
基于iBAT和DTW算法的异常轨迹检测
2019-06-04 03:20逄焕利李红岩
长春工业大学学报 2019年2期
逄焕利, 李红岩
(长春工业大学 计算机科学与工程学院, 吉林 长春 130012)
0 引 言
近年来,随着GPS(Global Positioning System)技术在各类电子产品和移动终端上的广泛使用,生成大量轨迹数据,轨迹异常检测已成为时空轨迹模式挖掘的重要研究内容。 轨迹异常检测可以为不同的应用服务,例如城市的气象监测[1]、交通实时路况监控[2-3]和热点路径发现[4]等。轨迹频繁模式挖掘[5]和轨迹异常检测[6]是轨迹数据挖掘的主要研究内容。
目前,学者们对时空轨迹的异常检测做了大量研究,并提出了许多异常检测算法。文献[7]提出了经典的TRAOD算法,但是该算法计算效率不高、结果的准确性低;韩博洋等[8]提出了一种基于出租车GPS时空轨迹数据的异常轨迹检测算法,该算法将离线挖掘与在线实时检测相结合,其优点是具有实时性,可以快速反馈实时检测的结果,但是由于时间和空间两个维度的阈值设置比较困难,如果不能合理设置阈值,会在一定程度上影响到检测效果;唐梦萌等[9]提出的算法效率在一定程度上得到了提高,但算法并没有充分考虑轨迹的其他特征。因此,该算法不能提高异常轨迹检测效果。在分析了异常“少而不同”的特征后,文献[10-11]提出了一种基于隔离的异常轨迹(iBAT),与其他异常检测方法相比,该算法更接近于基于异常数据特征的异常检测初衷。但是该算法在用网格表示轨迹的过程中,由于相似的轨迹可以生成不同的网格序列,结果一些正常轨迹被检测为异常轨迹,不能达到期望的效果。
为了提高轨迹异常检测效果,文中设计了一种结合iBAT和DTW算法的异常轨迹检测算法。在使用iBAT发现异常的结果上加入相似轨迹度量的过程,应用相似性度量在出租车轨迹的异常检测上,实现了降低轨迹异常检测误报率的目的。
