
基于门控记忆网络的汉语篇章主次关系识别方法
2019-06-03 10:52:46王体爽李培峰朱巧明
中文信息学报 2019年5期
王体爽,李培峰,朱巧明
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)
0 引言
近年来,自然语言处理领域的研究逐步从浅层次的字、词、短语级别的语义分析延伸到了深层次篇章层级的语义理解。根据修辞结构理论(rhetorical structure theory,RST)[1],篇章通常由一系列具有语义联系的子句、句子或句群构成。RST分层级将相邻的篇章单元(discourse units,DUs)链接起来,构成了一个前后衔接、语义连贯的语言整体单位。篇章分析是自然语言处理的一个核心问题,可应用于自动文摘[2]、问答系统[3]、情感分析[4]、信息抽取[5]等领域。
篇章分析包含结构构建、主次识别、关系分类三个子任务。其中,篇章主次关系表示了篇章内部的主要和次要内容之间的关系。主要内容是指篇章中居于支配地位、起决定作用的部分,而次要内容是指篇章中居于辅助地位、不起决定作用的部分。RST中篇章主次关系分为单核关系和多核关系。其中,单核关系包括核心(nucleus)和卫星(statellite),核心表达主要内容,卫星表达次要内容。多核关系包括两个或两个以上核心。所以,在篇章主次关系中有以下三种类型:核心—卫星(NS)表示左子树为主要部分、卫星—核心(SN)表示右子树为主要部分、核心—核心(NN)表示左、右子树都为主要部分。其中NS、SN属于单核关系,NN属于多核关系。
下面以汉语篇章树库(Chinese Discourse Treebank,CDTB)[6]中的一个具体例子来说明篇章主次关系的含义。
例1随着从今年四月开始中国对保税区外有关特殊政策的调整,保税区免证、免税a,保税政策的稳定性优势显得更为明显b,国内外一大批实业加工项目相继在区内落户c。到去年十二月底,区内已累计设立企业一千六百一十四家d,总投资达十二亿美元e,其中外商投资企业二百六十家f,实际利用外资一点一三亿美元g。另外,众多国内企业也通过保税区与国际市场接轨h。
