
基于多部情感词典与SVM的电影评论情感分析
2019-06-06 01:20:02吴杰胜王诗兵
阜阳师范大学学报(自然科学版) 2019年2期
吴杰胜,陆 奎,王诗兵
(1.安徽理工大学 计算机科学与工程学院,安徽 淮南 232001;2.阜阳师范学院 计算机与信息工程学院,安徽 阜阳 236037)
近些年来,随着我国的经济发展状况越来越好,人们的生活质量也逐步上升,电影产业也越来越发达,每年的电影产量都在逐步上升。但随着产量的增多,质量的好坏也受到广大网友的评价。因此,每部电影出来之后,广大网友都会在网上发表评论,这些海量的主观评论文本数据中包含着丰富的情感信息,如何对这些情感信息进行情感极性分析,就是我们研究的焦点。
电影评论与其它文本评论数据有很多不同,比如它涉及到电影本身传达出的情感信息,还有评论作者本身对某个电影人物的态度观点等。因此电影评论具有元素多样化,情感信息丰富,语言表达灵活等特征,所以对此类评论文本情感分析至关重要,对电影产业的发展起到促进作用。
1 相关工作
情感分析是属于自然语言处理领域的一个子领域,近年来关于情感分析的研究一直在不断进步。目前国内外对情感分析的研究主要集中在微博消息领域,但是对电影评论领域的情感分析研究很少,因此本文主要研究这个领域的情感分析。文献[1]指出情感即文本作者的意见和观点,因此对情感的分析也可以理解为对意见的挖掘,文本意见挖掘属于数据挖掘的子类,主要是利用现有的计算机技术挖掘出蕴含在文本间的观点、情绪等元素。目前主要通过构造相应的情感词典和利用机器学习算法这两种方法来对文本进行情感分析、极性分类。
基于情感词典的方法进行情感分析出现比较早,而且它对细粒度的文本情感分析效果极佳。Baccianella等人提出一种利用情感词典提取情感特征进行情感分析的方法[2];朱嫣岚等人就是在基础情感词典的基础上,构造了两种计算词汇语义的情感权值方法[3];Jose等人在基础情感词典的基础上,构造了一种分类器,可以对文本语义之间的歧义进行消除,从而提高情感分析准确率[4]。
基于机器学习的方法进行情感分析,主要通过选取一些特征标注训练集和测试集,接着利用朴素贝叶斯、支持向量机(support vector machine,SVM)等分类器进行情感分类。文献[5-6]将朴素贝叶斯与支持向量机相结合对微博进行情感分析。Pang等人首先提出运用机器学习方法进行情感分析[7],但是在不同的分类方法下,发现还是SVM这种方法最好,情感分类效果最准确。
