
基于便携式近红外光谱仪的大豆蛋白波长优选
2019-06-18 08:31
分析仪器 2019年3期
(1.江苏大学食品与生物工程学院,镇江 212013;2. 无锡迅杰光远科技有限公司,无锡 214028;3.江苏大学机械工程学院,镇江 212013)
大豆作为我国主要的经济农作物,具有分布范围广,营养价值高,小规模种植为主的特点。其种植特点对大豆的现场收购造成一定的难度。目前市场上大豆收购价格的定价主要依据是大豆的粗蛋白含量,对于小型的大豆收购商及豆农,传统的经验判断缺乏公信力,很难让别人信服;而凯氏定氮法等理化方法存在操作复杂,检测所需时间长,以及存在人为因素干扰等问题[1]。
近红外光谱法作为一种快速检测方法,依据信息来自于含氢基团C-H、O-H、N-H基频振动的倍频和组合频,具有采样速度快、操作简单的特点,已成为农产品无损检测的主要手段之一[2]。基于MEMS技术的便携式近红外光谱仪,具有体积小,抗震,准确性好的特点,近年来在现场分析检测领域得到了广泛的应用[3]。但近红外光谱谱峰宽且重叠严重,光谱的解释性较差,需要借助化学计量学方法才能进行定量分析。偏最小二乘(Partial least squares, PLS)虽具有良好的抗干扰能力,可全光谱参与校正模型的建立[4],但光谱中的噪声信号以及沉余信息很容易扩大其估计方差,降低校正模型的精度和稳定性[5]。
特征波长优选可以剔除噪声过大的谱区,减少波长变量,提高测量速度;通过剔除线性模型下相关性很小的变量,得到稳健性好、预测能力强的校正模型[6]。目前,常用的波长选择方法主要有相关系数法(Correlation Coefficients, CC)、无信息变量消除(Elimination of Uninformative Variables, UVE)、连续投影算法(Successive Projections Algorithm, SPA)、遗传算法(Genetic Algorithms, GA)[7]、竞争性自适应权重取样法(Competitive Adaptive Reweighted Sampling, CARS)[8]和后向间隔偏最小二乘(Backwards interval PLS , BiPLS)方法[9]等。本文介绍了基于IAS-2000便携式谷物分析仪的大豆籽粒漫反射近红外光谱,利用竞争性自适应权重取样法(CARS)优选出与粗蛋白含量相关的特征变量来建立PLS模型,并与其他光谱预处理方法的校正模型进行了比较。
1 试验部分
1.1 测试仪器与参数确定
