
感知用户年龄的Item-based协同过滤推荐算法
2019-06-14 07:36张彩廷祝永志
计算机技术与发展 2019年6期
张彩廷,祝永志
(曲阜师范大学 信息科学与工程学院,山东 日照 276826)
0 引 言
在被称之为“大数据时代”[1]的今天,电子商务琳琅满目的商品、休闲娱乐软件数不尽的电影和音乐、每天大大小小的新闻事件以及社交网站中充满的无限可能,使得人们的生活丰富多彩,但如何从如此大量的信息中快速找到自己需要的或感兴趣的信息成为互联网平台的挑战。当前,推荐系统成为人们互联网生活中的“引路人”,其在电子商务中的主要功能有:吸引新用户,即向潜在的新客户推荐物品将访客转换为购买者;激励老用户,即根据他们之前购买的物品向老客户推荐更多他们可能喜欢的物品;改善客户服务,提高系统与用户的交互[2]。目前,在推荐系统中应用最广泛的是协同过滤推荐算法。
文中首先简要介绍了相关研究,在对传统算法的基本思想和相关技术进行简单描述的基础上提出了一种改进算法,并通过实验进行了验证。
1 相关研究
对于推荐算法,已经有不少学者针对其各方面存在的问题提出了各种各样的改进方法。例如,文献[3]为了缓解数据稀疏性问题,提出了综合用户特征及专家信任的协作过滤推荐算法;文献[4]主要考虑用户特征随时间的动态变化,进行精确相似度的计算,并解决冷启动问题;文献[5]提出对用户评分矩阵进行两个维度联合聚类,然后在类内进行矩阵分解预测评分的两阶段联合聚类协同过滤算法,以提升推荐实时性;文献[6]将基于用户的协同过滤算法运行在Hadoop平台,将多任务映射到不同的处理器上,以解决算法扩展性的问题。
文中受上述文献启发,提出一种感知用户年龄的Item-based协同过滤推荐算法,该算法在推荐系统的实时性、精确性和可扩展性上均有所改善。
2 传统Item-based协同过滤推荐算法
2.1 相关技术
(1)相似度计算。
Item-based协同过滤算法常用有三种相似度计算方法[7]:
余弦相似度:
(1)
修正余弦相似度:
(2)
Pearson相关性相似度:
(3)
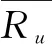
(2)项目邻居选择。
将所有Item对的相似度组成一个项目相似度矩阵,每行为一个项目i的相似度向量,将每行的相似度都从大到小降序排列,选出相似度最高的前k个项目,作为该行项目i的邻居项目,所组成的集合标记为KNNI(i)。集合之外的相似度不用于目标用户预测评分的参考[8],根据需求可以调整k的大小来控制算法计算量和精度。
(3)评分预测。
(4)
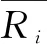
该评分预测算法是在该项目评分平均值的基础上,利用相似度和目标用户对其他项目的评分的加权平均值来计算预测评分[6]。
2.2 算法描述
Item-based协同过滤算法的基本思想为:根据用户的历史行为信息计算项目间的相似度,从而预测用户的其他喜好以及喜好程度,根据预测为其进行推荐,算法主要步骤[9]如下:
(1)利用原始数据生成用户-项目评分矩阵;
(2)选择相似度计算方法,计算所有项目之间的相似度,并筛选出每个项目相似度最高的k个邻居项目;
(3)依据目标用户对该项目的邻居项目的历史评分,利用评分预测算法来预测目标用户对该项目的评分;
(4)将对目标用户预测出评分的项目进行排序,从高到低选择一定数量对目标用户进行推荐。
3 感知用户年龄的Item-based协同过滤推荐算法