总之,这两种方法都各有优劣,基于情感词典的方法相对可以处理评论文本这种细粒度的情感分析,基于机器学习的方法需要人工构造训练集,花费时间较多。因此本文提出一种基于情感词典与SVM相结合的方法对电影评论进行情感分析,主要集中在对情感词典进行扩充,尤其是构造电影评论特定领域的情感词典,实验论证该方法比单一的方法效果好。情感分析系统流程图如图1。
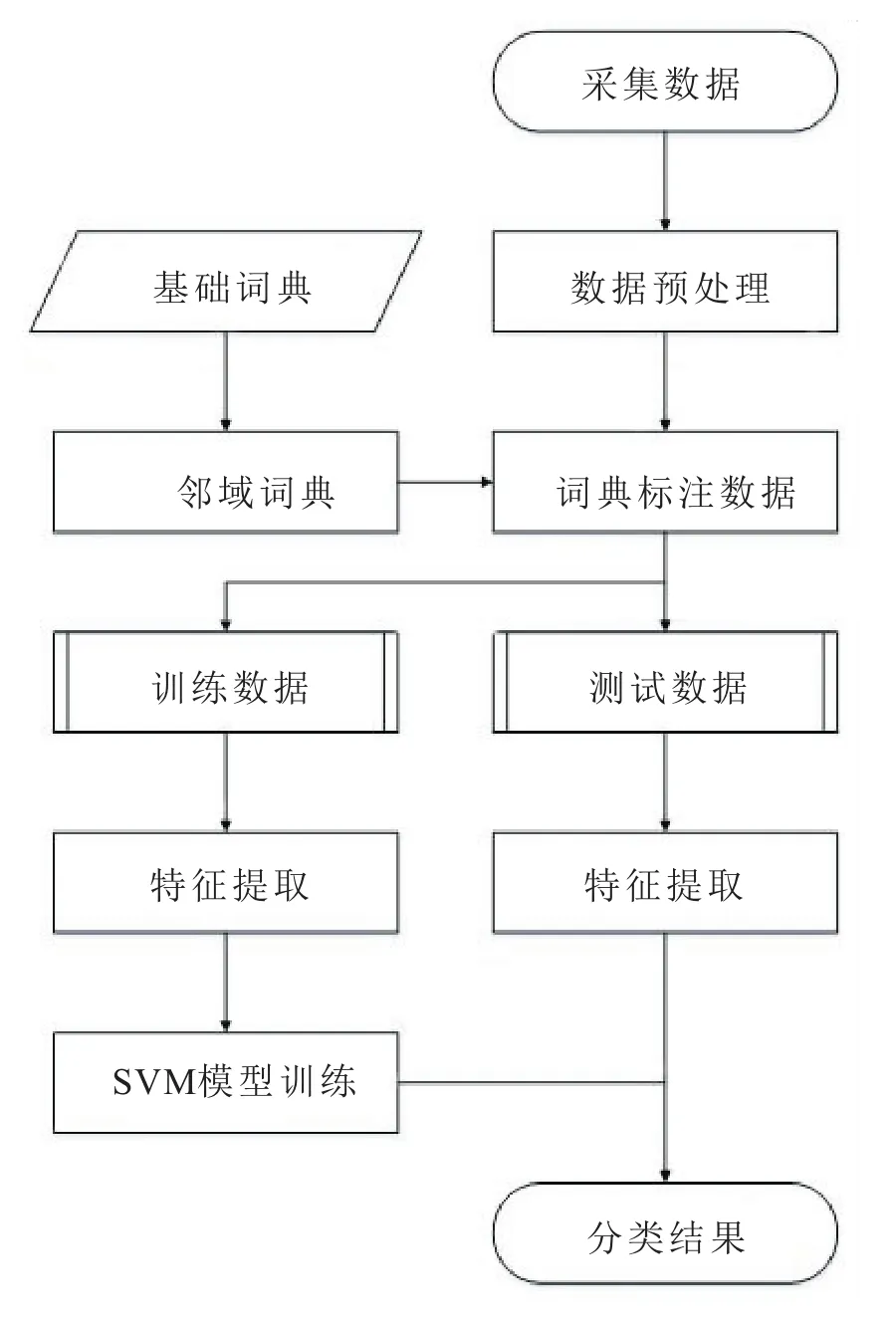
图1 情感分析系统整体流程图
2 情感词典的构建
目前国外的情感词典《General Inquirer》完善度很高,但在国内还没有一部这样比较完善的词典,所以对电影评论来说,有一部完善的情感词典是很有必要的。现在国内使用常见的代表性情感词典有知网HowNet情感词典,台湾大学的正、负向情感词典和大连理工大学中文情感词典库等等。所以本文在此基础词典的基础上进行整合和优化,构建了除此基础情感词典之外,还构建了否定词词典和程度副词词典,同时对电影评论用改进的PMI(pointwise mutual information)算法专门构建了一个电影评论领域情感词典,其中将基础情感词典中正负向情感词权值分别设为1和-1。
2.1 电影评论文本的预处理
电影评论具有元素多样性、主题针对性、语言随意性等特点,故需要进行预处理。其步骤如下:
1)将评论文本中一些链接、图片、视频、动画等无关因素去除。这些内容虽对情感分析有一定作用,但是影响不大,可以删除;
2)对数据进行整理,由于电影评论数据由评论和评分两部分构成,所以过滤只有单一部分的数据;
3)删除停用词,比如助词“的”,代词“她,他”等之类的词;
4)分词和词性标注,本文使用中科院ICTCLAS软件进行分词与词性标注。
2.2 领域情感词典的构建
由于基础的情感词典还不完整,对情感词的概括是有限的,所以还需要针对电影评论文本上一些特有的情感新词进行识别,从而对这些新词集合构建一个词典。本文利用PMI算法计算新词与种子词之间的语义相似度,最后计算未知新词的情感极性。PMI又称点互信息,主要是可以计算词与词之间的相似度。未知词w1和种子词之间的相似度计算公式为:
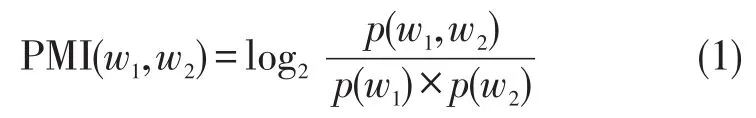
其中P(w1,w2)表示(w1,w2)共同出现的概率,p(w1),p(w2)分别表示w1,w2单独出现的概率。