1 相关原理
1.1 轨迹与轨迹异常
轨迹是记录运动物体的历史位置信息的时空数据,令Tr表示二维空间中的运动物体的轨迹:
Tr={(x1,y1,t1),(x2,y2,t2),…,(xn,yn,tn),…}
式中:(xi,yi,ti)----移动对象在ti时刻的经纬度,即该对象的位置信息。
异常轨迹是不遵循预期规则模式的事件,即表现出不符合相似性标准的行为。
1.2 轨迹异常检测
1.2.1 时空轨迹相似性度量
轨迹异常检测的前提是定义轨迹相似性度量的标准,通常使用轨迹点或轨迹段之间的距离测量来描述轨迹之间的相似度。有几种典型的轨迹相似性度量,包括欧几里德距离、Hausdorff、DTW、LCSS等。
欧几里德距离是解决序列相似性问题的一种方法,但是,它不适用于长度不等或时间尺度不一致的轨迹数据,并且对噪声数据敏感;Hausdorff距离是两组点之间距离的度量(不匹配程度);DTW方法首先应用于语音识别领域,并应用于轨道距离的计算,解决了不同采样率和规模的问题;LCSS方法通常用于计算两个轨道之间的最长相似子轨道序列的长度,其表示轨道之间的相似度。尽管LCSS可以处理噪声轨迹数据,但是该方法不考虑轨道之间类似子序列之间的不同间隙的大小,降低了相似性测量的准确度。
1.2.2 轨迹异常检测方法的分类
到目前为止,学者们提出了许多检测轨迹异常的方法,大致可分为四类:基于分类的检测方法、基于历史相似性的检测方法、基于距离的检测方法和基于网格的检测方法。时空轨迹数据异常检测技术分类如图1所示。
图1 时空轨迹数据异常检测技术分类
