
基于迁移学习的电力通信网异常站点业务数量预测
2019-06-15 02:13杨济海李号号彭汐单张智成李石君
数据采集与处理 2019年3期
杨济海 李号号 彭汐单 张智成 黄 倩 李石君
(1.国网江西省电力有限公司信息通信分公司,南昌,330077;2.武汉大学计算机学院,武汉,430072;3.国网江西省电力有限公司,南昌,330077;4.南瑞集团有限公司,南京,210003)
引 言
迁移学习是机器学习的一个新方向,它是利用已存在的知识对不同但相关的领域进行训练学习。迁移学习打破了传统机器学习所需满足的条件——训练数据和测试数据独立同分布,以及拥有足够的数据来训练一个好的模型[1]。研究表明,两个不同领域的相似度越高,迁移学习就越容易,效果越好,否则往往效果不佳,甚至出现“负迁移”的结果。迁移学习已经成功应用到多个领域[2],如文本情感分析、图像分类、人类活动识别、软件缺陷分类和多语言文本分类等。表1总结了现有的各种迁移学习方法。

表1 各种迁移学习方法的举例和描述Tab.1 Examples and descriptions of various migration learning methods
Dai等提出了基于实例的TrAdaBoost[4]算法,该算法的思想是最大限度利用源数据,找到源数据中与目标数据相关的数据,然后和目标数据一起训练学习。但是TrAdaBoost算法只利用了单个源数据,算法的结果依赖于源数据与目标数据的相关性,如果相关性很弱,容易产生负迁移。Cheng等人通过考虑多个源与目标的相关性,提出了两种多源学习算法,MTrA和TTrA[11]。多源的迁移学习主要研究当源领域为多个时如何进行迁移的问题,主要的成果有Transitive transfer learning[12](两个相似度不高的域利用从第三方中学习到的相似度关系,完成知识的传递迁移),Distant domain TL[13](在相似度极低的两个域进行迁移时,用Autoencoder自动从多个中间辅助域中选择知识)等,多源的迁移可以有效地利用多个领域的知识,综合起来达到较好的效果。在多源的迁移学习问题中,现有的算法如MultiSource-TrAdaBoost,Task-TrAdaBoost,Weighted multi-source TrAdaBoost等研究的都是对称的二分类问题,缺少对回归问题的研究,回归问题和二分类问题在目标函数的定义等方面还是有着很大的区别,所以本文将提出加权多源TrAdaBoost的回归算法。
本文除了关注迁移学习的理论研究外,还将重点关注其在电力通信网中的应用。国家电网通信管理系统(TMS)中普遍存在账物与实物不一致、数据录入错误和数据缺失的问题。阮筠萃介绍了电力通信网管理系统的静态资源与实际不符合、动态资源关联错误、基础数据保险不到位的各类型数据质量问题,以及这些问题带来的巨大挑战[14]。Liu等详细分析了导致电力数据质量问题的原因[15]。在TMS系统中存在着一些业务记录严重缺失的站点,本文将这些站点定义为异常站点。使用本文提出的加权多源TrAdaBoost的回归算法对站点正确的业务数量进行预测,将极大地降低数据维护的成本,具有巨大的现实意义。
1 加权多源TrAdaBoost的回归算法
在分类的问题中,对于一个样本xi的预测ht,要么是正确的,要么是不正确的,所以其误差ei=|yi-ht(xi)|为0或者1。在回归问题中,该误差有可能极其大,所以需要将其归一化,这样才能使用TrAdaBoost的权重更新机制。本文将AdaBoost的误差函数引入进来,误差函数有如下3种方式,其中D表示最大的误差。

在TrAdaBoost的权重更新机制中,由于源领域样本的权值只会减少而不会增加,而目标领域样本的权值只会增加却不会减少,因此两个领域的权重之差会越来越大,在迭代次数较多的情况下,会严重影响模型的效果。该问题在回归问题中显得尤为严重,因为ei几乎不可能为0,即使很小的误差,也会导致权重的缩减,所以在多次迭代之后,源领域的样本权重很有可能缩减为0。为了解决该问题,本文引入了误差容忍系数γ,如果某个样本的误差小于容忍系数,那么其权重不发生变化,如果该样本的误差超过了容忍系数,其权重才会发生变化。误差容忍系数将一定程度解决源领域权重缩减的问题,提高迁移的效果,并控制模型对误差的容忍程度。

