structured Output SVM和Gaussian Kernels策略[15]。
同时,对于不同的应用场景,目标跟踪也有不同的分类:根据跟踪视频背景的不同,可以分为基于静态背景的目标跟踪和基于动态背景的目标跟踪;根据跟踪目标数量的不同,可以分为单目标跟踪和多目标跟踪;根据光照强弱不同,可以分为强光照下目标跟踪和弱光照下目标跟踪;根据是否具有跟踪目标的先验信息,可以分为基于监督学习、基于半监督学习和基于无监督学习[16]的目标跟踪。
推动目标跟踪技术不断向前发展的正是对于其实时性、准确性和健壮性的不断追求,在目前的科学研究和实际应用中,目标跟踪的质量还不能达到我们预期的设想,所以研究人员在不断地改进和寻找新方法来提高目标跟踪的质量。为了获得较好的跟踪效果,在目标跟踪中就需要选择合适的特征和高效的分类器,由于环境的复杂和目标本身的复杂性,有大量的特征可供选择,本文将会介绍几个目标检测中常见的特征,如颜色、纹理和梯度特征[17]。
1 目标跟踪的难点与挑战
用于目标跟踪的视频序列是将3D现实世界投影到2D图像平面上,会有信息损失、噪声以及成像过程中的光照变化、场景变化等影响。目标跟踪面临一系列的挑战,可以将目标跟踪面临的挑战和难点总结为以下十类:1)光照变化;2)遮挡;3)复杂背景影响;4)尺度变化;5)颜色变化;6)目标形变;7)前景/背景变化;8)摄像头角度变化;9)目标身份切换;10)目标消失后重现。
目标跟踪中存在着各种挑战和难点,跟踪技术的发展正是围绕这些挑战和难点而不断展开,使得该领域的研究有着强大的活力,吸引着科研人员不断为之努力,并且不断地推动其向前发展。对于不同的挑战,研究者提出了大量的相关算法。例如Zdenek Kalal将检测器、在线学习机制和跟踪器有机结合在一起,提出一种TLD算法[18],在跟踪目标发生部分遮挡或全遮挡时,TLD也能准确快速地跟踪到目标,并且鲁棒性强;Informatik[19]在TLD的检测器中引入了滑动窗口,对TLD中检测器的方差滤波器、组合分类器和最近邻分类器三个阶段进行了改进,提高了TLD算法的精度;Zhou[20]利用Kalman滤波器对TLD检测器当前帧目标的区域进行预测,再利用马尔科夫模型对目标运动方向进行预测,提高了TLD的跟踪效果。
这些挑战对目标跟踪的效果会产生一定的影响,同时也激发了新方法和新技术的产生,提高了跟踪的适用范围和跟踪精度等。但目前跟踪技术还不能完全解决各种难点和挑战。
2 目标跟踪常用特征
通常,每个目标都具有其独特的特征,在目标检测和跟踪中,通过检测到目标特定的特征即可完成对目标的检测和跟踪。特征的选取对目标跟踪的效果极其重要,若特征选取不当,可能出现跟踪不到目标或者误判目标的情况。以下是目标跟踪中常用特征。
2.1 颜色特征
在对彩色视频图像进行目标跟踪时,通常会选取颜色特征进行目标检测。颜色特征也是目标跟踪中使用最广泛的一种特征。颜色特征受到图像质量、方向、大小、遮挡的影响较小,在图像处理中,有RGB、CMYK、LUV、HSV、HSL等颜色空间表征,但在目标跟踪中,常采用RGB和HSV颜色特征。
RGB颜色空间由红色(R)、绿色(G)、蓝色(B)三个颜色通道组成[21]。对于不同目标的颜色,其R、G、B取不同的值。RGB可以直接、简单地识别出特定的目标,但RGB特征对于光照比较敏感[22],且RGB颜色空间各通道间有一定的相关性,对跟踪效果会有一定影响。HSV[23]空间通过色度(H)、饱和度(S)、亮度(V)来表征图像的颜色特征,并且相互独立,不产生影响,可以处理颜色的相关性,对光照和颜色的处理更加方便,对于光照也具有更强的鲁棒性[24-26]。
2.2 纹理特征
