
一种改进的DNN瓶颈特征提取方法*
2019-05-31 03:19张玉来李良荣
通信技术 2019年3期
张玉来,李良荣
(贵州大学 大数据与信息工程学院,贵州 贵阳 550025)
0 引 言
语音识别技术已经被广泛应用到社会很多的领域中(智能查阅、自动控制、文化、教育等),但传统语音识别系统越来越难以满足对海量数据建模的需求,自然语音对话识别的泛化能力差等缺点逐渐暴露,因此重点研究大词汇量连续语音识别技术,进而提出更有效的语音识别方法,对推动人工智能语音产业的发展具有重要意义。
当前大词汇量连续语音识别系统主要由三部分组成:特征提取、声学模型建立、解码[1]。其中在特征提取部分,主要是从原始语音中提取出有利于分类识别的语音特征,并对这些特征降维和后续运算处理。而当前很多算法都可以应用在语音特征参数提取中,其中梅尔频率倒谱系数(MFCC)是应用最为广泛的一种特征提取方式。以MFCC为代表的语音特征一般被称为短时静态特征,MFCC特征语音时长较短,一般每帧语音信号大约20~30 ms,因此导致其易受到噪声干扰,而且特征之间相关性不高。另外一种特征提取方法——Mel标度滤波器组(Fbank)特征提取,与MFCC相比,Fbank不经过离散余弦变换的去相关操作,保留了更多的原始语音信息,特征之间相关性更高,并且减少了运算量。相关实验表明:Fbank特征更有利于深度学习神经网络(DNN)的训练,但是冗余信息较多,说话人特征信息表征能力还是不够强。
针对上述语音特征提取算法的不足,本文提出了使用L2,1范数惩罚函数和重叠组套索算法来改进深度神经网络的语音瓶颈特征提取方法[2-4],将其用于解决冗余信息过多、表征能力不足的问题,能够有效提高语音相关性信息的特征。
1 基于DNN的瓶颈声学特征提取
近年来,深度学习广泛应用语音识别,尤其是Grézl等提出了瓶颈深度置信网络(BN-DBN)并应用于连续语音识别中[5],取得了很好的效果。瓶颈特征中的“瓶颈”就是指多层感知器(MLP)中位于最中间层的神经元(即瓶颈层),其个数相对于其它层要少得多,整个神经网络酷似一个瓶颈[6]。瓶颈深度置信网络通过引入瓶颈层,减少了输出特征的维度、降低了后续的运算复杂度。
DNN模型有输入层、隐含层、输出层。同一层中节点间不能连接,相邻层间的节点则采用全连接的方式;隐含层权值要通过当前网络层以及前一层权值加权计算得到。
深度神经网络瓶颈特征模型(BN-DNN)是在DNN模型的基础上,在隐藏层之间引入瓶颈层来减少输出特征的维度[7]。其模型结构如图1所示。
