
基于位置的发布/订阅索引结构
2019-06-25 07:19罗昌银唐玉茹李子蹊李艳红但唐朋
中南民族大学学报(自然科学版) 2019年2期
罗昌银,唐玉茹,李子蹊,李艳红,但唐朋
(1 华中师范大学 计算机学院,武汉 430079;2法国国立应用科学学院 机械系,里昂;3中南民族大学 计算机科学学院,武汉 430074)
随着互联网技术的发展和移动智能终端设备的普及,空间文本数据量以前所未有的速度增长.针对空间文本数据的研究已经成为数据库领域中的一个热门话题[1].传统的发布/订阅方法在处理空间文本数据时效率不高,本文将研究面向空间文本数据的发布/订阅技术,为用户提供更加灵活、高效的订阅方法.
在发布/订阅系统中存在两个主体:发布者与订阅者.发布者发布新消息,订阅者(用户)订阅他们感兴趣的消息[2].当新消息到来时立刻执行消息与订阅的匹配工作.如果两者完全匹配,则消息被发送给订阅者[3].基于位置的发布/订阅在现实生活中有很多的应用,比如武汉万达电影院发布的信息{(电影名:忠犬八公),(票价:31元),(地点:武汉万达影院)},人们可以根据空间与文本信息选择电影院.Flickr上的照片除了有空间信息和文本信息,每一张照片还有视图数量、评论数等数字属性,人们可根据空间和文本信息来选择他们所需的照片.
由于移动设备产生的数据具有各式各样的大量属性,为了更好地处理空间文本数据,本文使用布尔表达式表示空间文本对象的文本属性.相比于空间关键词,布尔表达式能够表达丰富的空间文本信息及其属性范围,还能更加灵活地表达用户的查询[4].空间文本对象中的文本由多个谓词表示,其中每个谓词都包括属性名、关系操作符和属性值,而消息由属性值对组成.只有消息中所有属性都出现在订阅中且各个属性值都在订阅相应属性值的范围内,消息与订阅才完全匹配.此时可以将消息发送给订阅者.
1 相关定义与问题分析
基于位置的发布/订阅中,订阅者使用布尔表达式表示自己的兴趣偏好,发布者发布的消息也以布尔表达式的形式表示.基于位置的发布/订阅不仅能够匹配消息与订阅的空间信息,还能够匹配文本信息,从而得到符合用户需求的消息[5].以下面是文中使用的相关定义.
定义1谓词.谓词是一个三元组,定义为P=(A,oper,value),其中A表示属性名,oper表示操作符,可以是>,<,= 等.value表示属性值. 为了评判x值是否满足谓词约束,可以通过下式进行判定[6].如果给定的值在谓词要求的范围内,则返回1,否则返回0.
P(A,oper,value)(x)→{0,1}.
例如 谓词P=(price,>,80)表示的意思是price>80,则P(90)=1,P(70)=0.
定义2订阅.订阅由多个谓词与一个最小边界矩形表示,即S={P1,…,Pn;R},其中P1,…,Pn是订阅S中的谓词列表,表示用户的兴趣偏好.R表示最小边界矩形,表示用户感兴趣的位置范围.
例如 订阅{(price,>,100),(price,<,400), (name,=,bicycle);R1}的具体含义是在R1范围内找到价格在100~400元之间的自行车.
定义3消息.消息由多个谓词与边界矩形表示,即E={P1,…,Pn;R},其中各个符号的含义与订阅中符号的含义相同.
例如 消息{(price,=,350),(name,=,bicycle);R2}的含义是消息在R2位置内并且具有的文本属性是价格等于350元的自行车.
定义4匹配.基于位置的发布/订阅进行消息与订阅的匹配时,需要满足空间约束与文本约束.
空间约束;消息E与订阅S具有重叠的空间,即S.R∩E.R∅.
文本约束;消息E中的谓词属性全部出现在订阅S中,即 ∀p∃q(p∈S∧q∈E→p.A=q.A∧p(q.oper) = 1 ).