表2 符号表Tab.2 Symbol table
在多源的加权学习中,每个源领域将得到一个弱的学习器,根据弱学习器在目标领域上的误差情况,可以每次只选取误差最小(相关性最强)的源领域,也可以根据该误差的大小对每个弱学习器进行加权,加权之后进行集成,得到本次迭代中的测试误差,根据该测试误差去调整样本的权重。前者的做法往往会造成其他的源领域样本失去辅助作用,所以本文选择后者的做法。部分符号说明见表2。
算法1加权多源TrAdaBoost的回归算法
输入 (DS1,…,DSk,…,DSN),Dtarget,T,γ
输出 回归器f(·):X→Y
步骤:
(1)初始化参数φ(s),其中,ns为所有源领域的样本数的总和

(2)初始化样本权重。
(3)fort:1 →T。
(4)合并训练数据集Dk=(DSk,Dtarget),同时对权重向量(wSk,wtarget)归一化。
(5)对合并后的每一个训练数据集Dk,(wSk,wtarget),将其代入到回归模型。此处选择带参数的SVR模型(也可以选择回归树等),即
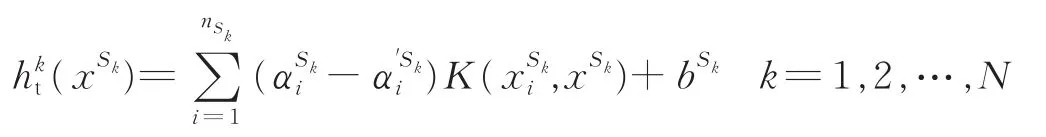


(8)计算在第t次迭代得到的候选预测模型ht在Dtarget上的误差

(9)更新所有样本的权重。根据上面得到的误差εt更新各个源领域和目标领域样本的权重。对于目标领域中的样本,需要根据预测的误差大小增加样本的权重,即表示对于预测错误的样本,应增加此样本的重要性,达到强调此样本的目的。对于源领域中的样本,如果样本预测值小于γ,则此样本的权重不变;相反,如果相差大于γ,则减小此样本的权重,即表示预测错误的样本对目标数据的学习没有帮助,应该降低这些样本的影响。设置φt为

更新目标领域样本的权重

更新各个源领域样本的权重

(10)如果t≤T,则转到步骤(4);如果t>T,则计算出最终的预测模型f(x)。f(x)为ht(x)的加权中位数,用ln(1/φt)作为ht(x)的权值。
2 通信网异常站点检测与真值预测
异常站点的挖掘与纠正是国家电网根据实际的需求提取出来的研究课题,具有很大的研究价值和现实意义。在通信网管理系统中,小部分站点存在系统录入的业务数量与实际的业务数量相差较大的问题,本文将这种现象称为业务数量缺失,将业务数量缺失的站点称为异常站点。这类问题给实际的运营和管理带来巨大的困难,单靠人力无法完成这类数据质量的治理。
在对业务数量进行预测时,由于全国各省的站点数量不同——大的省份有两千多个站点,而小的只有两百个左右的站点,各省经济、人口、基础设施等因素的不同,导致了其数据分布也各不相同。如果放到同一个模型中进行训练,无法得到满意的预测精度。本文通过上述的加权多源TrAdaBoost的回归算法,运用其他省份的数据来训练目标数据,使模型能够达到较为满意的效果。本文设计的异常站点检测与真值预测的模型如图1所示。

