
面向文本结构的混合分层注意力网络的话题归类
2019-06-03 10:52:52杨小平梁天新韩镇远
中文信息学报 2019年5期
车 蕾,杨小平,王 良,梁天新,韩镇远
(1. 中国人民大学 信息学院,北京 100872; 2. 北京科技大学 信息管理学院,北京 100192)
0 引言
利用机器学习技术进行话题检测与跟踪并关注舆情安全是舆情监测的重要手段。话题检测与跟踪致力于从互联网上大量新闻报道中检测新话题并跟踪话题的发展,主要任务包括新闻报道切分、话题检测、话题跟踪、在线新事件检测和关联检测五项任务[1]。话题归类是话题跟踪中的重要研究点之一。话题归类是将最近采集到的新闻归类到与之相关的话题簇中。话题归类的核心问题是文本表示与分类模型。
文本结构包括逻辑结构和组织结构。文本的逻辑结构通常包括标题和正文等信息。标题属于短文本,正文属于长文本。标题虽然长度较短,但是具有提示和评价新闻核心内容的作用,在区分话题类别方面具有重要作用。目前,文献中缺乏充分利用文本逻辑结构特征开展话题归类的研究工作。文本的组织结构包括字—词语—句层次。为维持良好的上下文结构及完整的语法结构,文本通常包含许多与主题相关度较低的字、词语和句子。发现并过滤这些与主题相关性低的成分,可以加大对文本局部信息的注意力,在提高文本分类效率的同时改善分类效果。近年来,深度学习在自然语言处理领域取得了系统性的突破,但基于深度学习、挖掘文本组织结构特征来解决话题归类问题的研究还有待深入。
本文将充分利用文本逻辑结构特征与文本组织结构特征,基于深度学习算法和分层网络,引入注意力机制和多策略竞争机制,将重点放在关键字、关键词语和关键句子上,忽略其他无关内容,有效提取话题特征信息,从而提高话题归类的准确度,提升模型的泛化能力和健壮能力。为此,本文提出一个面向文本结构的混合分层注意力网络的话题归类模型(简称TSOHHAN),主要贡献如下:
(1) 更有效地利用了文本的逻辑结构。TSOHHAN模型同时考虑正文长文本和标题短文本对话题归类问题的贡献性。
(2) 更有效地利用了文本的组织结构。TSOHHAN模型针对中文文本,采用字词—句层次结构;针对英文文本,采用词语—句层次结构。为了有效地提取强相关信息,模型分别采用了字词混合级注意力机制、词语级注意力机制和句级注意力机制。
(3) 在标题分类的置信度选择上和文本分类的置信度选择上采用多策略竞争机制。一方面因“数”制宜,另一方面满足特征融合的需求。
(4) 开展CNN、TextCNN、Bi-GRU、Bi-LSTM、基于字—句层次的HAN、基于词语—句层次的HAN、基于字词—句层次的HAN和TSOHHAN等模型在话题归类方面的对比实验。实验结果表明,TSOHHAN话题归类模型优于其他模型。为了说明TSOHHAN模型的有效性和泛化性,实验选取了4个文本数据集,分别包括两个中文数据集和两个英文数据集。
本文接下来首先阐述相关研究工作,第2节深入探讨面向文本结构的混合分层注意力网络的话题归类模型,第3节阐述实验工作并分析实验结果,最后对全文进行总结并对该研究方向进行展望。
1 相关工作
话题归类属于文本分类问题。文本分类的主要任务是将给定的文本集合划分到已知的一个或者多个类别集合中。例如,新闻文本分类就是将新闻文本划分到其所属的话题中,如“国内”“国际”“体育”等。