近红外光谱仪器:试验采用IAS-2000型便携式谷物分析仪,如图1所示,仪器采用上照式漫反射检测模式。该仪器是基于MEMS技术的可编程固定光栅近红外光谱仪,核心部件为线性扫描的数字微镜器件(Digital Micro-mirror Device, DMD),使用铟镓砷(InGaAs)单点探测器,仪器的工作光谱范围900 nm ~1700nm,原始采样点 256个,经插值处理,波长间隔为1nm ,共801个波长点,光谱分辨率 12.87nm,仪器的光路结构如图1(B)所示。
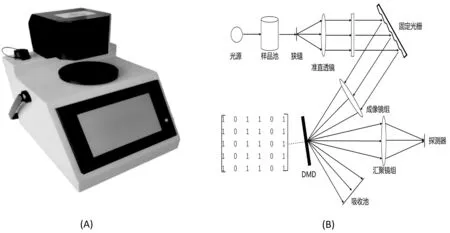
图1 IAS-2000便携式谷物分析仪(A).仪器外形;(B).仪器内部的光路结构
1.2 样品来源与大豆粗蛋白含量测定
试验所用的大豆样品来自黑龙江地区总计239个独立样本。样品的光谱扫描在25°C条件下进行。大豆粗蛋白的测定依据国标GB/T 5511—2018《谷物和豆类氮含量测定和粗蛋白质含量计算凯氏法》,使用K1100Q半自动型凯氏定氮仪进行。
所有大豆样品的近红外原始光谱如图2(A) 所示。
1.3 数据处理
采用CARS、GA、CC、BiPLS作为波长优选算法;数据预处理选用了标准正态变量变换(SNV);PCA结合马氏距离异常样本剔除;SPXY(Sample set Partitioning based on joint X-Y distance)及K-S法进行校正样品划分;偏最小二乘(PLS)进行定量校正模型的建立等。以上算法均在MATLAB 2016a环境下运行。样品经SNV处理后的光谱如图2(B)所示。
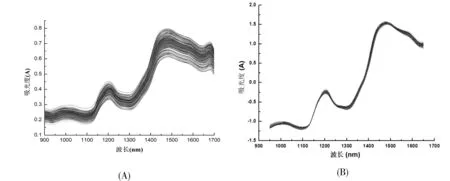
图2 大豆样品经SNV处理前后光谱(A). 239个大豆样品近红外光谱图 ; (B) .样品经SNV处理后光谱
2 结果与讨论
2.1 光谱数据点的选择与异常样品剔除
由于大豆的粒径差异以及颗粒物的装样很难保证每次完全一致,在上照式漫反射近红外光谱仪的光谱采样过程中,光程和漫反射光会产生一定的变化,导致谱图的重复性较差。为了获取可靠、稳定的模型,需要对原始光谱进行预处理过滤无用信息,降低模型的复杂度。标准正态变量变换(SNV)是基于统计学方法的用以修正因为散射导致的光谱线性变化,对于消除固体颗粒大小、表面散射以及光程变化对近红外漫反射光谱的影响很有帮助,采用SNV处理后结果如图2(B)。由于在预处理之后光谱两端的噪声比较大,因此在建模前去掉全光谱801个点两端各50个光谱点,实际使用光谱范围950 nm ~1650nm,其中每条光谱包含701个数据点。
