
基于迭代的磁共振指纹参数量化算法改进
2019-06-12 07:38:58商国灿
中小企业管理与科技 2019年11期
商国灿
(中南民族大学生物医学工程学院,武汉430070)
1 引言
MRF[1]作为一种全新的定量MRI 技术,可以通过一次数据采集同时获得多种人体组织参数,大大地提高了成像速度,并且改善了噪声对图像质量的影响。但当前MRF 研究仍处于初期,参数量化不精确,尤其是T2 参数的量化,因此我们对参数量化算法进行研究。
由于高度欠采样,直接匹配方法中多帧MRF 空域图像(含伪影),再做字典与指纹匹配,图像质量很差;而迭代方法[2]则采用的高欠采样的k 空间数据(真实数据),通过逐次迭代投影梯度方法来获取较高质量的多帧MRF 空域图像,从而获得质量较优的定量参数图像,但运行时间太长,这两者都不适合临床推广。为了进一步提高参数量化精度,本文采用迭代方法并采用覆盖树与逼近最近邻搜索[3]来加速投影过程,从而提升图像质量,并同时加速参数量化的速度。
2 方法
与MRI 不同,MRF 采用伪随机的数据采集方式,主要体现在翻转角TR 和重复时间FA 的随机组合上。MRF 技术主要包括数据采集、字典设计与生成和参数量化算法三部分。先通过脉冲序列进行高欠采样,得到多帧高欠采样k 空间数据,然后进行反傅里叶变换,得到多帧空域图像,对多帧图像逐像素将信号值连起来,就是一条“指纹”信号,它用于区分不同的组织类型。然后采用TR,FA,{T1,T2,df}等参数进行字典设计,字典包括了所有组织类型的可能性。最后对字典和指纹进行奇异值压缩(加速计算),对逐像素对指纹信号在字典中寻找最佳匹配,从而返回T1,T2,PD,B0 图像。
2.1 字典建立
由于人体不同部位的组织类型不同,相应的T1,T2 值也不同,本文主要考虑了T1,T2,df(磁场的不均匀性)三种参数,为了折中图像质量与计算时间,每条字典条目的长度为1000。按照最小值,步距,最大值分段来设置的,形如T1=[100:20:2000,2300:300:5000],T2=[20:5:100,110:10:200,400:200:3000],off=[-250:40:-190,-50:2:50,190:40:250]/1000。
考虑T1>T2,T1 与T2 的合理组合为3318,最终{T1,T2,df} 的参数组合为3318×55=182490 组。考虑磁场的不均匀性df,字典信号生成公式[4]如下式(1)(2)所示,施加180 度反转脉冲后磁化矢量变为m0=[0,0,-1]。设第i 个脉冲TRi/2 时刻磁化矢量为[mx,i,my,i,mz,i],第i+1 个脉冲TRi+1/2 时刻的磁化矢量为[mx,i+1,my,i+1,mz,i+1],时间间隔为t,考虑df 的影响,则两个时刻的磁化矢量满足公式:
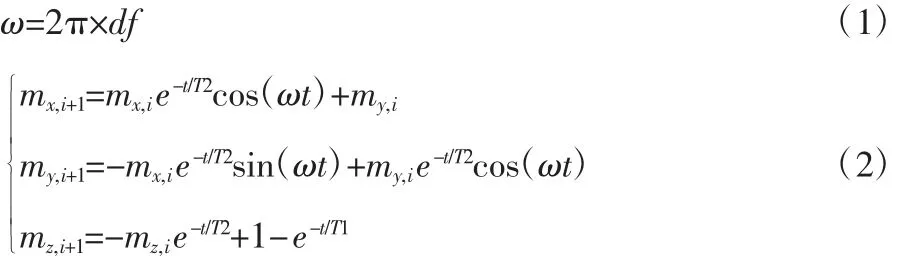
字典的建立需要设定伪随机变化的TR 和FA,FA 采用分段函数实现,范围为15~60 度,TR 的范围为10~14ms,FA 和TR 都加了随机加性噪声。针对一组固定的{TR,FA},将上述{T1,T2,df}组合代入方程(1)(2),进行1000 次计算便可得到长度为1000 的字典信号,重复计算,便可得到大小为1000×182490 的字典,然后采用奇异值压缩[5]将字典压缩成200×182490。
2.2 模型建立与采集重建
采用BrainWeb 模型(第94 层)进行MRF 成像的数据仿真,大小为181×217×181,由于傅里叶变换要求矩阵大小为2的N 次方,通过填零处理将模型扩大为256×256。大脑模型由7 种不同组织组成,每种组织包含T1,T2,质子密度和df 信息。
对上述模型,采用1000 组{TR,FA}构成的序列参数,采用EPI 轨迹模拟1/16 高欠采样数据采集,得到1000 帧高度欠采样的k 空间数据,并采用2D IFFT 进行重建,得到1000 帧图像,然后逐像素获取指纹信号,然后对长度为1000 的指纹信号实施奇异值压缩,得到长度为200 的MRF 信号,供后续参数量化算法使用。
2.3 基于迭代的参数量化算法及改进
