
AttrHIN2Vec:一种新型异质信息网络表示学习模型
2019-05-27 01:18:46文鹏李青熊友
现代计算机 2019年11期
文鹏,李青,熊友
(重庆大学计算机学院,重庆 400044)
0 引言
信息网络,例如社交与通信网络、论文引用网络、航线网络,在现实世界中无处不在[1]。通常,这些信息网络的规模比较大,给网络数据分析带来了巨大的挑战。一种称为网络嵌入(也称为网络表示学习)的研究方法在学术界与工业界已经引起了越来越多的关注。网络嵌入的核心思想是将网络嵌入到低维空间,并将每个结点表示为低维特征向量。研究表明,网络嵌入在许多网络分析任务中表现优异,例如可视化、节点分类、链路预测和实体检索[2-8]。
在过去的几年中,许多文献从不同角度对网络嵌入进行了改进。当前比较流行的方式是将自然语言处理技术应用于网络嵌入,例如,NLP中著名的Word2Vec 模 型[9,10]。DeepWalk[2]和 Node2Vec[11]模 型 在随机游走后采用Word2Vec模型(Skip-Gram)。LINE[1]专注于一阶相似性和二阶相似性来表示网络。
然而,大多数传统的网络嵌入仅仅关注同质网络[1,11]。同质网络只能表示单一类型的节点和关系,这意味着它具有天然的局限性。传统模型在处理不同类型的结点和关系时表现不佳,异质结点的表示难以区分[12]。此外,模型[1,11]没有考虑节点的属性信息,这可能会损失一部分有意义的信息。事实上,大量的社交与信息网络具有结点类型丰富,结点之间的关系存在多样性的特点[13],这样的网络通常被描述为异质网络。Dong Y[12]提出了Metapath2Vec和Metapath2Vec++来解决异质网络表示学习带来的挑战,但它忽略了每个结点丰富的属性信息,并且没有关注元路径的权重信息。
在本文中,我们提出了一种名为“AttrHin2Vec”的网络表示学习模型,旨在获取异质信息网络(HIN)的丰富信息。我们首先采用带权重元路径的随机游走来生成结点序列;然后我们提出了一个名为“AttrSkip-Gram”的带属性异质Skip-Gram模型来嵌入结点;最后,我们获得了包括目标结点的结点属性信息的完整特征向量表示。通过这种方式,我们可以充分发现潜在的结点嵌入信息,进而为网络分析任务做出贡献。
总而言之,我们的工作做出了以下贡献:
●我们提出了一种名为“AttrHIN2Vec”的新型网络表示学习模型,它保留了异质网络的结点属性信息与权重信息。
●我们采用MovieLens-1M数据集进行了多标签分类实验。与 DeepWalk/node2vec,LINE,Metapath2Vec等最新网络表示学习模型相比,我们的模型效果更佳。
1 相关工作