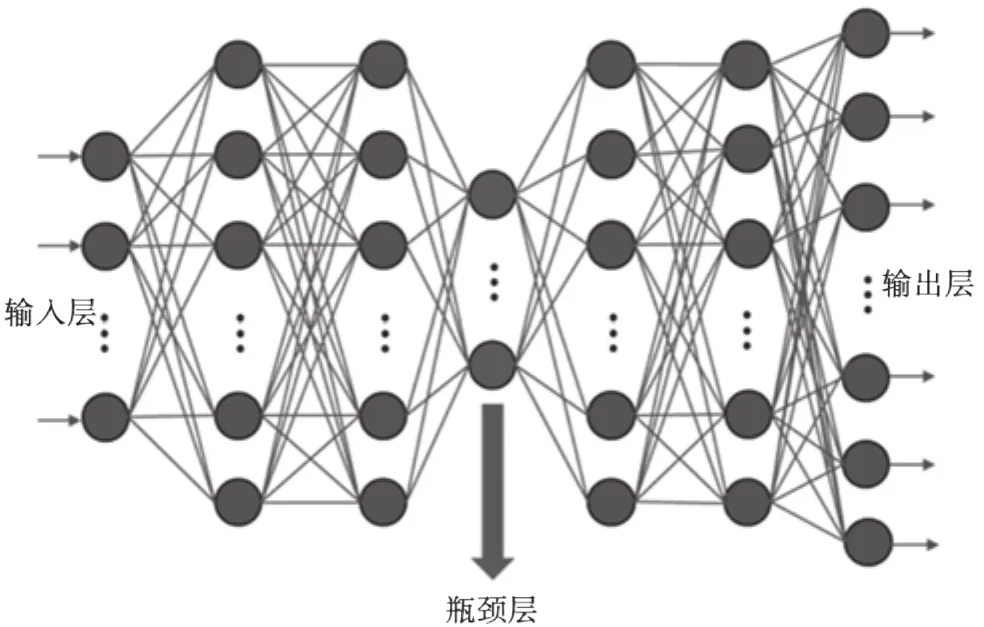
图1 BN-DNN模型结构
由于瓶颈层中的节点数量小于其他隐藏层,因此通过DNN的连续训练尽可能地将后续分类信息压缩为瓶颈单元的激励信号。DNN中的每个隐藏层都可以视为多输入特征的非线性变换。隐藏层的输出是原始输入的新表达形式。越深层的生成特征就越具有不变性和辨别性。通过DNN学到的特征表示在不同人和环境变化方面比原始特征更具有鲁棒性。由于BN-DNN模型引入了瓶颈层,可以有效减少输出特征的维度,以降低计算的复杂度。
训练方法:以MFCC声学特征作为输入数据,首先,将BN-DNN当作深度置信网络进行无监督预训练调整网络合适的初值,同时将MFCC未标注的数据输入BN-DNN训练,全面有效地提取语音特征;其次, BN-DNN进行微调优化,采用标注数据进行网络的监督训练,对网络模型更加精细的调整;最后,BN-DNN模型提取出语音瓶颈特征[8-12]。语音瓶颈特征提取过程与原始语音特征提取过程不同,它是在原始语音特征的基础上从BN-DNN中得到更具有说话人特性的语音瓶颈特征,该特征消除了冗余信息,其结构先验信息更加突出。特征提取流程如图2所示。

图2 基于DNN的语音瓶颈特征提取流程
2 基于改进的DNN模型语音瓶颈特征提取方法
针对大词汇量连续语音识别,目前基于DNN模型语音瓶颈特征提取方法在识别准确率的表现仍达不到期望目标,需要去掉大量的冗余信息,突出容易分类的说话人特性信息以至于特征数据不会过于庞大而增加不必要的计算量。此外,连续语音中前后帧信息之间具有一定的相关性,这些前后帧相关信息也是提高语音识别率的关键。
科学研究表明,人类大脑皮层中的神经元在处理信息的过程中是稀疏的,神经元在大多数情况下都处于非激活状态。因此模仿人类神经系统,将DNN中不工作的神经元设置为非激活状态,即对其进行稀疏化,并从中提取更有效的特征信息[13-15]。此外,对DNN进行稀疏正则化处理,在一定程度上提高了网络的泛化能力。
套索模型是Tibshirani提出的基于正则化的能够同时实现稀疏特征选择和模型参数估计的方法。BN-DNN中重叠组套索算法是在将每层神经元分成几个两两相互重叠,之后把组间的重叠结构作为先验信息引入到惩罚函数中,对整个神经网络进行稀疏化处理。
已知线性模型为:

其中,y=RN为响应向量,X∈RN×P为设计矩阵,β∈RP为回归系数向量,b∈RN为误差向量且全部误差变量独立同分布bn~N(0,σ2),n∈ (1,2,…,N),N为样本数,P为变量数。
重叠组套索模型,将P个输入特征分为J个组G={gj|j=1,2,…,J},其中gj∈ {1,2,…,P}表示组的索引集,且但不同的是重叠组套索模型允许相邻组之间的特征出现重叠。则重叠组套索模型为:
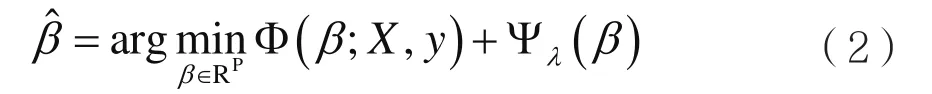
本文采用损失函数为交叉熵,即对目标概率p(x)和sigmoid函数的输出q(x)进行交叉熵运算。DNN网络参数训练采用反向传播算法,其目标函数表示为:

加入L2,1惩罚函数λ||p(h=1|v)||2,1。得到最终的目标函数:
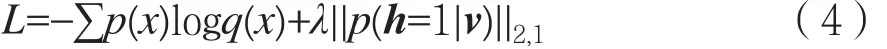
其中,||·||2,1为L2,1范数,p(h=1|v)表示隐含层神经元h的激活概率。对回归系数进行惩罚来压缩回归系数的大小,较小的回归系数自动被压缩为0,从而使目标函数学习的结果具有重叠组稀疏的特征。选择L2,1范数的原因有两方面:在组间,L1范数可以促进部分隐含层单元组的范数为0;在组内,L2范数具有组内相关性特征选择的作用。在语音瓶颈特征提取的过程中,BN-DNN参数训练时不仅受到组间稀疏化影响,还受到组内不同语音帧之间相关性信息的影响,因此提取到的语音瓶颈特征具有前后帧相关性优点。
对于式(4)中的重叠组套索L2,1范数稀疏正则项分解得到:
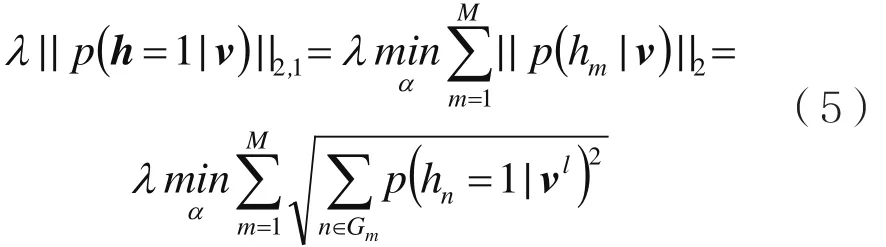
其中,Gm表示M个重叠组中的第m组神经元,n为Gm中对应的第n个隐层神经元,p(hn=1|vl)表示第l层隐含层中第n个隐层神经元的激活概率。
确定目标函数后,利用梯度下降算法计算目标函数的对数似然概率,从而推导出针对重叠组稀疏正则项的更新公式:
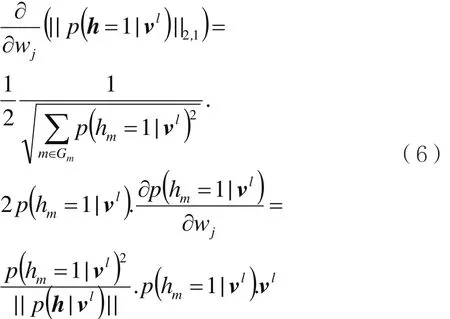
因此可得到BN-DNN训练的权值和偏置的更新公式:
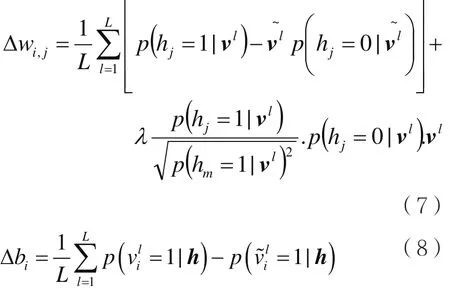
其中,λ≥0,L表示BN-DNN的目标函数,Δwi,j表示从节点i到节点j的更新权值,Δbi表示节点i的更新偏置。改进后的语音瓶颈特征提取方法如图3所示,在BN-DNN预训练之后加入重叠组套索算法、L2,1范数稀疏正则化,在BN-DNN训练的过程中进行稀疏化处理和参数调优。
