
基于机器学习的视频行为动作识别在无纸化考核中的应用
2019-06-20 07:27全美在线北京教育科技股份有限公司朱国平江苏省住房和城乡建设厅执业资格考试与注册中心蒋晓曦徐锋
中国建设信息化 2019年10期
文|全美在线(北京)教育科技股份有限公司 朱国平、江苏省住房和城乡建设厅执业资格考试与注册中心 蒋晓曦 徐锋
【关键字】机器学习;卷积神经网络;视频识别;行为识别;无纸化考核
一、引言
计算机视觉(Computer Vision)是研究计算机如何像人类视觉系统一样,从数字图像或视频中理解其高层内涵的一门学科,简言之就是研究如何让计算机看懂世界,包括对数字图像或视频进行预处理、特征提取、特征分类、分析理解几个过程,将现实世界中的高维数据向低维符号信息的映射,进而触发自主决策。
考试在中国源远流长,而有考试,一般来说,就会有作弊。随着科学技术的逐步发展,基于深度学习的视频行为/动作/物体识别的技术可以在考试中进行应用,通过监控镜头加上运算分析,代替监控人员实时的监督整个考试的过程,对发现的违纪行为、违纪物品进行报警。
本文将探索使用DL 方法解决考试监控视频中行为识别/动作识别的问题。从算法介绍、算法实现、具体应用效果等方面进行阐释。
二、基于卷积神经网络的行为识别算法介绍
针对考场监控场景使用卷积神经网络,需要对监控视频在时间和空间维度都进行多帧连续特征计算,捕捉有效特征。
传统卷积:

表示I 层第j 特征map 的x,y 位置的单元值,其中tanh 为双曲正切函数,bij 为这个特征map 的偏差,
三维卷积:

三维卷积是多个连续的帧组成一个立方体,使用三维卷积核卷积。采用多种卷积核,提取多种特征,捕获动作信息。

网络结构:
使用7 帧 60x40 大小帧序列作为输入,第一层为硬编码的卷积核,然后进行两次卷积和下采样,最后得到一个128 维的特征集合。

在这里,我们采用一个线性分类器来对这128 维的特征向量进行分类,实现行为识别。模型中所有可训练的参数都是随机初始化的,然后通过在线BP 算法进行训练。
三、监控中的人体动作识别的过程
1.系统将考生人体骨骼向量化。

(1)以w*h 大小的彩色图像作为输入 ;
(2)经过VGG 的前10 层网络得到一个特征度F ;
(3)网络分成两个循环分支,一个分支用于预测置信图S:关键点(人体关节),一个分支用于预测L:像素点在骨架中的走向(肢体) ;
(4)第一个循环分支以特征图F 作为输入,得到一组S1,L1 ;
(5)之后的分支分别以上一个分支的输出St-1,Lt-1 和特征图F 作为输入 ;
(6)网络最终输出S,L ;

(7)损失函数计算S,L 的预测值与groundtruth(S*,L*)之间的L2 范数;

2.关键点检测(关节) 计算方法:
(1)通过第k 个人的两个关建点Xj1,k,Xj2,k 之间任意像素p 的单位向量计算L 的groundtruth(Lc*)//其中k 表示第k 个人,j1 和j2 表示两个能够相连的关节(例如手肘和手腕直间通过手臂相连),c 表示第c 种肢体。

计算方法:计算图像中第k 个人的关键点Xj1,k 指向Xj2,k 的单位向量Lc,k*(P)=v(v 大小和方向固定)。
其中像素P 是否落在肢体上需要满足两个条件
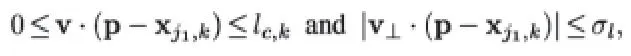
每张图像中第c 中肢体的Lc*,为k 个人在位置p 的向量平均值

(2)评估两个关键点之间的相关性。
关键点dj1,dj2 和PAF 已知之后,计算两个关键点连线向量和两关键点连线上各像素的PAF 向量之间的点积的积分作为两个关键点之间的相关性。

3.多人检测:
关键点和关键点之间的相关性PAF 已知,将关键点作为图的顶点,将关键点之间的相关性PAF 看为图的边权,则将多人检测问题转化为二分图匹配问题,并用匈牙利算法求得相连关键点最优匹配。

Dj1,Dj2 是两种关节的集合,Zc 是第c 种肢体的集合,Emn 是两种关键点之间的相关性,求最优的zc 集合。
最终通过系统反应出考生人体结构,并对其具体是否违规予以判别。
四、算法应用示例
如下图所示,我们通过对考场内监控视频进行了计算机化的图像识别。通过训练,系统能够自动识别视频中的人体与物品,同时对视频内的多个人体进行识别:

在人体有明显动作违规行为时,能够进行自动判定。

下一步,系统将在如下几方面深入开展研究:
1.结合移动网络通信和云计算技术,创建在不同终端(PC、手持设备、车载设备等)下的视频识别方案,着眼实时的可视化、数据化考核管理研究。
2.进一步深化动态数据分析模型,采取合理的数据挖掘技术辅助决策工作;同时实时通过系统数据分析决策过程的实施情况,利用数据对决策结果进行监控,为制定政策、形势预判提供有力的技术支撑。
3.对考生的在考试监控中的行为动作和物别识别进一步优化,为后续建立全面无人值守考场夯实基础。
猜你喜欢
建材发展导向(2022年3期)2022-04-19
黑龙江大学自然科学学报(2022年1期)2022-03-29
计算机系统应用(2021年10期)2022-01-06
今日农业(2021年8期)2021-11-28
北京航空航天大学学报(2021年9期)2021-11-02
建材发展导向(2021年11期)2021-07-28
电子制作(2019年13期)2020-01-14
学生天地(2019年28期)2019-08-25
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
