
基于强化学习的无人机自主机动决策方法*
2019-06-14 09:26孙楚,赵辉,王渊,周欢,韩瑾
火力与指挥控制 2019年4期
孙 楚,赵 辉,王 渊,周 欢,韩 瑾
(1.空军工程大学航空航天工程学院,西安 710038;2.汾西重工有限责任公司,太原 030027)
0 引言
机动决策是无人战斗机(Unmanned Combat Aerial Vehicle,UCAV)自主空战决策任务系统的重要组成环节[1-2]。将强化学习技术应用于UCAV的机动决策研究中,能够充分发挥强化学习在无样本学习中的优势,其强大的学习能力能够极大地加强UCAV的鲁棒性及对动态环境的适应能力,对提升无人机自主作战效能具有重要的意义。
文献[3]使用RBF神经网络建立了航空兵认知行为模型,一定程度上克服了空间离散方法的使用困境,但RBF网络中隐层节点数固定不变且离散动作集有限,在面对快速变化的空战态势时算法的泛化能力明显不足;文献[4-7]针对连续状态空间强化学习问题进行了详细的研究,提出了一系列用于解决连续状态空间下强化学习应用问题的方法,但其涉及的控制动作控制变量为离散形式,控制情形简单,要应用于复杂的空战机动决策中还有待改进。需要指出的是,现有机动决策的研究成果虽能够解决连续状态空间问题,但均以建立战术动作集与基本动作集为基础[8],将动作空间作离散化处理以实现机动决策。一方面,离散的动作集虽然能够快速生成决策序列,但针对剧烈变化的空战态势缺乏灵活有效的调整方法[9],无法有效应对非典型空战态势;另一方面,离散化粒度粗糙的动作集会使飞行轨迹不够平滑,增大控制系统负担;而离散化粒度精细的动作集会提高问题维度,增大计算负担。采用连续动作集强化学习的机动决策方法建立状态与动作值的映射关系,直接输出连续的动作控制变量,在这种情况下机动动作将不受任何限制,同时控制量形式简单,极大地提升了UCAV的机动灵活性,较好地克服了离散动作集的缺点,对提升UCAV自主控制水平与作战能力而言非常必要。
针对上述问题,本文采用强化学习中的Actor-Critic构架,充分发挥了其解决连续状态空间问题的优势,通过共用隐层的自适应NRBF神经网络,实现对不同态势下真实值函数与最优策略的逼近,在输出效用值的同时输出连续动作控制变量;结合熵理论设计了NRBF神经网络隐层节点的自适应调整方法;通过构建高斯分布的随机动作控制变量平衡学习中“探索-利用”的关系。最后通过不同态势下的仿真分析了决策方法在空战中的对抗能力,并通过对比实验验证了连续动作控制变量集对提升UCAV控制性能的有效性。
1 基本模型
1.1 无人机状态与动作描述参数
