
SDN中基于信息熵与DNN的DDoS攻击检测模型
2019-05-15 11:44王劲松
计算机研究与发展 2019年5期
张 龙 王劲松
(天津理工大学计算机科学与工程学院 天津 300384) (计算机病毒防治技术国家工程实验室(天津理工大学) 天津 300457) (天津市智能计算及软件新技术重点实验室(天津理工大学) 天津 300384)
分布式拒绝服务攻击(distributed denial of service, DDoS)一直以来都是互联网的主要威胁之一[1-4].DDoS攻击者通过扫描网络,发现存在漏洞的主机,并将这些存在漏洞的主机作为傀儡机向目标服务器发送大量请求数据包,导致目标主机丧失服务功能,致使网络故障.分布式拒绝服务攻击种类繁多,比较常见的有利用UDP进行的分布式反射拒绝服务攻击、利用TCP三次握手过程进行攻击的SYN Flood攻击等[5].现如今网络多采用分布式架构,这种网络架构构建之初是为了体现其高扩展性的分布式结构,但是也导致了很多安全漏洞的出现[6].软件定义网络(software defined networking, SDN)作为新兴的网络架构,已经逐步流行并被广泛研究,被认为是网络发展的方向[7],因此,关于防止SDN网络中的DDoS攻击对于SDN网络安全是十分重要的[8].
SDN是网络虚拟化的一种实现方式,它将网络的控制层和数据层分离,达到“软件管理网络”的目的.SDN网络的控制层能够集中控制整个网络的信息,控制器中开放了多个编程接口,便于网络管理人员管理网络.SDN网络集中控制的特点使控制器成为DDoS攻击者的主要攻击目标[9].当攻击者向SDN网络发起DDoS攻击时,为了通过网络安全设备,会伪装源IP地址,交换机持续收到大量的数据包,这些数据包并不在原流表中.控制器不断收到来自交换机的转发数据包,成为被攻击对象.当控制器的资源被耗尽时,整个SDN网络陷入瘫痪.因此及时检测并终止SDN网络中的DDoS攻击流量成为现在的研究热点,但是如何及时发现异常流量,精准识别异常流量成为当前研究的难点[10].
为防御DDoS攻击,如何发现网络中的异常流量是主要的研究方法.大多数情况下,攻击者将异常流量伪装成正常流量,因此很难甄别.基于信息熵的检测方法与基于机器学习的检测方法就是众多检测方法中的两种,但这2种检测方法都存在缺陷.基于信息熵的检测算法检测速度快,并不需要构建较多的流量特征,但是相较于基于机器学习的算法存在准确率较低且误报率较高的缺点.基于机器学习的DDoS流量识别方法具有较高的准确率,但是检测过程中需要手动构建较多的流量特征,影响检测速度.因此如何找到一个模型方法,其既能够具有异常流量的高识别率,又有对高速流量的反应能力和检测效率,成为研究的难点与挑战.
深度学习算法的出现解决了机器学习的局限性.深度学习的过程就是使用多个处理层对数据进行高层抽象,得到多重非线性变换函数的过程.深度神经网络(deep neural network, DNN)在图像识别、语音识别等领域取得了很好的效果.与传统的机器学习相比,深度神经网络通过多层的非线性变换,组合低层特征形成更加抽象的高层表示,使得一个学习系统能够不依赖人工的特征选择,发现数据的分布式特征表示,并学习到复杂的表达函数[11].随着GPU技术以及多种深度学习平台的不断发展,使得深度神经网络能够快速处理海量数据的分类工作[12-13].因此,基于深度神经网络识别DDoS异常流量,不需要手动设计过多的流量特征,同时具有更高的检测准确率与更快的检测时间.但是在实际应用中,由于SDN网络中流量巨大,将全部流量进行检测耗费巨大的计算资源,并且对检测的实时性造成影响.
因此,综合之前的研究与学习,本文创新性地提出了一种基于信息熵与DNN的DDoS检测模型.该模型包括了基于信息熵的初检模块和基于DNN的检测模块.该检测模型汲取了信息熵和DNN算法的优点,在初检模块发现流量异常之后再进行精度测量.该模型弥补了基于信息熵的检测算法识别率低、误报率高的缺点;也缩短了基于DNN算法的检测时间,降低了资源占用率,不仅可以提高检测的准确度,还可以缩短检测的处理时间,节省了DNN算法对资源使用频率.