传统文本分类基于机器学习方法,主要有朴素贝叶斯(Naive Bayes,NB)、K近邻(K-Nearest Neighbor,KNN)、支持向量机(Support Vector Machine,SVM)、决策树(Decision Tree)等[2]。其中SVM一直保持不错的效果。传统文本分类方法的性能取决于人工设计的特征[3]。再者,由于人为因素的干扰,人工分类很难有统一的标准,并且还需要一定的先验知识。当领域发生变化时,分类标准也需要重新设计。
为了避免过多的人工设计特征,研究者开始将深度学习方法运用到文本分类问题中。2006年Hinton 教授提出深度学习的概念[4],指出深度学习模型具有自动从大量无监督数据中学习出任务所需特征的优势,在自然语言处理(NLP)中表现出强大的实力。卷积神经网络(CNN)能够通过窗口滤波器从局部文本中提取深层特征[5]。Kim提出了TextCNN[5]模型,利用CNN来提取句子中类似N-Grams 的关键信息。尽管TextCNN在很多任务里面都有不错的表现,然而CNN的局限在于卷积尺寸是固定的,对变长句子处理不够理想。循环神经网络(RNN)通过使用带自反馈的神经元,能够处理任意长度的序列。长短时记忆网络(LSTM)是一种特殊的循环神经网络(RNN),能够根据全局上下文记忆或忽略特征[6]。GRU(gated recurrent unit)[7]是LSTM的一个变体,能够很好地处理远距离依赖。可见,深度学习模型在NLP领域已经获得了很好的表现,应用前景广阔。但是仍然存在有待深入研究的问题,如上述研究不能高质量地从众多信息中选择出对当前任务目标更关键的信息。
深度学习中的注意力机制具有选择特性,它可以降低数据维度,让任务处理系统更专注于找到输入数据中与当前输出显著相关的有用信息,从而提高输出的质量[8]。Yang等[9]提出了分层注意力网络,用层次结构反映文本结构,分别在单词和句子级别使用注意力机制,捕捉不同层次的重要信息,提升了文本分类的性能和准确度。Wang等[10]基于分层注意力网络研究视频的行为识别。Wang等[11]提出了实体增强层次注意力神经网络,从生物医学文本中挖掘蛋白质的相互作用。Gao等[12]基于分层注意力网络,改善了非结构化癌症病理报告中的多信息提取任务的效果。Yan等[13]提出分层多尺度注意力网络解决计算机视觉领域的动作识别问题。Zhou等[14]提出混合注意力网络以解决短文本分类问题。Pappas等[15]基于多语言层次注意力网络研究文本的分类问题。Tarnpradab S等[16]基于层次注意力网络研究在线论坛的摘要提交问题。Yang等[9]提出的分层次注意力网络是在英文数据集上开展的实验,英文文本组成的最小粒度是词语级。而中文数据集中文本组成的最小粒度是字级,与英文数据集的粒度有所不同,目前针对中文数据集的分层次注意力网络的研究还很少。
上述研究仅针对长文本或短文本中的一种,而新闻的标题和正文对话题类别的区分都起到一定作用,目前还没有同时基于长、短文本的话题归类研究。总之,目前话题归类模型的研究工作还没有充分利用文本逻辑结构特征和文本组织结构特征。
2 模型