例1段落包含8个(a~h)基本篇章单元,篇章结构树如图1所示。其中,叶子节点(a~h)是基本篇章单元,而非叶子节点是关系节点,表示该节点连接的两个孩子之间的关系类型。叶子节点和关系节点统称为篇章单元(discourse unit,DU)。箭头指向篇章主次关系中的较为重要部分的核心单元,如例1中的因果关系节点左孩子a-b是右孩子c的原因,在本例中认为结果更重要,因此箭头指向右孩子,即叶子节点c是核心,它们的关系是卫星—核心(SN)。例1中,从图1所示的根节点开始,每次选择核心单元直到叶子节点,可以得到(国内外一大批实业加工项目相继在区内落户c)这个篇章基本单元,可作为整个段落的摘要。
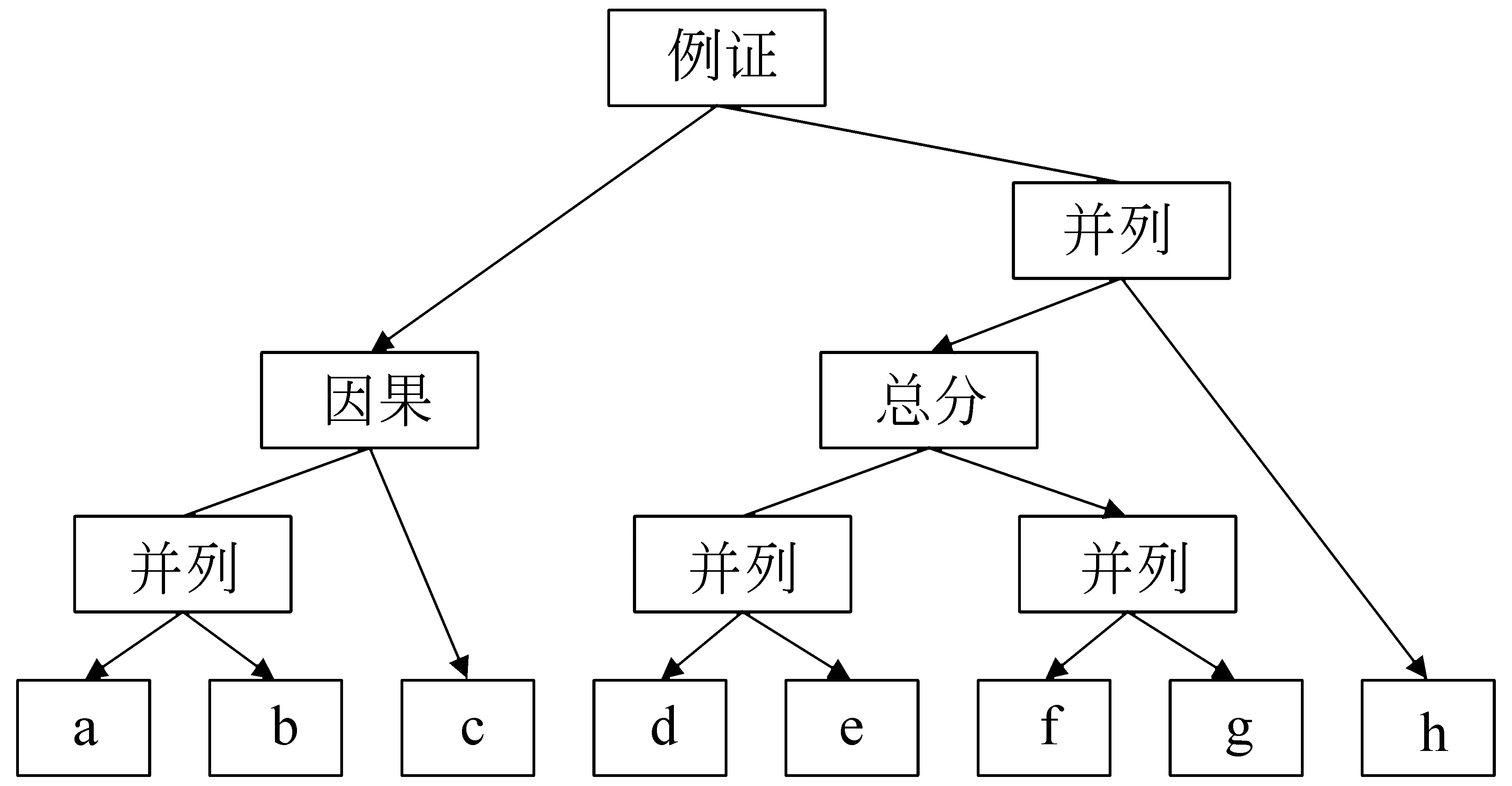
图1 例1的篇章结构树
目前,只有少数研究专注于篇章主次关系识别,面向汉语的篇章主次关系识别研究更少。大规模语料库的缺乏、汉语表达形式多样以及篇章构成复杂,都给汉语篇章主次关系识别造成了一定的困难。本文首次将门控记忆网络(gated memory networks,GMN)用于汉语篇章主次关系识别任务。首先,联合双向LSTM(Bi-LSTM)和CNN对DU进行编码以捕获全局信息和局部信息。然后,融合两个DU信息获得门控单元,用于控制两个DU的信息流动,从而获取相对于整体更重要的信息,而不是每一个篇章单元相对于自己的重要信息。最后,利用以上信息进行篇章主次关系识别。在CDTB语料库上的实验结果表明,本文的方法在宏平均F1值、微平均F1值以及各个主次关系类型上的F1值均有提升。
1 相关工作
目前,涉及篇章主次关系的语料库资源主要有英文修辞结构篇章树库(RST Discourse Treebank,RST-DT)[8]和汉语篇章树库CDTB[6]。徐凡等[7]对中英文篇章分析技术的研究现状进行了综述,介绍了中英文篇章分析技术在自然语言处理中的应用,并分别从篇章理论、篇章语料库及评测、篇章分析器的自动构建等方面详细阐述了中英文篇章分析技术。篇章主次关系识别研究大多数集中于英语语料库RST-DT上,这些研究一般将篇章主次关系识别看作篇章修辞结构分析中的一个辅助环节,忽略了其在篇章结构分析中的重要性。
在RST-DT树库上,大多数研究使用的方法是基于支持向量机(support vector machine,SVM)和条件随机场(conditional random fields,CRF)模型以及它们的变体等传统机器学习方法。Hernault等[9]使用两个SVM,实现了一个自底向上自动构建篇章树的框架。Joty等[10]等根据句内和句间的关系分布上的差异性,使用了两个动态条件随机场模型构建了句内和句间两个层级的篇章分析器,并使用动态规划算法对篇章树的构建进行优化。Feng等[11]使用两组线性条件随机场模型对篇章关系区域划分和篇章主次关系做出识别。Wang等[12]使用基于转移的方法将篇章树构建转化成shift-reduce序列,提出了先标注结构—主次,再进行标签标注的两步模型。Li等[13]提出使用依存结构来表示两个篇章单元之间的关系。