在采用SNV方法对大豆近红外光谱进行处理的基础上,使用主成分分析(PCA)求得样本光谱的得分矩阵,并依据得分矩阵来计算因子空间的马氏距离,选取前面4个主成分的得分进行马氏距离计算,设马氏距离权重阈值e为1.5[10]。得到239个样品的马氏距离分布(见图3)。

图3 239个样本的马氏距离分布图
从图3可以清晰的看到,通过马氏距离的计算可以发现存在几个异常样本,如29、26、114、219等,剔除异常值样本可以提高校正模型的稳定性和准确性[10]。
2.2 校正样本划分
校正集和预测集样本的选择对模型的质量有着重要的影响,对于校正集样本的选择,通常采用样本均匀分布的方法,这样可以保证样本的代表性,本实验的样本选择方法为SPXY (Sample set Partitioning based on joint X-Y distance)法,该方法是在K-S方法的基础上提出的,在计算样本之间的距离时同时兼顾了光谱及浓度为特征参数。
对除去异常值后保留的235个样本利用SPXY法划分,校正集与预测集样品数的划分比例为 3∶1,其划分结果如表1所示,从中可以看出校正集样品蛋白含量范围33.84 %~46.32 %大于验证集34.66%~41.26%,这样的划分是合理的[11]。

表1 SPXY法选取的大豆校正集与预测集样品的划分
2.3 光谱变量的筛选
竞争性自适应重加权算法[8](CARS) 模仿的是进化论中的“适者生存”法则,通过定义波长贡献度结合指数衰减函数(EDF)筛选出PLS模型中回归系数绝对值较大的波长点,再通过N次蒙特卡洛采样,每次在校正集中随机挑选80%~90%的样本建立PLS模型,采用自适应重加权采样(ARS)技术进一步筛选波长变量,最后通过交互检验(CV)选出模型交互验证均方差(RMSECV)值最低的子集,即为最优变量子集。为提高校正模型的预测精度,在样品划分的基础上对波长采用CARS进行优选。首先采用蒙特卡洛采样500次,每次抽取80%的样本作为校正集,建立PLS回归模型,再利用指数衰减函数(EDF)去除波长权重对模型贡献度小的波长点,最后以交互验证均方根误差(root mean square error of cross-validation, RMSECV)作为评价指标,选择RMSECV值最小的变量子集,作为最优变量集。