设红方UCAV为我机,蓝方UCAV为敌机。状态变量是UCAV对态势的描述,输入状态变量越多,则对态势的描述越全面,但会增大网络学习的计算量,选取基本的状态描述变量x0为
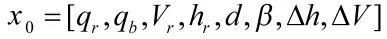
式中,Vr与hr分别是我机和敌机UCAV的速度和高度;qr与qb分别表示我机和敌机UCAV速度矢量与其质心的夹角;ΔV与Δh分别表示我机和敌机的速度差、高度差;β表示我机和敌机UCAV速度的矢量夹角;d表示我机和敌机UCAV的相对距离。
为了充分发掘态势信息,x0经过数据处理后才能作为输入变量,其中包含了对qr,qb,Vr的微分运算,实际输入x为
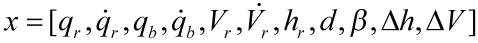
这种选取方法侧重于无人机的位置与速度状态,适合描述双方的空战态势。
状态变量与双方在地面坐标系下的换算关系为
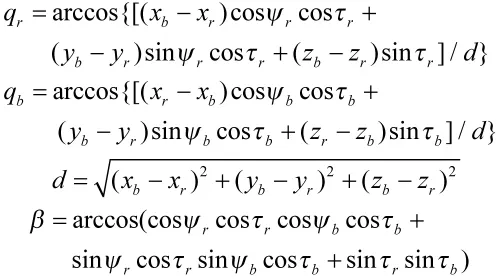
式中(xr,yr,zr)、(xb,yb,zb)分别为我机UCAV与敌机UCAV在地面坐标系下的坐标分别为双方UCAV的航向角;分别为双方UCAV的航迹角。
为简化分析过程,这里选用三自由度质点运动模型,UCAV动力学方程可表示为
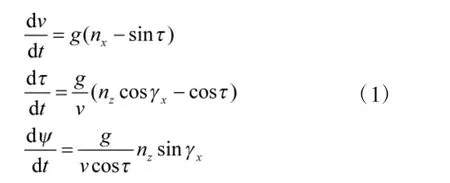
式(1)中,nx为切向过载,用于表示UCAV的切向加速度;nz为法向过载,用于表示UCAV的法向加速度;γx为滚转角。
根据UCAV的动力学方程,可以得到UCAV在地面坐标系下各个方向上的加速度,表示为

通过对式(1)、式(2)进行运算,可以得到UCAV的速度v,航迹角,航向角与UCAV在地面坐标系下的坐标;此外,通过改变 nx、nz与 γx,可以控制UCAV在任意方向上的加速度,因此,可以选择nx、nz与γx3个参数来描述UCAV的动作控制量a,记为

1.2 Actor-Critic强化学习模型
在UCAV机动决策中应用强化学习方法,首先必须解决连续状态空间的表示问题。Actor-Critic构架将动作生成与策略评价部分分离,分别进行策略学习与值函数的逼近,能够较好地解决连续状态空间下的决策问题,其基本结构如图1所示。
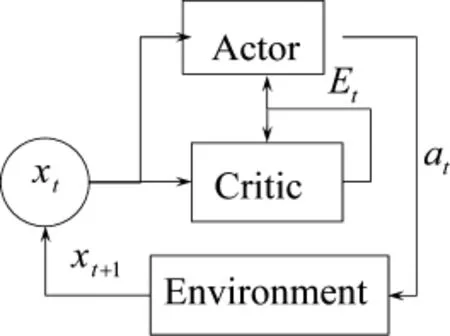
图1 Actor-Critic结构
其中,xt为t时刻的输入状态变量,at为当前策略下t时刻生成的动作控制变量。
Critic部分用于对状态进行评估,是从状态xt到效用值V(xt)的映射关系,表示为