从词汇形态学来看,词语内部的深层结构为更深层次地处理和更好地理解整个句子提供了额外的信息[17]。以字作为最小语言模型的单元,可以解决生僻词和网络新词不能被识别的问题[18]。针对中文文本的最细粒度的组成单元是字这一特点,本文在网络结构设计上既蕴含了形态学上汉字的原始含义,又蕴含了中文词语的语义信息,提出字词—句的层次结构。从文本的逻辑结构来看,新闻标题属于短文本,本文基于几种短文本分类性能较优的深度学习算法,遵循竞争机制,构建多策略标题分类层。新闻正文属于长文本,采用分层注意力网络构建话题归类模型。TSOHHAN模型如图1所示,包括: 文本表示层、多策略竞争标题分类层、字词级/词级/句级Bi-GRU层、字词级/词级/句级注意力层和话题归类层。
一篇文章的表示应该首先建立字级向量、词语级向量、句子级向量,然后再将句子级向量聚集在一起形成一个文章的向量表示。另外文献[9]提出不同的词和句子对于一篇文章所能表达的信息量是不一样的。所以网络结构设计上包含两个级别的注意力机制,即词语级别和句子级别。图1的模型利用各个层级的上下文向量产生注意力层,求出每个字、每个词语和每个句子的任务相关程度。实验表明,与字—句和词—句相比,中文文本采用字词—句的层次网络,效果较优。最后,遵循竞争机制,产生标题和正文分类结果的综合置信度,得到话题归类的最终结果。
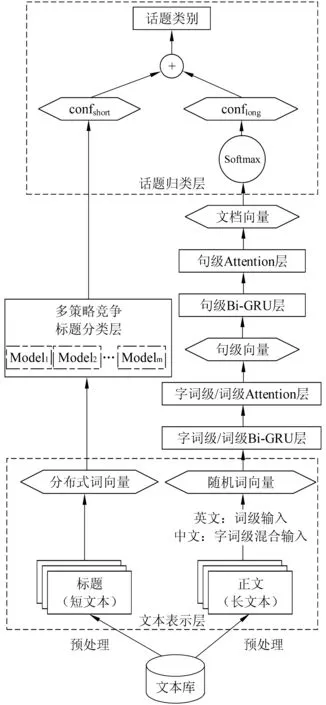
图1 TSOHHAN话题归类模型
2.1 文本表示层
文本表示层的任务是将待分类文本转换成计算机可以识别的向量表示。预处理之后得到的文本数据集表示如式(1)所示。
Doc=(Class,Title,Con)
(1)
其中,Class是类型,Title是标题短文本,Con是正文长文本。在TSOHHAN模型中,标题短文本采用的是分布式词向量表示,正文长文本采用的是随机词向量表示。
2.1.1 短文本向量表示
短文本采用分布式词向量表示。分布式表示有效地克服了传统文本表示中的词语原子性问题。分布式表示(Distributed Representation)最早是Hinton在1986年提出的[19],基本思想是将每个词表示成n维稠密、连续的实数向量。分布式表示最大的优点是具备非常强的特征表达能力。尽管Hinton在1986年就提出了词的分布式表示,Bengio在2003年便提出了NNLM(neural network language model)[20],词向量的大规模应用却是从2013年开始的。Mikolov在2013年发表了两篇关于Word2Vec的文章[21-22],更重要的是发布了简单好用的Word2Vec工具包。该工具包生成词向量的效果在语义维度上得到了很好的验证,极大推进了文本分析的进程。
本文的语料保存在文本文档中,首先提取训练集、验证集、测试集文档中的短文本集合Titles,构建词库Voc_Tit,并对词库中的词语进行词向量的映射,从而构建标题特征矩阵Mat_Tit。Titles和Voc_Tit的表示如式(2)和式(3)所示。

2.1.2 长文本向量表示
长文本采用随机词向量表示。随机词向量表示,即对所有词序进行编码,并将词序映射为随机词向量,进而由词序构成句子向量[23]。本文的语料保存在文本文档中,首先提取训练集、验证集、测试集文档中的长文本集合Cons,然后读取Cons中的所有句子,构建词库Voc_Con,并对词库中的词语进行随机编序,针对词序进行词向量的映射,从而构建句子特征矩阵Mat_Con。Cons和Voc_Con的表示如式(4)和式(5)所示。
