
基于MFCC及其一阶差分特征的语音情感识别研究
2019-05-27 01:18罗相林秦雪佩贾年
现代计算机 2019年11期
罗相林,秦雪佩,贾年
(西华大学计算机与软件工程学院,成都610039)
0 引言
随着计算机科学的发展,计算机的计算能力逐年显著提升,语音情感识别充分利用现代计算机强大的计算能力,通过计算机识别语音情感信息,是人机交互的重要领域,在医疗、教育都有广泛的应用,目前很多国家都在进行这方面的研究。语音情感识别主要包括预处理、特征参数提取和情感分类三部分,预处理包括采样、量化、分帧加窗等操作,特征提取包括著名的MFCC特征提取、基频、共振峰、短时能量、短时过零率等。对于情感的分类,目前国内外学者普遍采用基本情感、情感二维空间、情感轮三种分类方式[1]。识别方法方面,目前国内外学者和研究机构采用SVM、DNN、HMM、RNN等分类方法。
本文通过提取语音信号的MFCC和其一阶特征,对特征进行归一化和降维后,采用SVM模型对进行训练,识别语音情感,提升了语音情感的识别率。MFCC特征反映了语音信号的静态特征,一阶差分MFCC特征则反映了语音信号的动态特征,两种特征结合是本文的一个特色;PCA降维降低了特征的维度,提升了模型的训练效率;用网格搜索法[2]对模型进行调参,求出最优解,方便实用;十折交叉验证法选用模型降低了由数据分割带来的模型评估的误差,利于模型择优。
1 语音信号的特征提取
1. 1 MFCC特征提取
研究表明,由于人耳的特殊构造,人耳的滤波作用在1000Hz一下为线性尺度,在1000Hz以上为对数尺度,这使得人耳对于低频的信号更加灵敏[3];人耳并不能区分所有频率分量,只有两个频率分量相差一定带宽时,人类才能区分,否则人就会把两个音调听成同一个,这称为屏蔽效应,带宽称为临界带宽。MFCC在一定程度上模仿了人耳的这一特性,MFCC滤波器组就相当于人耳的滤波器,提取过程如图1。
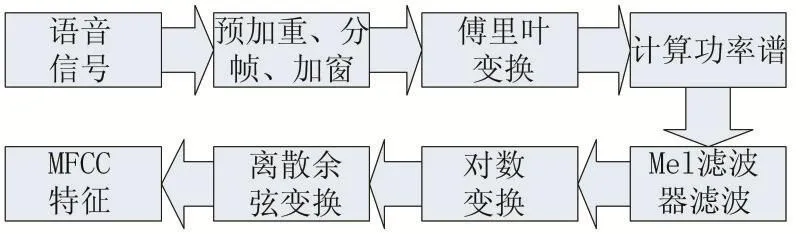
图1
预加重的作用是放大高频,平衡频谱,因为通常高频与低频相比具有较小的幅度,也可以改善信噪比,本文使用一阶预加重滤波器对信号进行预加重,公式如下:

其中α的值一般取0.95或0.97,本文取0.97。
信号预加重之后,需要将信号分成短时帧。这一步骤的基本原理是信号中的频率随时间变化,因此大多数情况下,对整个信号进行傅里叶变换是没有意义的,因为我们会随着时间的推移而丢失信号的频率轮廓。为了避免这种情况,我们可以假设在短时间内信号的频率是静止的。因此,我们通过在该短时帧上进行傅里叶变换,再通过相邻帧的连接来获得信号轮廓的良好近似。语音处理中典型帧大小范围为20ms至40ms,连续帧之间具有50%(+/-10%)的重叠,本文采用通常语音处理中的设置,帧大小为25ms,帧重叠为15ms。