纹理特征是对目标外观的微观变化进行表征的一种特征,可描述目标图像中反复出现的局部模式和排列规则[27]。如局部二值模式(Local Binary Pattern,LBP)[28]是目标跟踪中一种常见的纹理特征算法,其特点是计算简单、表征效果好,在目标检测和人脸识别方面应用广泛。LBP特征首先将图像灰度化,取中心点像素灰度值为阈值,对该像素为中心的领域进行阈值操作,灰度大于中心像素值的点置为1,反之置为0;再将阈值操作后的邻域像素点的二进制数按照顺时针的顺序转化为十进制数,即 LBP 值。基本的LBP编码计算公式为
,
(1)
式中,gc为中心店像素(xc,yc)的灰度值;N为领域像素个数;gp为邻域点p的灰度。
研究表明,纹理特征具有对颜色、亮度不敏感的特点,对噪声有较强的抵抗力,且具有旋转不变性和灰度不变性。
2.3 梯度特征
梯度特征[29]是对视频图像中目标的局部梯度分布进行统计,进而表征物体的外观。目前使用得比较广泛的梯度特征是HOG特征[30]。HOG特征的思想是根据梯度幅值在梯度方向上进行分块统计,利用HOG特征可以很好的表达目标物体的轮廓信息。HOG特征计算公式为
Gx(x,y)=H(x+1,y)-H(x-1,y),
(2)
Gy(x,y)=H(x,y+1)-H(x,y-1),
(3)
式中,Gx(x,y)、Gy(x,y)、H(x,y)分别表示输入图像中像素点(x,y)处的水平方向梯度、垂直方向梯度和像素值,像素点(x,y)处的梯度幅值和梯度方向为
(4)
(5)
梯度特征常用在行人检测中,它对于光照、颜色、目标形变具有较高的鲁棒性,但是无法表达出目标物体准确尺寸、角度。
在目标检测和跟踪中还有诸如光流[31]、轮廓等特征[16],特征的选择对目标检测的质量有着重要的影响,在具体应用中,常常会采取多个特征同时进行检测的方法,在一定程度上会提高目标检测的精度,但是带来的代价是计算开销增大以及实时性会受到一定影响。表1对几个跟踪特征的优缺点进行了对比。

表1 跟踪特征对比Tab.1 Tracking feature comparison
3 目标检测方法
3.1 帧间差分法
连续两帧图像帧之间具有很强的相关性,静止的物体在两帧图像中几乎没有发生变化。因此对两帧进行差分运算时,静止物体的像素灰度值的差值就很小,而运动物体的像素灰度值的差值就有明显变化[32]。帧间差分法[33]就是利用这个原理对目标视频序列进行帧间差分运算,通过与设定阈值进行比较,当差分值大于设定阈值时判定该物体为运动物体,即前景目标;差分值小于设定阈值时判定物体为静止物体,即背景点。帧间差分法计算公式为
D(x,y)=fT(x,y)-fT-1(x,y),
(6)
式中,fT(x,y)表示第T帧像素值,fT-1(x,y)表示第T-1帧像素值,T表示阈值,当D(x,y)比阈值T大时即判定为前景点,反之则为背景点。
帧间差分法方法简单,运算量小,易于实现,适合于动态变化的情况。但其受阈值选取的影响较大,若阈值设置过高,会出现漏检运动物体的情况,若阈值设置过低,可能会误判运动物体,阈值的合理选取非常重要,同时对于运动较慢的情况,帧间差分法效果并不理想。
3.2 背景差分法
背景差分法[34]适合于静态背景的场景。首先提取出目标视频的静态背景图像,然后将当前帧与背景图像进行差分运算,通过与设定的阈值进行比较来判别背景点和运动点[35]。背景差分法的原理是运动的物体与背景的像素差值较大,而静态物体本身就属于背景,差分运算后像素差值差异小。背景差分法计算公式为
D(x,y)=fT(x,y)-fb(x,y),
(7)
其中,fT(x,y)表示当前帧像素值,fb(x,y)表示背景图像像素值,T表示阈值,当D(x,y)的值大于阈值T时则判定为前景点,反之则为背景点。背景差分法适用于静态背景的情况,具有运算量小、易于实现的特点;但是对于场景变化、光照变化等具有很高的敏感性。