因为log函数是一个单调递增函数,所以若公式(1)的计算结果大即相似度高,则可知两个词情感极性相同,否则就不同,本文设定计算结果大于1即为相似度高。但仅仅计算一对词的语义相似度在情感分析中不具有说服力,所以本文在考虑这个的基础上,在统计评论文本情感词的词频时,根据结果选取了30对正负向情感极性高的种子词,构成正向的情感词集合Wp和负向情感词集合WN,用来考察多词之间的语义相似度。同时对PMI公式进行改进,得出新词w的情感极性判断的新公式:

式(2)的值如果大于等于0,则新词的情感极性为正向;小于0,新词的情感极性为负向。
2.3 否定词词典
否定词词典包括否定副词和反问词两部分。文献[9]指出否定副词和反问词修饰情感词时,都会改变词的情感极性,但反问词语气更强,而双重否定不会改变词的情感极性,但是语气会更加强烈。通过筛选共获取25个否定词,示例如表1。
2.4 程度副词词典
程度副词词典来自于知网词典库。将这些词一共分为6个等级。等级分别是超、最、很、较、稍、欠。分别对这6个等级给予一定的权值,对所修饰的情感词的情感强度扩大一定的倍数。示例如表2所示。

表1 否定词词典和双重否定词词典示例
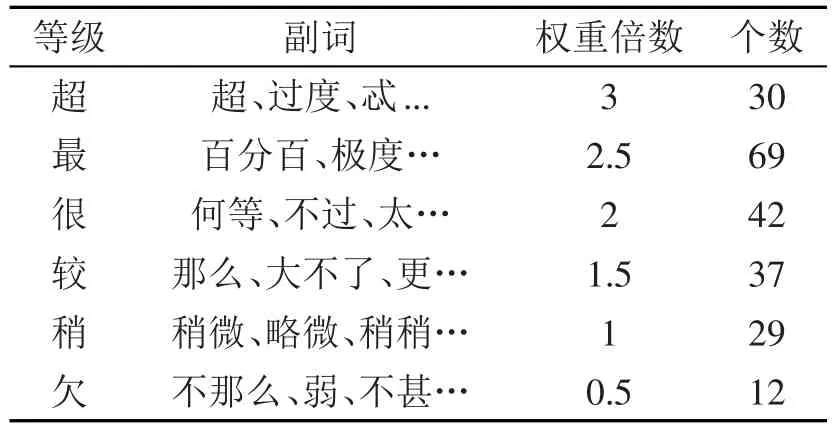
表2 程度副词词典示例
3 情感分析、计算和SVM特征选择
3.1 情感分析与计算
本文提出的基于情感词典和SVM的电影评论情感分析方法,因为SVM是一种有监督的机器学习算法,首先需要构造训练集来对SVM模型进行训练,然后再对测试数据进行情感分类。因此本文首先根据用户评分挑选出若干条评论文本,并将之与多部情感词典相匹配进行情感权值计算,若评论文本情感权值大于等于0,情感极性标为1代表正向情感;若评论文本情感权值小于0,情感极性标为-1代表负向情感。将这些情感极性的结果与用户评分进行对比,若正向情感权值的文本在评分中大于等于3且负向情感权值的文本在评分中小于3,则代表两者情感极性一致,则将这些文本选作为训练集数据。具体的计算评论文本情感权值的算法描述如下:
1)对电影评论文本进行预处理;
2)根据构建的情感词典,匹配文本中的情感词,得到情感词若干个;
3)While找到情感词
Do寻找情感词之前修饰的否定词、程度副词;
4)根据情感词典,计算每个情感词的情感权值;
5)对每个情感词权值进行加和得出文本的情感权值,若权值大于等于0标记为1,小于0标记为-1。
基于多部情感词典的电影评论情感分析前需要对评论文本进行综合情感计算。用字母D表示单个评论文本。词语情感值E(Wi)计算公式为:

式(3)中Ni表示情感词前对应的否定词或者双重否定词、反问词的情感权值,Ai表示情感词前对应的程度副词情感权值,seni表示情感词与词典匹配得到的权值,Wi表示情感词语,i为情感词的序号。
若情感词前面出现否定词,则需要考虑否定词的个数,如果为奇数,则词语的情感权值与情感词典中匹配到的词语情感极性相反;如果为偶数,即为双重否定词,则计算的情感权值与情感词典中匹配到的词语情感极性相同。具体计算公式为

其中,k为否定词的个数。
若情感词前面出现反问词,则会改变情感极性并且强度更大,它们的取值大小可以根据情感词典得出权值为-2。
由于否定词与程度副词的相对顺序关系对词语情感权值也有影响,比如“太不好看”和“不太好看”,显然第二句的情感比第一句的情感影响弱一些,情感不一样,因此,当否定词在程度副词之前时,将E(Wi)的大小乘以0.5,;当程度副词在否定词之前时,将E(Wi)的大小乘以-1。具体计算公式为
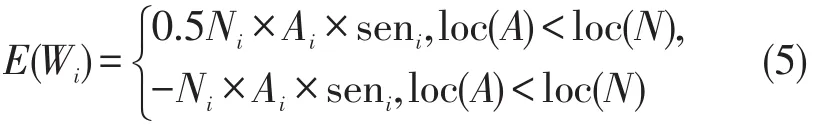
式中loc(A)代表程度副词的位置,loc(N)代表否定词的位置。
因此,最后得出单条电影评论的情感权值计算公式如下:

由公式(6)知,当式(6)的值大于0时,代表此条电影评论情感极性为正向,小于0,代表此条电影评论情感极性为负向。
3.2 特征选择
支持向量机SVM模型是Vapnik等人于1995年提出的,主要用于分类问题,能够解决样本小,非线性等问题,尤其是在解决文本分类问题中,效果极佳。目前常使用的SVM分类工具有LibSVM和SVMLight两种,本文主要用LibSVM来进行情感分类。
我们选用五个特征——词性、否定词、程度副词、正向情感词、负向情感词。选用这五个特征是因为评论中首先词性的作用占很大比重,然后是否定词和程度副词对情感极性的影响也很大,其次情感词是情感分类的核心。因此,将训练样本中得出的正向情感词和负向情感词也作为特征。
4 电影评论情感分析实验
4.1 实验数据与过程
利用网络爬虫工具从国内著名电影评分网站豆瓣上爬取了电影《我不是药神》和电影《战狼2》的评论数据,在经过预处理之后,分别共剩下25 675、23 427条数据作为实验数据。通过计算情感权值与用户评分相结合的方法来标注数据,不需要人工操作标注数据,然后将这些数据随机分为3组,因为分为三组数据,能更好的有效利用数据集进行实验,用前两组作为训练集,是为了更加准确的训练SVM模型,然后最后一组作为测试集,测试分类结果。实验过程中,我们主要进行两组对比实验,第一组是基于基础情感词典的方法,并在SVM上进行情感分类;第二组是基于本文构造的情感词典的方法,并在SVM上进行情感分类。为了对比最终的分类结果,本文采用正确率accuracy来作为性能评价指标,具体公式如下