分帧之后,需要对每一帧信号进行加窗处理。加窗的目的主要有两个:一是信号使全局更加连续,避免出现吉布斯效应;二是使原本没有周期的语音信号呈现出周期函数的部分特征。本文采用汉明窗进行加窗,汉明窗的公式如下:
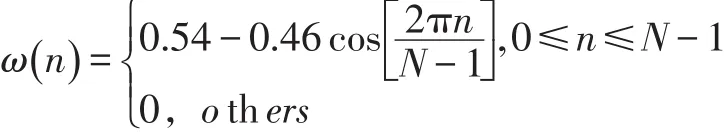
傅里叶变换将信号从时域变换到频域,得到信号的频谱特征,傅里叶变换的公式如下:
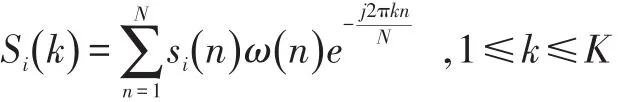
计算功率谱,即每帧谱线能量,公式如下:
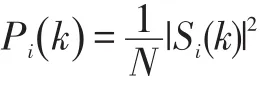
将每帧谱线能量谱通过Mel滤波器组,得到滤波后的能量谱,Mel滤波器公式:

将通过Mel滤波器组的能量取对数,然后进行离散余弦变换就得到MFCC特征。
1. 2 一阶MFCC特征提取
MFCC为语音信号的静态特征,不符合语音动态变化的特征,如果能提取语音的动态特征就更能反映语音的实际特性[4]。对MFCC进行差分运算就得到语音信号的动态特征,即一阶MFCC特征。差分运算公式:

其中d(n)表示第n个一阶差分,c(n+i)表示第n+i个倒谱系数的阶数,k表示差分帧的区间。
2 数据预处理和模型寻优
2. 1 数据归一化和PCA降维
由于提取到的初始特征在数量级方面相差很大,单位不统一,根据机器学习的相关理论,应该对数据进行归一化处理,提高机器学习的效果。本文采用数据缩放的形式,经过实验,将特征缩放到指定的区间,以提升语音情感识别效果。
语音情感识别的结果受特征参数的影响比较大[5],为了提高识别率,一般会提取更多特征,但是维数过多会造成维数灾难,导致识别率降低。因此,本文选择常用的一种降维方法,PCA降维方法对特征进行降维[6]。PCA是一个线性变换,将数据集变换到新的坐标系统中,使得任何数据投影的第一大方差在第一个坐标(称为第一主成分)上,第二大方差在第二个坐标(第二主成分)上,依次类推。PCA的目标是寻找r(r小于特征向量维数)个新变量,使它们反映事物的主要特征,压缩原有数据矩阵的规模,将特征向量的维数降低,挑选出最少的维数来概括最重要特征。寻找到的r个新变量是互不相关、正交的,它很大程度上体现了原始特征。
2. 2 支持向量机
本文选择SVM分类器进行语音情感识别。SVM是一种应用广泛的机器学习方法,具有如下特点:①非线性映射是SVM方法的理论基础,SVM利用内积核函数代替向高维空间的非线性映射;②对特征空间划分的最优超平面是SVM的目标,最大化分类边际的思想是SVM方法的核心;③支持向量是SVM的训练结果,在SVM分类决策中起决定作用的是支持向量;④SVM是一种有坚实理论基础的新颖的小样本学习方法。它基本上不涉及概率测度及大数定律等,因此不同于现有的统计方法。