3.3 光流法
光流法[36]是对图像中运动物体进行检测的一种重要的方法。光流法的原理是用图像中的光流场来表征图像的运动,这类似于空间中用运动场来表征物体运动;对图像中每个像素点求得其光流矢量,从而来得到图像的运动场,如果图像中不存在运动目标,那么整个图像的光流场应该是连续的;若图像中存在有运动目标,则运动目标的光流矢量与周围背景的运动矢量应该是有显著的不同,通过这种方法,即可检测出图像中的运动目标。
光流法在摄像机运动的情况下也适用,并且可以计算出运动物体的实时速度,但是光流法对光照敏感,若整个图像中无运动物体,而光照发生变化,也可观察到光流,会误判运动物体,而在像素灰度变化较小的区域,则有可能观察不到运动物体。表2总结了几个目标检测方法的特点。
表2 目标检测方法对比
Tab.2 Comparison of object detection methods

优点缺点帧间差分法方法简单,运算量小,适合动态变化对阈值的依赖强背景差分法运算量小,易于实现,适合静态变化对场景变化、光照变化敏感光流法可检测物体运动速度,摄像机运动情况仍适用对光照敏感
4 跟踪方法
4.1 基于特征的跟踪
基于特征的跟踪方法是一种不考虑跟踪目标整体情况,将目标物体的特征点作为跟踪目标的方法。该方法只对从目标物体上提取出来的显著特征进行跟踪,假定目标物体可由一定的特征进行表达,在跟踪过程中,只要跟踪到了该特征即完成了对目标物体的跟踪,在目标被遮挡的情况下有很好的效果。在选取特征时,通常会选取具有平移、旋转、缩放不变性的特征,例如颜色、质心、角点、hu矩等。在实际应用中,可以采用多个特征对同一目标进行表征,效果更佳,例如在红外目标跟踪中,由于红外图像信噪比低、易受背景影响等特点,往往会采用多特征融合[37-38]的方法进行红外目标跟踪,有效地提高了跟踪质量。
基于特征的跟踪算法对目标物体的尺度、形状和光照的变换不敏感;在存在遮挡的情况下,只要有部分特征点可见,即可完成对目标的跟踪。
4.2 基于区域的跟踪
基于区域的跟踪是事先获得包含跟踪目标的区域,通常用一个略大于目标的矩形区域进行表征,也可以用不规则的形状表征;在获得目标区域后,利用跟踪算法对目标进行跟踪。
基于区域的跟踪算法在没有遮挡的情况下能够获得精度较高且稳定的跟踪效果,但是在出现较大遮挡或者目标有较大变形时效果不理想,该算法的计算量大、耗时大,尤其是目标区域设置得过大时耗时尤其严重。
4.3 基于轮廓的跟踪
基于轮廓的跟踪是用一组闭合曲线描述运动目标的方法,该方法通过粗略勾画轮廓,以闭合的轮廓曲线作为匹配模板,在图像中后续帧图像进行目标边缘提取,匹配两个轮廓曲线,以实现跟踪目标。Snake轮廓算法是目前常见的一种基于轮廓跟踪的算法,其原理是利用一条可变形的参数化的曲线来表征运动目标的轮廓,且能动态迭代,实现轮廓跟踪。
基于轮廓的跟踪计算量不大,匹配速度快,准确率也高,但是对于运动目标形变大、存在遮挡情况会使提取的轮廓不精准,影响跟踪效果。
4.4 基于模型的跟踪
基于模型的跟踪[39]需要具有一定的先验信息,利用先验信息对目标进行建模,并在对目标的匹配跟踪过程中不断地更新模型。这种方法对于在运动过程中几乎只发生平移、旋转的刚体来说效果较好,对于在运动中会发生较大形变、存在遮挡的情况则跟踪效果不佳。
基于模型的跟踪算法模型跟踪匹配精度高,受观测视角影响小;但是计算复杂、耗时多,从而导致实时性不高。
4.5 基于稀疏表示的跟踪
