
基于TextCNN情感预测器的情感监督聊天机器人
2019-05-25 06:54周震卿韩立新
微型电脑应用 2019年5期
周震卿, 韩立新
(河海大学 计算机与信息学院, 南京 211100)
0 引言
从ELIZA[1]、PARRY[2],到小冰、Siri,聊天机器人一直受到学术界和工业界的广泛关注。按功能可以将聊天机器人划分为任务型和非任务型。任务型聊天机器人可以在特定场景下,代替人完成某些工作,例如Siri就可以通过语音交互,帮用户完成拨打电话、查找文件等任务。非任务型聊天机器人通过不断与用户对话,达到情感陪护的目的。非任务型聊天机器人的实现方法可以分为检索式和生成式2种。检索式聊天机器人需要预先构建知识库,针对用户的问题,利用文本匹配、检索和排序方法,从知识库中找出最合适的句子作为回复。而生成式聊天机器人则直接从大量人与人的对话中学习对话模型,然后利用对话模型为收到的用户信息“创作”回复[3]。相比检索式聊天机器人,生成式聊天机器人更加符合人类学习对话的方式。
Ritter等[4]借助统计机器翻译技术构建语言模型,把问题“翻译” 成回复。Vinyals 等[5]利用 Sequence-to- Sequence[5]模型,构建了一个基于神经网络的对话模型。梁苗苗[6]借助主题模型,在解码过程中加入句子的主题信息。赵宇晴等[7]利用强化学习中的策略梯度方法,代替原有的极大似然损失训练聊天机器人。利用 Sequence-to- Sequence 模型构建聊天机器人存在2个问题:(1)容易生成缺乏语义的回复,(2)在进行多轮对话时,上下文语义不一致。
对于回复缺乏语义问题,目前比较好的解决方法是在回复生成的过程中加入情感特征。Zhou等[8]对不同情感建模,引入多种情感表达策略构建了ECM(Emotional Chatting Machine),但ECM在生成回复时,用特定情感代替一句话具有的复杂情感,存在一定的不足,而且ECM需要人为给定回复的情感;曹东岩[9]通过情感分类器、情感转移概率矩阵和外部情感词典,间接获得回复情感表示,在解码过程中引入情感特征,但是情感转移概率矩阵是通过统计问题与回复的情感获得,利用它间接得到的回复情感向量不够准确,而且这种方法并没有真正地监督回复情感,只是在解码的每个时刻简单加入情感向量。