从本质上看,它避开了从归纳到演绎的传统过程,实现了高效的从训练样本到预报样本的“转导推理”,大大简化了通常的分类和回归等问题;⑤SVM的最终决策函数只由少数的支持向量所确定,计算的复杂性取决于支持向量的数目,而不是样本空间的维数,这在某种意义上避免了“维数灾难”;⑥少数支持向量决定了最终结果,这不但可以帮助我们抓住关键样本、剔除大量冗余样本,而且注定了该方法不但算法简单,而且具有较好的鲁棒性。
SVM用于处理多分类问题时,常用的有一对多(one-to-rest)和一对一(one-to-one)两种策略[7]。根据前期的分析研究,一对一的分类策略更有效,本文采用该策略。核函数是支持向量机的关键,目前常用的核函数有线性核函数、多项式核函数、高斯核函数等。根据前期的实验数据,文中采用效果最好的高斯核函数。如何选择合适的惩罚因子C和核函数参数g是训练一个SVM分类器的关键问题,本文采取网格搜索法[8]进行参数搜索,用K折交叉验证法进行评估,选择出最优模型。
2. 3 K折交叉验证
本文用十折交叉验证评估SVM的超参(C和g),进而选择模型[9]。模型评估的方法是将数据分为训练集、验证集、测试集,训练集用于训练模型,验证集用于模型的参数选择配置,测试集用于评估模型的泛化能力。传统的模型评估方法只需按比例将原始数据划分成三部分,不过如果只做一次分割,评估结果对训练集、验证集和测试集的样本数比例,还有分割后数据的分布是否和原始数据集的分布相同等因素比较敏感,不同的划分会得到不同的最优模型,而且分成三个集合后,用于训练的数据更少了。
K折交叉验证是对传统的模型评估方法的改进。以K取十为例,先将原始数据划分为训练集和测试集,再将训练集划分为十份互斥的数据,设定模型参数后,每次选取其中九份数据做训练集训练模型,另一份数据集作为验证集评估模型,总共进行十次,求出平均得分,得到模型最终得分。具体过程如图2所示。
K折交叉验证减少了原始数据分割后数据的分布对模型评估的影响,增强了模型的泛化能力。
3 实验与结果分析
3. 1 实验设计
本文选取德国柏林技术大学录制的柏林德语情感语料库作为实验数据,它共535句语音,由5男5女录制,它包含生气(anger)、害怕(fear)、高兴(happy)、厌烦(boredom)、悲伤(sad)、平静(neutral)、厌恶(disgust)7种情感。由于提取特征的单位和数量级不统一,经过实验,用[-10,10]将特征归一化效果最好,然后用PCA选择60个特征向量。
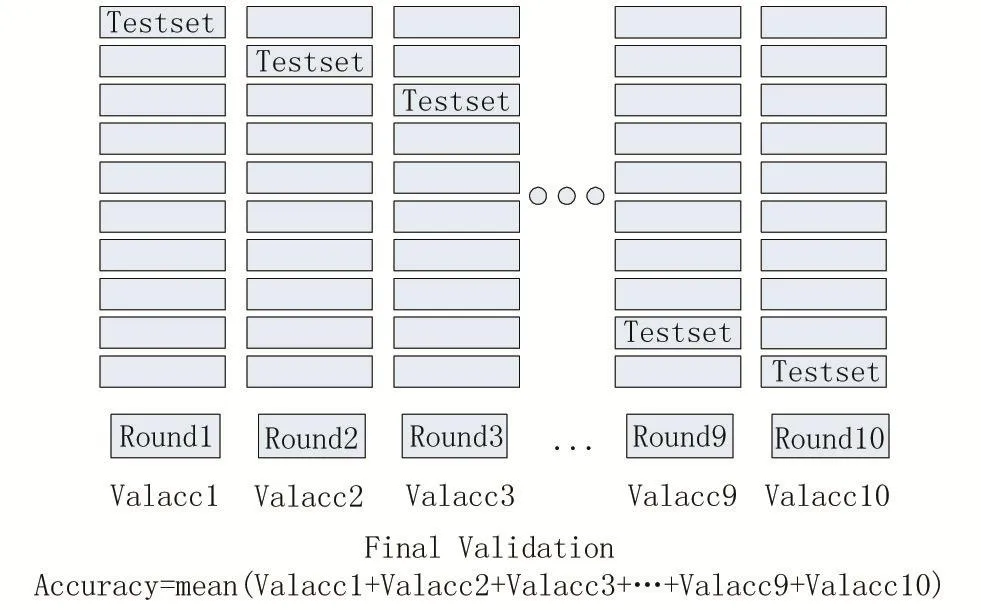
图2