受到近年来压缩感知和稀疏表示技术在图像去噪、图像去模糊和图像修复等计算机视觉领域的成功应用的启发,基于稀疏表示的算法在跟踪领域也得到了成功应用。Mei[40]首次提出一种将稀疏表示理论用于跟踪领域的L1范式最小化的目标跟踪算法。该算法思路是在粒子滤波框架下,将一组目标模板和单位模板(单位矩阵的列向量)作为基函数来线性表示每一个候选目标。当候选目标为跟踪结果时,其能够以较低的重构误差仅由基函数中的目标模板进行线性表示而获得,因而基函数中的单位模板在整个线性表示中的系数接近零,在此可以假设线性表示的系数是稀疏的,并可利用 L1 范式最小化求解这些系数。每一个目标候选在粒子滤波下的权重可以计算为使用目标模板和对应的系数重构该目标候选时所得到的重构误差,并将具有最大权重的目标候选取定为跟踪结果。
最常用的算法是利用稀疏表示建模目标的外观,合理地选择目标模板和遮挡模板建模跟踪目标及如何设计快速有效的跟踪算法是这类算法的关键。
4.6 基于贝叶斯滤波的跟踪
贝叶斯滤波(Bayesian Filtering)是在贝叶斯估计理论的基础上提出来的滤波方案[41]。其原理是利用所有已知信息来构造系统状态变量的后验概率密度,即:用系统模型预测状态的先验概率密度,再使用最近的测量值进行修正,得到后验概率密度。比较典型的算法包括卡尔曼滤波(Kalman Filter)和粒子滤波(Partical Filter)。
卡尔曼滤波是一种特殊的贝叶斯滤波,对于估计一个动态系统最优状态适用,在观测到的系统状态参数存在噪声、观测值不准确的情况下,卡尔曼滤波仍然能够实现对状态真实值的最优估计。卡尔曼滤波的基本思路是:首先建立一描述随机动态变量随时间变化的先验模型;然后对随机变量进行实时观测,利用卡尔曼滤波方程组实时获得目标状态基于全局信息的最优估计[8,42],卡尔曼滤波只适用于高斯线性系统。对于非线性系统,人们提出来一种基于蒙特卡罗思想的粒子滤波方法[43-44]。
粒子滤波的基本思想是用一组样本(或称粒子)来近似表示系统的后验概率分布,然后使用这一近似的表示来估计非线性系统的状态[43-45]。利用这种思想,粒子滤波在滤波的过程中可以对任意形式的概率进行处理,解决了卡尔曼滤波只能对线性高斯分布的概率问题适用的局限。表3总结了几个跟踪算法的特点。
5 相关滤波和深度学习的目标跟踪
在目标跟踪过程中存在各种复杂的情况,经典的跟踪算法并不能很好地解决各种复杂情况。在相关滤波(Correlation Filter)和深度学习(Deep Learning)的方法出现后,由于它们具有更高的鲁棒性和解决各种复杂情况的能力,目标跟踪技术领域近年来几乎被相关滤波和深度学习方法所占领,其在目标跟踪中的应用得到了飞速的发展。
5.1 基于相关滤波的目标跟踪
相关滤波在目标跟踪领域的应用开始于2010年,Bolme提出的误差最小平方和滤波器(MOSSE)[46]首次将相关滤波引入到目标跟踪当中,MOSSE通过一个最小平方和滤波器来实现对目标物体的跟踪,取得了很好的效果,之后基于相关滤波的跟踪大都是在此基础上改进的。

表3 跟踪方法对比Tab.3 Comparison of tracking methods
基于相关滤波的目标跟踪框架一般总结为如下几点:
1) 通过在第一帧给定目标位置。
2) 提取的图像块训练得到相关滤波器。对于随后的每一帧,利用从上一帧目标位置区域提取得到的图像块用来进行目标检测。
3) 从原始输入数据中提取图像块的特征,利用余弦窗口进行边缘平滑。
4) 利用离散傅里叶变换进行相关滤波操作。
5) 经过傅里叶变换后可得到置信图,其中具有最大响应的位置就是跟踪目标的位置。
6) 提取该位置目标外观,对滤波器进行训练和更新。
