
基于PC运行环境的机器学习病毒检测方法
2019-06-15 01:01肖行
数字技术与应用 2019年3期
肖行

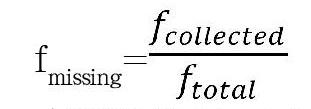

摘要:随着物联网、云计算、大数据、智能手机的普及,数以亿计的各种不同类型的设备,所产生的海量数据,对网络安全的难度提高了几个数量级。传统的安全解决方案耗时耗力,也满足不了对未知病毒,安全漏洞的预测。本文通过分析电脑软件和硬件的运行环境,来预测计算机在抵御计算机病毒的能力,可作为现有计算机病毒检测良好的补充。
关键词:网络;安全;病毒检测;软件;硬件;运行环境
中图分类号:R373 文献标识码:A 文章编号:1007-9416(2019)03-0201-01
随着近年来网络安全事件频发,网络安全形势日益严峻,国家政治安全和用户信息遭到威胁,网络安全越来越值得我们重视。本文试图从网络病毒检测方向出发,探讨怎样更好保护地网络安全。
1 传统病毒检测方法分析
现在的病毒检测方法,主要是通过对目前已经发现,并且大规模爆发的病毒,进行手动提取病毒的特征。
特征代码分析方法,主要通过采集已知病毒樣本,分析是否含有病毒代码病毒数据库,这是目前最有效最简单的检测方法。但是这样的方法缺点也是显而易见,之前分析的匹配的病毒代码,到病毒下一次感染或者爆发就会出现新的变种,导致传统方法不能匹配。
校验法通过检验算法可以用来检测已知病毒,也可以用来检测未知病毒,但是他不能识别病毒名称类型,也不能检测不依附于其他文件的病毒。
行为监测法主要是对现有的病毒,通过收集资料研究看考拷证,总结病毒的共同现象行为。这种方法一般能较好的发现未知病毒,但是有可能误报。
上面列出了传统方法在病毒检测的三种主要手段,可以看出,这里主要是对现有病毒进行分析,再提取对应的病毒特征,亦或对正常文件进行分析,反之则判断为有病毒的文件。
2 本文方法阐述
由于个人计算机的普及面极为广泛,计算机硬件的发展也是日新月异,安照摩尔定律硬件几乎在半年就会更新一代,这样就造就了个人计算机的千差万别,操作系统等软件更是迥然相异,这就使得计算机病毒在不同硬件和软件环境有可能出现不同行为特征,这对病毒检测无疑是一种灾难。
3 本文方法实验
3.1 数据采集
本文提出一种基于对计算机现有的软件和硬件运行环境,从而判断计算机是否容易感染或者已经感染病毒。所收集的数据特征包括计算机硬件BIOS信息,硬盘大小,内存大小,屏幕尺寸,操作系统版本,是否安装了杀毒软件,杀毒软件版本,IP信息,PC购买日期,是否已经中病毒等特征。数据来源主要收集于本人所在工作单位的2000台左右的PC,通过相关管理软件以及PC上锁安装的杀毒软件所收集的信息。
3.2 数据预处理
数据的预处理主要包括把IP转换成地理位置,增加每个数据的缺失率,把string类型的数据转换成float或者int类型,增加时间戳。
把IP转换成地址位置信息,主要考虑到病毒一般在同一网段或者临近的PC进行传播,如果有一台PC已经中病毒了,附近PC中病毒的可能性较高,所以把IP转换成位置信息有助于最终的病毒检测。转换方法为把核心交换机定义成距离中心,通过IP接入的交换机到中心的拓扑位置的Euclidean距离作为转换结果。
LEuclidean=
由于收集的数据中必然有缺失,考虑到缺失一些不重要的特征,对最终特征也没有不好的影响,所以直接剔除也不是一种好的方法。共有ftotal个特征,如果其中一台PC只收集到fcollected个特征,那么缺失率为:
fmissing=
在算法当中,string类型的数据是不能直接处理,一般都要转换为数值类型的数据,这里采用的转化方法为pandas的factorize方法,就是把所有类型进行排序,再把string特征所在的排序号作为特征。
fstring,_=pd.factorize(fstring)
时间戳在病毒检测中非常的重要,表现在2个方法,首先杀毒软件不同版本杀毒效果是不同的,高版本也不一定好;其次,病毒的爆发一般存在与时间的相关性,比如某一时间熊猫烧香病毒大量爆发,而近段时间勒索病毒的大量爆发,都是与时间戳存在一定关联的,所以把杀毒软件的版本这一特征,转化为时间序列特征是有必要的。
3.3 实验结果与分析
本文采用目前机器学习较为流行的集成学习方法,包括陈天奇的XGboost,微软的LightGBM,以及Yandex的CATboost。这三种boosting算法主要思路都是集成弱分类器为强分类器,其中在细节上各有差异,所以在最终训练结果也会有些差别。实验所采用的平台为Windows 7 8G内存,I5 7500 4核,Anaconda Jupyer Notebook,python 3.5的版本。XGboost,LightGBM和CATboost均为python版本。
实验预测结果对比如图1。
从图1可以看出这三种算法的实验结果差别并不大,都是在70%左右。因此可以证明通过收集计算机的硬件和软件运行环境,来检测计算机是否容易中病毒,这种方法是行之有效的。即本文提出的病毒检测方法在算法的适用性上是没有区分的,也可以间接说明本文方法独立于传统病毒检测方法,不是排斥的关系,而是可以相互补充,共同提升病毒检测率。
4 展望
本文提出了一种基于PC运行环境的机器学习病毒检测新方法,可以作为传统病毒检测方法一种强有力的补充。优势主要表现在:第一,手段多样化,传统方法主要是通过分析病毒特征,而本文通过PC软硬件运行环境进检测,绕过了分析病毒的繁琐过程。第二,检测结果具有通用性,不单只是对一种或者几种病毒,而是对所有符合PC运行环境的病毒都能检测的到。当然缺点也是显而易见的,70%的检测结果还是大有提升空间,而且也存在误报率较高的现象,因此今后的主要工作可以从这两个方面入手,进一步提高本方法的实用性。
參考文献
[1] 张勇,张卫民,欧庆于.基于主动学习的计算机病毒检测方法研究[J].计算机与数字工程,2011,39(11):89-105.
[2] Chen T,Guestrin C.XGBoost: A Scalable Tree Boosting System[J].2016.
[3] Prokhorenkova L, Gusev G, Vorobev A, et al. CatBoost: unbiased boosting with categorical features[J].2017.
Machine Learning Virus Detection Based on PC Environment
XIAO Hang
(Guangzhou No.1 People's Hospital,Guangzhou Guangdong 510180)
Abstract:With the popularity of IOT, cloud computing, big data and smart phones, massive data were produced by millions of devices, the difficulty of network security has increased by several orders of magnitude. Traditional security solutions are time-consuming and labor-intensive,and cannot meet the prediction of unknown viruses and security vulnerabilities.By analyzing the running environment of computer software and hardware,we propose a method to predict the ability of computer virus detection, which is a complement to the existing computer virus detection.
Key words:network;security;virus detection;software;hardware
猜你喜欢
当代水产(2022年3期)2022-04-26
测控技术(2018年8期)2018-11-25
现代检验医学杂志(2016年2期)2016-11-14
中国新通信(2016年16期)2016-10-18
科学与财富(2016年28期)2016-10-14
科学与财富(2016年28期)2016-10-14
考试周刊(2016年79期)2016-10-13
医学研究杂志(2015年8期)2015-06-22