在RST-DT树库上,使用神经网络方法的相关研究较少。Li等[14]使用两层前馈神经网络来确定两个篇章单元之间的关系,并且使用递归神经网络通过计算篇章单元的子树来获取该篇章单元的表示。Li等[15]提出了一种基于Attention的分层Bi-LSTM网络以学习篇章单元的表示,并使用基于张量的变换函数来捕获篇章单元特征之间的相互关系。
相对于RST-DT,基于CDTB语料库的研究更少。李艳翠[16]借助上下文特征、词汇特征、依存树特征,采用最大熵模型进行主次关系识别。Kong等[17]使用语义相似度、上下文特征、采用最大熵模型,构建了一个端到端的篇章结构分析器。Xu等[18]提出了一个TMN(Text Matching Networks)模型,使用Bi-LSTM和CNN对两个篇章单元编码后通过三种匹配关系进行主次关系识别,他们的方法在CDTB语料库上的性能达到了69.0(微平均F1),明显优于传统的特征工程方法。
2 基于GMN的汉语主次关系识别模型(GMN-Nu)
在CDTB语料库上,Xu等[18]提出的TMN模型在主次关系识别任务上性能最好。TMN模型的主要思想有以下两点: ①认为语义相似度更大的两个篇章单元更有可能是多核关系。②认为在单核关系中和段落主题更接近的更有可能是核心。基于这两点思想,TMN模型引入了两个DU的语义相似度和每个DU与段落主题的相似度。
TMN模型容易将语义相似度较高的非多核关系错误识别为多核关系。如例2所示,例子中“农业”和“粮食”,“收成”和“产量”的相似度比较高,TMN模型误将例2识别为多核关系。
例2农业获得较好收成a,全年粮食总产量达七十六点六亿公斤b。(NS关系)
另外,当两个篇章单元序列长度不平衡时,TMN偏向于将更长的篇章单元识别为主要部分,而较短的篇章单元识别为次要部分。如例3所示,两个EDU的词序列长度非常不均衡,b包含了更多的信息,当经过匹配关系之后会得到b更加接近于段落主题的结论,而a和段落主题的关系相对于b要更疏远,TMN模型误将例3识别为卫星—核心(SN)关系。
例3经济效益可观a,上缴税费实现二百五十八亿元,实现利润一百亿元b。(NS关系)