其中,V(xt)是瞬时奖赏r的折扣累积,是状态与动作的评价指标。在真实值函数未知的情况下,由时序差分学习方法[10],设折扣率为γ,V(xt)的更新公式为
同时Critic部分存储了过去的效用值,用于生成误差函数Et。
Actor部分用于实现状态xt到动作at的映射关系,这种映射关系是策略的具体体现,表示为
对于空战机动决策问题,式(4)、式(6)一般由复杂的非线性映射关系表示,本文采用归一化RBF神经网络实现这种映射。
图1的运行流程为:状态xt分别输入Actor与Critic部分,分别输出当前策略下的动作at与误差函数Et;误差Et用于更新Actor与Critic中的参数;动作at作用于环境产生下一个状态变量xt+1。
2 基于连续动作强化学习的机动决策方法
2.1 NRBF神经网络的值函数逼近
以NRBF神经网络作为Actor与Critic中的非线性逼近器,实现从状态到效用值与动作控制量的映射,基本结构如图2所示。无人机获取的状态变量输入后,网络输出为当前状态的效用值V(x)。通过不断地修正网络中的参数,可以实现对真实效用值的逼近。
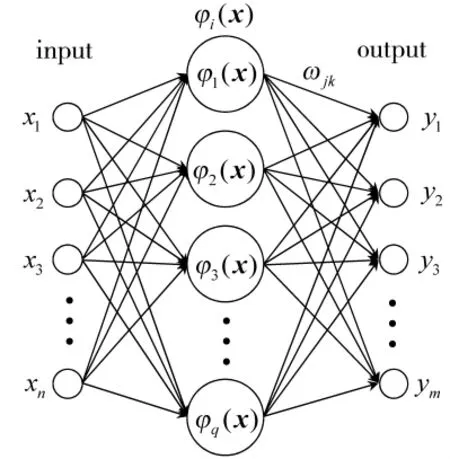
图2 RBF神经网络结构
用于实现非线性映射的基函数采用高斯函数,第j个RBF函数如式(7)所示。
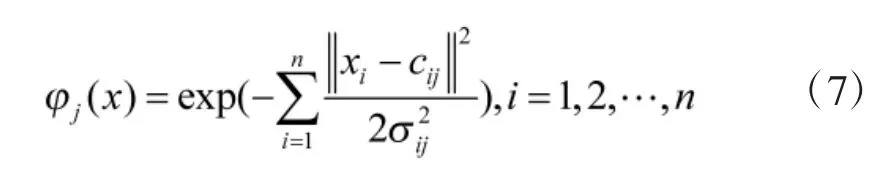
其中,x为输入状态变量,cij为第i个基函数的中心,σij为基函数中心的宽度。
输出层的线性映射表示为
其中,wik表示各个连接节点的权重,m表示输出节点的个数。
NRBF神经网络提高了网络的插值性能,降低了网络对高斯基函数中参数的敏感度[11],这些特性均有助于提高网络的泛化性。将RBF神经网络的输出进行归一化处理,即得到NRBF神经网络,表示为
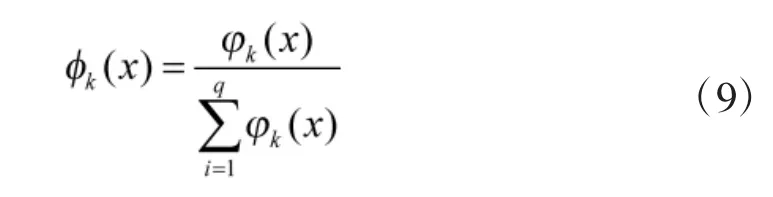
网络采用TD方法逼近真实值函数,则TD误差表示为
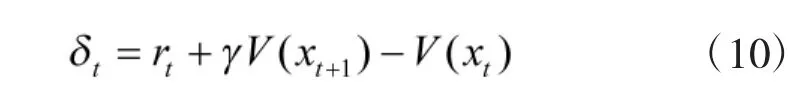
其中,rt为瞬时奖赏,γ为折扣率。
2.2 状态空间自适应调整方法
NRBF神经网络中,隐层节点个数q、中心ci、宽度σi与输出层的连接权重wij直接决定了网络的性能,对于本例中的无样本学习情况,并没有办法事先确定完整抽象空战态势特征的隐层节点个数,较好的方法是令网络起始节点数为零,在训练过程中自行判断是否需要添加新的节点,故为其设计自适应调整的优化方法。
2.2.1 结构学习
由于强化学习相当于采用无标签数据学习,对每一个输入xt,仅能得到瞬时奖赏rt,因此,采用TD误差δt作为增加节点的准则,表示为

其中,δmin为TD的误差阈值。
