
基于大数据平台的货车超偏载数据分车计算研究
2019-05-30 03:25杨连报刘宗洋
铁道货运 2019年5期
王 喆,杨连报,刘宗洋
(中国铁道科学研究院集团有限公司 电子计算技术研究所,北京 100081)
近年来,随着铁路信息化建设的逐步深入,系统覆盖面越来越广,积累的数据量越来越大。据初步统计,铁路数据总量已达PB级,日增长量超TB级。同时,随着物联网及传感器技术的广泛应用,特别是在铁路行车安全监控领域,积累了大量的结构化和非结构化数据[1]。对海量历史数据的分析和挖掘有助于发现新的业务规律和现象,从而指导业务流程的改进和创新,做到“强基达标、提质增效”。但是,由于铁路现有信息系统架构及硬件平台能力的限制,铁路各业务系统对历史数据的分析和利用效率不高。因此,依托铁路数据服务平台的分布式计算架构,对海量的铁路货车超偏载检测数据进行统计分析,实现分车(运输任务去重)计算,为后续开展铁路货运分析奠定基础。
1 货车超偏载数据分车计算
1.1 问题描述
为了保证货车上装载的货物不超载、不偏载、不偏重、不集重,货车运输沿途会设置许多超偏载检测装置对货车的超偏载情况进行检测[2]。超偏载检测装置主要由称重台面、传感器、数据采集仪和计算机等组成[3],一般安装在车站进(出)站信号机附近。当货车车辆以一定速度通过超偏载检测设备时,位于钢轨底部的压力传感器将接受到的压力变化转成数字信号传至计算机,计算得出货物相关的数据,并结合车号自动识别系统和确报系统在超偏载检测系统中生成一条记录,包括当前检测的车辆编号、总重、通过时间、发到站信息、测点编码、货物编码等。
目前,各铁路局集团公司在主要货运线路上部署了超过290个超偏载检测点,全路货车车辆保有量超过70万辆,上述车辆每年途径各检测点生成的检测记录总数约1.4亿条。假设一趟运输任务(从A地到B地)有N辆车组成,并途经M个检测点,在不考虑设备失效的情况下该趟运输任务会生成N×M条检测记录。铁路货车超偏载检测示意图如图1所示。
分车计算需要从这N×M条记录中去除重复代表同一趟运输任务的多条记录,并找出参与本次运输任务的车辆编号集合。分车计算的结果是实现货运运量统计、始到站(起点站—终点站组合)发送货物频次和运量统计、超偏载检测设备性能评估等计算的基础和前提。

图1 铁路货车超偏载检测示意图Fig.1 Freight train overload and unbalance load detecting system
1.2 数据基础
全路超偏载检测信息最终汇集在货运计量系统的超偏载子系统中,数据存储在Oracle数据库中。该数据库的车辆检测信息表中记录了每辆车经过检测点时的检测记录。超偏载车辆信息表部分信息如表1所示。研究选取全路2014—2016年的超偏载检测记录,数据量约4亿条。
1.3 计算方案
分车计算就是将一定时间范围内,从A站到B站之间多个检测点对若干辆车检测的记录中识别出相互不重复的运输任务,并且输出每趟运输所使用的车辆编号序列。计算方案如下。
(1)将所有记录按照不同车辆编号分组,在同一分组内再按照相同始发站、终到站分组,一共分成若干组。
(2)对每一组相同车辆编号、始发站、终到站的记录集按照检测时间升序排序。
(3)从分组的记录集中识别出A站到B站所经过的检测点序列SAB。相同始到站检测点序列示意图如图2所示。

表1 超偏载车辆信息表部分信息Tab.1 Partial information of vehicle table of overload and unbalance load detecting system
(4)以SAB序列为判断依据重新遍历记录集,将记录集分割成不同的运输任务,结束。