基于相关滤波的目标跟踪具有高效率、高鲁棒性的特点,相比于经典的目标跟踪算法性能有大幅提升,很快就广泛运用在了目标跟踪领域,自从MOSSE方法提出后,大量的相关滤波方法也相继提出。Henriques在2010年提出了一种基于检测的核循环结构的CSK[47]算法,Kaihua Zhang在2014年提出了一种利用时空上下文信息进行跟踪的STC[48]算法。Henriques在2014年又提出了一种将核函数引入到跟踪器中的KCF[49]算法,在当时获得了极大的关注;除此之外,大量的相关滤波算法如Danelljan的CN[50]、DSST[51],Zhang的STC[52],Ma的LCT[53]等算法在不同程度上对相关滤波算法做出了改进,取得了不错的效果,使得基于相关滤波的跟踪算法不断地在向前发展。
在基于相关滤波的跟踪中,值得一提的是C-COT[54]算法和ECO[55]算法,它们都是由Danelljan团队提出的,其中C-COT算法在VOT2016中取得了排名第一的好成绩。传统的相关滤波跟踪模型多采用单一分辨率的手工特征或CNN特征,但由于目标尺度变化等因素影响,单一分辨率特征输出结果可能会存在扰动,影响跟踪效果。C-COT使用深度神经网络VGG-Net提取特征,通过立方插值,将不同分辨率的特征图插值到连续空间域,再应用Hessian矩阵求得亚像素精度的目标位置。C-COT的核心过程可以总结为:1)对于跟踪目标,利用VGG-Net提取不同分辨率的特征,如图2(a);2)利用训练得到的多个连续卷积操作滤波器分别对特征图进行卷积运算,如图2(b);3)经过步骤2)后得到响应图,如图2(c);4)将图2(c)的响应图进行加权平均,得到多个分辨率置信度之和,即为最终的置信图,置信图极大值的位置即为目标预测位置,如图2(d)。
ECO算法是Dnelljan在其C-COT算法的基础上进行改进而成的,对于影响相关滤波跟踪算法效率和导致过拟合情况的3个主要因素:模型大小、训练集大小和模型更新策略,ECO算法提出了3个对应的解决措施。对于模型大小,ECO提出了对卷积操作进行因式分解(Factorized Convolution Operator)的办法,通过提取特征子集进行降维,从而减少模型参数;对于训练集冗余的问题,提出了生成样本空间模型(Generative Sample Space Model)的策略,将类似的样本归并到一个Component,训练样本从多个Component中选择;在模型更新策略选择上,ECO选择了一种稀疏更新的策略,摒弃了在每一帧中进行更新的办法,将更新间隔设置为6,有效避免了模型漂移问题。ECO创新性的改进使其获得了更加优秀的跟踪效果,目前为止ECO在相关滤波跟踪算法中仍处于领先地位。
图2 C-COT主要结构
Fig.2 Main structure of C-COT
5.2 基于深度学习的目标跟踪
深度学习近年来是计算机科学的一个研究热点,作为机器学习的一个新的研究方向,在人工智能领域的许多问题上都有较大突破。在计算机视觉、自然语言处理、音视频处理等领域都有所应用且取得了很好的效果。
深度学习的概念是来源于对人工神经网络的研究,是大数据时代对神经网络的一种新的发展。1988年Rumelhart、Hinton和Williams提出了基于反向传播的神经网络算法(BP)[56],但这个网络在随着层数增加会出现过拟合或者陷入局部最小现象,此后神经网络的研究进展相对比较缓慢,直到2006年,Hinton在国际顶尖学术刊物《Science》发表了他在深度置信网络领域的研究成果[57],首次提出了深度网络与深度学习的概念,至此深度学习的研究逐渐开始火热起来,很快在学术界和工业界都变得如火如荼,不断地取得显著的成果。
科研人员在2011年将深度学习技术应用在语音识别问题上,将其准确率提高了20%~30%,取得了突破性的进展[58],仅一年后,研究人员又将基于卷积神经网络的深度学习技术使用在大规模图像分类问题上,性能上取得了很大的突破[59];鉴于此,国内外科研工作者开始尝试将深度学习技术引入目标检测[60-61]和视频分类[62-63]领域,最终也取得了显著的效果。