本文的主要贡献有3个方面:
1) 提出了一个SDN中检测DDoS攻击的模型,该模型包括基于信息熵的初检模块和基于DNN检测模块,结合2种方法的优点,提高模型识别率、准确率,降低模型误报率,加快检测速率,减少计算资源占用率.
2) 利用OpenFlow协议字段、手工提取等方法构造出了19维特征向量,作为DNN模型的输入.经过训练与测试,该模型识别DDoS流量的准确率高于传统机器学习方法,并具有更低的误报率.
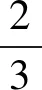
1 研究现状
DDoS攻击发展至今已经成为当今互联网的重大安全威胁[14].网络技术不断发展,各种新型网络架构的出现与智能设备的普及,使得DDoS的攻击方法呈现出多发性的发展趋势[15].随着网络科技的进步,DDoS攻击者也开始利用新的网络设备或网络架构发起攻击.近年来SDN网络成为研究人员与网络服务供应商的研究热点,而SDN中的DDoS攻击问题是其中的研究热点之一[16-17].
Fonseca等人[18]提出了一种设立备用控制器的方法,当SDN网络遭受到DDoS攻击时,交换机断开与控制器的连接,连接到其他备用控制器上.该方法能够暂时缓解DDoS攻击带来的危害,但不能从根本上防止DDoS攻击.一旦备用控制器也都遭到攻击,整个SDN网络将失去控制.Kim等人[19]提出了一种基于流量阈值预测攻击的方法.该方法通过提取NetFlow流数据构造流量特征,并通过检测函数来计算流量特征并设计阈值.然而,这种方法需要处理预先收集的数据流量,并且需要大量的前期准备工作.此外,测试的成功与否与研究人员的实际经验密切相关.
Giseop等人[20]提出了一种快速熵计算方法发现流量中的DDoS攻击,通过统计网络流量计算一段时间内的熵值,若熵值超过阈值则认定网络中发生了DDoS攻击.该方法成功地提高了检测速度,但未能显著提高检测准确率,且算法具有较高的误报率.Jun等人[21]提出了一种基于流熵和包采样的大型网络检测机制.该方法提高了检测的准确率并降低了误报率,但它根据相关经验设置了阈值,增加了人为因素的影响.Kalkan等人[22]提出了一个统计解决方案来检测SDN网络中的DDoS攻击,该方法提取流量特征,生成特征矩阵,通过流量特征之间的不同组合计算联合熵发现流量中的异常流量.该方法与以往基于熵的检测算法相比有了很大的改进,检测范围与检测准确率都有了很大的提升,但是该方法需要较长周期的准备与统计,计算较为复杂,可扩展性差,实时性不高.Kumar等人[23]提出了一种基于熵的SDN网络中TCP SYN泛洪攻击的早期检测技术.该技术基于流量特征,通过计算一个基于时间的数据包窗口序列内的流量特征的熵值,来测量在SDN控制器接收的数据包的随机性程度.并与该实例下的阈值(自适应)进行进一步比较,该方法能够对攻击进行早期检测.但是,该方法假设只有一个目标节点,不具有普遍性,而且该方法只针对TCP SYN Flood攻击.通过以上的研究可知,在SDN中,现有的基于信息熵的DDoS检测方法很难兼具高准确率与高检测速率.
Chen等人[24]提出了一种基于SGBoost的DDoS流量检测算法,该方法使用SGBoost分类器对KDD 99数据集进行测试,测试结果表明该方法具有检测准确率高和检测速度快等特点.但是该方法用于其他实验环境数据的检测效果未可知.Yang等人[25]利用支持向量机(support vector machines, SVM)的方法检测SDN中的DDoS流量.该方法同样对KDD 99数据集进行测试,测试结果表明了该方法的有效性.该方法也面临实际检测效果未知的问题.同时文献[24]与文献[25]提出的方法都需要手动构建大量特征,影响检测效率.Tang等人[26]提出了一种基于深度学习的SDN中异常流量检测方法,该方法设计流量特征,利用深度学习算法检测SDN网络中的异常流量,较之前的机器学习方法在准确率上有所提高.但是检测效率却不高,当流量巨大时,正常流量的检测会消耗深度学习硬件的资源,增长计算时间.