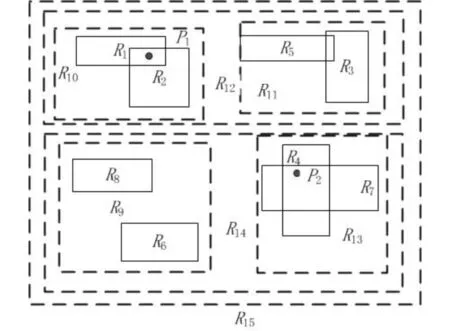
图1 订阅集合Fig.1 Collection of subscriptions
由以上定义可知,消息E的最小边界矩形与S的最小边界矩形重叠,则E与S空间信息匹配.消息E的属性满足订阅S的属性,则文本信息匹配.只有同时满足空间约束与文本约束才可以判定消息E与订阅S匹配.此时,消息E作为匹配结果发送给订阅S.
图1中包含的订阅与消息如下:
S1={(A,=,3),(B,=,3),(C,≥,2);R1},
S2={(A,≥,9),(C,≤,2),(E,≤,9);R2},
S3={(B,≤,2),(E,=,2);R3},
S4={(B,=,3),(E,≥,4);R4},
S5={(C,=,4),(D,=,2),(E,≤,9);R5},
S6={(A,≤,2),(C,≥,2);R6},
S7={(B∈(2,3,5)),(C,=,4);R7},
S8={(B,=,3),(C,≥,2);R8},
E1={(A,=,3),(B,=,3),(C,=,5);P1},
E2={(B,=,3),(C,=,4);P2}.
消息E1与订阅S1,S2重叠,则S1与S2满足空间约束.但是E1中没有属性E,且属性C与属性A不满足S2对应属性值的范围,即E1与S2匹配时不能满足文本约束,因此消息E1不能够与订阅S2匹配.而E1中的属性全部满足S1,且E1中每个属性的属性值都在S1相应属性值的范围内,则E1与S1匹配.
2 索引结构介绍
由于空间文本对象具有空间属性与文本属性,在进行消息与订阅的匹配时,不仅要进行空间修剪,还要进行文本修剪[7].但是由于订阅的数量较多并且消息到来的频率较高,这对基于位置的发布/订阅来说是一个巨大的挑战[8].为了减少消息与订阅匹配过程中产生过多的候选节点,更好地满足用户的需求,避免用户淹没在大量的匹配结果中,本文使用空间约束与文本约束以得到最符合订阅的消息.TR-tree索引结构首先使用空间约束得到一定数量的候选订阅,再使用文本约束进行匹配,最后得到结果,不仅减少了需要匹配的订阅的数量,还高效地进行了匹配工作.
2.1 选择关键属性
随着网上购物的流行,出现了各种各样的商品,且商品具备的属性各不相同,以传统关键词的方式表示文本属性已不能满足需求[9].布尔表达式能够表示结构化、半结构化与非结构化的属性,这样的表示方式比关键词更加灵活,因此本文使用布尔表达式表示消息与订阅的属性.
为了更好地对订阅分组,减少匹配过程中候选订阅的数量,提升消息与订阅的匹配速度,TR-tree索引使用了关键属性.关键属性的选择有以下几种方式:
1)随机选择关键属性.根据订阅中已有的属性值,随机选择多个能够表示全部订阅的属性值作为关键属性.关键属性能够减少候选订阅的数量以加快匹配速度.但是随机选择关键属性存在的缺点是:随机产生的关键属性不能够表示全部订阅;
2)选择出现频率较小的属性作为关键属性.这种方式得到的关键属性可以最大限度地减少候选订阅的数量,但是其缺点与随机选择关键属性一样;
3)选择出现频率较大的属性作为关键属性.这种方式得到的关键属性可以最大程度地保证每个订阅都可以以关键属性的形式表示.因此,本文使用这种方式选择关键属性.例如,根据图1订阅中出现的属性,得到高频率的属性B与C,则每个订阅的关键属性如表1所示.