同时计算输入状态变量到每一个基函数中心的距离和d,如果新输入向量满足
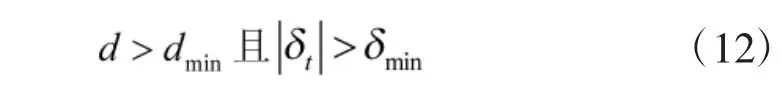
则增加一个节点。该节点增加规则基于这样一个推论:如果新输入状态变量到每一个基函数中心的距离和越大,那么它与所有基函数的不相关性就越高,现有基函数对该状态变量的表达能力就越弱。
距离d的计算方法决定了节点增加方法的性能,通常采用的欧式距离公式的问题在于:该公式是距离的几何度量,而在空战态势评估中,两个相近的状态变量可能代表完全不同的态势,这里结合熵原理,以相对熵作为距离的评判标准。
定义对输入状态变量xt,它与任意基函数中心的相对熵为
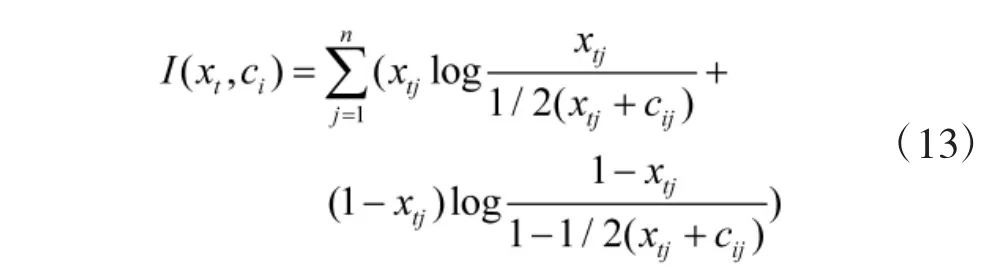
则相对熵距离可表示为

当输入状态变量到其他所有基函数中心的相对熵距离和小于dmin,表明该状态变量包含的相对信息量较小,不应增加新的节点;反之,表明该状态变量包含的信息量较大,现有基函数的表达能力不足,需要增加新的节点。
对于新增基函数的中心,直接选取当前输入样本,新增基函数的宽度为
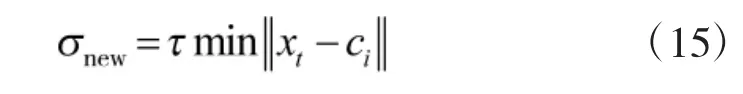
其中,为重叠系数。
2.2.2 参数学习
基于TD误差,误差函数表示为

由式(5),使用当前估计的值函数代替真实值函数,采用梯度下降法对权重向量w的误差求负导数,可以得到对参数w的更新规则为
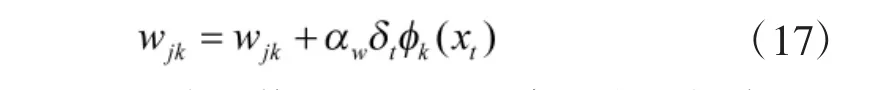
其中,αw为对连接权值向量的学习率。同理分别对ci与σi的误差求负导数,可得到基函数中心与宽度的更新公式为
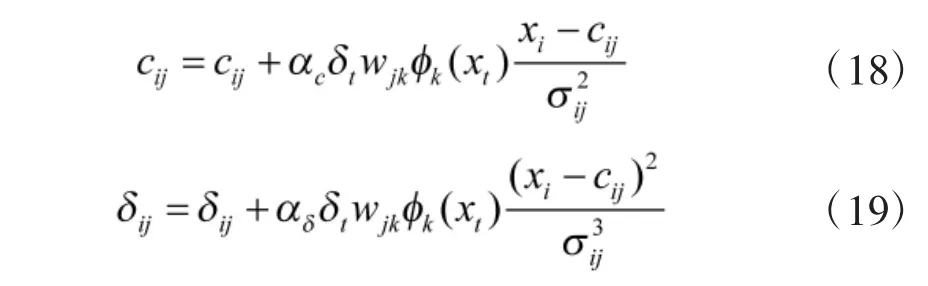
其中,αc与αδ为对应参数的学习率。
2.3 无人机动作选择策略
通过网络输出的动作控制变量本质上是过去所有瞬时奖赏的折扣累积,因此,输出层的权重更新方法体现了对过去经验的“利用”,为了平衡网络对于未知动作的探索,有必要设计随机动作选择方法。
设对状态xt,网络输出动作值为at,表示为
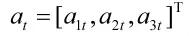
以纵向过载nx为例,网络输出的a1t并不能直接作为动作值,需要将其转换为符合无人机控制特性的 a1t',设
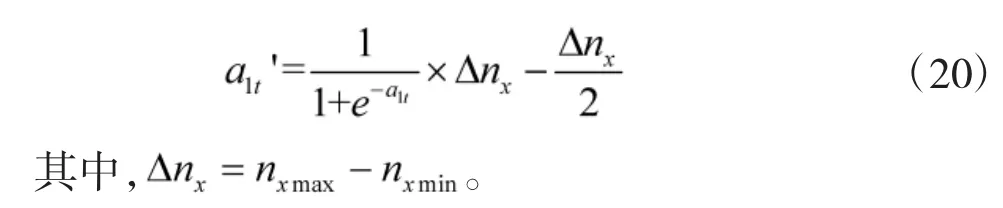
设当前状态下的输出为a1t'=nxt,服从N(nxt,σ(k))的高斯分布,k表示网络运行次数,其标准差为k的函数,设

其中,b1,b2为参数。
受实际情况的约束,3个控制变量均有固定的取值范围,将a1t'的概率分布修改为