基于分类的检测方法在给定一个训练数据集后,可以取得很好的检测效果,但是由于时空轨迹数据中的异常通常是未知的,所以很难找到一个完备的训练数据集,因此基于分类的异常检测方法并不适用于在线异常检测;基于历史相似性的检测方法通过大量历史轨迹数据构建模型,在交通异常检测中有着广泛的应用,但是增量更新会有较高的计算开销;基于距离的异常检测通常关注异常子轨迹、异常片段,所以忽略了轨迹的时空相似性;基于网格划分的异常检测通过城市路网划分成相等大小的网格单元,通过识别网格单元的单元序列进行异常检测,可分为基于似然比检验统计量的异常轨迹检测、基于隔离机制的异常轨迹检测、基于方向和密度的进化异常轨迹检测。
2 iBAT+DTW方法
文中提出的异常轨迹检测方法采用基于隔离机制(iBAT)的异常轨迹检测方法来检测轨迹异常。 在得到正常和异常轨迹之后,再结合动态时间规整方法进行轨迹相似性测量,进一步划分轨迹,从而达到降低异常检测误报率的目的。文中异常轨迹检测过程如图2所示。

图2 异常检测流程
步骤如下:
1)预处理轨迹并提取相同的起始轨迹;
2)使用iBAT算法进行异常检测(计算异常分数);
3)根据异常分值初步划分异常轨迹集合与正常轨迹集合;
4)计算DTW分值ScoreDTW,并使用DTW算法测量相似度;
5)若ScoreDTW>DTW阈值,则标记为异常轨迹,否则标记为正常轨迹。
iBAT算法描述如下:
输入:t-待检测轨迹;T-轨迹集合;m-二叉树的个数;ψ-二次采样样本大小。
输出:异常分值s(t,ψ)。
过程:
ni=0
for i=1 to m do
T'←随机从轨迹集合T中选取样本,样本大小为ψ
repeat
ni←ni+1
随机从轨迹t中选取一个网格p
T'←从样本T'中选取包含网格P的轨迹
until直到T'为空
end for
根据公式计算异常分值s(t,ψ)。
2.1 预处理
由于GPS装置收集的数据具有一些偏差数据,如数据异常、纬度和经度越界等,这些数据将影响轨迹异常检测结果的准确性。为了降低噪声数据对异常检测性能的影响,首先要对数据进行分析,删除无用属性,清洗噪声数据如空值或者无效地址和时间。预处理数据见表1。