3.1 算法改进
(1)冷启动问题是指新加入的用户和项目因为没有相关历史数据而导致无法进行相似度的相关计算,因此不能对其进行推荐。相对于新项目冷启动问题,新用户冷启动问题在现实的推荐系统中表现得更为突出。为解决用户冷启动问题,文中在传统的用户评分数据集的基础上加入用户特征数据集。用户特征数据集包含的用户特征有:年龄、性别、职业和邮政编码,相关专家给出四个特征的权重比值为4∶3∶2∶1[4],可以看出年龄特征所占比重最大。因此,首先根据用户年龄特征对用户评分数据集进行预处理,将不同年龄段的用户分成不同的组。在组内进行项目间的相似度计算,这些局部项目间的相似度的计算大大减小,提高了推荐实时性[10]。
(2)传统Item-based协同过滤算法的相似度计算并不能准确反映项目间的相似程度,针对该问题,文中使用加权相似度。共同评分的用户数量越多,则该相似度有效度越高,故权重选取为同一Item对打分的用户数量[11],加权相似度计算公式如下:
加权余弦相似度:
(5)
加权Pearson相关性相似度:
(6)
其中,n为项目i和项目j共同打分的用户数量;其余元素与式1~3中含义相同。
(3)随着推荐系统使用时间的增长和用户数量的增多,系统数据规模会快速扩展,传统的单机推荐算法对于海量的用户和项目历史数据是无能为力的,不论是存储还是计算无疑都成为了难题。分布式计算平台的出现解决了推荐系统可扩展性的难题。文中利用Spark分布式计算平台和HDFS分布式存储系统相结合的方式,Spark基于内存计算,HDFS具有高容错性、适合批处理等特点,能够满足大数据计算和存储的需求[12]。
Spark是基于内存的分布式计算框架,通过对弹性分布式数据集(RDD)的操作来进行计算,这些计算会在集群上自动并行执行[13]。每个应用需要一个驱动器程序来发起,它通过一个SparkContext对象来访问Spark,这个对象代表对计算集群的一个连接[14],驱动器程序一般要管理多个执行器节点,计算会被分配到所有的节点上执行。Spark在集群上的运行如图1所示。
3.2 算法描述
输入:用户评分数据集,用户特征数据集,目标用户年龄标识;
输出:对目标用户的预测评分集。
(1)用户特征矩阵提取年龄特征列,数据集已对年龄进行分段标识;
(2)用户评分矩阵提取User ID,Movie ID,评分对应的列,不使用时间戳数据;
(3)根据目标用户年龄段,提取该类别用户的评分数据,并格式化为非嵌套元组,并将数据按4∶1分为训练集和测试集;
(4)计算类内训练集项目相似度矩阵,记录各个Item的最近邻集;
(5)预测评分算法对训练集的空缺数据进行预测。
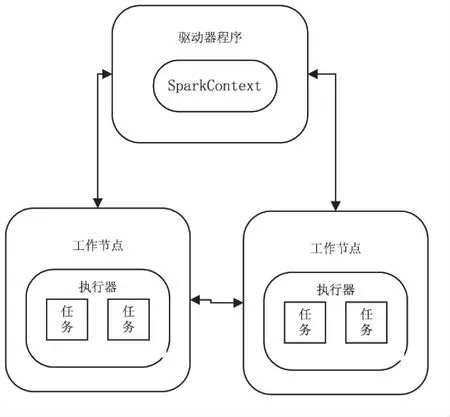
图1 Spark运行原理
4 实验及结果分析
4.1 实验数据集与实验环境
实验采用MovieLens网站提供的1 MB数据集,文中使用了其中的ratings.dat和users.dat两个数据集,ratings.dat是一百多万条用户电影评分数据,users.dat是参与评分的六千多名用户特征信息。
实验环境为虚拟机上架设的三个节点的Hadoop集群,系统为Ubuntu16.04,Spark为2.1.0版本,运行在Hadoop集群,其依赖于Yarn,HDFS作为存储平台,采用Python语言进行实验编程。
4.2 实验设计与结果分析