基于CARS的校正集175个样品波长筛选过程如图4所示,图4(A)表示光谱数据变量个数与CARS运行次数的变化关系,随着运行次数的增加变量数的变化由快到慢呈递减的趋势[12];图4(B)为10折交互检验得到的RMSECV值随着运行次数的变化关系,在前47次运行时,RMSECV值呈逐渐减小的过程,无关变量被剔除后模型预测均方根误差减小,随着运行次数逐渐增加,核心变量被剔除模型均方根误差增大。图4(C)中每条线表示1个变量回归系数随着运行次数的变化趋势,一连串“*”表示的直线与回归变量组相交的点即为残差最低点。
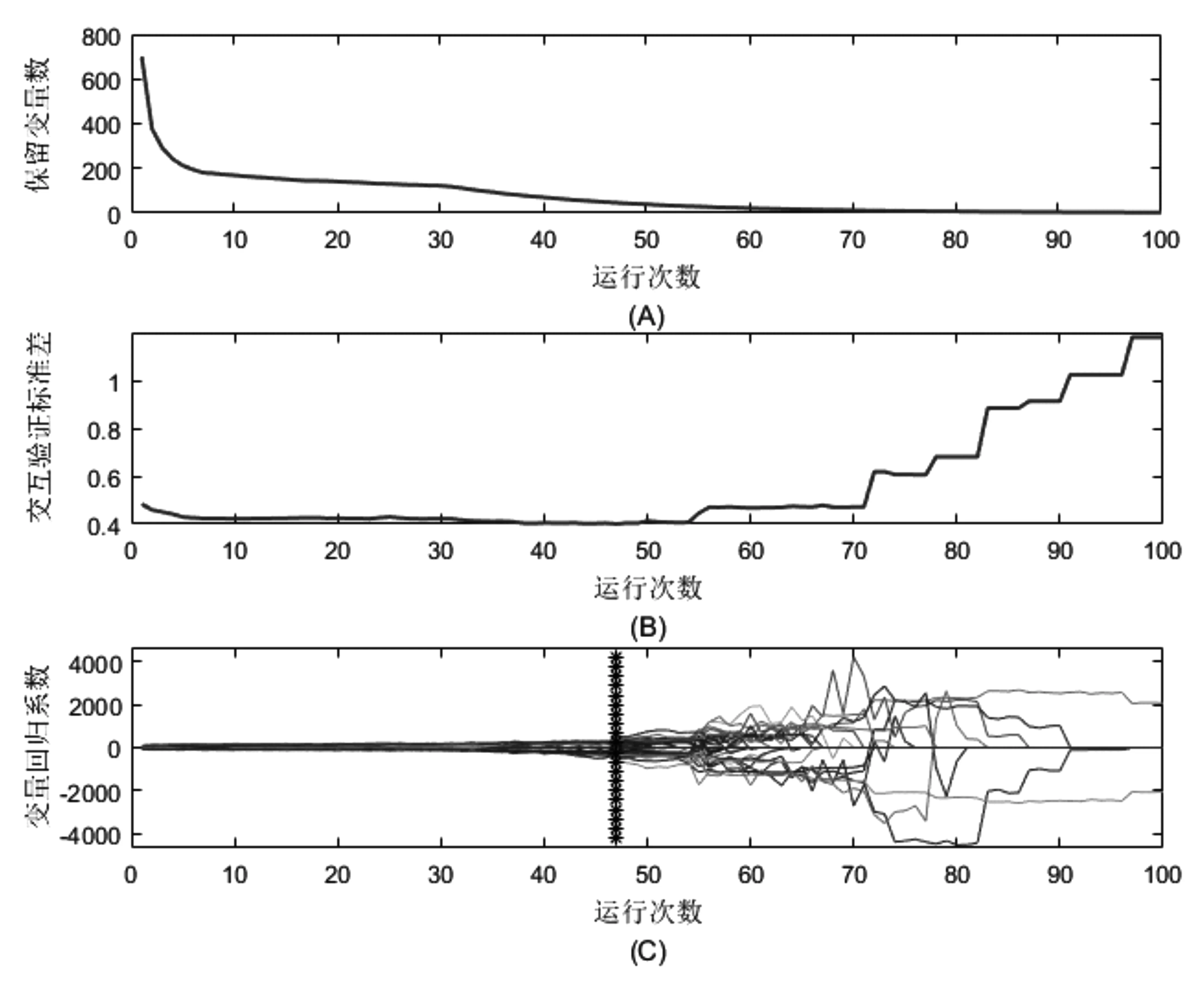
图4 大豆蛋白数据变量筛选图(A).保留波长数; (B).交互验证标准差 ;(C).波长变量回归系数
经过CARS波长优选,最终优选的变量数为46个波长点,采用CARS优选的变量建立的校正模型主成分因子数为9个,相较于全光谱模型的11个主成分,主成分因子数降低,说明CARS波长优选起到了简化模型的效果。校正模型对样本预测值与实际理化值之间的散点图如图5所示。图5 (A)为CARS算法优选的波长点建立的校正模型,在校正集中相关系数()及交互验证均方根误差(RMSECV)分别为0.9693和0.3898;在预测集中相关系数(Rp)及模型预测均方根误差(RMSEP)分别为0.9589和0.4015。图5(B)为全光谱建立的校正模型,在校正集中相关系数(Rc)及交互验证均方根误差(RMSECV)分别为0.9543和0.4119;在预测集中相关系数(Rp)及模型预测均方根误差(RMSEP)分别为0.9534和0.4388。通过与全光谱模型对比可以看出经过CARS波长优选,光谱变量总数由701减少到46个,在简化了模型的同时提高了模型的精度。

图5 校正模型预测值和实测值的散点图(A) .CARS-PLS;(B).PLS
2.4 结果比较与分析
为了检验使用CARS-PLS建立的模型与使用全光谱PLS建立的模型稳定性,随机选择了预测集样本中5个蛋白含量分布较宽的大豆样本,每个样品1天测定10次,仪器参数不变,共进行3天。通过对比预测结果极差与均方根值,判断模型的稳定性。图6(A)表示了使用CARS-PLS建立的模型的稳定性数据,其5个样本平均极差及均方根值分别为0.86、0.2335;图6(B)表示了使用全光谱PLS建立的模型的稳定性数据,5个大豆样本3天测试平均极差及均方根值分别为1.12、0.3335。表明经过CARS波长优选,模型的稳定性也得到了提升。CARS-PLS建立的模型在大豆粗蛋白模型与其他几种方法(CARS-PLS、GA-PLS、相关系数法建立的模型以及波段优选BiPLS)建立的模型相比较,结果如表2所示。从表中可以看出与GA、相关系数法及BiPLS模型相比,CARS-PLS模型的稳定性及预测准确性最好。