通过以上的研究发现,基于信息熵的检测算法中存在诸多问题:阈值的确定往往会带来识别率与误报率的矛盾、计算复杂度高、可扩展性差、检测速率不高以及数据统计周期较长.基于机器学习的检测算法中同样也存在检测速率低、CPU占用率高、未使用实际数据验证等问题.深度学习的算法准确率高,误报率低,但是当网络流量过大时会影响检测时间,占用计算资源.本文针对上述研究方法中出现的问题,提出了一种基于信息熵与深度学习的检测模型.该模型综合以前的基于信息熵的检测方法和机器学习检测方法,利用信息熵的方法对流量进行初步检测,再利用DNN对疑似问题流量进行精度检测.该方法与传统的基于信息熵和基于机器学习的方法相比具有更高的检测准确率、更低的误报率以及更高的检测效率.
2 DDoS攻击检测模型
2.1 攻击检测总体架构
本文的检测模型部署在SDN网络中的控制器中,该模型包括2个主要部分:基于信息熵的异常初检模块和基于DNN的DDoS流量检测模块,如图1所示:
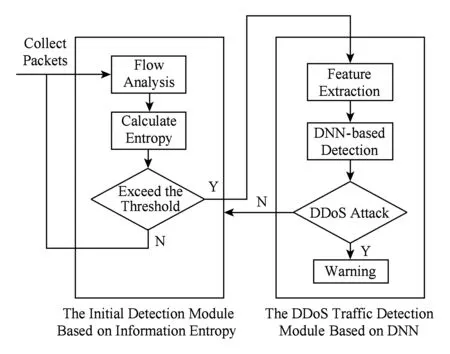
Fig. 1 Detection model structure based on information entropy and DNN图1 基于信息熵与DNN的检测模型结构
在SDN网络中,每当交换机收到一个新的数据包,控制器就会更新该交换机的流表项,当SDN网络遭到攻击时,控制器会收到来自交换机大量的数据包,致使控制器中断服务,网络瘫痪.异常初检模块通过收集SDN控制器中packet_in数据包,计算固定间隔数据包窗口数内数据特征的熵值,并与设定的阈值进行对比,一旦不在正常范围内,则认定该流量为疑似异常流量,将所有流量进行基于DNN的异常检测.基于DNN的DDoS流量检测模块通过交换机流表项提取所需特征,进行进一步的检测,以确认网络中是否发生DDoS攻击,如果发生攻击则发出警告,通知网络管理人员做进一步的处理.
2.2 基于信息熵的异常初检模块
熵(entropy)也被称作信息熵,是反映随机变量取值不确定性的程度.当随机变量取值越是随机时,信息熵值就越高,当随机变量取值越一致时,信息熵值就越低[27].
我们用香农公式来计算样本熵值:
(1)
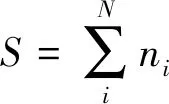
由于网络流量的自相似性,我们考量数据包特征样本的稀疏与密集程度只与样本的个数有关,熵值的大小只由样本数据的异同情况决定,例如2个相同数目的样本序列X和Y,X是一个在30 s内收集的样本序列,Y是一个在45 s内收集的样本序列,但是2个样本序列的熵值相同,那么我们就认为X和Y具有相同的分布稀疏程度[28].