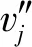
当用随机词向量表示字时,只要把词语替换成字即可。
本研究中,中文长文本的输入处理方式是词语和构成该词语的每个汉字混合输入。这种处理方式与Yang的方法[9]相比,不仅能解决生僻词和网络新词不能被识别的问题,而且能挖掘汉字更深层次的语义,更好地提升文本分类效果。本文采用混合输入模式,与每种输入类型训练一个单独的文本分类模型并做线性插值的方式相比,混合输入在训练和评估方面比线性插值更高效[24]。
2.2 多策略竞争标题分类层
多策略竞争标题分类层采用“多策略竞争机制”进行标题文本分类。基于CNN、TextCNN、Bi-LSTM和Bi-GRU的分类模型具有相同的输入层和输出层结构,但是隐藏层有所区别。CNN和Text-CNN的隐藏层增设了卷积层和最大池化层,侧重于挖掘文本的构成特征。Bi-LSTM和Bi-GRU的隐藏层嵌入了循环神经网络和门控机制,侧重于挖掘序列化的语义特征。要获得好的多策略集成,每个分类学习器应“好而不同”,即个体学习器要有一定的“准确性”,即学习器不能太差,并且要有“多样性”,即学习器间具有差异。Krogh和Vedelsby提出的“误差—分歧分解”明确指出: 个体学习器准确性越高、多样性越大,则集成越好[25]。
本文分别采用CNN、TextCNN、Bi-LSTM和Bi-GRU对4组实验数据的标题数据进行短文本分类实验。本文实验显示,Bi-GRU处理Data1和Data2的准确率比较高,TextCNN处理Data3和Data4的准确率比较高。因此,为保证集成效果,本文采用“多策略竞争机制”进行短文本分类,即同时采用多种分类模型进行类别预测,置信度高的胜出。基于多策略竞争的标题分类方法在本文简写为MTC。每种模型预测的置信度向量confModeli如式(6)所示,confi,j表示第i个模型第j个类别的置信度值。如式(7)所示,confMaxModeli表示第i个模型预测的置信度向量中的置信度最大值,即预测的类别对应的置信度。标题文本的置信度向量confshort如式(8)所示。式(6)和式(7)中,j的值域为[1,…,n],n为类别数目。式(6)~式(8)中,i的值域为[1,…,m],m表示分类模型的数目,本实验中m取4。
2.3 基于字词级的Bi-GRU层


(11)
候选隐含状态使用了重置门来控制包含过去时刻信息的上一个隐含状态的流入。重置门提供了丢弃与未来无关的过去隐含状态的机制,也就是说,重置门决定了过去有多少信息被遗忘。*表示矩阵元素相乘。
(12)

本模型的隐含状态hit为正向隐含状态和反向隐含状态的连接,如式(17)所示。
(17)
注: [ ]表示两个向量相连接。
2.4 基于字词级的注意力层
基于字词级的注意力层的任务是使用注意力机制得到每个字词与任务的相关程度,以得到相应的句子表示。首先,通过单层神经网络训练出对应hit的隐含状态μit,tanh函数的作用是将值域压入[-1,1]中,如式(18)所示。接着,如式(19)所示获得hit的任务权重αit。最后,引入类似Softmax的计算方式对μit进行数值转换,通过归一化,将原始计算数值整理成所有元素权重之和为1的概率分布,同时也通过Softmax的内在机制更加突出重要元素的权重。μwc是一个随机初始化的上下文向量,模型利用它计算出对应hit的任务权重αit,以体现hit与任务的相关程度。最后,通过加权求和得到基于注意力机制的句子向量si,如式(20)所示。