为了解决上述问题,本文利用TextCNN模型提取句子中的N-gram信息,并构建端到端的回复情感预测器,对回复情感建模,直接由问题获得回复情感表示。在引入情感特征时,本文并不是简单获取某个特定情感(例如“高兴”、“难过”)的向量表示,而是提取整个句子的情感向量,这个向量更准确地表征了回复情感。另外,仅仅在模型中引入单一的情感特征是不够的,为了增加回复情感信息,实现对聊天机器人的高效情感监督,本文进一步在Sequence-to-Sequence模型损失函数中引入情感分类损失,真正地在训练过程中实现了情感监督,从而能够利用该监督方法,有效地指导语言模型对情感表达的学习,进一步解决了聊天机器人回复缺乏语义问题。
1 基于TextCNN的情感预测器
用低维向量表示词,可以避免传统one-hot方法存在的稀疏问题,同时捕捉到了词的语义信息。情感同样可以用向量形式化地表示。Zhou等[8]从文本中获得了6类情感的向量表示,作为聊天机器人解码的情感输入。曹东岩[9]在对问题进行情感分类的基础上,学习问题与回答之间的情感转移概率,结合外部情感词典获得回复的情感表示。Kim[10]利用CNN网络提取句子特征,在文本分类任务中取得了很好的效果。基于上述工作,本文设计了一个基于TextCNN[10]的情感预测器(TCNN Emotion Predictor,TCNN-EP),由问题直接获得回复情感表示。TCNN-EP结构如图1所示。
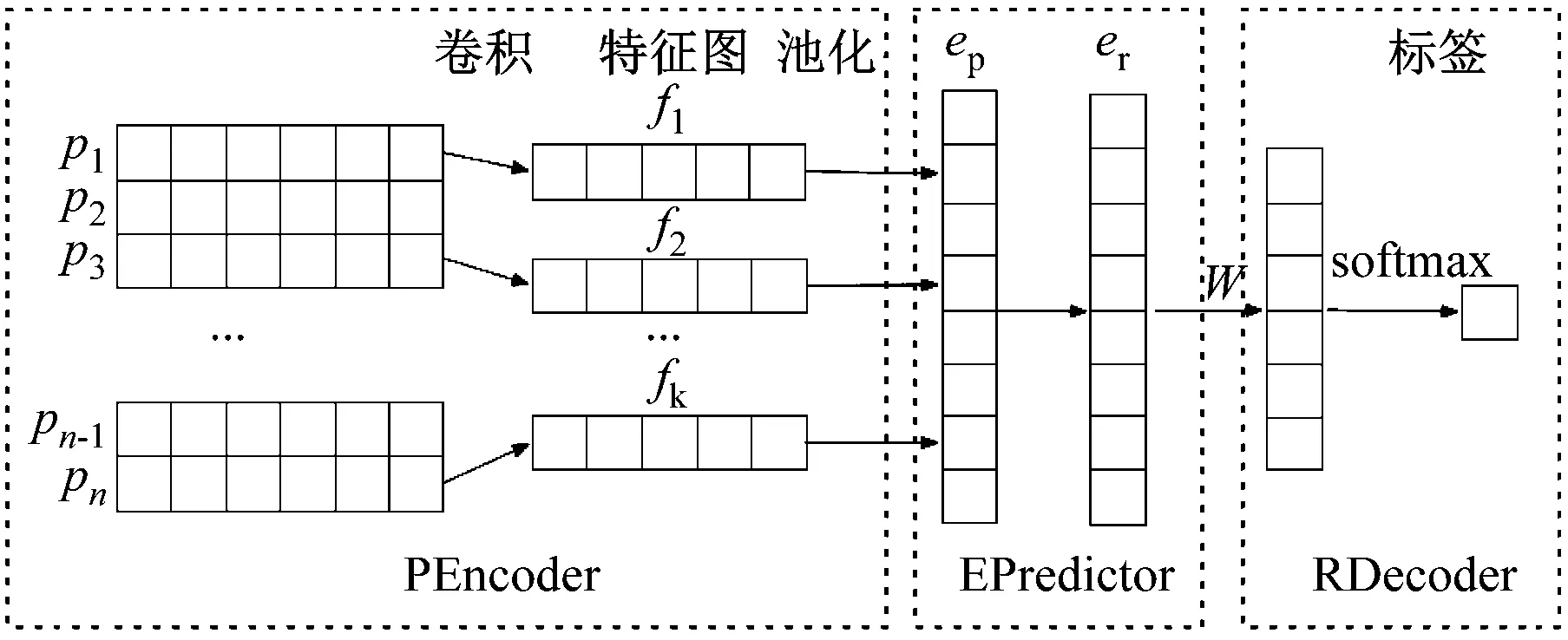
图1 TCNN情感预测器
Pencoder是问题情感编码器,EPredictor是回复情感预测器,RDecoder是回复情感解码器。对输入序列P
ep=PEncoder(P)
er=f(Wprep+bpr)
l=sample(RDncoder(er))
(1)
对于训练好的RCNN-EP,只需要把问题P输入问题情感编码器PEncoder,通过情感预测器EPerdictior,就能获得P的回复情感向量er。
2 情感监督聊天机器人
目前生成式聊天机器人采用Sequence-to-Sequence模型实现。这种模型将问题序列P编码成高维语义向量h,再对h解码获得回复R。然而,仅仅用一个高维向量并不能很好地表征一句话蕴含的所有语义信息,当问题序列较长时,h往往只能“记住”序列后半部分的信息。同时,现有模型在生成回复时,更倾向于选择 “是的”、“恩”等普适性回复。针对生成式聊天机器人回复缺乏信息问题,本文提出了一种情感监督聊天机器人模型——ESC(Emotion-Supervised Chatbot)。ESC是基于Sequence-to-Sequence模型和注意力[11]机制,它利用GRU网络完成编码和解码,同时在解码中融合回复情感特征,最后利用情感判别器对回复进行情感监督。该模型结构如图2所示。