为了解决以上问题,本文把门控记忆网络(GMN)应用于主次关系识别任务,实现了一个基于GMN的汉语主次关系识别模型(GMN-Nu)。其架构如图2所示,包含3个部分: ①输入和编码; ②多层结构的门控记忆网络; ③主次关系识别。
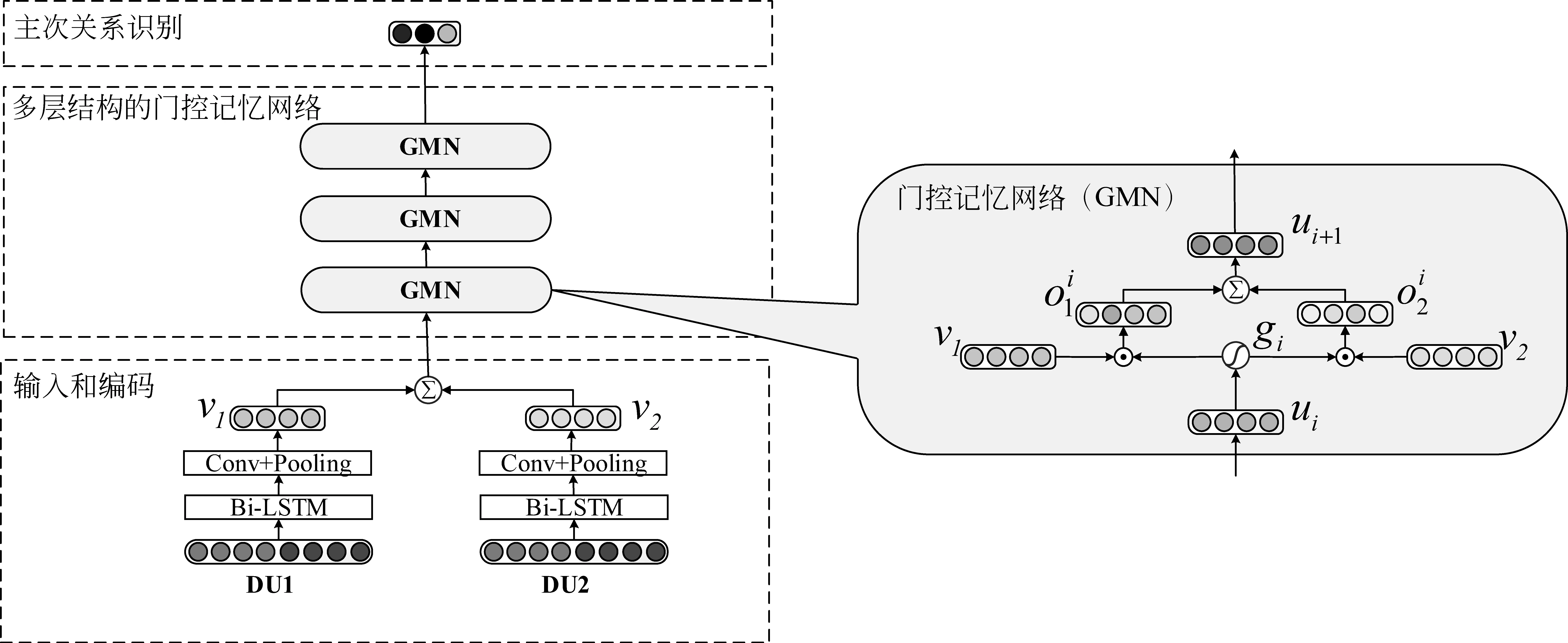
图2 GMN-Nu模型框架图
首先,在输入和编码层部分,模型以两个篇章单元DU1和DU2的词和词性为输入,同时,我们考虑使用字代替词来考察不同粒度输入对汉语篇章主次关系识别的影响。使用Bi-LSTM和CNN对两个篇章单元编码,以获取全局信息和局部信息。以例1为例,DU1/DU2可以是例1篇章结构树的任何一个关系节点的左、右孩子。其次,在多结构的门控记忆网络层部分,使用多层门控记忆网络从整体信息抽取每一个DU相对于整体来说更重要的语义信息表示。该方法融合DU1和DU2的信息以获得整体信息,通过sigmoid计算门控单元,作用于DU1和DU2以得到相对于整体的更重要的语义信息。最后,在主次关系识别层,使用softmax进行主次关系识别。
GMN-Nu模型的优点是: ①GMN-Nu模型是用整体信息来控制每个DU的信息流动。即使两个DU语义相似度高,经过GMN-Nu模型抽取出的仍然是每个DU相对于整体重要语义信息表示。这样就不会造成将语义相似度较高的非多核关系错误识别为多核关系。②在GMN-Nu模型中不使用段落主题,而是使用两个DU的整体信息,同时将每个DU置于同等重要地位。这就避免了将更长的DU识别为主要内容,对于长度不平衡的语料具有更好的识别能力。③GMN-Nu具有很好的可扩展性,可以很容易使用不同层次的门控记忆网络。
2.1 输入和编码层
首先结合Bi-LSTM和CNN对两个篇章单元DU1和DU2进行编码,输入是每一个篇章单元的词序列(t1,t2,…,tT),其中T是词序列长度。在词序列中拼接词向量ei和它的词性向量pi,当使用字作为输入时,将每个字所在词的词性作为每个字的词性,如式(1)所示。
Wi=[ei,pi]
(1)
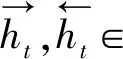
(2)
这样,每个输出不仅包含词本身的信息,还融合了上下文信息。此外,选取CNN来获取局部信息,等同于N-gram模型。它可以有效地捕获窗口内词汇的局部交互信息,这一点恰好可以弥补Bi-LSTM只能捕获全局信息的缺点。最后,应用全局最大池化来获取每一个卷积核得到的最有效的特征表示,从而得到每一个DU的信息表示vi∈c。
2.2 多层结构的门控记忆网络层