表1 关键属性Tab.1 Key attributes
2.2 文本索引
文本索引主要分为订阅分组与谓词分组两部分.首先,将所有的订阅根据其包含的谓词数量进行分组得到L(count).然后,根据关键属性A对L(count)再次分组以得到文本索引L(A).文本索引还使用操作符列表存储谓词,为了避免重复存储相同的谓词,文本索引中每个订阅都有一个指向订阅包含的谓词的指针.图1中的订阅包含的谓词数量如表2所示.

表2 谓词数量Tab.2 Number of predicates
根据订阅中包含谓词数量的不同,将所有的订阅分组之后如图2所示.

图2 订阅分组Fig.2 Subscription group
订阅分组之后,再对其进行谓词分组.由表 1 可得订阅的关键属性为C、B.得到的谓词分组如图3所示.
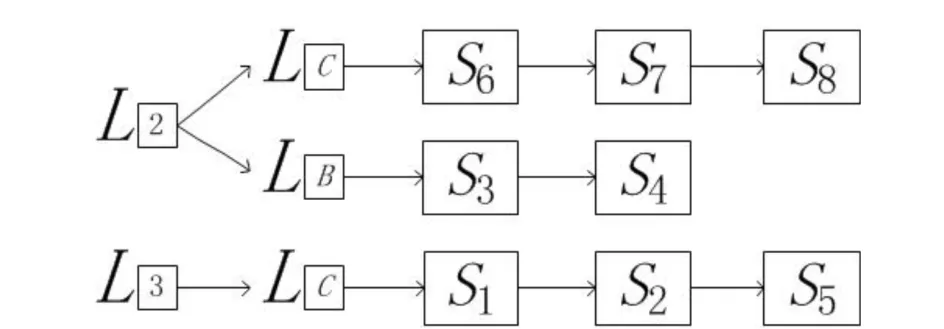
图3 谓词分组Fig.3 Predicates group
2.3 索引结构
CHEN Z等人[10]提出的kdt-tree使用空间关键词表示订阅者的兴趣偏好.但是随着智能手机的广泛使用,消息与订阅中包含的文本信息的种类越来越多,并且各种信息的属性值也有显著的差异,使用关键词的形式表示文本信息已不能满足用户对发布/订阅的需求,人们期待使用更加高效与灵活的方式表示自身的兴趣偏好.为了满足用户对基于位置的发布/订阅的新需求,TR-tree的文本索引结构使用布尔表达式表示用户兴趣偏好.布尔表达式不仅能表示各种类型的信息,还能够更加灵活地展示文本属性. ZHANG D等人[11]研究的索引结构OPindex,构建时间较短并且使用了布尔表达式表示谓词.虽然此索引结构具有高效的文本修剪能力,但是却没有使用空间约束,无法进行空间修剪,更无法对消息与订阅进行空间匹配.为了避免OPindex存在的不足,TR-tree使用了过滤验证的方式实现空间修剪与文本修剪,进而为订阅者筛选出满足空间约束与文本约束的消息.传统的R-tree是针对所有订阅而构建的,当新消息到来时,需要判断所有的节点是否与消息存在空间上的重叠.当新消息到来的频率较快时,消息与订阅的匹配次数显著增加,此时R-tree的空间修剪能力将会显著下降.为了更好地进行消息与订阅的空间匹配,需要对R-tree进行改进,这样才能够较好地展现其空间修剪能力.TR-tree主要包括以布尔表达式表示的文本结构和根据关键谓词与谓词数量构建的空间结构R-tree.文本结构以布尔表达式的形式表示谓词,实现了消息与订阅的文本修剪.为了避免重复存储谓词,文本结构使用操作符列表存储不同的属性值对.R-tree根据消息中关键谓词与谓词的数量进行消息与订阅的空间修剪.