深度学习技术首次运用在目标跟踪领域是在2013年,由王乃岩提出的DLT[64]算法表明了深度学习技术在目标跟踪中能够取得比传统方法更加准确的效果。由于深度学习在训练阶段需要大量样本,而在目标跟踪过程中仅仅提供第一帧中的bounding-box数据作为训练数据,样本严重不足,DLT算法突破性地采用了“离线预训练+在线微调”的策略,即先使用栈式降噪自编码器(SDAE)在大规模的自然图像数据集上进行无监督预训练来获得通用的物体表征能力,预训练的网络结构如图3(b)所示,一共堆叠了4个降噪自编码器,降噪自编码器对输入加入噪声,通过重构出无噪声的原图来获得更鲁棒的特征表达能力。然后在跟踪过程中根据跟踪物体的情况进行微调,从而解决了训练样本的缺失问题,在线跟踪部分结构如图3(c)所示,取离线SDAE的encoding部分叠加sigmoid分类层组成了分类网络,利用第一帧获取正负样本,对分类网络进行微调获得对当前跟踪目标和背景更有针对性的分类网络。在跟踪过程中,对当前帧采用粒子滤波(particle filter)的方式提取一批候选的patch,这些patch输入分类网络中,置信度最高的成为最终的预测目标。DLT算法在CVPR2013中的29个跟踪器中排名第五,自此深度学习在目标跟踪领域中的应用拉开了大幕,此后越来越多的深度神经网络模型例如自动编码机(ADE)[65]、卷积神经网络(CNN)[66]、循环神经网络(RNN)[67]等都开始在目标跟踪领域崭露头角,并取得了不错的效果。

图3 DLT主要结构
Fig.3 Mainstructure of C-COT
DLT算法在离线预训练阶段的训练目标是图片重构,这与在线跟踪要区分目标和背景的需求相差较大,H Nam在2016年使用针对分类的卷积神经网络提出了一种MDNet[68]算法,提出了分域训练,针对每一类目标单独构建一个用于对应类别进行二分类的全连接层。王乃岩在2015年也对他的DLT算法提出了一种改进的SO-DLT[69]算法,这是Large-Scale CNN网络在目标跟踪中的一次成功应用;同年,Wang也将CNN特征应用在物体跟踪中,提出了FCNT[70]算法;C Ma[71]等人提出了一种将深度学习与相关滤波结合的目标跟踪方法,也取得了显著的效果;David[72]在2016年提出一个深度学习框架,第一次将基于深度学习的目标跟踪做到了100 fps以上,Chu[73]等人在2017年提出一个基于CNN的多目标跟踪框架,取得了很好的效果;Huang等人也提出了一种只在经历外观变化较大情况下才利用深度特征进行定位而通常情况下只利用简单特征进行定位的EAST[74]算法,在一定程度上减少了计算量,提高了算法的实时性。A He[75]等人在Luca Bertinetto的SiamFC算法基础上,将图像分类任务中的语义特征与相似度匹配任务中的外观特征互补结合,提高了跟踪的效果;J Choi[76]等人提出了一种训练了多个自编码器来进行数据压缩的算法,提高了算法的鲁棒性,且跟踪速度也令人十分满意。
随着神经网络研究的深入,目标跟踪的效果也得到了极大的提升,但其需要大量的训练数据作为支撑,通常在目标跟踪中数据存在两个问题:1)每一帧中正样本高度重叠,它们无法捕获物体丰富的变化表征;2)正负样本之间存在严重的不均衡分布的问题;Y Song等人提出了一种VITAL[77]算法,利用生成对抗网络(GAN)在特征空间进行正样本扩增,使其能够捕获目标物体在一定时间范围内的外观变化,获得更加鲁棒的跟踪效果;对于正负样本不均衡的问题,提出了一个高阶敏感损失来减小简单负样本对于分类器训练的影响。VITAL核心结构如图4所示,在最后一层卷积层和全连接层之间加入GAN,用来生成不同时序的一系列mask,作用在特征上可以获得不同外观变化的特征,mask的学习是通过选择masks中loss最大的作为最终mask,这样可以降低具有判别力特征的影响从而获得鲁棒的效果。