4.2 实验结果与分析
根据上述的实验方法,我们进行了两组实验,第一组实验,在只有一部基础情感词典的基础上进行情感分类;第二组实验,在本文构建的领域情感词典、否定词典、程度副词词典和基础情感词典共四部情感词典的基础上进行情感分类。实验结果如图2和3。
根据实验结果,可以看出基于四部情感词典的情感分类正确率要比基于一部情感词典的正确率高,验证了本文提出方法的效果。而且由于采用了情感计算和评分相结合的方法标注数据,使得SVM模型训练更加准确,模型的多个参数更加精确,也提高了情感分类的正确率。本文采用的构造四部情感词典的方法,能将电影评论的文本特性考虑进去,而且涉及的覆盖面广,因此也能提高电影评论情感分析的正确率。
5 小结
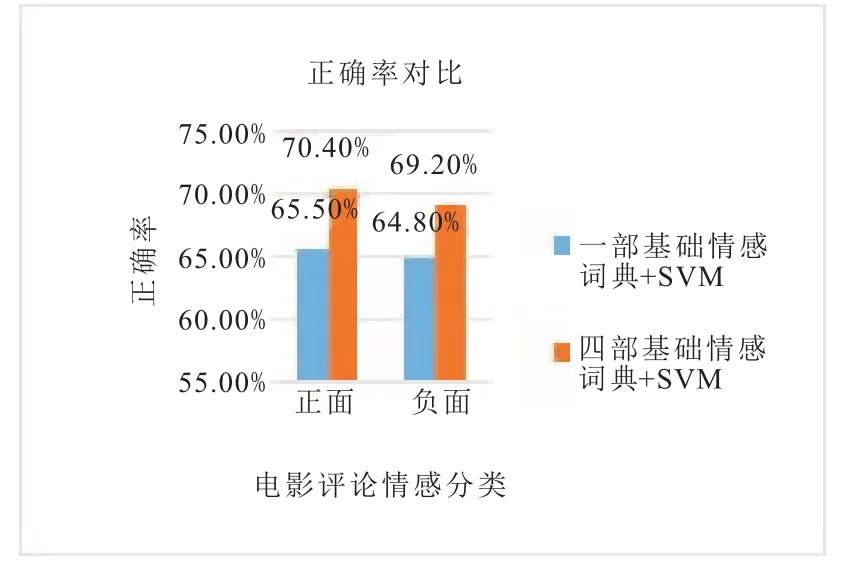
图2 《我不是药神》评论情感分类
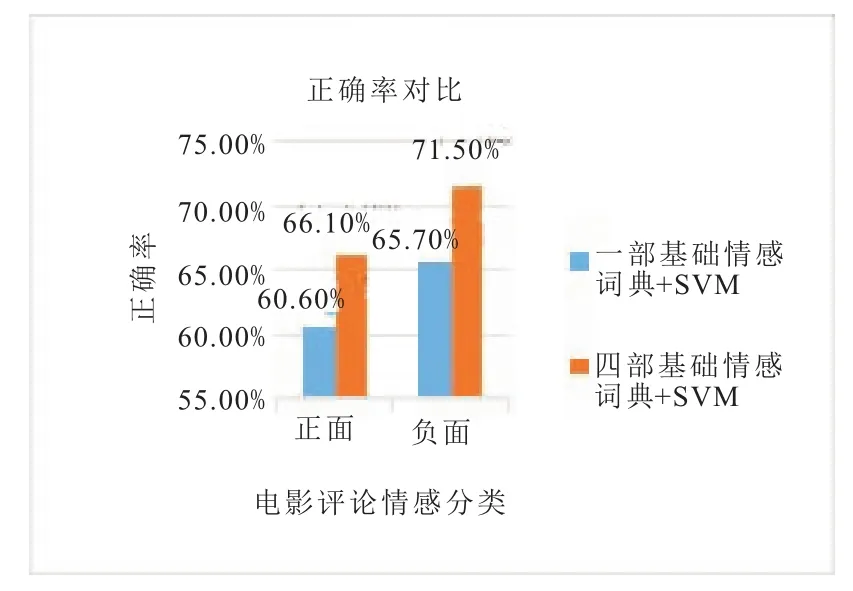
图3 《战狼2》评论情感分类
基于词典与SVM的方法能提高电影评论情感分析的正确率,能更好地应用于电影的喜好判断和推荐,对媒体平台进行电影推广具有指导作用。本文提出的基于四部情感词典的方法相比于基于基础情感词典的方法具有更好的情感分析效果,但仍有改进空间,比如将文本之间的语义规则考虑进去,涉及到句型规则分析和句间规则分析等等,同时还可以利用深度学习的方法进行情感分类,相信在未来,关于电影评论的情感分析研究会越来越精准。
猜你喜欢
阅读(快乐英语中年级)(2023年6期)2023-05-24 22:53:36
三门峡职业技术学院学报(2021年4期)2021-04-19 09:00:38
文苑(2019年24期)2020-01-06 12:06:50
时代英语·高一(2019年5期)2019-09-03 02:09:34
疯狂英语(双语世界)(2017年3期)2018-01-19 01:40:36
疯狂英语(双语世界)(2017年1期)2017-07-01 17:11:10
电测与仪表(2016年11期)2016-04-11 12:20:42
电源技术(2015年5期)2015-08-22 11:18:28
高中生学习·高三版(2014年3期)2014-04-29 06:09:37
当代修辞学(2013年4期)2013-01-23 06:43:10