为了更好地展现订阅者的兴趣偏好,并且执行消息与订阅的高效匹配,TR-tree索引结构使用了空间索引与文本索引.其中空间索引R-tree对空间文本对象进行空间修剪.为了减少中间结果的数量,提升匹配效率,R-tree是根据谓词数量与关键谓词构建的.当新消息到来时,根据消息中的关键谓词与谓词数量找到匹配的R-tree以修剪不满足空间约束的订阅.经过空间约束而得到的订阅作为候选订阅再进行文本匹配,在文本匹配的过程中会修剪不满足文本约束的订阅,从而得到匹配结果.文本索引是根据谓词数量与关键谓词对订阅分组的,不仅能加快消息与订阅的匹配,并且为了避免存储重复的谓词,文本索引根据谓词中的操作符建立了不同的列表,从而减少内存空间的使用.
TR-tree索引结构如图4所示,图中L(2)与L(3)是文本索引.R-tree(2,C),R-tree(2,B)与R-tree(3,C)是根据谓词数量与关键谓词建立的空间索引,其结构如图5所示. 而“=”,“≤”,“≥”的列表是存储谓词,这样可以避免重复存储谓词,减少内存的使用.
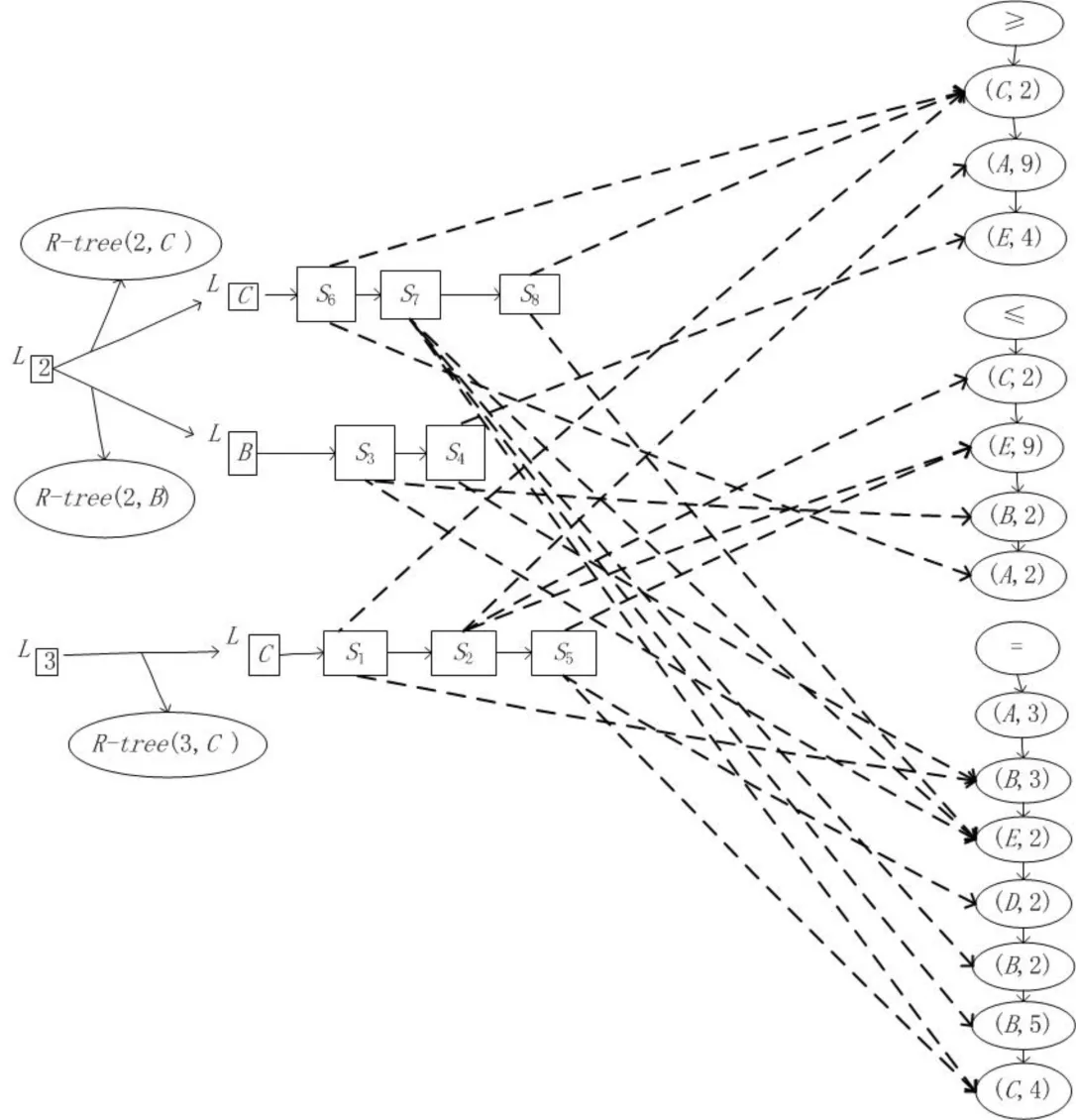
图4 TR-tree结构Fig.4 The structure of TR-tree

图5 R-treeFig.5 R-tree
本文的匹配算法步骤如下:
步骤1 输入消息E,初始化结果集R、候选结果集C;
步骤2 获得消息E的谓词数量m与E中包含的关键谓词keyArr;
步骤3 根据m与keyArr找到空间索引中满足谓词数量为m、关键谓词为keyArr的空间索引结构R-tree(m,keyArr);
步骤4 遍历R-tree(m,keyArr)进行空间修剪,如果满足空间约束,则作为候选节点并加入候选结果集C中;否则订阅被修剪,不再进行文本匹配;
步骤5 逐一对候选结果集C中的订阅进行谓词匹配,找到满足谓词约束的订阅并将其加入结果集R中,否则修剪;