最近,网络表示学习在学术界和工业界引起了广泛关注。它起源于应用于网络分析任务的潜在因子模型[14,15],例如,用于推荐系统、节点分类的分解模型。随着深度学习技术的发展,越来越多的基于神经网络的表述学习模型被提出。一个典型的例子是Word2Vec,它由一个双层神经网络组成,旨在学习自然语言处理中单词的分布式表示[9,10]。基于Word2Vec,Perozzi等提出了DeepWalk[2]。DeepWalk通过在网络中结点的随机游走形成一个序列,相当于词嵌入中文档的句子,然后将序列作为Skip-Gram模型的输入,最终得到结点的低维向量表示。此后,为了保留一阶和二阶相似性,Tang等人[1]提出了名为LINE的大规模信息网路嵌入方法。文献[11]中提出的Node2Vec模型在邻近节点的多样性方面表现良好。Node2Vec模型通过平衡广度优先采样与深度优先采样,生成目标节点序列。然后,通过最大化保留的网络邻近节点的相似度得到最终的节点表示。
然而,上述模型都是基于同质网络。由于异质信息网络在现实世界中具有更好的描述各种网络的能力,因此基于异构网络的网络嵌入日益引起重视。Yuxiao Dong等[12]研究了异质学习网络中的表示学习问题,通过改进随机游走策略和Skip-Gram算法,提出了基于元路径的随机游走和异质Skip-Gram算法,建立了Metapath2Vec模型。大量实验表明,Metapath2Vec在数据挖掘任务上的性能优于当前大多数异质信息网络表示学习模型。
本文通过设计AttrHIN2Vec模型,通过利用基于元路径的随机游走的结点属性信息和权重信息来捕获大规模异构网络中的潜在特征向量,进一步推动了这一方向的研究。
2 问题定义
文献[13]简要介绍了异质网络中的表示学习问题,我们据此提出属性异质网络的定义以及学习问题。
定义1属性异质信息网络表示为G=(V,E,A,T),其中,V代表网络中的结点集合,E代表结点相连的边集合,T为结点类型的集合,并且有|TV|+|TE|>2。对于任意一个结点v,存在一个映射函数φ(v):V→TV,TV代表结点类型。同样的,对于任意一条边e,存在一个映射函数φ(e):E→TE,TE代表边类型。A为结点属性集合,即A={a1…,am}。对于任意结点vi∈V,均关联一个属性向量[a1(vi)…,am(vi)],aj(vi)代表结点vi在属性aj上的取值。
属性异质信息网络表示学习:给定属性网络G,将网络中结点与属性都转化为向量的表示形式,即学习函数,其中VV是指结点向量,dV为结点维数;而VA则是属性向量,dA为属性维数。和通常的网络表示学习一样,在转化后的结点向量和属性向量需要满足:低维连续、拓扑结构完整性和属性完整性。
3 AttrHin2Vec模型
本文提出的属性异质信息网络表示学习模型Attr-HIN2vec包括两个主要模块,首先是基于带权重元路径的随机游走,用于生成路径序列;其次,在异质Skip-Gram结点向量更新的基础上加入属性向量的更新,提出属性异质AttrSkip-Gram。
3. 1 带权重元路径随机游走
传统的元路径随机游走算法忽略了元路径的权重信息,因此,本文采用带权重的元路径随机游走。对于给定的异构网络G=(V,E,A,T)和元路径P:,在第i步时的转移概率如下:
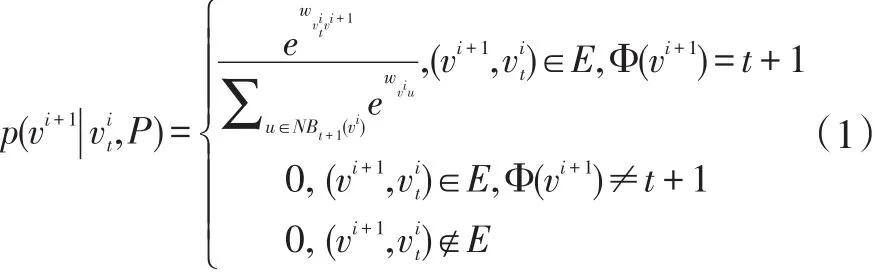
本文对于异质信息网络中的每个结点,依据定义的元路径,在权重概率的指导下都构造k条长度为l的路径序列,然后将这些路径序列当作文档训练集中的句子,那么结点的相邻结点则可以看作是对应的上下文结点。