图1 异常站点检测与真值预测模型图Fig.1 Abnormal site detection and true value prediction model
数据清洗是对初始数据进行缺失值处理、异常值处理和冗余去除等操作。在特征工程中,选取的特征主要来源于业务专家推荐和相关性分析方法,本文引入社交网络分析的方法,提取中心度和PageRank值的特征,充分考虑了站点在拓扑结构中的重要度。使用图G来表达某个省份的站点与光缆的拓扑图,站点之间的权重为光缆的数量,以邻接矩阵的方式来表达,其中g为站点的数量,如果i,j之间无光缆连接,则xij=0。CD(i)为站点i的中心度。图2绘制了中心度与业务数量的曲线图,也能验证中心度与业务数量的强关联关系。
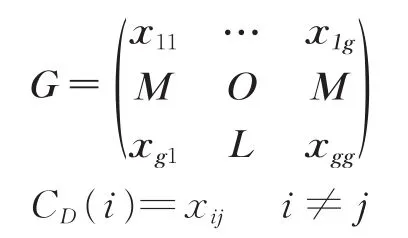
本文为了引入其他站点对该站点业务数量的影响,使用了PageRank算法提取特征,节点xi的PageRank值的更新公式如式(1)所示,其中M(xi)为所有站点对站点xi有出链的站点集合,L(xj)表示xj到所有其他站点出链的权重之和,xji表示站点xj到xi的权重,d为阻尼系数,一般经验值取0.85。式(1)表明,如果与站点xi相连接的站点个数越多,则说明该站点的重要性越高,如果与该站点连接的其他站点越重要,那么该站点很可能也越重要,承载的业务越多,如果该站点所占连接源的站点的权重越高,则说明该站点重要性越高。除了上述特征外,还有站点类型、电压等级、端口占有率、调度等级、建成年限、设备数量和机房数量等特征。

异常站点的挖掘首先是一个异常检测问题,有很多从概念视角和具体应用视角的异常检测相关的综述[16-18]。本文选择了无监督算法iForest选择初始的异常站点,使用iForest主要是因为该算法需调节的参数少、准确率高、运行效率快。剔除异常站点后剩下的站点就可以被输入到回归模型中。如果不过滤这些离群点数据,将会严重影响模型最终的效果和泛化能力。如果要预测某个省份的站点业务数量,就将该省份的数据作为目标领域,其他省份的数据作为源领域。使用上述的加权多源TrAdaBoost的回归算法,解决了不同省份之间数据分布不同、部分省份训练数据过少的问题。使用带参数的SVR作为基回归器,因为SVR采用的是结构化风险最小化,更适合小样本的使用场景且有更好的鲁棒性。异常站点来自两个部分,一是iForest发现的异常站点(离群点),二是回归模型的预测值与观测值残差较大的站点。
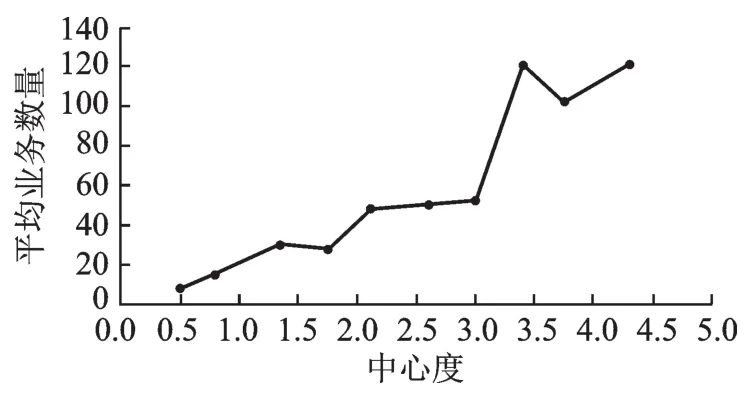
图2 站点中心度与业务平均数量的关系Fig.2 Relationship between site center degree and average number of businesse
3 实 验
3.1 Friedman#1回归问题
Friedman#1(Friedman,1991)是一个非常著名的回归问题,为了验证提出的加权多源TrAdaBoost回归算法,本文修改了Friedman问题,以便将其使用到迁移学习的问题中。通过式(2)可生成目标领域和源领域的数据集,其中N表示正态分布。为生成源领域的数据集,本文对式(2)的参数ai,bi,ci进行了改进,不再取固定值,ai,bi由N(0,0.1d)生成,ci由N(0,0.05d)生成,这里的d是一个参数,控制目标领域样本与源领域样本的相似度。本文使用不同的d随机生成了5个源领域的数据集,d的取值为[0.5,1]。每个源领域数据集的大小为200,目标训练集的大小为15,测试数据集的大小为600,生成了60份目标领域和源领域的数据集,分为3组。图3展示了生成的数据集,其中不同的数据集以不同的颜色表示。由于目标数据集的数据较少(黑色的点),难以训练出有效的回归模型。测试数据集的分布用蓝线表示,可以观察到源领域的数据分布(红色、黄色等)明显与目标领域不同,因此改造后的Friedman回归问题是非常适合迁移学习的使用场景。