针对英文文本,直接采用词级处理。基于词级的Bi-GRU层与注意力层的对应公式同Yang的论文[9]。
2.5 基于句子级的Bi-GRU层与注意力层

(21)
基于句子的注意力层的任务是使用注意力机制得到每个句子与任务的相关程度,进而以对应的文档表示,即文档向量。式(22)中的μi是通过单层神经网络训练出来的对应hi的隐含状态。式(23)引入类似Softmax的计算方式对μi进行数值转换,计算出来的αi就是对应hi的任务权重。如式(24)所示,vlong就是通过加权求和得到基于注意力机制的文档向量,作为话题归类层的输入。
2.6 话题归类层
在TSOHHAN模型的话题归类层,将基于句子注意力层的输出vlong输入到Softmax层以获取类别置信度向量conflong[式(25)]。合并短文本的类别置信度向量[式(6)]和长文本的类别置信度向量[式(25)],得到最终的全局类别置信度向量conf,如式(26)所示。基于多策略竞争机制,最终话题类别为全局类别置信度向量中最大的置信度值对应的类别Text_cat,如式(27)所示。其中,cat[]是话题类别集合。
3 实验及结果分析
3.1 实验环境及数据
实验是在GPU为NVIDA GeForce GTX 1060 3 GB、CPU为Intel(R) Core(TM) i5-3470 CPU @3.20 GHz、内存为14 GB、操作系统为64位Windows 10的计算机上运行的。开发环境为: Python 3.6,TensorFlow 1.3。
为了验证模型的有效性,本文采用如下4种标准数据集进行实验,语料库均可以通过开源网站获得。
(1) 复旦数据(中文)[24](简称Data1): 即复旦大学文本分类数据,此数据集由复旦大学计算机信息与技术系国际数据库中心自然语言处理小组提供。实验从中选取了8个数据量超过1 200的主题。实验数据集的分布情况如图2所示。
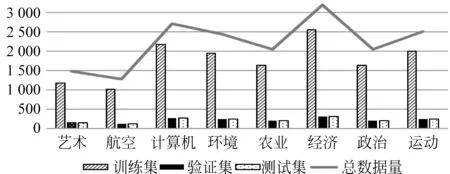
图2 复旦大学数据集(Data1)数据分布情况
(2) HUCNews(中文)[27](简称Data2): 是由清华大学自然语言处理实验室推出的中文新闻文本分类工具包,能够自动高效地实现用户自定义的文本分类语料的训练、评测、分类功能。实验从中选取了10个主题。实验数据集的分布情况如图3所示。

图3 HUCnews数据集(Data2)数据分布情况
(3) 20 news(英文)[28](简称Data3): 此新闻数据集由Ken Lang收集,包括20 017个文本,20个类别。实验数据集的分布情况如图4所示。
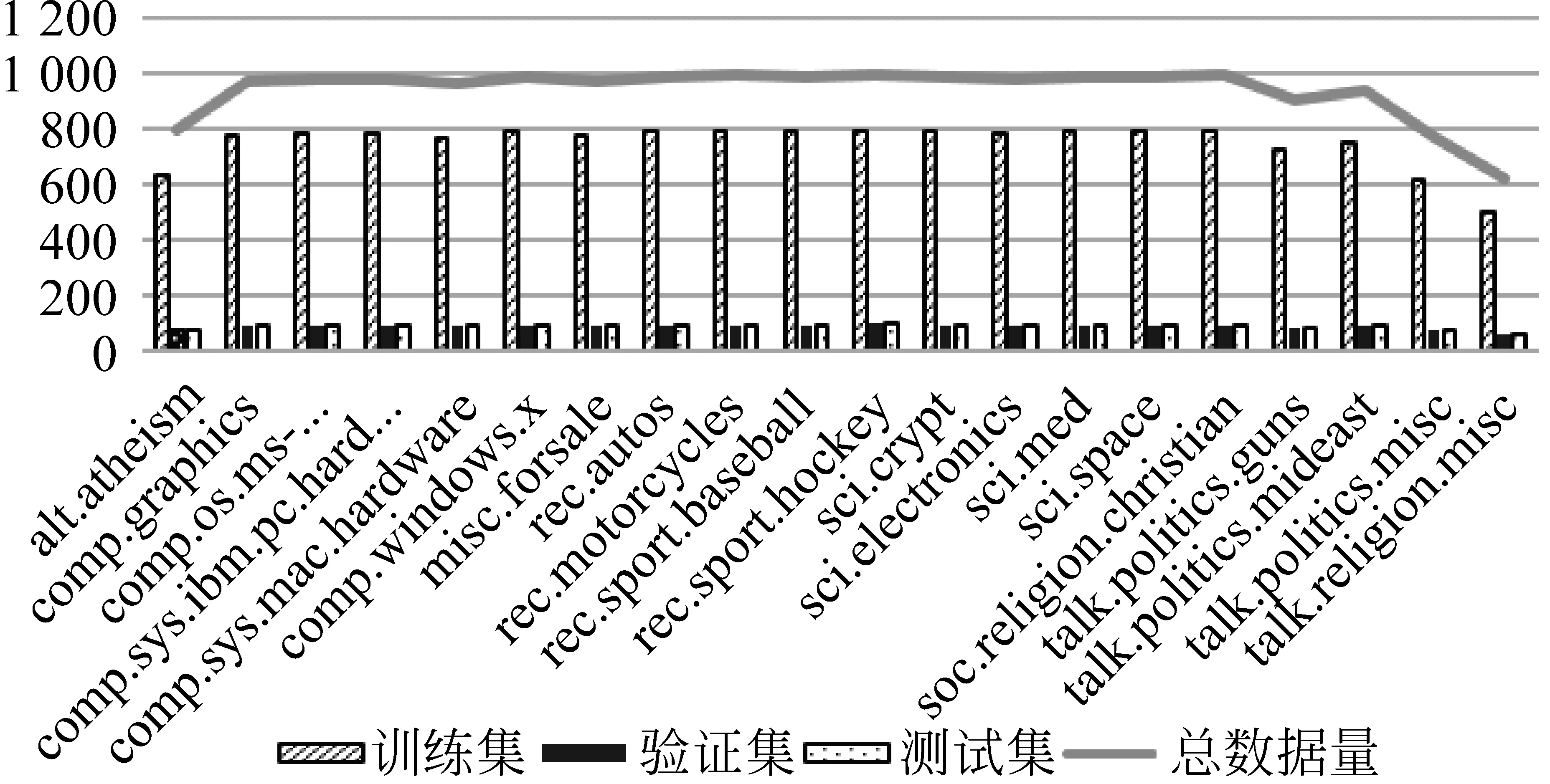
图4 20 news数据集(Data3)数据分布情况
(4) 路透社(英文)[29](简称Data4): 此新闻数据集是由路透公司采集的1987年的新闻稿组成的Reutrs-21578文集作为实验数据集。实验从中选取了10个主题。实验数据集的分布情况如图5所示。

图5 路透社数据集(Data4)数据分布情况
实验数据集的整体分布情况如表1所示。
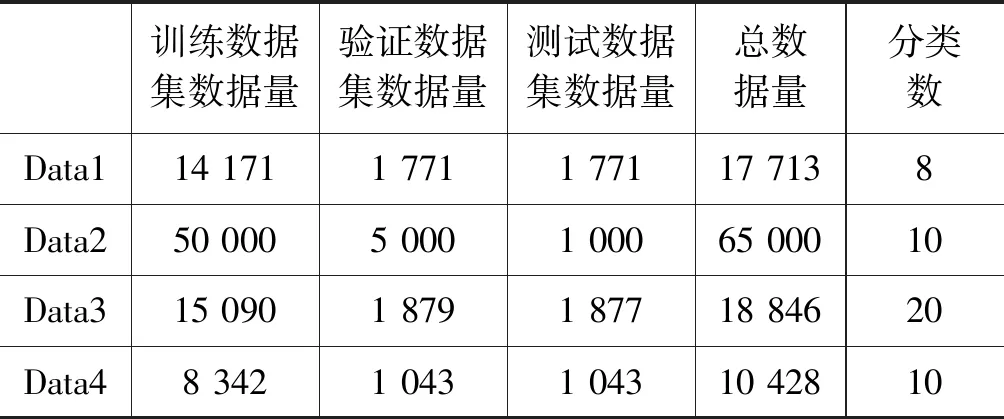