3. 2 带属性Skip-Gram模型
本文提出带属性的Skip-Gram(简称AttrSkip-Gram)向量更新模块分别在metapath2vec的Skip-gram模型的更新模块基础上进行改进。利用带权重元路径随机游走策略在属性异质信息网络G=(V,E,A,T)中生成多条路径序列之后,就可以将这些路径序列当成文本中的句子,选取某条路径中一个随机结点v∈V就等同于选取文本中的单词,然后将v前后大小为τ的窗口定义为结点的上下文Nt(v),t∈TV,AttrSkip-Gram是根据Nt(v)中各个结点的向量更新中心结点v的向量。基于负采样的思想,在计算v的向量时,还需要另外进行负采样,即随机选取若干v以外的结点,记为NEG(v)。AttrSkip-Gram更新的目标是使得中心结点v的向量近似于其上下文Nt(v)中各结点的向量,并使Nt(v)中各结点的向量远离负样本NEG(v)中的结点。由于在异质信息网络中,还需要考虑结点的类型,所以希望最大化如下目标函数:
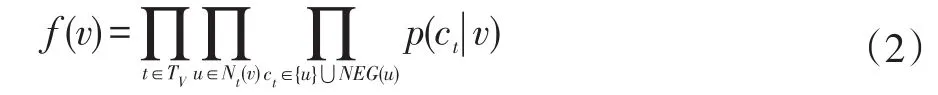
其中,
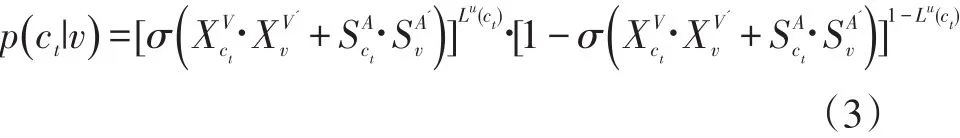

其中,M为结点与属性之间的映射关系矩阵,Mv表示结点v拥有的属性集合,为属性i的输出层向量表示,为属性i在投影层的辅助向量。因此,的物理意义为结点v拥有的属性的辅助向量之和,为结点ct所拥有属性的输出层向量之和。
在式(3)中,对于结点 v,正采样时,ct=u,Lu(ct)=1,公式前半部分有效,最大化 f()v则要求结点ct的属性向量与中心词的属性向量尽可能相似;负采样时,Lu(ct)=0,公式后半部分有效,则要求与中心词的属性向量尽可能不相似。
将其扩展到整个网络图G,整体的目标为最大化函数:

取对数后得到公式:
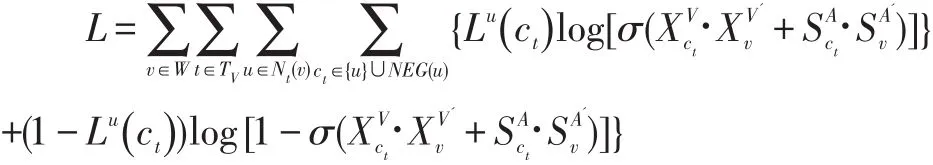
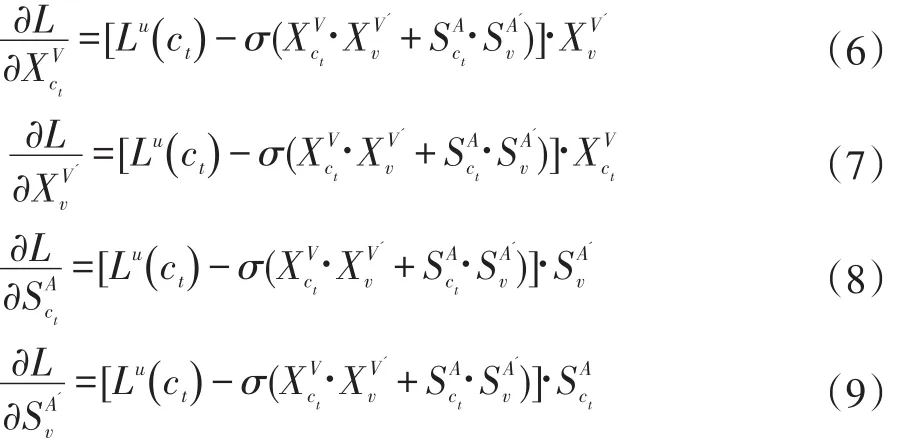
更新公式
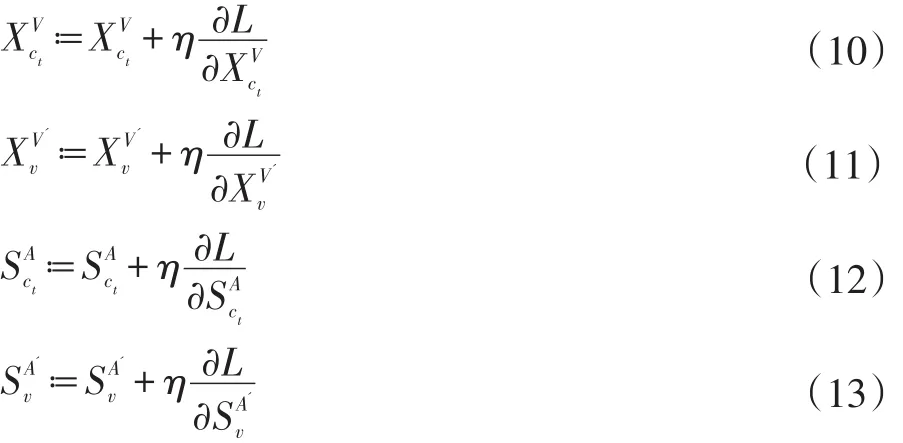

同样的,(12)中对于辅助属性向量vAi的更新为:

3. 3 AttrHIN 2Vec算法
AttrHIN2vec模型及AttrSkip-Gram更新相关向量的过程如下:首先初始化结点向量XV与属性向量XA,以及它们在投影层的辅助向量XV'与 XA'(1-2行),对于每个结点,都要生成k条带权随机游走路径(3-5行),其中,第5行为随机游走路径生成函数。然后依次根据各条路径中的节点及其上下文进行向量更新(6-9行),其中,第8行为AttrSkipGram函数。
第13-19行是随机游走路径函数genRandom-Walk,对于一个加权异质信息网络G,以及元路径P,以r为当前结点,生成长度为l的路径。