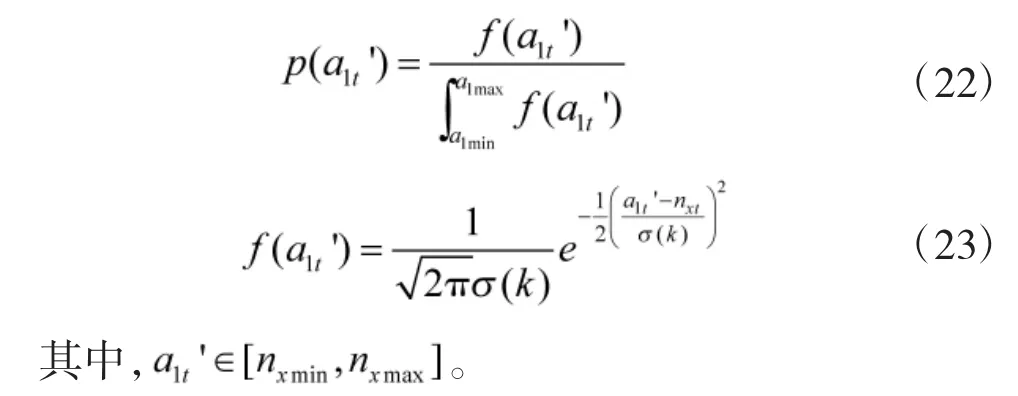
对每一个 a1t',按 p(a1t')的概率在内随机选取动作值,当参数确定时,选取动作值的概率分布仅由k决定。
令a1t'=nxt,可得选择网络输出动作值的概率为
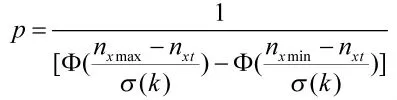
图 3 列出了在 a1'∈[-10,10],b1=20,b2=1 000,nxt=0情况下的动作值概率分布情况。
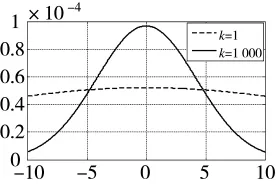
图3 动作控制变量概率密度
可见在k=1时,概率分布曲线平缓,近似于均匀分布,表明在初次试探时,无人机更注重对未知动作的探索;当k=1 000时,概率分布集中于0附近,表明此时无人机更倾向于选择与网络实际输出相近的动作值;同时,如果网络的后期训练效果不够理想,可以通过人为减小k值以增强对未知动作的探索,且k值的改变并不直接作用于网络的参数更新过程,有效提高了网络的训练效果。
2.4 奖赏函数设计
对空战其中一方而言:当达成导弹发射条件时,获得最大奖赏;当态势有利时,获得一般奖赏;当态势不利时,获得负奖赏。依据该原则,设计奖赏函数如下。
2.4.1 角度奖赏
式(24)中:φ为本机速度矢量与目标线的夹角;q为目标速度矢量与目标线的夹角;φmax为导弹最大发射偏角。
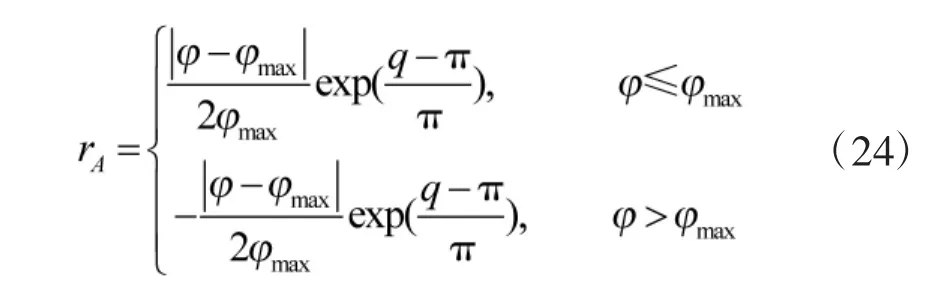
2.4.2 速度奖赏
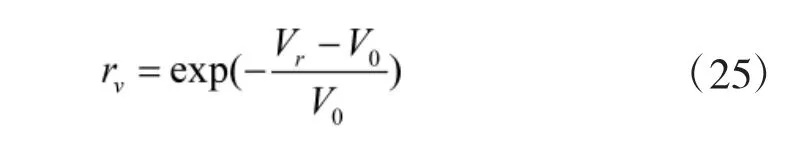
其中,V0为最佳空战速度,表示为
其中,Vmax表示无人机最大飞行速度,dmax表示雷达最大搜索距离。
2.4.3 距离奖赏
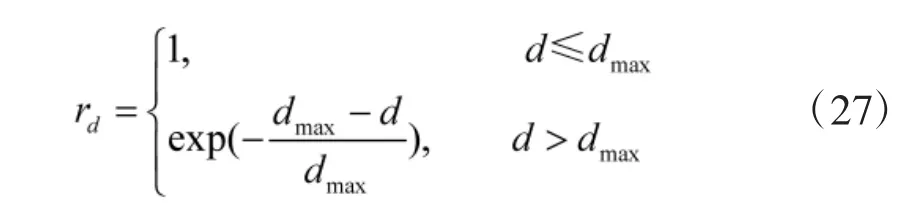
2.4.4 高度奖赏
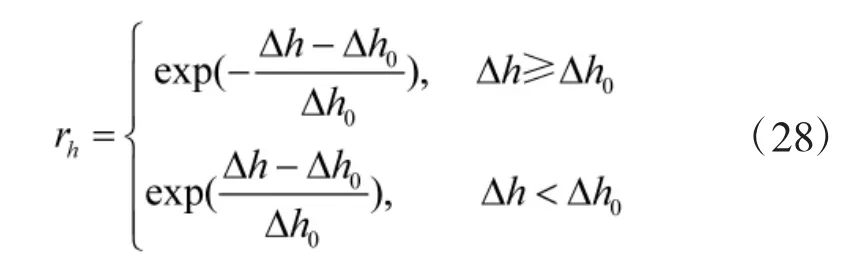
其中,Δh0为最佳空战高度差。2.4.5 达成发射条件奖赏
设计导弹发射条件为:vr≤1.8 Ma,|φ|≤π/3,π/3≤q≤5π/3,d≤10 000 m。当本机对目标达到上述态势时,变量con=1(否则为0),获得奖赏
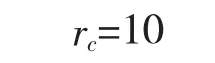
当敌机形成上述态势时,本机获得奖赏
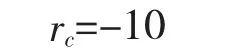
2.4.6 环境奖赏