对BrainWeb 数据模型,将压缩后的字典和高度欠采样的k 空间数据Y 作为参数量化算法的输入。高度欠采样的信号模型如式(3)所示,Y 是高欠采k 空间数据,X 是估计值,noise是噪声,信号模型的主要任务是从Y 中恢复X。可采用式(4)所示的有约束凸优化方法来解决该问题。
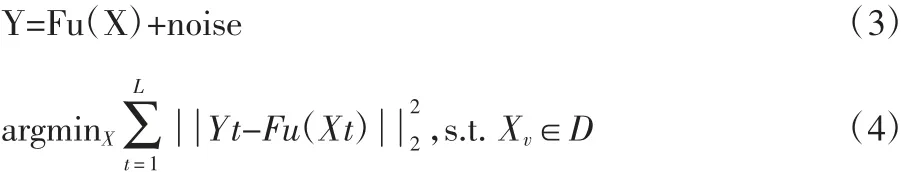
式(4)的最优解可采用迭代投影梯度算法来求解,如式(5)(6)(7)所示,通过逐次迭代投影,从而获取更精准的Xn+1及指纹信号。
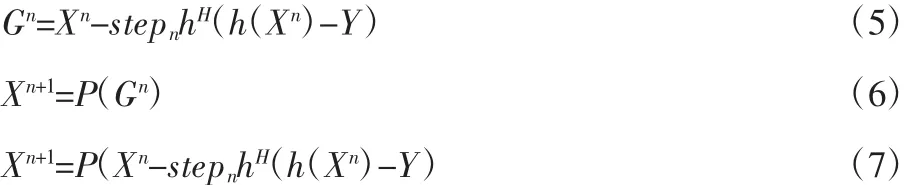
投影的详细步骤如式(8)~(11)所示,式(8)表明在字典中寻找像素位置处的最佳匹配条目,式(9)表示最佳匹配条目的索引号,式(10)用来计算质子密度,式(11)表示投影更新。
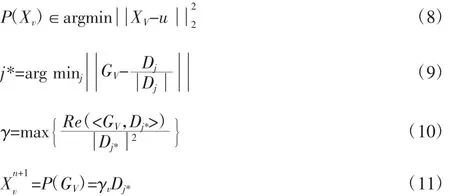
自适应步长更新如式(12)所示,当ω<stepn时,则将步长变为stepn/2,然后重复前文梯度投影步骤及更新Xn+1,直到满足ω>stepn,则进行下一次迭代。

终止条件则如式(13)所示,如果满足式(13)则迭代程序结束;若迭代多次仍不满足式(13),则当迭代次数达到50 次时,迭代程序终止。最后在字典中逐像素搜索最佳匹配的条目,返回T1,T2,PD,B0 图像。
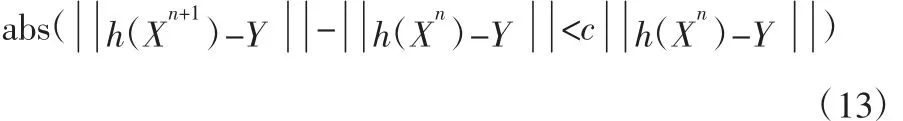
覆盖树[6]是专门用于最近邻搜索的一种数据结构,必须满足嵌套、覆盖和分离三个属性,使得节点在不同的尺度上,形成了覆盖多个尺度的数据网,从而方便逼近最近邻搜索的执行,更快地找到最佳估计。逼近最近邻搜索则如式(14)所示,式(14)表明查询条目p 的不精确的最近邻条目为q,当且仅当式等同于迭代算法中精确的逼近最近邻搜索。
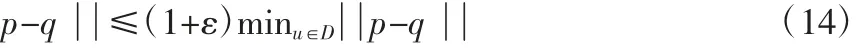
基于以上方法我们做出以下几点改进:改进了{TR,FA}的设计,原文TR 设计成常数(10ms),这里设计成随机噪声;增大了EPI 采样轨迹相邻帧之间的k 空间行间隔,提高了数据的不连贯性;考虑了字典参数的条件,从而使得字典条目减少了几万条,从而大大地缩短计算时间;将搜索步长从改为,使得搜索步骤更加精细,从而提高量化精度。
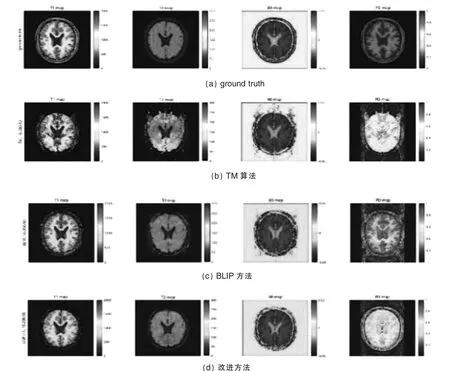
图1 BrainWeb 模型参数量化算法结果
3 结果
本文采用BrainWeb 模型数据,分别对直接匹配法、迭代投影方法和改进方法进行算法实现,T1,T2,PD,B0 的定量图像结果如图1 所示。
由图1 可知,改进方法能够极大地改善图像质量,尤其在脑部图像的边缘保护上,改进方法要比直接匹配方法和BLIP 方法好很多。直接匹配方法存在较严重的混叠伪影,BLIP 方法对混叠伪影有所改进,改进方法则基本上没有混叠伪影。
4 结论
MRF 是一种全新的定量MRI 成像技术,其采用的特殊参数量化算法来获取多种参数的精准量化图像,但MRF 成像领域仍然有许多技术难点亟待攻克。改进的参数量化方法在大大改善T1、T2 图像质量同时提高了量化效率,为MRF 走向临床提供了一定的技术支撑。
猜你喜欢
家教世界(2023年28期)2023-11-14 10:13:50
家教世界(2023年25期)2023-10-09 02:11:56
小哥白尼(趣味科学)(2021年11期)2021-02-28 08:35:00
小天使·一年级语数英综合(2020年10期)2020-12-16 02:57:11
创新作文(小学版)(2016年19期)2016-08-22 05:54:08
读者(2016年14期)2016-06-29 17:25:50
测绘科学与工程(2016年4期)2016-04-17 06:51:13
自动化学报(2016年8期)2016-04-16 03:39:00
青少年科技博览(中学版)(2015年7期)2015-08-12 18:50:24
测绘科学与工程(2014年2期)2014-02-27 07:05:49