在实验中,将SDN控制器的packet_in数据包作为单元数据包.我们定义固定的包数间隔为一个包单元数据包(packetbin),即把连续的数据包按特定包数划分成一个个包单元(bin).我们用packetbin中的某些特征序列值作为样本数据,并计算该特征序列样本数据的熵值.我们选取了能够反映当前网络状态的2个最主要特征:源IP地址和目的IP地址.每个packetbin中包数W大小的选择控制着样本特征在短时间内的变化情况,如果W值过大会导致熵值变化不明显从而降低检测的准确度.原则上,W的选择与实验网络的负载相关,在本实验环境的SDN网络里,根据主机数目与流量情况,经过测量分析,发现W=100时对于我们所用的数据是一个很好的折中.在计算熵时,也就是式(1)中的S=W=100,我们计算第1个连续的W个数据包中源IP地址和目的IP地址的信息熵值,然后移动到下一个相邻的W个包计算相应的熵值.我们得到一个基于信息熵异常流量分析指标,如表1所示:
Table 1 Abnormal Flow Analysis Index Based on Information Entropy

表1 基于信息熵的异常流量分析指标
我们设定了实验阈值T,如果当指标中的信息熵不在阈值范围内时,我们则认为SDN网络中发生了某些异常,发出警告,并将此刻开始启动基于深度学习的DDoS流量检测模块对SDN网络中的流量进行检测,发现DDoS攻击并发出警告.与其他的基于熵的方法不同,我们并不设置置信区间,因为我们并不将其作为判断网络中是否发生DDoS的标准,只是将其作为初检方法,因为单纯的基于熵值的检测方法具有局限性,如阈值如何确定会影响整个算法的准确度,这种方法往往会造成较高的误报率.在我们的初检模型里,阈值被设定为一个较为宽泛的范围,该方法具有较高的检测识别率,但是却具有较高的误报率,作为初检方法,只要求其具有较高的识别率.
基于信息熵的异常初检模块对网络中的流量进行了异常初检,将产生的疑似异常流量输入到深度学习模块进行进一步的处理,这样既完成了异常流量的检测,也减缓了深度学习模块所需要资源的压力.
2.3 特征的提取与构建
传统的机器学习算法里,如何选取特征会影响整个算法的成功与否.选择好的特征能够提升算法的准确率.但是过多的特征设计会增加算法的复杂度,人工筛选特征的过程会影响模型的检测速度.DNN模型能够自动逐层提取特征,对提取的特征进行权值分配,以达到最好的效果.
在实验的DNN模型里,我们直接提取了OpenFlow流表中的部分字段作为第1层的特征输入.除了在流表中能够直接提取的特征外,我们手动设计了2个特征,这些特征同样作为深度学习网络的输入.深度学习模型的输入特征如表2所示.
我们手动提取的2个特征是平均数据分组数和平均数据分组位数.其中,平均数据分组数n_packets_ave是分组的包数(n_packets)除以流持续时间(duration),即每秒数据分组包数:
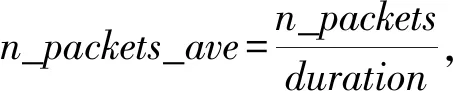
(2)
平均数据分组位数(n_bytes_ave)是分组的位数(n_bytes)除以流持续时间(duration),即每秒数据分组位数:
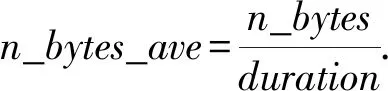
(3)
综上所述,我们根据流表信息构造了深度学习检测模型的19维的特征输入,这些特征都可在流表项中直接读取,其中手动构建的特征也较易获得.我们将这19维特征向量都作为深度学习检测模型的输入,以识别DDoS异常流量.

Table 2 DNN Feature Description表2 DNN模型输入特征
2.4 DNN检测模型
深度神经网络DNN是指深度神经网络算法,是一个包括一个输入层、多个隐含层以及一个输出层的全连接深度神经网络[29].图2描述了一个具有5维向量输入、7维向量输出并具有L-1层隐含层的DNN网络模型.

Fig. 2 A DNN model with 5 inputs and 7 outputs图2 DNN模型图
在DNN网络中,每一层都包含了权重向量W和偏移矢量b,我们计算第h层的输出lh,
lh=tanh(bh+whlh-1),
(4)
其中,bh是偏移矢量,wh是权重矩阵,非线性函数我们使用的是tanh函数.顶层输出lμ与监督的目标输出y组合成损失函数ω(lμ,y).输出层的线性回归函数为
(5)


(6)
其在(x,y)对上的期望值最小化.训练时,利用反向传播(back propagation)算法与梯度下降(gradient descent)算法,根据每个神经元的输出误差值,对权重值和偏移量进行调整.当代价函数输出最小时,达到最佳结果.
输出函数选择softmax函数并定义交叉熵误差函数:
(7)
其中,N为单元数量.通过从w得到相对于每个权重wk的代价函数F(w)来获得F(w)的梯度,其定义为

(8)
即
wh+1=wh-τhθh,
(9)
其中,τh称为学习效率[30].最后,根据式(7)~(9),使用相应的随机梯度下降算法使得代价函数最小化,最后我们将得到最佳的权重值.