设置环境奖赏的主要目的是使无人机能够较好地适应环境。实验发现:在网络训练的初期,网络动作选择策略的探索主要是为了适应飞行环境,避免危险的飞行动作,如:飞行高度低于最低安全高度或飞行速度超过最大允许速度。此过程耗时较长,且此时网络对空战态势奖赏不敏感,对提升无人机机动决策能力的贡献较小,因此,为了提升网络训练效率,环境奖赏的力度要远大于其他奖赏,促使网络迅速生成符合环境约束的动作策略。
设环境奖赏为re,表示为
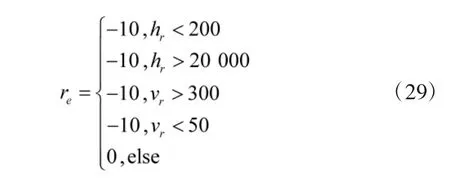
综上所述,总奖赏函数表示为
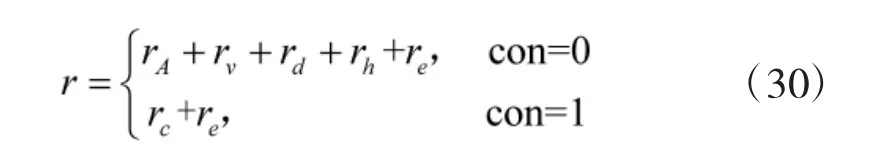
2.5 机动决策方法结构
基于以上的分析,机动决策强模型如下页图4所示。
输出为3个动作控制量与当前状态的效用值V(xt),参数学习模块通过结合存储的V(xt-1)对隐层与输出层进行参数更新;动作控制量首先经动作选择策略模块选择要采取的动作值,再作用于环境,产生下一个状态变量xt+1。
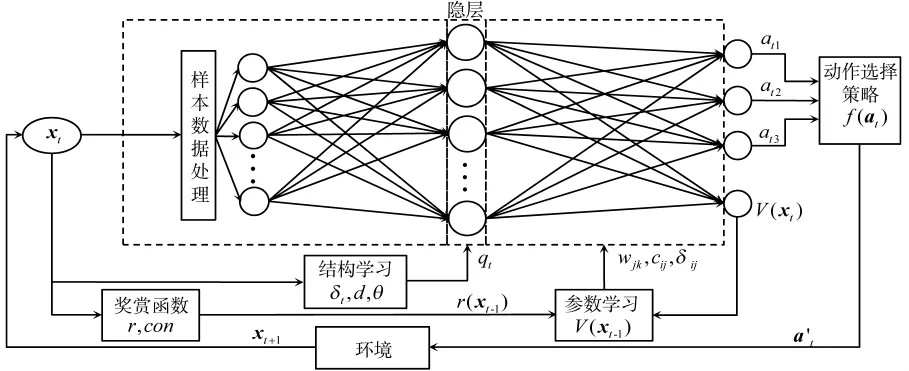
图4 基于强化学习的机动决策方法
算法流程为:
Step 1:数据初始化;
Step 2:读取输入变量并处理生成xt,产生3个动作控制量与对当前状态的估计效用值V(xt);
Step 3:计算瞬时奖赏 rt,并按式(11)与式(14)计算输入状态变量到每一个隐层节点的相对熵距离与 TD 误差 δt,如果满足式(12),则增加一个节点,否则节点数不变;
Step 3:动作选择策略对网络输出动作控制量进行处理,生成作用于环境的动作控制量;
Step 4:结合缓存的 V(xt-1),按式(17)~ 式(19)更新网络参数;
Step 5:判断是否达到最大学习步数,是则结束;否则将动作控制量作用于环境,生成xt+1,转到Step 2。
3 仿真实验
3.1 空战对抗实验
为了加快计算速度,仿真设置敌方无人机按固定航迹飞行,起始点为(0,0,0),匀速 200 m/s,共有直线飞行、蛇形机动、盘旋飞行3个情形,其状态参数事先以数组形式存储,按时间输出作为环境的反馈信号。3种情形下的我方UCAV参数设置如表1所示。
这里选取了训练后期的3条飞行轨迹与最终收敛的飞行轨迹,并给出了不同训练次数下法向过载控制量的变化曲线,结果如图5~图13所示。
其中蓝色轨迹为敌机飞行轨迹。