首先用传统Item-based推荐算法,分别用余弦相似度和Pearson相关性相似度对数据集进行实验。实验数据共1 000 209条评分数据,按4∶1分为训练数据和测试数据,由于数据量过大,仅取邻居数为10,对此数据集进行了三次实验,运行时间都在3 000 s以上,每次实验都需要耗费大量时间。MAE(平均绝对误差)如表1所示。

表1 传统算法实验结果
如表1所示,两种相似度推荐算法测试出的MAE都大于1,可见传统推荐算法推荐效果并不理想。
感知用户年龄的Item-based协同过滤推荐算法中分类标识规则为:18岁以下、18岁~24岁、25岁~34岁、35岁~44岁、45岁~49岁、50岁~55岁、56岁以上,分别标识为1、18、25、35、45、50和56。每组用户数量与总数量相比大大减少,比例最大的不到40%,最小的为2.7%。实验结果显示不同用户组实验运行时间最长为2 934 s,最短为82 s,可见改进算法在很大程度上提高了推荐的实时性。
利用改进算法同样进行了两组实验,实验结果如图2~图5所示。
图2和图3是第一组采用传统相似度的各年龄段实验结果,18岁以下和18~24岁这两组用户的MAE在0.7~0.9之间,其余用户组实验的MAE结果可以控制在0.7~0.8之间,比18岁以下和18至24岁两组用户的推荐结果更为精确。这说明,24岁以下用户爱好并不稳定,该分组数据质量不高,随着年龄增长用户兴趣逐渐趋于稳定,推荐准确度也相应提高[15]。从项目邻居数的选取角度来看,随着邻居数目的增大,MAE变化率不断减小。与传统推荐算法相比,MAE都在1以下,而且最小达0.706 0,精确度有大幅提高。
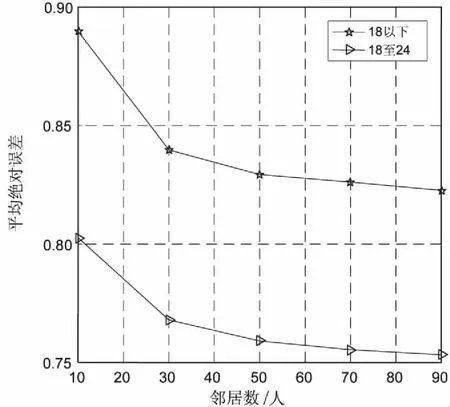
图2 第一组实验结果(1)

图3 第一组实验结果(2)
图4和图5是第二组实验结果,相似度采用Pearson相关性相似度,实验结果同样显示18岁以下和18~24岁这两组用户MAE偏高,其余用户组使用该算法MAE控制在0.65~0.8之间,推荐精度大大提高。

图4 第二组实验结果(1)
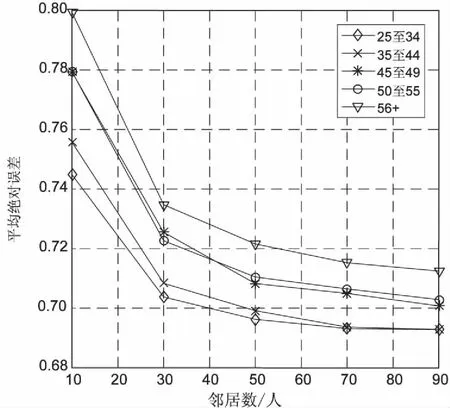
图5 第二组实验结果(2)
由上述实验结果可以说明该算法能够保证推荐精度,提高推荐实时性,并且运行在分布式集群上具有可扩展性。该算法适用于计算资源有限,需要减少计算量,能够与用户有效交互,为用户提供精准个性化推荐的推荐系统。
5 结束语
针对传统Item-based协同过滤算法存在的相关问题,提出一种感知用户年龄的Item-based协同过滤推荐算法。新用户进入系统时根据年龄信息,利用相应组内的用户历史信息为其推荐,降低了计算相似度阶段的计算量;采用加权相似度提高了推荐准确度;并且该算法运行在Spark分布式集群,具有可扩展性。通过实验表明,该算法在计算效率和推荐精度方面都有一定程度的改善。
猜你喜欢
小猕猴智力画刊(2022年9期)2022-11-04
黄河之声(2022年10期)2022-09-27
北京航空航天大学学报(2022年6期)2022-07-02
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化·高二版(2022年4期)2022-05-09
新班主任(2022年4期)2022-04-27
汽车观察(2019年2期)2019-03-15
民生周刊(2017年19期)2017-10-25
小学生作文选刊·低年级版(2017年2期)2017-03-06