步骤6 得到满足空间约束与文本约束的订阅集R,遍历其中的订阅,将消息E发送给相应的订阅者.
3 实验
3.1 实验环境
实验环境设置为:CPU为Intel Core i5 4200H,内存为 4GB,机械磁盘为1T,操作系统为Windows 10,集成开发环境为Eclipse:Lunna Service Release.
实验的测试数据集有GeneDS与 RealDS,其中GeneDS是通过程序随机产生的数据集,属性与属性值分别使用26个字母与随机数随机生成,位置信息使用4个随机数,这4个随机数分别代表最小边界矩形的4个顶点.RealDS是真实数据集,即基于淘宝的商家信息、Twitter 与 Wikipedia的空间文本数据.其中,每条数据都包括谓词、经度、纬度等信息.从中随机选择5%作为初始化订阅集合,并对相应的属性值加上对应的操作符.
3.2 实验结果
OPindex没有空间索引,不具备空间修剪的性能.TR-tree与OPindex进行了文本索引对比.由图6可知,数据规模较小时,TR-tree的文本索引结构与OPindex的文本修剪能力相差不大甚至相同;但随着数据规模的增加,TR-tree索引结构具备较强的文本修剪能力,能够更好地进行文本匹配.
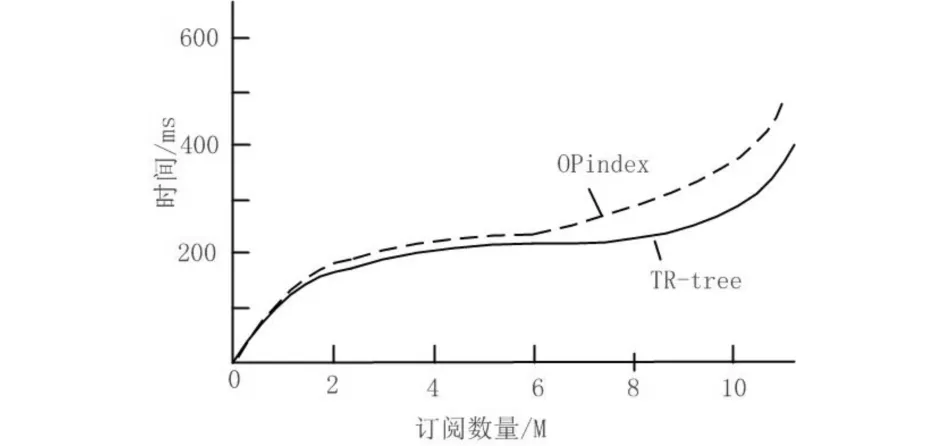
图6 数据规模对处理时间的影响Fig.6 Impact of data-size on processing time
图7 对比了RP-trees[12]与TR-tree的内存消耗.RP-trees与TR-tree都是在内存中进行匹配操作,属于内存驻留索引结构.通过两种索引结构的内存消耗对比可知随着订阅数量的增加,RP-trees的内存消耗显著增加. TR-tree索引结构使用操作符列表实现谓词属性的索引,避免了重复存储谓词,因此内存的消耗比RP-trees少.