图5~图13表明:前期策略学习侧重于对环境的适应,由于本例中环境奖赏力度较大,导致起始累积奖赏较低;训练进行到3 000次时,3种情形下的无人机动作选择策略均可以较好地适应飞行环境的约束,未出现早期训练过程中超出范围限制的危险飞行动作。此时无人机已经能够对敌机的机动动作做出一定的反应,但整体航迹上机动决策的质量并不高,末端仍然存在错过敌机的现象。控制量曲线的变化速率较快,表明此时的动作选择策略中仍然包含了较大的随机因素;继续进行训练,无人机与敌机航迹末端的距离明显减小,基本能够分辨出无人机要采取的机动动作,累积奖赏值趋于收敛,表明动作选择策略已接近最优;最终,无人机的动作选择策略会使航迹收敛,动作值中随机因素基本消失,控制量曲线趋于平滑。
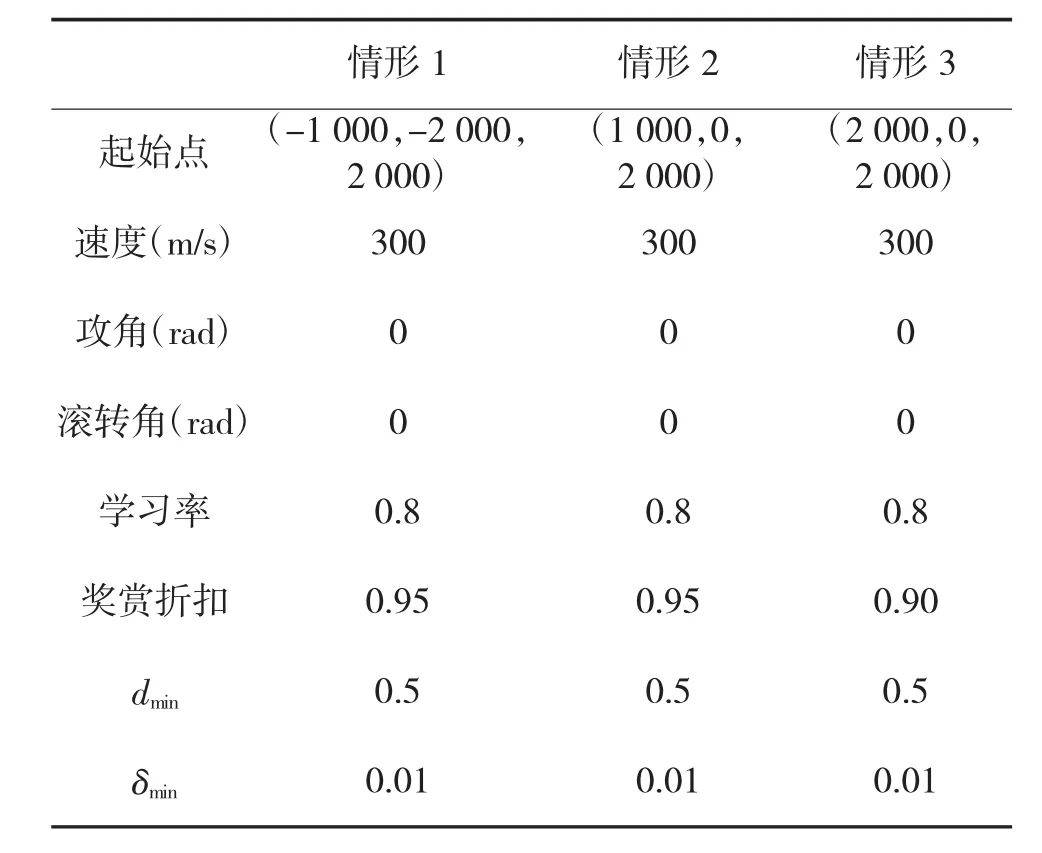
表1 仿真参数设置
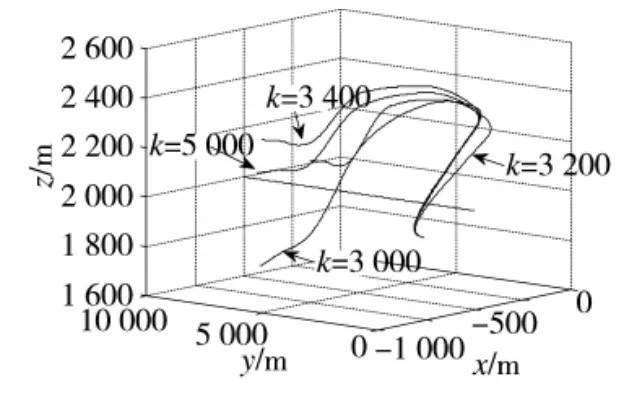
图5 敌机直线飞行的训练轨迹
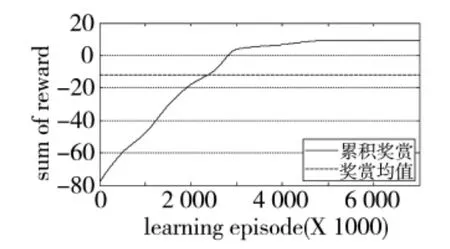
图6 累积奖赏变化曲线
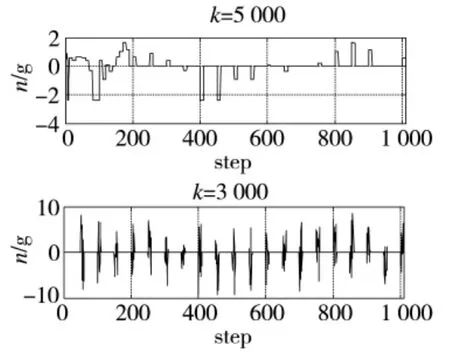
图7 法向过载控制量变化曲线
以上3个情形的仿真表明:无人机的动作选择策略在经训练后能够依据态势输出合理的连续动作控制量,具备空战能力。
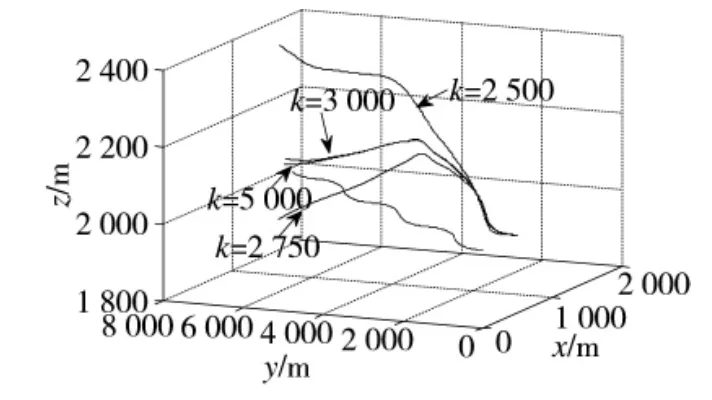
图8 敌机蛇形机动的训练轨迹
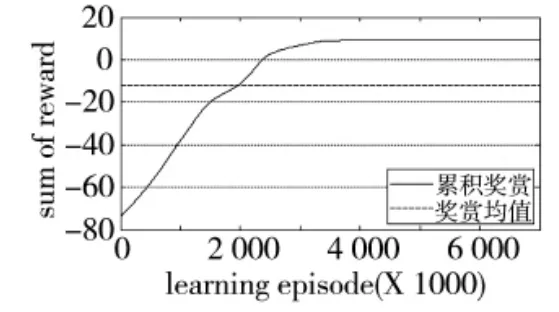
图9 累积奖赏变化曲线1
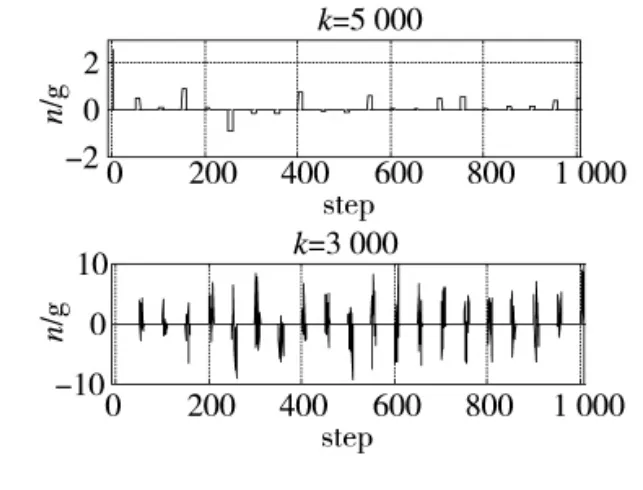
图10 法向过载控制量变化曲线1
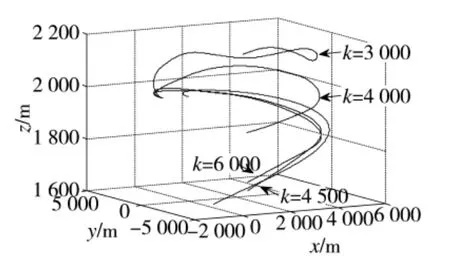
图11 敌机盘旋飞行的训练轨迹
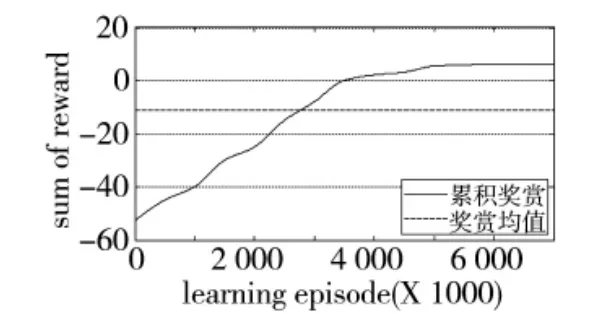
图12 累积奖赏变化曲线2
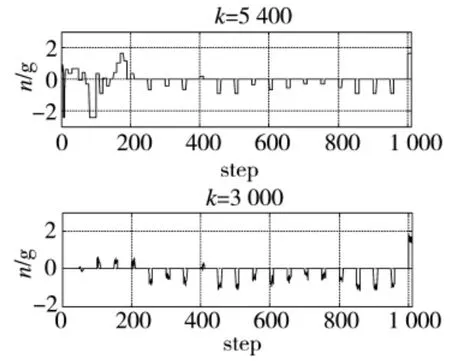
图13 法向过载控制量变化曲线2
3.2 动作选择策略性能分析
采用文献[12]中的基本机动动作集实现情形3中的无人机飞行轨迹。主要采取的动作与控制量如表2所示。

表2 基本机动动作操纵指令
按相同的仿真步长对无人机分别施加控制量,得到控制量nz与γx的变化曲线如图14、图15所示。
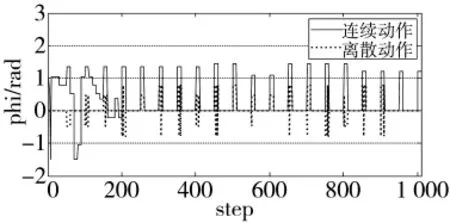
图15 滚转角控制量变化曲线
图14、图15表明:由于法向过载nz的取值仅为1,nzmax或-nzmax,采用基本机动动作集在每一步长上只能施加固定的控制量,而情形3中无人机盘旋过程中的法向过载保持在2 g以内,无论起始采取右转弯或右俯冲均使控制量产生严重的跳变,如果考虑控制系统的延迟特性,还会进一步降低控制效果;而连续动作情况下产生的控制量连续性较强,整体上控制量分布较均匀。因此,采用连续动作控制量更有利于无人机的控制。