从2015年以来的三年,深度学习在目标跟踪中掀起了一场热潮,大量基于深度学习的目标跟踪方法不断地提出,ICCV、ECCV、CVPR三大计算机视觉顶级会议中目标跟踪领域的论文呈现出了被深度学习占领的趋势,深度学习在目标跟踪中带来了极大的突破,其强大的特征表达能力可以自动学习到反映目标的良好特征,而不再需要耗时耗力的进行手工设计,在跟踪精度方面也有显著提高。然而其仍然有一系列问题存在,例如在训练阶段缺少数据,深度学习模型在训练时需要大量的数据,而在目标跟踪中训练的数据往往只有第一帧中提供的bounding-box作为训练数据,数据的量级最多也就只有几百个,远不满足深度学习数据量级;其次就是深度学习模型难以满足目标跟踪的实时性要求,目标跟踪对实时性的期待极高,深度学习模型由于其规模庞大的深度网络,在计算上带来了很大的开销,运算的速度难以达到目标跟踪的要求,且深度学习模型对硬件(如GPU)也有一定的要求。所以深度学习在目标跟踪中的应用也并不是一帆风顺,还有一系列的问题需要去解决。纵观目前深度学习在目标跟踪中带来的显著提升,其依然是一个令人有所期待的发展趋势,也有显著的研究空间。
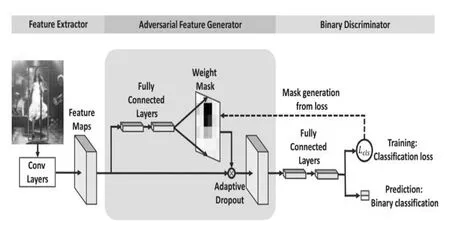
图4 VITAL主要结构
Fig.4 Main structure of VITAL
6 结束语
本文概述了目标跟踪的发展、技术流程以及常用的技术方法。目前目标跟踪技术的发展中,现有的传统方法已经不能很好地适用于当前需求。由于现实生活中,跟踪目标自身形态的变化、运动的复杂,背景环境的复杂,各种遮挡现象的存在以及在多目标跟踪中各个目标之间的相互遮挡等等复杂的情况,一个能够适应各种复杂情况的跟踪算法亟待提出,当前存在的各种算法大多只在特定的环境条件下能够发挥出理想的效果,目前所提各种方法是在理想实验环境中获得的,应用于工业生产还有一段很长的路。目前目标跟踪的发展方向是朝着设计一种能够自动提取目标特征、自动检测运动目标、自动跟踪运动目标并能够对跟踪目标的信息及行为进行一定的预测分析的跟踪器所进行的。
当前基于相关滤波和深度学习的目标跟踪成为了一个研究热点,其不论是在精度或是鲁棒性上,表现都比经典的跟踪方法有显著提升。在最近两年的各类挑战中,基于深度学习和相关滤波的跟踪器表现突出,性能遥遥领先其他算法,但是其仍然还有很长的路要走,其跟踪效果仍然不能够完美地适应各种复杂变化。特征的合理选取、网络结构的合理构造,对于深度学习和相关滤波在目标跟踪中的表现有着极大的影响,在人工智能、机器学习等技术飞速发展的背景下,相信目标跟踪能够从中获得技术上的新突破,并反之能推动其更深入的发展。
猜你喜欢
快乐学习报·教育周刊(2022年16期)2022-05-01
新高考·高三数学(2022年3期)2022-04-28
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年9期)2019-05-30
福建基础教育研究(2019年6期)2019-05-28
科技视界(2018年3期)2018-04-02
少儿科学周刊·儿童版(2015年2期)2015-07-07
科普童话·百科探秘(2015年4期)2015-05-14
中学生数理化·八年级物理人教版(2014年2期)2014-04-02
智慧与创想(2013年3期)2013-05-09