表1 实验数据集
3.2 文本预处理
对采集到的中文文本进行如下预处理: 首先采用结巴(jieba)分词工具对数据进行分词,并去除中英文文本中的数字;接着过滤掉叹词、副词等相关性较弱的词语和标点符号;最后去除停用词。
对采集到的英文文本进行如下预处理: 去除数字和停用词;字母全部转为小写;用Porter算法进行词干化处理,将英文中单复数、时态等变形词转换成原型。
所有字符编码采用无BOM的UTF-8格式。
实验中的短文本实验数据是从各数据集中提取的标题信息。标题提取过程中,针对某些标题缺失的情况进行标题补全。
3.3 对比实验及参数设置
目前,文本分类任务中使用的神经网络多为卷积神经网络或者循环神经网络。本文选取了9个模型进行对比实验,以便验证TSOHHAN话题归类模型的优秀性能。具体模型信息如下:
(1) CNN: 卷积神经网络。
(2) TextCNN: 面向文本分类的卷积神经网络。
(3) Bi-LSTM: 双向长短时记忆网络。
(4) Bi-GRU: 双向门控循环单元。
(5) HAN-W: 词级分层注意力网络。
(6) HAN-C: 字级分层注意力网络。
(7) HAN-WC: 字词混合级分层注意力网络。
(8) MTC: 基于多策略竞争的标题分类方法。
(9) TSOHHAN: 面向文本结构的混合分层注意力网络的话题归类模型。
通过模型(7)与模型(1)~(6)基于长文本的对比实验,验证HAN-WC对于中文文本集合的较好的话题归类效果。通过模型(1)~(4)和(8)基于短文本的对比实验,分析各模型对短文本话题归类效果。通过模型(9)与模型(5)~(7)的对比实验,验证本文提出的TSOHHAN话题归类模型具有较好的话题归类效果。
本实验的训练参数是通过多次实验获得的最优参数。其中,词向量的训练过程中,词向量维度取200,滑动窗口取10,算法选择为Skip-gram。在神经网络模型中,文本维度为200,卷积核数目为128,词汇表大小为8 000,隐含层层数为2,学习率为10-3。HAN相关模型中词单元数为200,句子单元数为100。
3.4 训练及优化策略
为了防止过拟合,TSOHHAN模型在Bi-GRU层采用Dropout机制进行正则化约束。Dropout最先由Hinton等人提出[30],通过随机丢弃——例如在前向传播的过程中,每个隐层单元有p的概率被丢弃——防止隐层单元的共适应问题。模型采用TensorFlow的自适应优化器,允许在每个步骤中为学习率计算不同的值,以使训练效果达到最优。
3.5 HAN模型归类性能与部分参数的关系
本节实验是基于HAN-C模型与Data1数据集。图6显示了HAN-C模型归类性能与epoch的关系。从图中可以看出,HAN-C模型收敛很慢,迭代次数epoch的值越大,准确率越高,在epoch为2 000时,准确率已经达到84.47%,高于算法(1)~(5)。综合考虑时间成本,HAN-W、HAN-C和HAN-WC模型中的epoch值都采用2 000。

图6 HAN-C模型归类性能与epoch的关系