表1 GPS轨迹数据表
2.2 异常检测
地图首先被划分为250 m×250 m的统一网格。 根据每个网格单元在网格中的位置分配给每个网格单元一个网格ID(Grid_ID)。 之后,每个滑行轨迹的坐标被映射到网格单元,并且网格ID用于表示轨迹的纬度和经度坐标。 将这个过程进行下去,每个轨迹的输出就是一组网格ID序列(Grid_Seq),完成用网格序列表示轨迹。 以两条轨迹Tra1和Tra2为例,过程如图3所示。
完成以上过程后,所有的轨迹都被表示成一组网格序列,将通过相同起-终点网格对的轨迹划分为一组,这样问题就被转化为寻找相同起-终点网格对中的异常轨迹。轨迹相同起-终点分类的过程如图4所示。
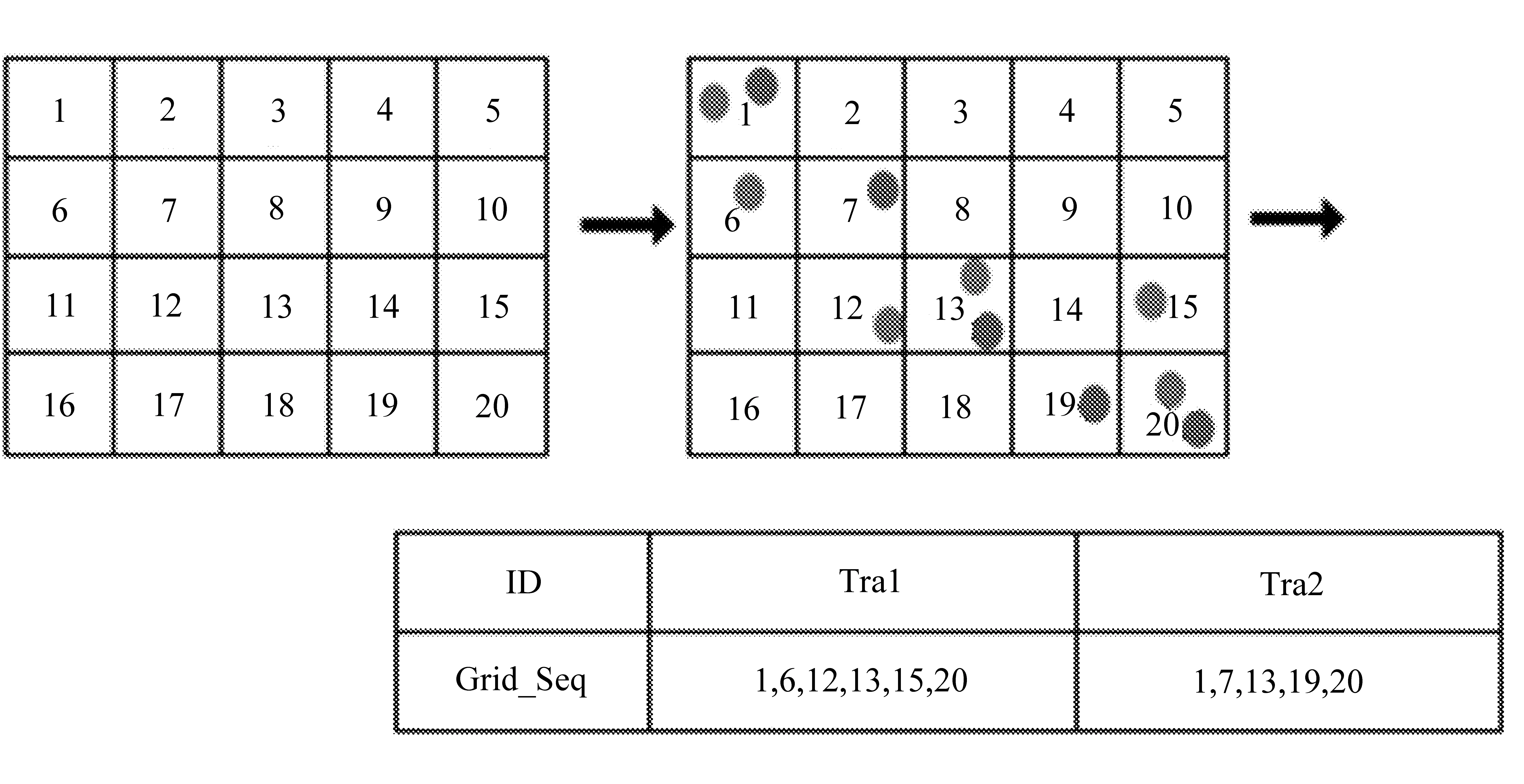
图3 网格序列表示轨迹过程
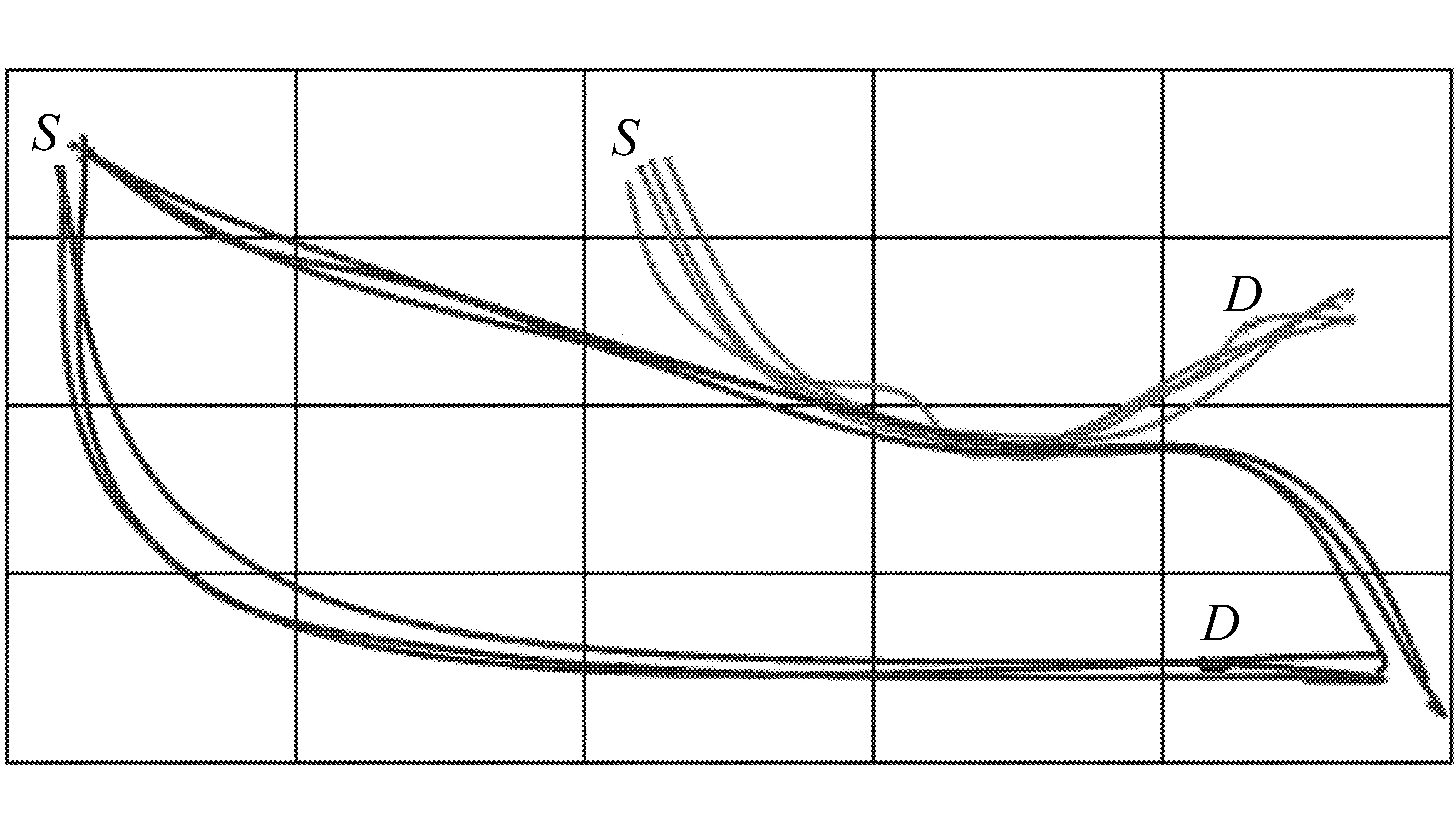
图4 轨迹相同起-终点分类过程
一个特定的网格代表一个特定的区域,在划分区域时,使用的网格大小为250 m×250 m。
iBAT异常检测的最后一步是计算异常分值,来决定轨迹是异常轨迹还是正常轨迹,公式如下:
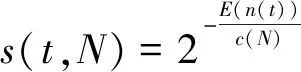
(1)
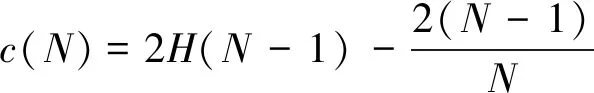
(2)
式中:t----要隔离的轨迹数据;
n(t)----隔离t用到的网格数;
E(n(t))----平均网格数,也表示数据t在N棵iTree的路径长度的均值;
s(t,N)----数据t在由N个样本的训练数据构成的iTree的异常指数,数据t最终的异常分值是综合了多棵iTree的结果;
c(N)----用N条数据构建的二叉树的平均路径长度,在这里主要用来做归一化。