第20-33行是AttrSkipGram函数,用于更新相关向量。第22行中的eV表示上下文结点对于当前计算的中心结点或负采样结点u的更新量之和,第25行中将eV的值更新到各个上下文结点的辅助向量上;同样的,为上下文结点所包含的属性对于结点u的属性的更新量之和,26-28行中根据eA更新相关的属性在投影层的辅助向量。
AttrHIN2Vec算法
Input:
属性异质信息网络G=(V,E,A,T);元路径模式P;每个结点随机游走路径数k;随机游走路径长度l;结点向量维数dV,属性向量维数dA,邻居结点数量τ
Output:
结 点 向 量 矩 阵XV∈R|V|×dV,属性向量矩阵XA∈R|A|×dA


4 实验
本文通过多标签分类的实验来验证在Attr-HIN2Vec模型网络表示学习的效果。在本实验中,我们使用MovieLens-1M数据集[16]。MovieLens-1M数据集包含6040个用户,3883个电影和100209个电影评级,它们由用户表(users.dat),电影表(movies.dat)和评级表(ratings.dat)组成。
4. 1 实验设置
本文的分类任务是对电影的类型完成分类,由于在MovieLens-1M的数据集中,同一部电影可能会有好几种类型,在本实验中对于多种类型,随机选择其中的一个类型来做实验。我们比较的对象主要是其他网络表示学习的方法,包括以下几个:
(1)DeepWalk[2]/node2vec[11]:node2vec通过 p、q两个参数来控制随机游走生成的路径,调整p可以减少来回重复游走的情况,q可以控制随机游走是以深度优先搜索(q<1)还是以广度优先搜索(q>1)的形式进行随机游走。当p=1,q=1时,DeepWalk可以视作node2vec的一个特例。本实验即设置p=1,q=1。
(2)LINE[1]:本文使用考虑一阶相似度和二阶相似度LINE的改进版本进行实验对比。
(3)Metapath2Vec[14]:在 Metapath2Vec中,采用元路径(UMU,用户-电影-用户)的随机游走的异质信息网络进行网络表示学习。
(4)AttrHIN2vec:本文提出的在 Metapath2Vec模型的基础上,通过带权重元路径(UMU,用户-电影-用户)随机游走方法,在异质的Skip-Gram模型上增加结点属性进行训练。训练结果的结点用d维向量表示,前面维的向量是通过结点在异质信息网络中的拓扑结构训练得到的,而后面的维向量是将结点的所有属性向量取平均值。
本文使用如下相同的参数进行对比,另外还对本文提出的加权带属性的异质信息网络中的参数进行敏感度验证。
(1)每个结点为起始结点的游走次数 w为1000次;
(2)每次游走的长度l为100;
(3)训练出来的向量维度d为128;
(4)上下文窗口大小k为7;
(5)负采样的词的数量为5。
本文采用准确率和召回率的调和平均F值(FMeasure)进行评价。
4. 2 多标签分类实验
由于电影可能属于多种类型,因此在本实验中构建异质信息网络时,我们会随机选择一种类型作为结点的标签。首先,我们使用完整数据集进行结点表示学习。然后,将逻辑回归的训练集从10%到90%进行划分,将剩余的作为测试集,每个比例的训练集重复进行10次实验,取平均的F值进行比较。