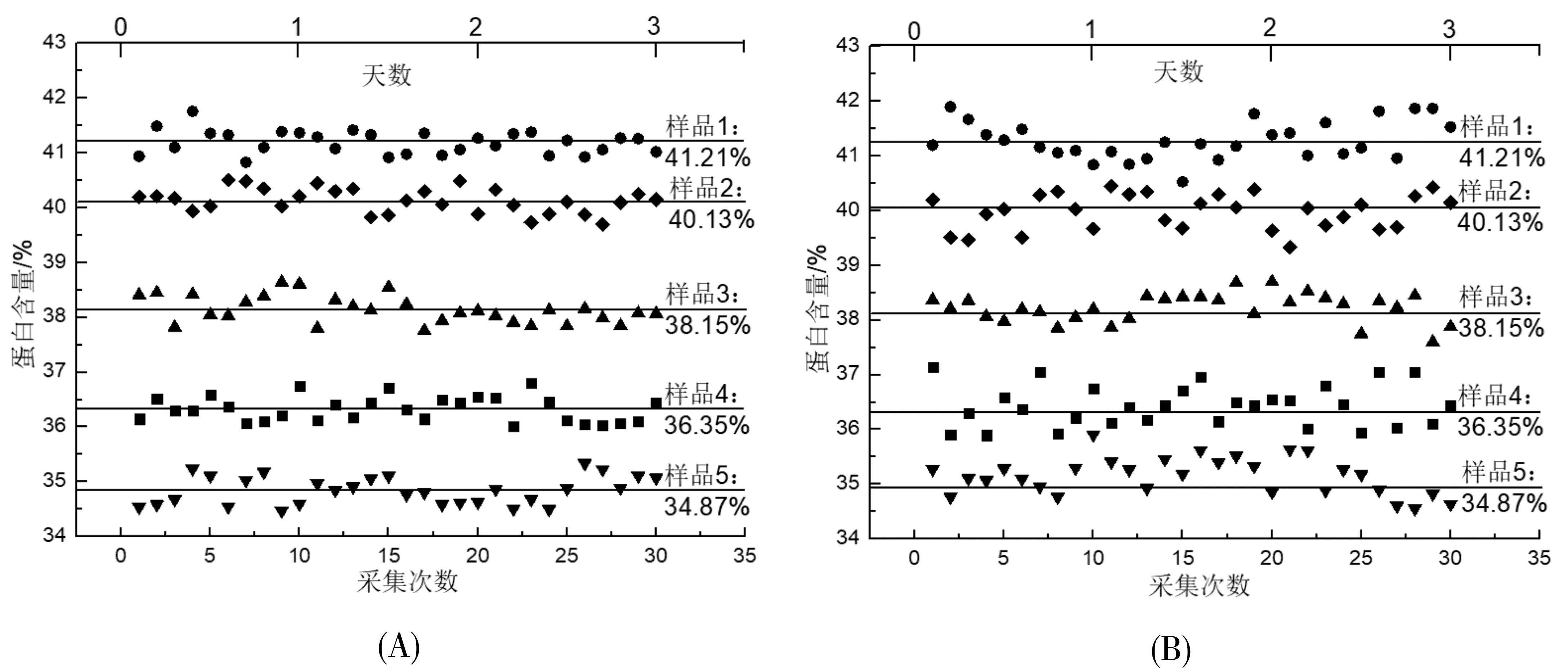
图6 模型预测结果长期稳定性散点图(A). CARS-PLS; (B). PLS
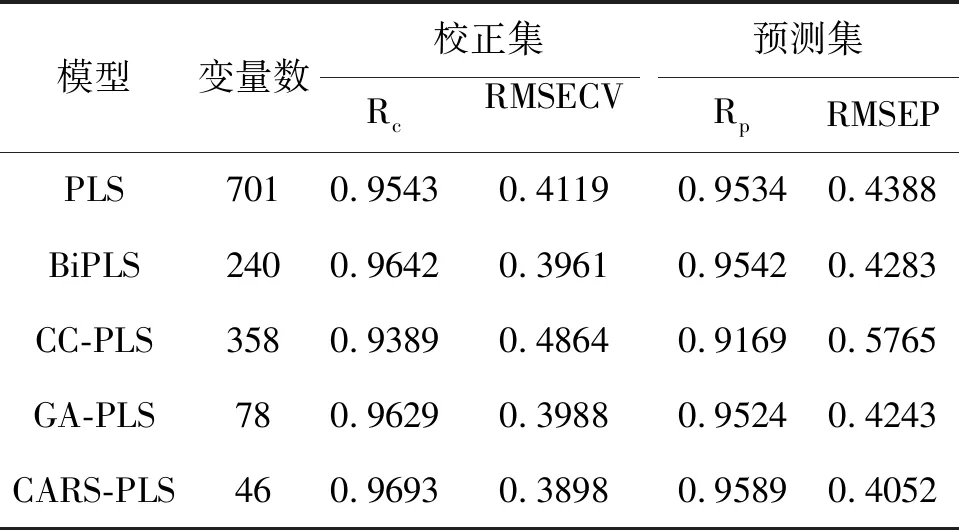
表2 不同PLS校正模型下的结果分析
由表2可以看出,全光谱PLS建模过程中由于光谱中包含了大量与蛋白含量无关的数据点,在一定程度上对校正模型的预测能力产生了影响;并且由于数据量非常大,建模及预测过程中耗时且对设备性能要求较高。GA-PLS及BiPLS都剔除了大量与大豆蛋白含量无关的数据点,但在模型准确性上前者要优于后者。但是GA属于全局寻优,随机性较强,并且在样本量过多时必需进行数据压缩,否则,很容易出现过拟合现象,而变量压缩的方法选取也会对结果造成较大影响,因此,在建模及预测过程中很难保证结果的一致性;BiPLS属于波段优选,共有245个波长点参与了校正模型的建立,虽优于全光谱701个波长点,但数据量还是很庞大。
3 结论
本研究采用竞争性自适应权重取样法(CARS)作为国产便携式近红外光谱仪在大豆粗蛋白含量测定过程中的波长优选算法。在进行波长优选过程中,针对大豆颗粒的装样及所采用的便携式近红外光谱仪特性,选择了标准正态变量变换(SNV)作为光谱数据预处理方法,利用SPXY法作为校正集与预测集样品划分方法,用竞争性自适应权重取样法(CARS)对大豆近红外光谱进行特征波长选取。再通过对比CARS、遗传算法(GA)、相关系数法(CC)及后向间隔偏最小二乘(BiPLS)优选的特征波长/波段使用PLS算法建立的校正模型。结果表明使用CARS-PLS建立的模型明显优于其他模型,不仅减少了建模所用的变量数,而且校正模型的预测精度及稳定性也得到了提高。
猜你喜欢
国学(2020年1期)2020-06-29
飞天(2019年6期)2019-07-08
摄影之友(影像视觉)(2017年10期)2017-11-07
摄影之友(影像视觉)(2017年1期)2017-07-18
自动化学报(2017年2期)2017-04-04
中国照明(2016年4期)2016-05-17
新高考·高二数学(2015年2期)2015-05-27
中国当代医药(2015年26期)2015-03-01
物理实验(2015年9期)2015-02-28
新高考·高二数学(2014年7期)2014-09-18