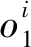
(7)
2.3 主次关系识别层
根据DU1和DU2获得了篇章单元的语义表示v1和v2。基于v1和v2,计算得到整体信息,最终获得每个DU的重要语义信息表示。把门控记忆网络最后一层的输出uj记作c。最后,使用一层前馈神经网络实现篇章主次关系识别,如式(8)所示,Wy∈c×3,by∈3是softmax层参数矩阵。
2016年1月,习近平总书记在重庆召开推动长江经济带发展座谈会,强调当前和今后相当长一个时期,要把修复长江生态环境摆在压倒性位置,共抓大保护,不搞大开发。
y=softmax(Wyc+by)
(8)
在模型训练过程中,通过最大化对数似然损失函数使用Adam优化器来优化网络模型中的训练参数。
3 实验
在这一部分,首先介绍实验所用到的语料库CDTB以及详细的实验设置,最后报告并分析实验结果。
3.1 CDTB语料库
针对汉语篇章结构的一般特点,结合RST-DT和Penn Discourse Treebank(PDTB)[19]的优点,并吸取了RST的树形结构和篇章单位主次思想,PDTB的连接词处理方法,参考汉语复句和句群理论等的研究成果,李艳翠[16]基于宾州大学汉语树库(Penn Chinese Treebank,CTB)[20]建立了汉语篇章树库(Chinese Discourse Treebank,CDTB)。在CDTB语料库中,每一个段落解析为一棵连接依存树,称之为篇章结构树。子句位于篇章结构树的叶子节点,连接词位于篇章结构树的中间节点,连接词本身既可以表示逻辑语义关系,其在篇章结构树中的层次又可以表示篇章结构。
和RST-DT类似,CDTB中的篇章主次关系也有三种类型: 核心—卫星(NS),卫星—核心(SN)以及核心—核心(NN)。与RST-DT不同的是,CDTB将两个DU主次关系类型标记在其父节点上,因此,具有N个DU的连接依存二叉树具有N-1个主次关系。
CDTB在主次关系上有3 555(48.6%)个单核关系,3 755(51.4%)个多核关系。其中单核关系包括2 110个NS以及1 445个SN主次关系。这是因为在CDTB语料库中并列类是篇章关系中最大的(56.8%)一类关系类型,这导致了多核关系占到了全部主次关系数量的一半以上。CDTB语料库包括500篇新闻文档,共2 342个段落,10 650个子句,每个子句平均汉字长度为22,每棵篇章结构树平均子句个数4.5。