其中,H(N-1)可用ln(N-1)+0.577 215 66估算,这里的常数是欧拉系数。
从异常分值的公式看,异常分值s(t,N)越接近于1,表明数据t越异常;异常分值s(t,N)越接近于0,表明数据t越正常;如果异常分值s(t,N)在0.5附近,表明数据t在多棵iTree中的平均路径长度接近整体的平均值。
2.3 相似性度量
在根据iBAT算法获得正常和异常轨迹之后,下一步是使用动态时间扭曲(DTW)算法测量所有轨迹的相似性。 正常轨迹被定义为轨迹-1,异常轨迹被定义为轨迹-2。相似性度量过程如图5所示。

图5 相似性度量过程
当前研究的输入数据是有经度坐标和纬度坐标的GPS数据,d为两点间距离:
(3)
同时使用的分值ScoreDTW是坐标之间的平均距离,即:
(4)
公式计算的结果是轨迹的相似度,分值越小,则轨迹越相似。公式中使用0.000 7阈值,在实验环节这个阈值会更精确。
3 仿真实验与分析
3.1 实验准备
文中所有算法均通过python编程实现,并结合MATLAB进行了实验数据的仿真测试。实验运行机器为i5-5300U,64位Windows7操作系统,2.4 GHz CPU,4.0 GB内存。
该实验使用Cabspotting项目提供的真实出租车GPS轨迹数据,其中包括2008年在美国旧金山收集的出租车轨迹。每条记录每隔1 min采集一次位置信息。为了验证算法的有效性,文中设计了五组异常检测实验。从数据集中选出5个相同起-终点的网格对作为实验数据集,人工标记出异常轨迹,实验数据集见表2。
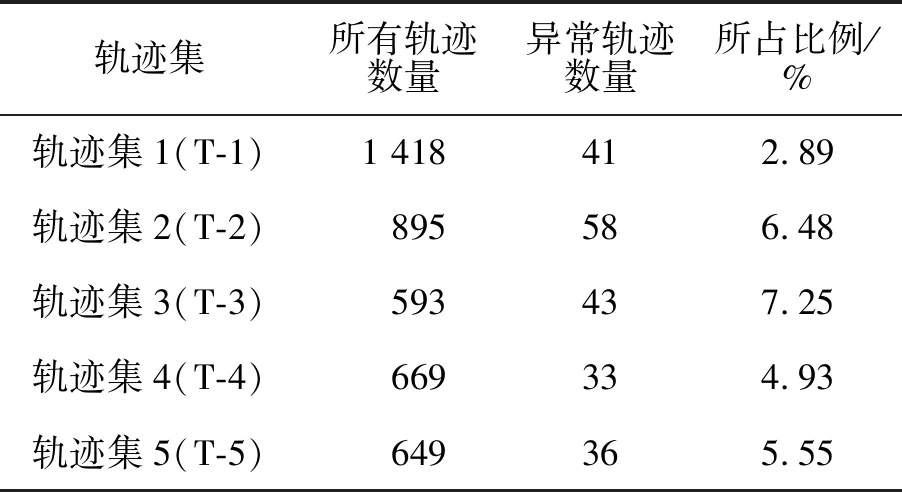
表2 实验数据集
3.2 网格单元大小实验
本实验环节是为了确定用以轨迹分类的网格单元的大小,实验用到的网格大小为100~500 m,网格单元大小实验如图6所示。

图6 网格单元大小实验