图2 相同始到站检测点序列示意图Fig.2 Diagram of the detection points sequence with same starting and destination point
该计算方案大体分作2个阶段,第一阶段分析得到A,B两站之间的检测点经路序列;第二阶段依据该序列进行运输任务识别。考虑到任意A,B两站之间的检测点序列为有限多个且在相当长的时间范围内不会发生变化,因而该方案的优点是使用该序列作为判断依据识别运输任务准确性较高。同时,由于该方案需要多次在海量记录集上的分组、排序、遍历等操作,对软硬件性能要求较高。考虑到使用传统的Oracle数据库结合SQL查询实现上述计算方案在时间开销上无法接受,研究利用大数据平台的分布式存储和计算架构解决上述问题。
2 基于大数据平台的货车超偏载数据分车计算研究
2.1 数据接入与存储
铁路数据服务平台以整合、集成成熟的开源大数据平台技术组件(Hadoop),采用分布式文件存储、分布式计算框架(MapReduce),以及分布式内存计算框架(Spark) 等开源产品或技术,同时利用统一目录、统一权限等实现完善的安全控制和数据管理功能[4-5]。铁路数据服务平台技术架构如图3所示。
数据集成模块能够实现结构化数据和非结构化数据的实时、非实时的采集。利用数据集成模块的结构化数据采集功能(StreamSets)从超偏载检测Oracle数据库中批量采集了3年的历史记录约4亿条,并存储在开源数据仓库(Hive)中。
2.2 方案实现
结合开源数据仓库自身的特点,分车计算的具体实现步骤如下。
(1)数据清洗。车辆检测数据表中车辆编号、始到站名称、检测点编号是判断和分组的重要依据。因此,数据条目中凡是上述字段为空的皆为无效数据。对原始的4亿条数据进行清洗后,余下约3.4亿条有效数据,将清洗完成的数据另存新表A。
(2)数据粗加工。在新表A中,对车辆编号进行分组并按照时间升序排序。针对每一个车号顺次扫描数据,处理原则如下:①当遇到前后两行始到站信息不一样时,可判断前一条记录为一趟运输,将该记录写入新表B;②当前后两行始到站一致但货物不一致时,可判断前一段记录为一趟运输,将该记录写入新表B;③当前后两行始到站和货物信息都一致时,继续向下搜索直到找到始到站不一样的记录,之前的记录都存入临时表C。
(3)经路序列处理。在表A中,按照相同的始到站进行分组,对每一对始到站,利用算法A1(探测点序列生成算法)产生当前始到站之间的探测点经路序列,将该结果存入字典表D。算法A1说明如表2所示。
(4)产出结果。遍历临时表C,对每一组车号、始到站相同的记录集进行遍历,结合字典表D,利用算法A2(探测点序列识别算法)识别相对独立的任务序列。每趟任务只保留一次探测记录并写入表B,表B即为分车计算的结果数据表。算法A2说明如表3所示。
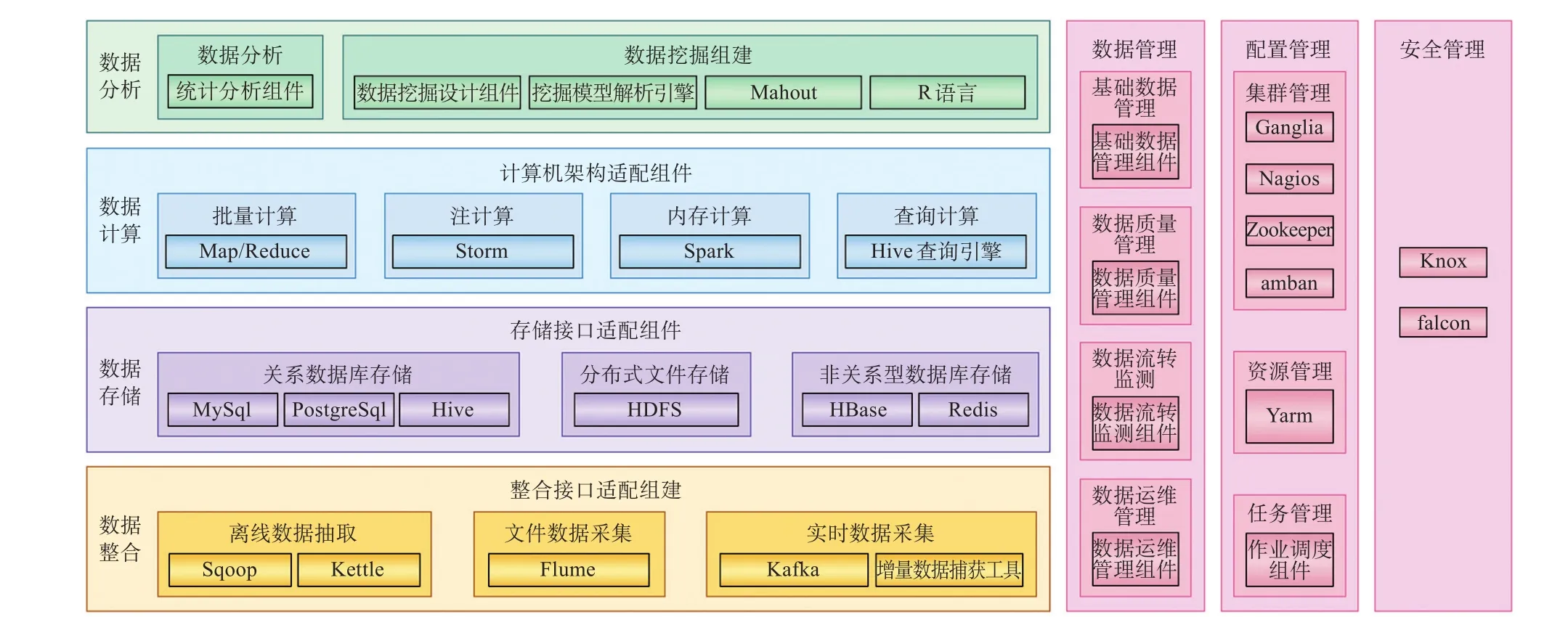
图3 铁路数据服务平台技术架构Fig.3 Technology architecture of railway data service platform
2.3 方案验证
参与计算的铁路数据服务平台部署于某单位内网中,集群规模为24台服务器。为了充分发挥铁路数据服务平台集群运算的优势,整个计算过程在平台上使用Spark SQL对Hive中结构化数据进行分析。Spark抽象出分布式内存存储结构弹性分布式数据集RDD进行数据的存储[6-7],考虑到分车计算需要大量的数据聚合运算,在使用Scala实现时,在UDAF(User De fined Aggregate Function)的派生类中重写了对DataFrame (升级版RDD)操作的各方法[8]。经实际测试,对清洗后的3.4亿条数据进行分车计算操作耗时约12 min,大大优于使用传统关系型数据库统计的方法。