3.3 自适应节点构建策略性能分析
3.1节中情形3下的奖赏值变化曲线如图16所示,其中奖赏1与均值1曲线为采用相对熵距离的奖赏与均值;奖赏2与均值2曲线为采用欧式距离的奖赏与均值。图17记录了第一次训练过程中1 010个仿真步长(40 s)内RBF神经网络隐层节点数目的变化情况,可以看出:在训练开始阶段,采用相对熵距离公式与欧式距离公式的网络节点增长速率相同,表明在训练开始阶段,由于网络隐层节点数少,对新状态变量的表达能力较弱,因此,此时节点增加速度较快;在训练后期,两者产生了显著的差异,采用相对熵距离的网络隐层节点数最终为616个,而采用欧式距离的隐层节点数为671个,通过观察图16中效用值变化曲线,采用相对熵距离与欧式距离计算方法的效用值的均值分别为-11.113 2与-11.925 9,最终效用值保持在6.387 0与6.106 3,表明两者的动作选择策略性能相近。基于相对熵距离的网络用较少的隐层节点数,达到了与采用欧式距离的网络相同的训练效果,证明基于相对熵距离的自适应节点构建方法更加高效。
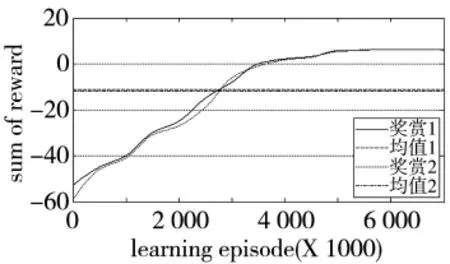
图16 奖赏值变化曲线
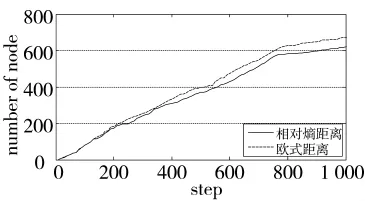
图17 隐层节点数量变化曲线
4 结论
本文设计了基于连续动作控制变量的无人机机动决策方法,采用共用隐层的NRBF神经网络结构分别逼近效用值与动作控制变量,提出了基于相对熵距离的神经网络隐层节点自适应构建方法,并设计了基于高斯分布的随机动作选择策略。仿真实验结果表明,所设计的算法能够满足无人机机动决策的需求,相对于采用有限离散动作集的机动决策算法,该方法产生的航迹更为平滑,无人机的机动也更加灵活;同时,该自适应节点构建策略有效降低了RBF神经网络的隐层节点数,提高了算法运行效率。
猜你喜欢
舰船科学技术(2022年11期)2022-07-15
文史春秋(2022年4期)2022-06-16
小哥白尼(军事科学)(2022年1期)2022-04-26
煤气与热力(2022年2期)2022-03-09
北京航空航天大学学报(2021年4期)2021-11-24
考试与评价·高二版(2021年1期)2021-09-10
当代陕西(2019年12期)2019-07-12
汉语世界(The World of Chinese)(2019年1期)2019-03-18
软件(2017年6期)2017-09-23
连环画报(2015年12期)2016-01-14