3.2 实验设置
训练集、开发集和测试集的设置和Xu等[18]一样,表1展示了数据集的划分和主次关系统计。同样,采取和Xu等相同的评判标准,将非二叉树转换成左子树的形式,转化后在训练集、开发集和测试集上核心—核心(NN)主次关系类别数量分别为3 743,514和485。同时,报告每个篇章主次关系类别的查准率P、查全率R和F1值,以及宏平均F1值和微平均F1值。
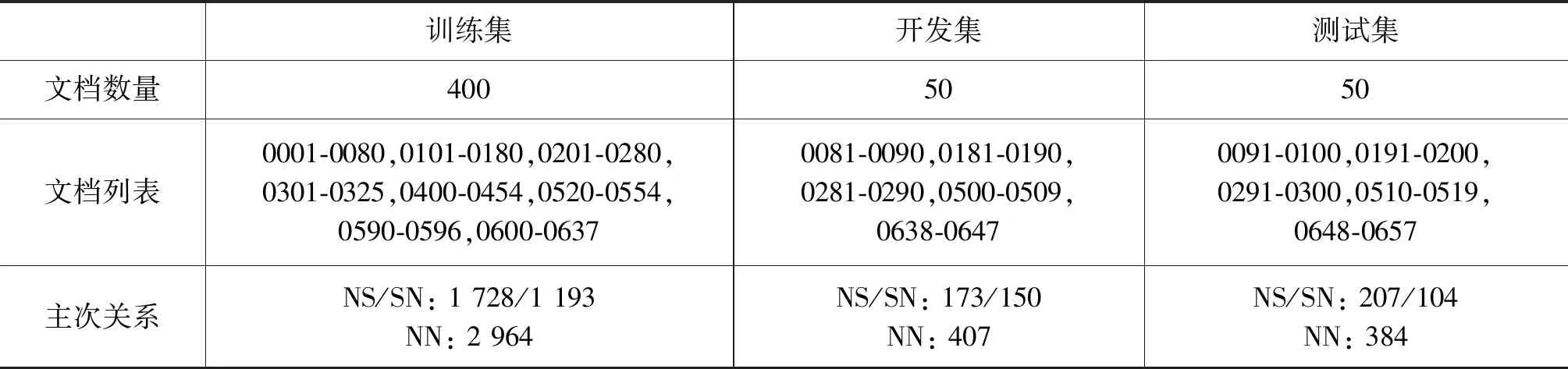
表1 数据集的划分及主次关系统计
参考Xu等[18]提出的TMN模型,将词向量维度设置为300,词性向量设置为50维。其中词向量使用在维基百科中文语料库上预训练好的词向量。除了词向量之外的参数都随机初始化。为了避免过拟合采用dropout策略,dropout设置为0.5。在开发集上通过网格化搜索来取得最佳的参数,之后合并训练集和开发集作为新的训练集对模型进行训练,并在测试集上评估模型。在编码层Bi-LSTM神经元设置为50维,根据表2得到的实验结果,把CNN卷积核数量设置为1 024,卷积核窗口大小为2。表3 是不同GMN层次的实验结果对比,实验结果表明使用3层GMN的模型整体效果更好。
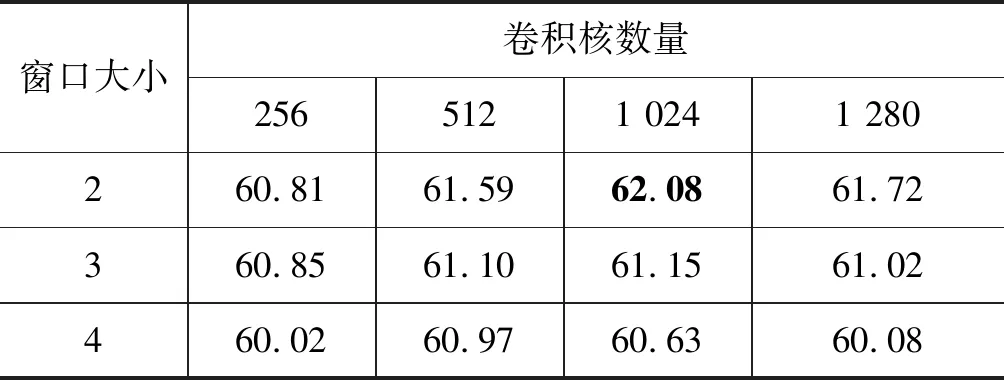
表2 在开发集上CNN不同参数获得的宏平均F1值
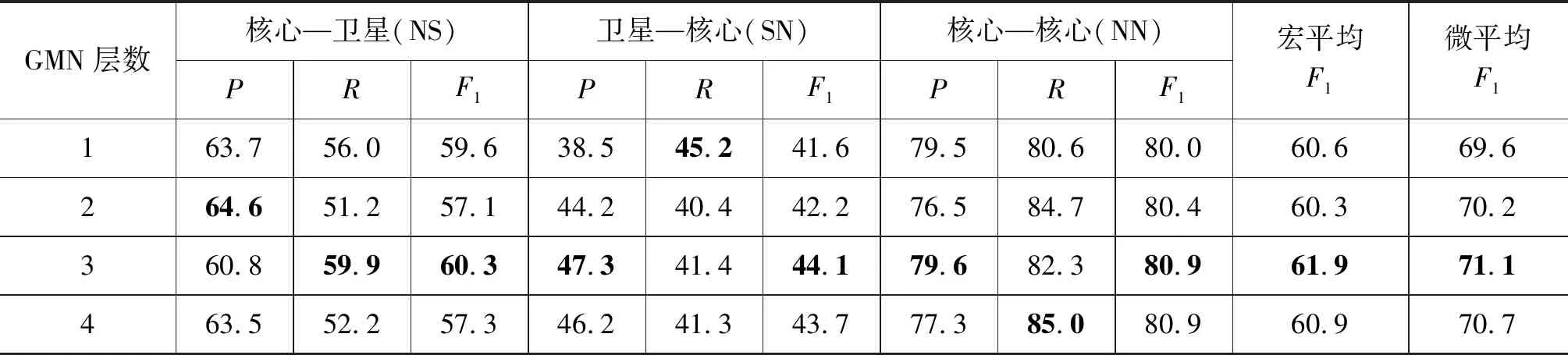
表3 不同层次GMN性能对比
3.3 实验结果
为了检验本文方法GMN-Nu的性能,设置了两个基准系统: ①最好的传统模型ME[17],该模型使用语义相似度、上下文特征,采用最大熵模型; ②最好的神经网络模型TMN[18],使用Bi-LSTM和CNN对两个篇章单元编码后使用三种匹配关系: Cosine、 Bilinear和Single Layer Network,分别用于计算语义相似度、线性关系和非线性关系,最后用于篇章主次关系识别。表4展示了使用词向量作为输入的GMN-Nu模型与ME和TMN性能比较。

表4 实验结果
表4显示GMN-Nu明显优于传统模型ME。对比TMN模型,GMN-Nu模型性能也有显著提升(显著性测试:p<0.001)。在各个篇章主次关系类别上的F1值以及宏平均F1值和微平均F1值均有提升。在核心—卫星(NS)主次关系上F1值提升了5.5%,在卫星—核心(SN)主次关系上F1值提升0.5%,在核心—核心(NN)主次关系上F1值提升1.3%。在宏平均F1值提升了1.5%,微平均F1值提升了2.1%。