实验使用了包括输入层、输出层和10个隐藏层的DNN结构,在隐含层使用双曲正切tanh函数进行非线性处理,在输出层进行现行激活,经过多批次的梯度下降训练,得到最后的检测模型.
3 实验结果及分析
3.1 实验环境设置及评估指标
本文利用mininet构建了一个SDN网络,其中控制器使用了基于JAVA的开源控制器Floodlight,操作系统为Ubuntu16.04.其中深度学习模块是基于Tensorflow框架进行开发.开发的硬件环境是48核的CPU服务器,操作系统环境为Ubuntu16.04.实验前,我们利用scapy工具向mininet虚拟网络中注入流量,模仿DDoS攻击.Mininet创建的网络拓扑如图3所示.SDN网络由10台交换机组成,每台交换机连接10台主机,选取其中2台主机作为DDoS攻击源,向SDN网络发起攻击.
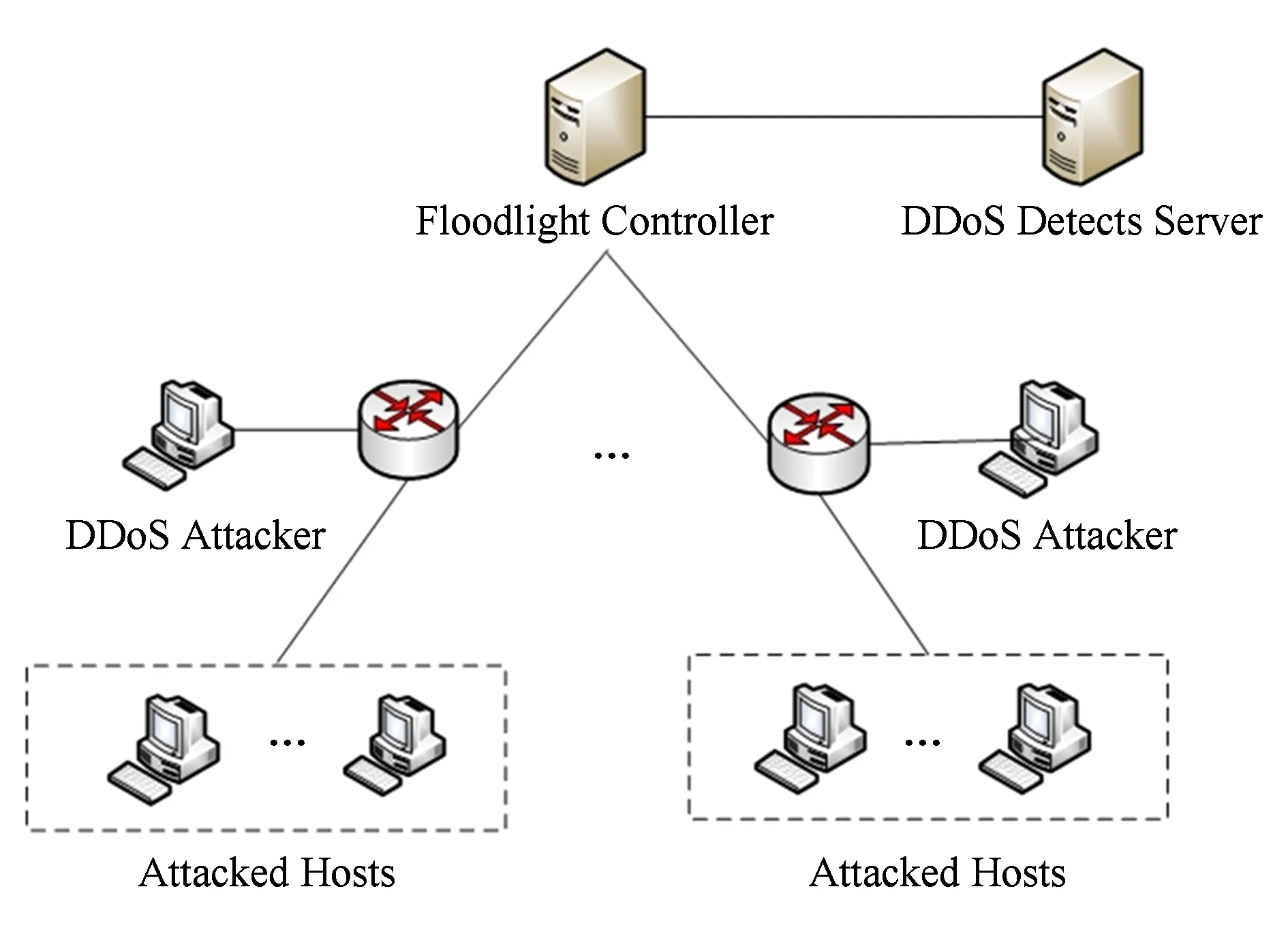
Fig. 3 Experimental Topology图3 实验拓扑结构
实验通过识别率(detection rate,DR)、准确率(accuracy,ACC)和误报率(false alarm rate,FAR)三个指标作为评估模型的标准.