表2 算法A1说明Tab.2 Explanation of algorithm A1

表3 算法A2说明Tab.3 Explanation of algorithm A2
通过对3年超偏载检测历史数据的分车计算,原始数据4亿条(有效数据3.4亿条)经过运输任务去重后得到结果数据约6 000万条。对结果数据的正确性验证同时采用了2种方案。方案一:宏观验证,即基于分车得到的结果数据进行运输任务统计,如2015年全路货物品类发送量排名、十大发货地排名、逐月货物发送量等;将统计结果同网络上公开发表的同样指标的数据进行比较,考察宏观层面的准确率。方案二:细节验证,即编写SQL脚本在Oracle平台上对一段时间内(数据记录在百万条量级,计算能力可接受范围内)的检测记录进行分车操作,充分利用关系型数据库增删改查的能力,生成最终结果集。将该结果集作为参照集同铁路数据服务平台生成的结果集进行对比,得到结果匹配度。
经对比,方案一的结果完全同现有公开数据匹配;方案二选取2015年1—3月铁路货运发送量按品类排序与超偏载计算记录数进行对比,匹配程度为96%。2种验证方案的最终结果充分证明分车计算方案的正确性,并且性能优势明显。
3 结束语
利用铁路数据服务平台存储和计算的优势进行超偏载检测数据的统计分析,不仅实现了分车计算,从海量结构化数据中去除了影响后续统计业务的重复运输任务,还得到了许多有价值的结果数据,如各货运站之间检测点序列,全路各相邻检测点之间行车平均时长,检测点称重误差范围等。这些结果数据对后续超偏载检测设备的状态判定有着重要价值,从而更加有效地保障铁路行车安全。下一步应充分考虑铁路大数据建设架构中“平台+应用”的模式,以铁路数据服务平台为基础,将研究的各项计算包装成微应用部署于平台之上,更方便地服务于业务部门数据分析人员,提供更灵活、更快速响应、更具扩展性的服务。
猜你喜欢
加油站服务指南(2022年6期)2022-07-28
现代苏州(2022年9期)2022-05-26
文萃报·周五版(2022年9期)2022-03-11
中国交通信息化(2020年11期)2021-01-14
湖北农机化(2020年4期)2020-07-24
中国交通信息化(2020年12期)2020-02-06
科学与财富(2018年28期)2018-11-16
科技与创新(2016年22期)2017-03-30
专用汽车(2016年4期)2016-03-01
专用汽车(2016年1期)2016-03-01