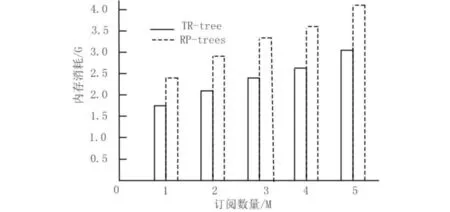
图7 内存消耗Fig.7 Memory consumption
图8 对比了TR-tree与RP-trees的消息与订阅的匹配速度. TR-tree可以实现消息与订阅的高效匹配,即使订阅的数量逐渐增加,其匹配能力远远超过PR-trees. PR-trees之所以需要耗费大量的时间是因为在消息与订阅匹配的过程中需要不断地更新计数数组,而在更新计数数组时需要随机访问整个数组,因此耗费的时间较多.
图9对比了TR-tree与RP-trees随着属性值的增加而产生的内存消耗.两种索引结构都是使用关键谓词对订阅分组.但是随着谓词属性数量的增加,两种索引结构的内存消耗有着显著的差别.随着属性值种类的增加, PR-trees会不断地重复存储谓词包含的属性值,需要消耗较多的内存;而TR-tree使用了操作符列表,避免了重复存储谓词,因此属性的增加并不会对内存产生过多影响.

图8 匹配时间Fig.8 Matching time
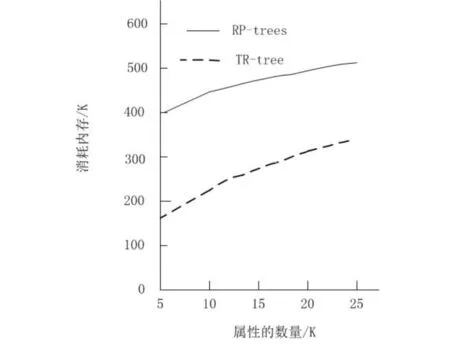
图9 属性值的内存消耗Fig.9 Memory consumption of attribute values
4 结论
通过对空间文本数据的研究,本文针对基于位置的发布/订阅提出具有空间约束与文本约束的索引结构TR-tree.TR-tree包括文本索引与空间索引.文本索引以关键谓词与谓词数量实现订阅的有效分组,并且使用操作符列表存储谓词,减少重复存储谓词的次数,将内存的使用控制在合理的范围内.空间索引根据关键谓词与谓词数量构建不同的R-tree,增强了空间索引的空间修剪能力.实验表明TR-tree索引结构具有较强的匹配能力,并且随着数据量的增加并没有消耗过多的内存.
猜你喜欢
——论胡好对逻辑谓词的误读
现代哲学(2020年5期)2020-11-30
西夏研究(2020年2期)2020-06-01
现代哲学(2019年4期)2019-12-14
电脑报(2019年31期)2019-09-10
当代陕西(2019年13期)2019-08-20
小学阅读指南·低年级版(2017年1期)2017-03-13
电脑爱好者(2015年21期)2015-09-10
人生十六七(2015年6期)2015-02-28
计算机辅助工程(2012年5期)2012-11-21
电脑爱好者(2009年13期)2009-07-07