由图6可以看出,网格越宽,可以形成的簇越少,然而包含最少3个成员的簇的数量会增加,这是因为网格的大小会极大地影响被覆盖的轨迹数量,如果网格太大,那么大多轨迹会在一个簇中被包含,从而发现异常水平会越低。基于地理位置信息和实际路径信息,将所研究区域划分为100 m×200 m统一的网格,使用的网格大小为250 m×250 m。
3.3 iBAT变量实验
异常检测性能评价指标包括检测率(Detection Rate, DR)、误报率(False Alarm Rate, FAR)、ROC曲线、查准率等,文中选择前3个指标对算法进行评价。DR是异常轨迹被成功检测出来的比率,FAR是正常轨迹被检测为异常的比率,这是评价异常检测方法的两个重要指标。一个好的异常检测算法应该同时具备高检测率(DR)和低误报率(FAR),ROC曲线可以用来描述两者之间的均衡程度,在算法评估时,需要一个量化指标来衡量检测效果的好坏,可以用ROC曲线下的面积(Area Under Curve, AUC)来量化,通常,AUC越大,表示检测算法性能越好。
除了待检测轨迹t和轨迹集合T,影响iBAT算法效果和时间效率的主要参数有两个:二叉树个数m和二次采样样本大小ψ。通过实验对比不同取值的AUC值,分别如图7和图8所示。
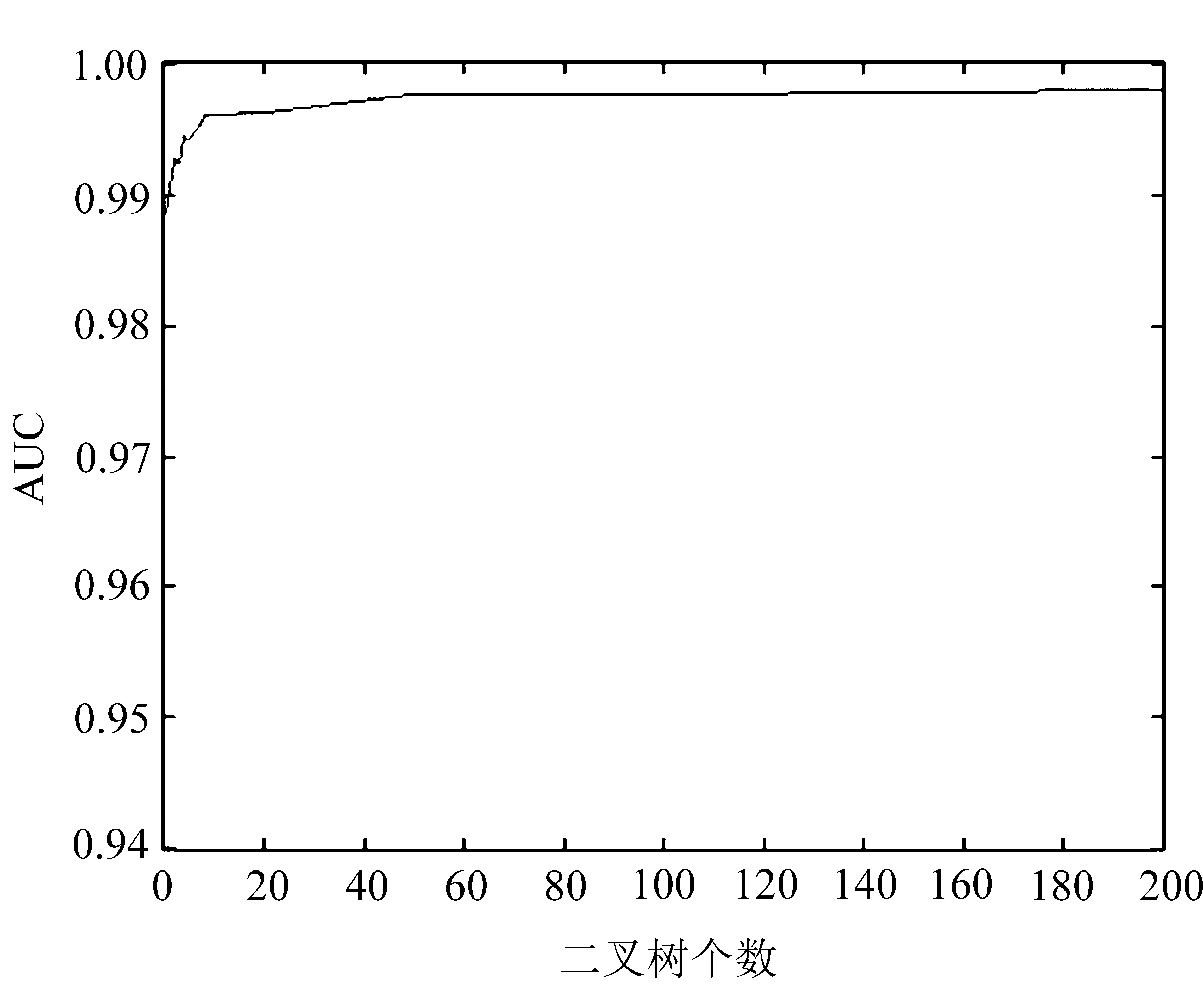
图7 iBAT参数m实验
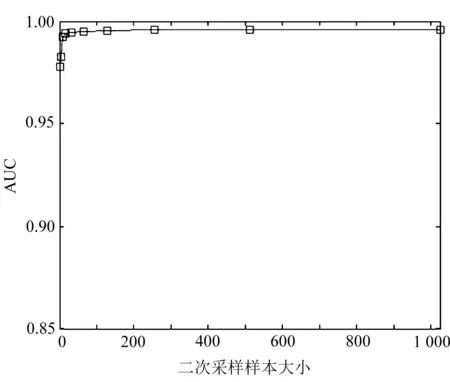
图8 iBAT参数ψ实验
图7是m取值[1,200]时AUC值的曲线,图8为ψ={2,4,8,16,32,…,1 024}时AUC值的曲线,由图中可以得出两个参数分别设置为m=100,ψ=256实验效果最好。
3.4 DTW阈值实验
本实验的目的是确定最优阈值作为判断轨迹正常还是异常的极限值。DTW阈值实验如图9所示。

图9 DTW阈值实验