考虑以下几组对比实验:
(1)AdaBoostRegressor表示将所有的源领域数据和目标领域的数据进行合并,不使用迁移学习;
(2)Muti-TrAdaBoost表示使用本文提出的加权多源的TrAdaBoost回归算法;
(3)Muti-TrAdaBoost withoutγ表示不使用本文提出的误差容忍系数,在实验中误差容忍系数γ取值为0.05(通过交叉验证方式得到的最优参数)。

图3 各个领域数据分布图Fig.3 Distribution of data in various fields
本文考虑使用拟合度R2和均方误差MSE两个指标,综合衡量回归模型的效果,表3展示的结果为每组实验的平均值。实验验证了加权多源的TrAdaBoost回归算法的有效性,误差容忍系数可以提高大约0.01的R2分数。

表3 实验结果对比Tab.3 Comparison of experimental results
3.2 异常站点检测与真值预测实验结果
本文使用了10个省份的数据,其中A,B,C三省的站点数量最少,分别为267,340,471,将作为目标领域,其他7个省份作为源领域。首先,在不使用迁移学习的情况下,单独训练每个省份的数据,取R2平均值以选取最合适的基回归器,实验结果(见图4)发现SVR最适合本任务。

图4 各个回归模型的模型分数对比图Fig.4 Comparison of model scores for each regression model
本文考虑以下几种对比实验:Target表示只用目标省份的数据进行训练;Target+Source表示将目标数据和辅助数据放在一起进行训练;Muti-TrAdaBoost表示使用本文提出的加权多源的TrAdaBoost回归算法进行训练;Muti-TrAdaBoost withoutγ表示在算法执行中不使用本文提出的误差容忍系数γ。实验结果见表4。通过实验结果可以发现:由于数据量过少,只用目标省份的数据很难训练出满意的模型;迁移学习考虑了目标领域与源领域数据分布的差别,在模型的分数上有一定的提升;容忍系数γ的引入,一定程度上解决了在回归问题中,源领域样本权重缩减太快的问题,从而提高了算法的效果。
召回率可以很好地衡量模型对异常站点的检测能力。因为人工排查所有站点的业务数量耗时耗力,所以本文采用随机抽样的方式,每次抽样100个站点,删减其业务数量,然后观测模型能否检测到被删减的站点。在A,B,C三省的站点中,随机进行了3次无放回抽样删减,平均有93个站点被标记为异常,模型召回率达93%。截至目前,根据模型推荐的异常站点,电网运营人员对约10个异常站点的实际业务数量进行了线下排查,根据排查结果与真值预测结果,得到的R2分数为0.807 2。

表4 算法的结果分析Tab.4 Analysis of the results of the algorithm
4 结束语
本文提出了加权多源TrAdaBoost的回归算法,多源的迁移学习拥有更广泛的使用场景和有效避免负迁移的优势。同时提出了误差容忍系数,该系数能够一定程度解决源领域样本权重缩减过快的问题,提高了算法的效果。在修改后的Friedman#1回归问题上进行了实验,验证了该算法的有效性。本文将提出的算法应用到电力通信网的行业问题中,提出了异常站点(业务数量缺失严重的站点)检测与真值预测模型,在特征工程中使用了社交网络分析的方法,最终的实验效果进一步验证了算法的有效性。本文将多源迁移学习应用到电力通信网的行业问题中,可以给该行业的问题带来新的思路和方法。
猜你喜欢
哈尔滨轴承(2020年2期)2020-11-06
当代陕西(2020年17期)2020-10-28
今日中国·法文版(2020年7期)2020-07-04
电子制作(2019年14期)2019-08-20
中国特种设备安全(2019年1期)2019-03-13
人大建设(2018年5期)2018-08-16
党的生活·党员电教与远程教育(2017年9期)2017-10-17
中国自行车(2017年1期)2017-04-16
故事会(2016年21期)2016-11-10
山东青年(2016年2期)2016-02-28