图7显示了HAN-C模型归类性能与batch_size的关系。话题具有漂移特性,话题归类模型的训练与预测需要基于时间窗口迭代执行,所以训练时间太长也会影响归类模型的性能。从图7可以看出,当batch_size=32时,准确率与训练时间综合性能最好。当batch_size=16时,准确率比取32时提升了0.12%,但训练时间增加了31.04%。当batch_size=8时,准确率有所下降。当batch_size=4时,准确率比取32时提升了0.59%,但是训练时间增加了3倍多。当batch_size=2时,准确率比取32时提升了0.79%,但是训练时间增加了7倍多。综上所述,本实验batch_size值取32是最好的选择。
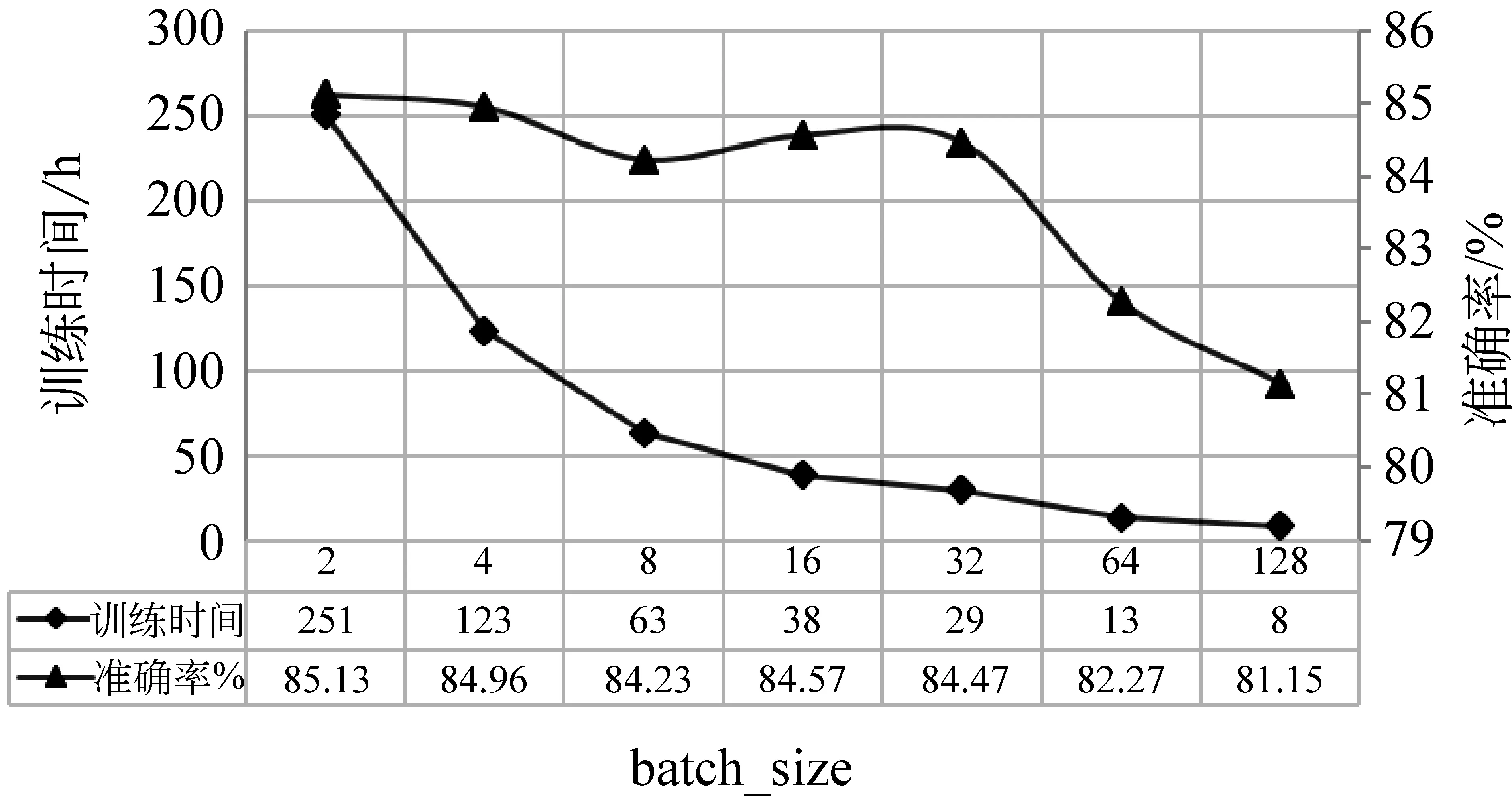
图7 HAN-C模型归类性能与batch_size的关系
3.6 实验结果与分析
3.6.1 各分类算法的实验结果对比分析
本文是对话题归类进行的多分类实验,在评价模型性能时使用宏平均准确度。表2是长文本部分的实验结果,分析此结果可知: 实验过程中为了提升文本分类效果,应保留文档的出处。无出处时Data1基于TextCNN测试的准确率是78.73%,有出处时准确率是80.91%。由Bi-LSTM和Bi-GRU的执行情况可以看出,Bi-GRU在长文本分类中效果优于CNN、TextCNN和Bi-LSTM。所以TSOHHAN模型中采用Bi-GRU进行字、词、句的序列编码。另外,各算法的准确率与数据集的分布情况和数据量也相关。Data2的数据分布比较均匀,而且数据量大,所以各算法对应的准确率都最高,HAN-WC的结果略低于Bi-GRU,差0.01%。中文数据Data1和Data2对应的HAN-WC都优于HAN-W和HAN-C,说明HAN-WC不仅挖掘了形态学上汉字的原始含义,还挖掘了中文词语的语义特征,这种字词向量混合表示方法对中文分类算法有一定的提升。同时也说明,对于中文文本来说,基于字词—句的层次注意力网络优于基于词语—句和字—句的层次注意力网络。从英文数据Data3和Data4的运行结果来看,基于注意力的分层网络优于其他深度学习算法。4个数据集的HAN模型的准确率比其他神经网络模型的最高准确率依次提升了5%、0%、2%、5%。综上所述,本研究中长文本分类算法采用HAN-WC是有效的,并具有一定的泛化能力。本研究中英文文本的最小粒度为单词,所以HAN-WC的结果取自HAN-W的结果。
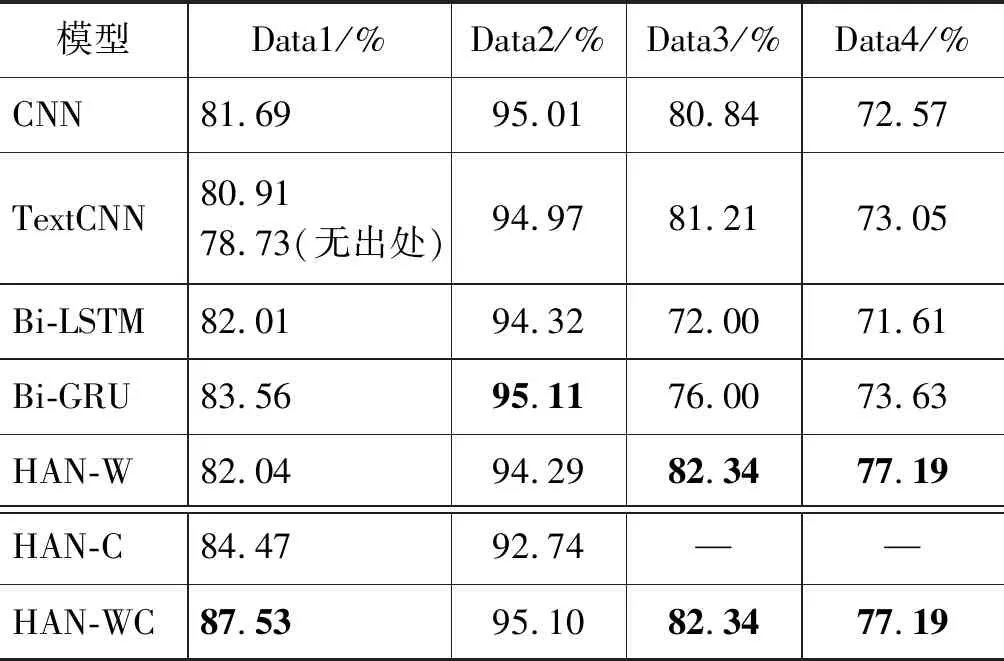
表2 长文本分类算法的实验结果(准确率)对比
由隐藏层特点决定,CNN/TextCNN更适合标题特征明显的数据,Bi-LSTM/ Bi-GRU更适合需要理解标题语义的数据。表3是短文本分类算法对比实验结果,通过该结果可以获知,不同短文本分类算法针对不同的数据,其准确率是不同的。本实验中,Bi-GRU和TextCNN的表现比较突出,在策略竞争机制中,起主导作用。4个基础模型的最高准确率比最低准确率分别提升了5%、12%、9%和9%。Data3原始数据的标题信息完整性相对较弱,所以对应的分类效果较差。从表3可以看出,Data1、Data2、Data3的MTC准确率微高于4个基础模型的最高准确率,Data4的MTC准确率接近于4个基础模型的最高准确率。这也体现了Bi-GRU在Data1和Data2短文本分类问题中的影响力,TextCNN在Data3和Data4短文本分类问题中的影响力。
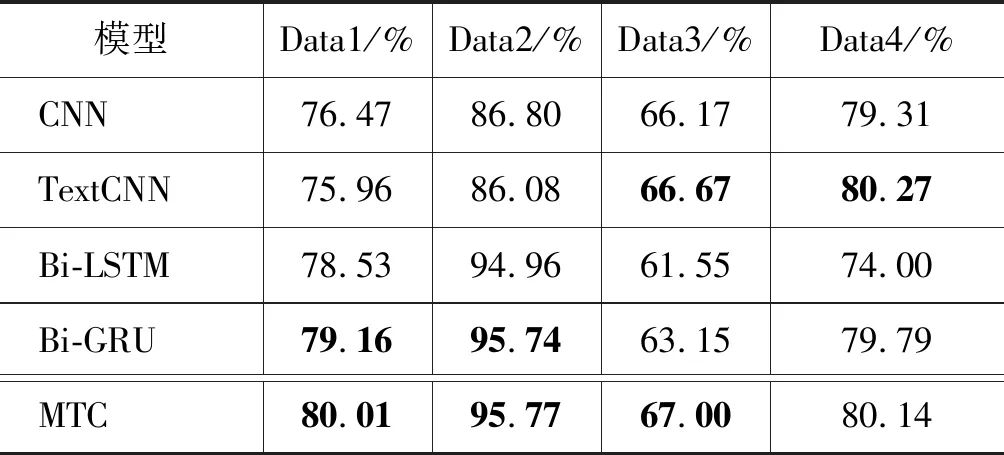
表3 短文本分类算法的实验结果(准确率)对比