从表4可看出,GMN-Nu在NS关系类型上的P值不如TMN,但在R值上较TMN模型提升14.5%。与此相反,在卫星—核心(SN)和核心—核心(NN)关系类型上的R值不如TMN,但在P值上较TMN模型均有提升。这是因为TMN模型偏向于将主次关系识别为核心—核心(NN)和卫星—核心(SN)关系,而GMN-Nu模型对于核心—卫星(NS)关系具有更好的识别效果。这正好验证了第2节的两点分析: ①TMN模型容易将语义相似度高的非多核关系错误地预测为多核关系; ②当EDU长度非常不均衡时,TMN模型更加偏向于将更长的那个EDU识别为主要内容。而GMN-Nu则能弥补以上的缺陷。
一般而言,一棵篇章结构树中越上层的关系节点,其左、右孩子的词序列长度越不平衡。在CDTB语料库中,关系节点的右孩子比左孩子词序列长50以上的语料中核心—卫星(NS)关系共有394(51.7%)个,卫星—核心(SN)关系有197(25.9%)个,核心-核心(NN)关系有171(22.4%)个。可以看出,当两个DU词序列长度不平衡时,较短的DU更有可能是主要内容。这是因为在CDTB语料库中的新闻语料的一个特点是大多采用总分结构,一般认为总结部分更有可能是主要内容,这也是为什么篇章主次关系识别研究有助于文本摘要任务。对于关系节点的右孩子比左孩子词序列长50以上的实例,TMN模型正确率为56.4%,GMN-Nu模型正确率为71.8%,性能得到明显提升(+15.4%)。可见,GMN-Nu模型对于词序列长度不平衡的实例具有更好的识别率。
对于主次关系识别任务,是要判断每一个DU相对于整体来说是否重要,即从整体来判断出主要内容和次要内容,而不是单独判断某一个DU是主要内容还是次要内容。基于这一特点,GMN-Nu模型整合了两个DU的信息,计算得到门控单元。然后使用门控单元和每个DU的特征表示计算得到每一层的记忆单元,最终获取到相对于整体来说每个DU的重要语义信息表示,而不是简单的捕获单个DU相对于自身重要的信息,这样可以从整体来考虑哪一个DU是主要内容,哪一个DU是次要内容。从表4也可以看出GMN-Nu模型在宏平均F1值、微平均F1以及三种关系类型的F1值均有提升。
在输入编码层,也考虑输入为每一个篇章单元的字序列,实验性能比本文采用的词系列差。其中,核心—卫星(NS)、卫星—核心(SN)和核心—核心(NN)的F1值为50.0%、40.2%和79.1%,较使用词向量作为输入性能均有所下降,特别是前两类。主要原因是在使用字向量作为输入时DU的序列长度会成倍增加。另外,本文将每个词的词性赋予该词的每个字,这会导致同一个字对应多个不同词性。