训练方法:第一步仍然是初始化初值;第二步在BN-DNN目标函数后加入L2,1范数惩罚函数,使目标函数学习的结果具有重叠组稀疏的特性;第三步将原始声学特征MFCC作为BN-DNN的输入数据,使用BP算法对BN-DNN的参数进行调优。在训练的过程中,重叠组套索算法对回归系数进行惩罚来压缩回归系数,当回归系数较小时自动被压缩为0,这样在训练参数的同时对系数进行稀疏化处理,逐层更新网络权重集,获得训练好的稀疏BN-DNN模型;最后输出瓶颈层的语音瓶颈特征。
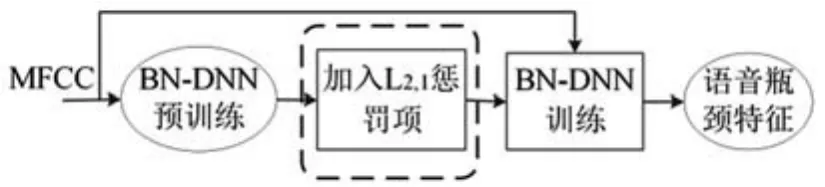
图3 改进的DNN语音瓶颈特征提取流程
3 实验与结果分析
本文使用Kaldi语音识别开源工具箱进行实验验证分析,其部署在Linux系统上,本实验选用500名说话人约5小时的Switchboard语音数据;测试集选用约1小时的语料库。实验中BN-DNN模型设置5个隐含层,将第3个隐含层设置为瓶颈层,其余各隐含层的神经元个数均为1 024;输入数据为连续11帧的40维MFCC瓶颈特征,因此,输入层的神经元均设为440(40×11)。本文将DNN网络结构设置为:440-[1024-1024 -1024-1024-1024]-440。
首先确定最优参数每组神经元个数Q和稀疏组重叠系数α。实验设置Q为64、128、256,重叠系数α为0%、20%、30%、40%。利用神经元中激活概率hi等于0的比例来度量网络的稀疏性,稀疏度定义为:
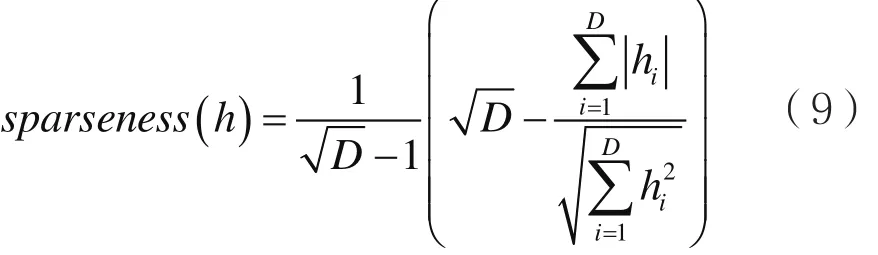
其中,D表示一层神经元个数,hi(i=1,2,…,D)表示神经元,由式(9)可知稀疏度的区间为[0,1],稀疏度越大表示该隐含层中神经元越稀疏,即权值为0的神经元个数越多。对于每个模型,首先使用训练集对模型进行训练,得出每一层神经元中的激活概率,然后将其代入式(9)中即可计算出该层的稀疏度,最后,计算出所有隐含层稀疏度的平均值作为整个神经网络的稀疏度[16]。重叠组套索稀疏DNN中不同Q和α情况稀疏度及词错误率(Word Error Rate,WER)的变化如表1所示。
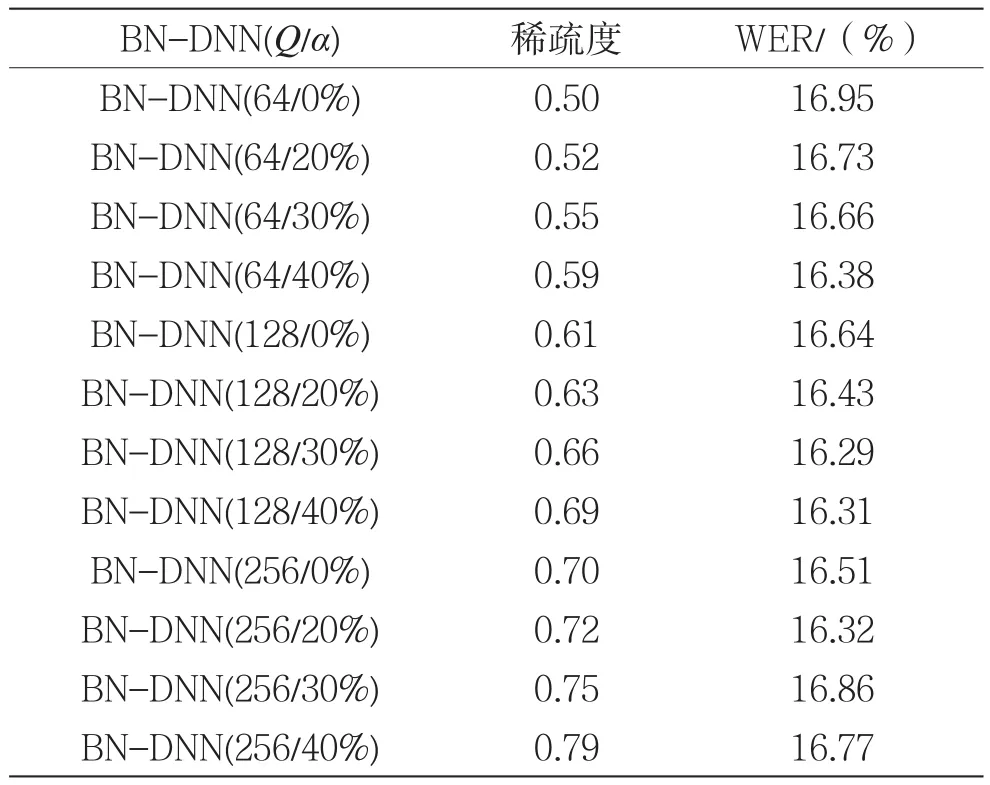
表1 不同Q和α情况稀疏度及WER的变化