首先将7类语音情感数据中的每一类随机抽取80%作为训练集,余下20%作为测试集,分别提取训练集和测试集的特征;其次将训练集随机划分成10份用于十折交叉验证训练和评估模型,选出最优模型;最后用测试集评估最优模型的性能,得出情感识别结果。本文提取MFCC和MFCC一阶差分特征的均值、方差、最大值、最小值共104维特征向量,用数据归一化和PCA对特征进行预处理,通过网格参数提供SVM的C和gamma值,并用十折交叉验证法对评估模型,最终选出最优模型,并用测试集测试模型的泛化能力,得出语音情感识别的结果。具体流程如图3。
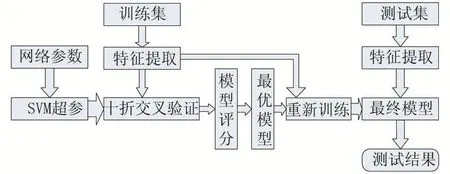
图3
3. 2 结果分析
运用上述实验设计流程进行实验,得到识别的混淆矩阵,结果如表1。
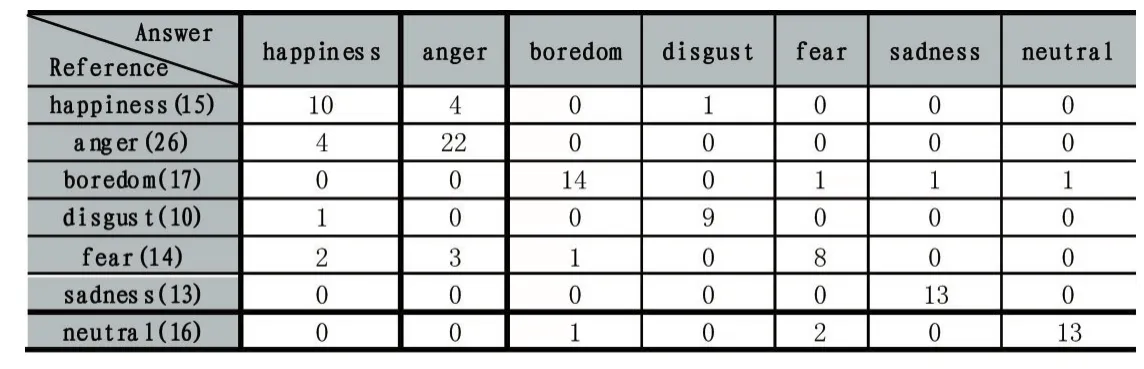
表1
分类结果报告如表2。
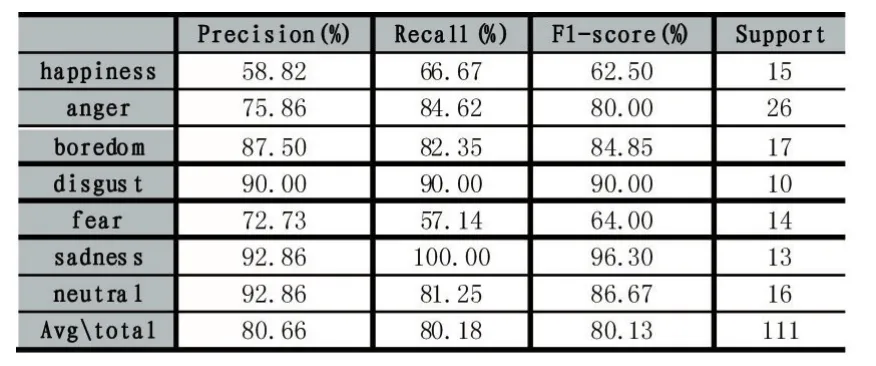
表2
从以上两张表可以看出:①采用7种情感的平均识别率为80.66%,每种情感的识别率都处于合理范围;②happiness情感容易被识别成anger情感,导致识别率较低,fear情感容易被识别成anger和happiness情感;③boredom、disgust、sadness、neutral识别率超过80%,其中 disgust、sadness、neutral识别率超过 90%。可见,本文的语音情感识别率较高。
在柏林语音数据集下,将本文实验结果与相关研究结果进行对比,如表3。
可见,除了文献[10]之外,其余的识别率均低于本文的语音情感识别率,说明本文的语音识别方法是有效的。文献[11]提取了语音信号的MEDC特征,本文并没有提取这种特征,识别率比本文高,也在情理之中;文献[11]采用DNN的识别率与本文识别率相近;文献[12]采用DNN+HMM的识别方法识别率比本文低2.74%。综上,本文的提出语音识别方法具有有效的识别率,且达到该领域的识别水平。

表3
4 结语
针对语音情感识别中特征维数高、识别率低的问题,本文采用PCA降低特征维数,用网格参数搜索结合十折交叉验证选择SVM模型。在柏林情感语料库的实验结果表明,本文采用的语音情感识别方法是有效的。但是happiness、fear和anger的识别率不高,希望以后进行相关研究,提高语音情感的识别率。
猜你喜欢
湖北大学学报(自然科学版)(2022年3期)2022-12-01
火力与指挥控制(2021年10期)2021-12-29
延安大学学报(自然科学版)(2020年4期)2021-01-15
阅读(快乐英语高年级)(2019年5期)2019-09-10
电子制作(2019年14期)2019-08-20
电子制作(2019年9期)2019-05-30
小说界(2018年5期)2018-11-26
中国高新技术企业(2017年5期)2017-05-05
软件(2016年6期)2017-02-06
物联网技术(2016年11期)2017-01-12