阈值为0.000 7时,错误检测达到最低值。0.000 7的值有一个十进制单位,其中1个十进制等于111 319 m。这表明,在研究中,轨迹之间的平均公差大约是77.9 m。
3.5 实验结果
通过比较iBAT和iBAT+DTW的检测结果,将iBAT+DTW进行分析,结果表明,使用iBAT+DTW方法误报率为0.027,使用iBAT的误报率达到0.124,见表3。
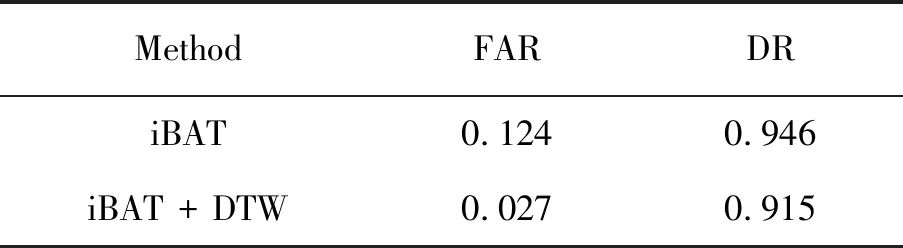
表3 异常检测结果
比较两种算法的AUC值,可以得出iBAT+DTW比iBAT检测精度更高的结论,如图10所示。
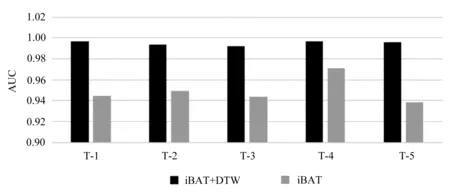
图10 实验对比图
由图中可见,iBAT+DTW是合适的度量相似性以及减少错误检测的轨迹异常检测方法。
4 结 语
从降低轨迹异常检测误报率的角度出发,提出了一种结合iBAT和DTW的轨迹异常检测算法,其在应用基于隔离机制的异常检测算法基础上加入相似性度量,并从网格单元大小、iBAT变量实验以及DTW阈值方面对算法进行了仿真分析,结果表明,相比iBAT算法,iBAT+DTW性能较优,能有效降低轨迹异常检测的误报率。
猜你喜欢
数学物理学报(2022年5期)2022-10-09
工会博览(2022年8期)2022-06-30
医学美学美容(2021年18期)2021-10-21
河北画报(2020年8期)2020-10-27
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
中国医疗保险(2018年3期)2018-07-14
现代装饰(2018年5期)2018-05-26
中国三峡(2017年2期)2017-06-09
浙江大学学报(工学版)(2016年2期)2016-06-05