表4是本文提出的TSOHHAN模型与HAN的实验结果对比。HAN-W、HAN-C和HAN-WC是不考虑标题信息的分类算法。从结果可以看出,增加标题信息的TSOHHAN模型的性能优于未增加标题信息的HAN。4个数据集的TSOHHAN模型的准确率比HAN-W分别提升了9%、2%、0.08%和8%。由表2和表4可知,4个数据集的TSOHHAN模型的准确率比其他神经网络模型(CNN、TextCNN、Bi-LSTM和Bi-GRU)的最高准确率分别提升了7%、1%、2%和13%。这也说明,深度挖掘文本逻辑结构特征和组织结构特征对话题归类问题的研究有积极的推进作用。另外,本实验也验证了TSOHHAN模型采用的多策略竞争机制的有效性。单个学习模型存在一定局限性,因为某些学习任务的真实假设可能不在其所考虑的假设空间中。如果结合多个学习模型,其相应的假设空间有所扩大,有可能学到更好的近似。另外,多个学习模型的集成可降低陷入糟糕局部极小点的风险。
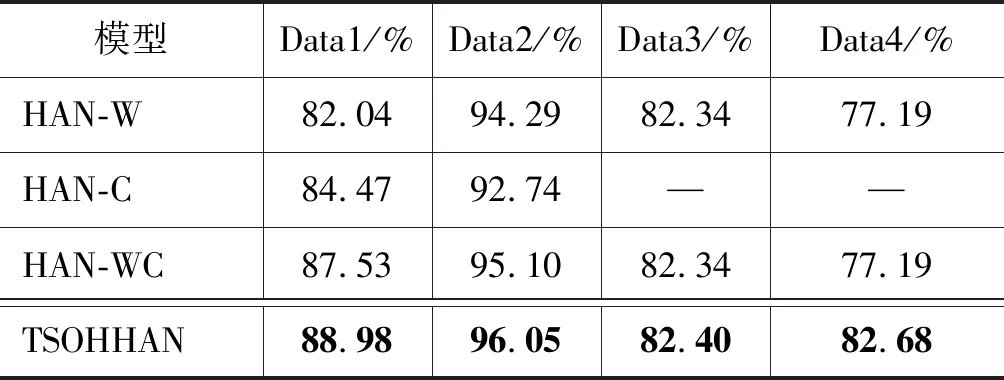
表4 TSOHHAN与HAN算法的实验结果(准确率)对比
3.6.2 收敛性能分析
为了说明模型的收敛性能,本文基于Data1数据开展了收敛性能的对比实验。图8依次显示了训练过程中CNN、TextCNN、Bi-GRU、Bi-LSTM、HAN各个模型的收敛情况。CNN迭代10次就收敛,TextCNN、Bi-GRU和Bi-LSTM迭代26次就收敛,HAN需要迭代2 000次才能达到优秀的分类效果,可见多层次模型不容易收敛,但是分类效果有所提升。

图8 收敛性能比对分析图
4 结论
本文针对话题追踪中的话题归类问题,提出了面向文本结构的混合分层注意力网络的话题归类模型,更充分利用了文本逻辑结构特征和文本组织结构特征,增强了文档特征数据的可区分性。针对中文文本,本文提出基于字词级混合输入,既挖掘了词语的语义特征,又挖掘了汉字的原始含义。在标题处理上,采用多策略竞争机制,扬长避短,因“数”制宜,确定标题的最优预测类别。本文提出的模型对话题归类问题的研究有推动作用。
TSOHHAN模型性能有待继续提升,后续的研究工作将进一步研究除标题之外的其他文本逻辑结构、重要特征与话题归类模型的相关性,添加额外信息,增加文档特征数据的可区分性,例如时序特征、关键命名实体、重要段落等信息。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
中学生数理化·中考版(2021年10期)2021-11-22 07:26:40
时代英语·高二(2018年7期)2018-12-03 09:23:06
疯狂英语·新读写(2018年2期)2018-11-29 17:59:24
时代英语·高二(2018年3期)2018-06-06 05:24:36
传媒评论(2017年3期)2017-06-13 09:18:10
中学生数理化·七年级数学人教版(2017年12期)2017-04-18 11:22:16
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
阅读与作文(英语高中版)(2013年12期)2013-12-11 08:20:08
阅读与作文(英语高中版)(2013年11期)2013-11-13 05:36:26