表5展示了GMN-Nu模型在篇章主次关系识别任务上错误识别的关系类型分布,可以看出有29.0%的NS关系和40.4%的SN关系被错误识别为核心-核心(NN)关系,这表明单核关系容易被错误识别为多核关系。主要有以下两点原因: ①在CDTB语料库中,NN关系类型在训练集上占到了一半以上的比例。②在测试集中有一些类似于例4的实例,这些实例的一个特征就是两个DU中都有大量的数字说明,而这样的实例大部分是单核关系,因为大都是一个DU是对另一个DU的补充说明。GMN-Nu模型从两个DU捕获的特征表示也会关注于这些数字说明,错误地将其识别为多核关系。
例4甘肃一九九七年全省国内生产总值达七百八十一点三亿元a,同比增长百分之八点三b。
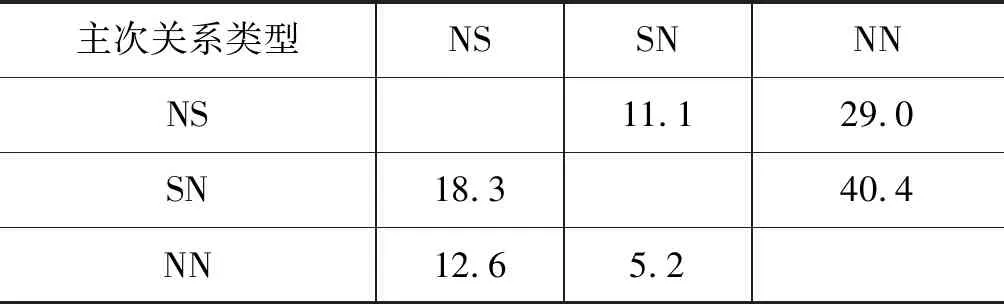
表5 识别错误的实例所占比例(%)
4 总结与展望
本文提出了在篇章主次关系识别任务上使用全局整体信息通过门控记忆单元来获取每一个DU相对于整体来说更加重要的特征表示。首先,使用Bi-LSTM和CNN对DU编码;然后,融合两个DU信息并计算得到门控单元,通过该门控单元计算每个DU的记忆单元;最终,捕获各个DU相对于整体来说重要的特征表示,从而识别出主要内容和次要内容。实验结果表明,GMN-Nu模型在宏平均F1值、微平均F1后以及三种关系类型的F1值均达到目前最好性能。在接下来的工作中,需要针对数据集的不平衡问题做出相应对策。
猜你喜欢
军民两用技术与产品(2021年10期)2021-11-25 14:17:57
开放教育研究(2020年2期)2020-03-31 01:54:14
天津外国语大学学报(2020年1期)2020-03-25 13:29:26
科学家(2019年3期)2019-08-18 09:47:43
作文评点报·低幼版(2017年13期)2017-04-18 18:15:11
科学与财富(2016年28期)2016-10-14 22:02:34
现代语文(2016年21期)2016-05-25 13:13:44
语言与翻译(2015年4期)2015-07-18 11:07:45
大连民族大学学报(2015年2期)2015-02-27 08:28:11
新东方英语(2014年1期)2014-01-07 19:56:11