图2 情感监督聊天机器人
对输入序列P
rt=σ(Wr·[ht-1,pt])
zt=σ(Wz·[ht-1,pt])
(2)
其中[ht-1,pt]表示把上一层的隐层输出与当前输入组合成一个新的向量。

(3)
score(·)是打分函数,用来衡量向量之间的相似程度。
除此之外,回复情感向量er需要与前一时刻的解码输出yt-1的词向量重新组合,构成t时刻的输入向量it如式(4)。
it=Wi·[emb(yt-1,er]+bi
(4)
emb(yt-1)表示yt-1的词向量表示。t时刻解码层输出yt式(5)。
projt=softmax(U·dt+b)
yt=sample(projt)
(5)
在解码完成后,需要将解码输出序列R=(y1,y2,…,yT)作为回复情感判别器REC的输入,但R是通过采样得到的离散值,因此损失函数并不可导。如果把输出序列直接作为回复情感判别器的输入,会导致情感分类误差无法反向传播。所以这里取解码层的隐层输出D=(d1,d2,…,dt)作为REC的输入。回复情感L′的计算公式如式(6)。
L′=sample(RDncoder(D))
(6)
整个模型的损失计算公式如式(7)。
Loss=θLoss(R,R′)+(1-θ)Loss(L,L′)
(7)
R是目标回复,R′是模型给出的回复。L′是模型输出的情感分类结果,L是目标回复R的情感标签。通过情感因子θ,可以控制情感分类损失在整个模型损失中所占的比例,从而达到情感监督的效果。
3 实验
3.1 实验描述
本文的模型采用Pytorch框架实现,另外在实验过程中还使用了gensim工具包。
实验数据采用 Zhou等[8]提供的6个分类情感语料,包含1 119 207组对话,共有98 619个词。在建立词典时选择了30 000个词,这些词可以覆盖整个数据集99.3%的词,其他的词用UNK表示,词向量为256维。
实验首先利用gensim中的word2vec模块训练词向量,用于模型词嵌入层的初始化。随后,针对问题和回复,分别训练了2个情感6分类器PEC和REC,这两个分类器都采用Text-CNN框架,模型结构与参数设置完全相同,均采用6个大小分别为3、4、5的卷积核(每种尺寸各2个)提取文本特征。然后利用训练好的PEC和REC组合训练TCNN-EP。训练过程中,除了EPredictor中全连接层的参数,其它参数均固定不变。最后通过TCNN-EP获得一个256维的回复情感向量,用于Sequence-to-Sequence模型的解码,并利用REC对解码结果进行情感分类。Sequence-to-Sequence模型的编码和解码层均采用3层双向GRU网络,每一层有256个隐层单元。
实验的基本模型采用了传统的Sequence-to-Sequence模型,词典以及模型参数设置均与本文提出的模型一致。另外,针对情感因子θ的不同取值进行了多组对比实验。
模型的训练均采用Adam优化器,学习率初始值为0.000 1,每10 000轮下降5% dropout设置为0.5,批大小为512,权重衰减率为10-8,损失函数均采用交叉熵损失。
3.2 实验结果
本文通过学习回复情感的向量表示,在生成式聊天机器人中引入情感特征,利用情感监督策略很好地解决了回复缺乏语义的问题。表1展示了基本模型与ESC给出的回复,其结果表明TCNN-EP能很好地预测回复的情感特征。

表1 基本模型与ESC的回答
表2展示了情感因子取不同值时ESC的回复,结果表明的不同取值对回复的质量有重要影响。

表2 情感因子模型回复
除了直观上的评价,本文还采用了3种方法综合评估模型,分别是困惑度[12]、BLEU[12]和人工评价[12]。困惑度是常用的语言模型评价标准,困惑度越低,模型效果越好。BLEU指标反应了两句话的一致程度,BLEU数值越高,两句话越一致。上述两种评价标准关注句子之间文字的一致性,而人工评价往往更关注语义,由于是人工对句子进行评价,所以往往能从语义角度评价模型。在人工评价的过程中,笔者找了20名志愿者,对同一问题5个模型产生的回复按喜好排序。志愿者们事先并不知道哪句回复由哪个模型产生。排名1、2、3、4、5的回复分别获得5、4、3、2、1的评分,最后获得每个模型的平均得分。

表3 多个模型的比较
表3展示了5种模型在3种评测方法下的平均得分。实验结果表明,当情感因子θ取0.4时,ESC在3个指标上都明显优于传统的Sequence-to-Sequence模型,这说明通过本文提出的方法引入情感特征是切实可行的,也反映了在回复生成中引入情感特征的重要性。此外,情感因子θ的不同取值对回复质量也有明显影响:当θ取值较小时,ESC在各项指标上接近基本模型;而当θ取0.4时,ESC的效果最好;当取值较大时,ESC的回复质量明显下降,甚至在BLEU指标上低于基本模型。
4 总结
情感监督聊天机器人通过感知情感,很好地将情感信息引入对话生成,提高了生成回复的质量。在对句子情感编码时,本文使用TextCNN模型,利用卷积网络具有局部特征提取的功能,充分提取了句子中类似N-gram的关键信息。同时,本文在Sequence-to-Sequence模型的训练过程中加入情感监督,使得模型除了能学到语言规则,还可以学习情感表达,达到了增加回复情感信息的目的。未来的研究可以基于深度强化学习与生成对抗网络的方法,来改进生成式模型的目标函数与训练方法,从而获得更合理的回复。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
南方周末(2019-12-19)2019-12-19
中国外汇(2019年19期)2019-11-26
南方周末(2019-07-18)2019-07-18
南方周末(2019-05-09)2019-05-09
意林(2017年9期)2017-06-06
少年文艺·开心阅读作文(2017年4期)2017-04-07
长江学术(2016年4期)2016-03-11
人间(2015年21期)2015-03-11
长江学术(2015年1期)2015-02-27