表1中列出了多标签分类结果。简而言之,提出的AttrHIN2Vec比其他方法表现更好。例如,将10%结点作为训练数据,AttrHIN2Vec在DeepWalk/node2vec,LINE上的F值实现了0.59-0.71的改进。结果表明,metapath2vec和AttrHIN2Vec比其他模型表现更好,特别是当训练数据集较小时。
总之,通过多标签分类实验,AttrHIN2Vec比目前最先进的方法表现更好。AttrHIN2Vec的优势在于其在进行基于元路径的随机游走时,考虑了结点属性信息和以及元路径的权重信息。

表1 多标签分类结果
4. 3 参数敏感度验证
在基于Skip-Gram的表示学习中有几个常见参数(参见章节4.1)。下面将对AttrHIN2Vec模型中的参数进行敏感度分析。图1显示了当选择一个可变参数后,其他参数一定的分类结果的F值。分别进行了三个类别的实验,即图中边带权重结点无属性的情况、无权重有属性及带权重有属性。
图1(a)和图1(b)中每个根结点游走的次数与游走路径的长度在三类实验中,与分类的效果都是成正相关的,分类性能随着游走次数和路径长度的增加而收敛,游走次数在1000次之后收敛,而游走路径长度在100之后收敛,总体来看,带权重有属性在同等条件下比其他两类实验的效果更好。当w和l较小时,属性信息起着重要作用。当l达到一定量时,权重信息对分类的贡献更大。在图1(c)中,显示维数d对分类几乎没有影响。图1(d)反映了在上下文窗口数量设定方面,在7之后的效果也越来越差。
5 结语
本文重点研究异质信息网络中的表示学习。现有的网络表示学习工作较少考虑网络的属性信息和权重信息。为了填补这一空白,我们提出了一种新型的模型:属性异质信息网络向量表示模型(AttrHIN2Vec)。它可以用来捕获网络中的潜在特征。实验表明,AttrHIN2Vec学到的潜在特征表示可以改善网络分析任务,如多标签分类。
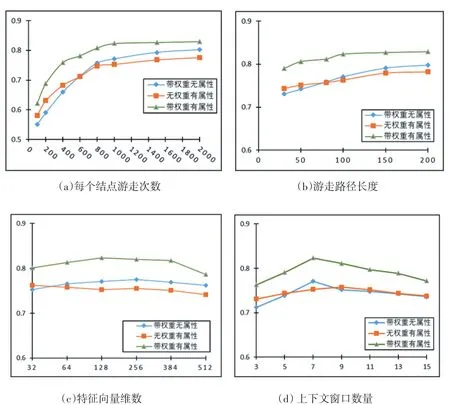
图1 分类中的参数敏感度验证
我们计划在以下两个方向继续我们的研究。随着不同类型节点和关系的增加,构建属性异质信息网络的成本将非常高。因此,提高构建效率尤为关键。此外,在构建网络时,属性的选择是一个值得研究的问题。
猜你喜欢
刑法论丛(2018年2期)2018-10-10 03:32:22
法律方法(2018年3期)2018-10-10 03:21:34
数学物理学报(2018年1期)2018-03-26 08:16:42
学习月刊(2016年4期)2016-07-11 02:54:12
湘江法律评论(2016年0期)2016-06-15 20:29:29
云南师范大学学报(自然科学版)(2015年5期)2015-12-26 12:46:16
中央民族大学学报(自然科学版)(2015年2期)2015-06-09 08:45:26
物理实验(2015年10期)2015-02-28 17:36:52
电子设计工程(2014年12期)2014-02-27 11:58:23
公务员文萃(2013年5期)2013-03-11 16:08:34