从表1可以看出改进的重叠组套索稀疏BNDNN模型提取到的瓶颈特征比没有稀疏的BNDNN(α=0%)模型识别效果更好,随着稀疏度的增加,WER也会有一定程度的减小,但并不是稀疏度越大WER的值越小,当WER达到最小值16.29%后,其并不随着稀疏度的增加而继续减小,反而增加。所以稀疏度对WER有一定程度的影响,但并不是稀疏度越大越好,效果最好的参数选择是每组神经元个数Q=128,稀疏组重叠系数α=30%。
在表1中重叠系数α=30%与α=0%相比,其WER平均降低了0.29%,这说明改进后的重叠组套索算法BN-DNN模型提取到的语音瓶颈特征能降低一定程度的错误率。其原因是将L2,1范数稀疏正则项作为目标函数的惩罚函数,提高了目标函数的泛化能力,从而识别率也相应提高。
本文为验证改进语音瓶颈特征提取方法的有效性,设置Q=128,α=30%,网络结构设置为440-[1024-1024 -39-1024-1024]-440,将其提取到的语音特征与MFCC、Fbank语音特征进行了对比实验。实验结果如表2所示。

表2 不同语音特征的WER
从表2中可看出与其它语音特征相比,改进的瓶颈特征的语音识别效果最佳,使用瓶颈特征均比其它声学特征(MFCC、Fbank)的词错误率低。其原因是瓶颈特征比一般特征更具有前后帧相关信息表达能力,能很好地利用结构先验信息,同时利用重叠组套索算法对BN-DNN网络中的目标函数进行稀疏正则化处理,有效控制了深度神经网络的泛化能力,从而进一步提高了语音识别效率。
4 结 语
本文研究了联合L2,1范数惩罚函数和重叠组套组稀疏改进BN-DNN的语音瓶颈特征提取方法,该方法将L2,1范数惩罚函数、重叠组套索模型与BNDNN相结合,目的是提取出低维、更具有表征能力的语音特征,该网络架构是将两个BN-DNN串联,其中第1个BN-DNN主要用来对特征进行后验概率估计初始化,减少外界干扰对特征的影响;第2个DNN将监督性信息嵌入到提取的特征当中,同时实现稀疏降维。最后通过实验将该语音瓶颈特征与原始声学特征进行实验对比分析,验证了该方法的有效性,为后续语音识别声学模型环节提供较好的语音特征信息。
猜你喜欢
波谱学杂志(2022年1期)2022-03-15
安阳工学院学报(2020年4期)2020-09-11
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
作文周刊·高二版(2019年43期)2019-01-06
电子制作(2018年19期)2018-11-14
中国校外教育(下旬)(2017年8期)2017-10-30
创业家(2015年9期)2015-02-27
体育师友(2012年1期)2012-03-20