识别率(DR)是被正确识别出的DDoS攻击流量与样本中所有DDoS攻击流量的比率:
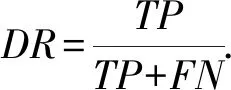
(10)
准确率(ACC)是正确识别正常流和异常流占总数据集的比率:
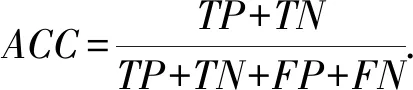
(11)
误报率(FAR)是指被模型误识别为DDoS攻击流量的正常流量与测试集中所有正常流量的比率.误报率越低代表模型的分类效果越好:

(12)
其中,真正率(true positive,TP)指DDoS异常流量流量被模型识别出的比率,真负率(false positive,FP)指正常流量被错误识别为DDoS流量的比率;假正率(true negative,TN)指正常流量被正确识别的比率;假负率(false negative,FN)指DDoS流量被错误识别为正常流量的比率[31].
3.2 基于信息熵的异常初检模块实验结果分析
在基于信息熵的异常初检模块中,我们提出了基于信息熵的异常流量分析指标,通过计算每个特征向量在若干个窗口内的熵值,根据熵值是否超过阈值来判断网络中是否发生了异常.首先采集交换机中正常网络流量的packet-in数据包,读取数据包中源IP地址、目的IP地址,再计算每个窗口即100个数据包内的特征熵值.SDN网络受到DDoS攻击时,收集10万条数据流量,解析源IP地址与目的IP地址,并求出信息熵值.对比如图4、图5所示:

Fig. 4 Comparison of source IP address entropy of normal traffic and DDoS traffic图4 正常流量以及DDoS异常流量源IP地址信息熵的变化

Fig. 5 Comparison of destination IP address entropy of normal traffic and DDoS traffic图5 正常流量以及DDoS异常流量目的IP地址信息熵的变化
由图4、图5可以看出,当SDN网络中发生DDoS攻击时,特征信息熵值出现了明显的变化,特征向量值都有明显的下降,并且变化范围小.基于信息熵的初检模块目的是能够识别网络中的异常流量,因此一定要有很高的识别率,但是由于只是初检模块,所以并不要求它有很低的误报率.根据以上原则,分析实验数据,我们得出了特征熵值的阈值,如表3所示:

Table 3 Threshold Entropy表3 特征熵值阈值
由实验数据分析可知,当源IP地址信息熵值阈值设定为2.519 2时,异常流量识别的识别率为100%,误报率为42.769%;当目的IP地址信息熵阈值设为2.555 7时,异常流量识别识别率为100%,误报率为39.231%.当2个特征熵值之一超过规定阈值时,我们则认为网络中发生了异常.
为了证明阈值的有效性,我们再次模拟DDoS攻击并采集数据,做标记以区别正常流量与异常流量.将正常流量与异常流量混合,进行基于信息熵的异常检测.如果当某一特征的信息熵值低于阈值,则标记为异常流量,最后将标记结果与初始标签作对比,计算算法的识别率与误报率.实验结果如表4所示:
Table 4Recognition Rate and False Alarm Rate Based onEntropy Anomaly Detection Algorithm
表4 基于信息熵异常检测算法的识别率与误报率%
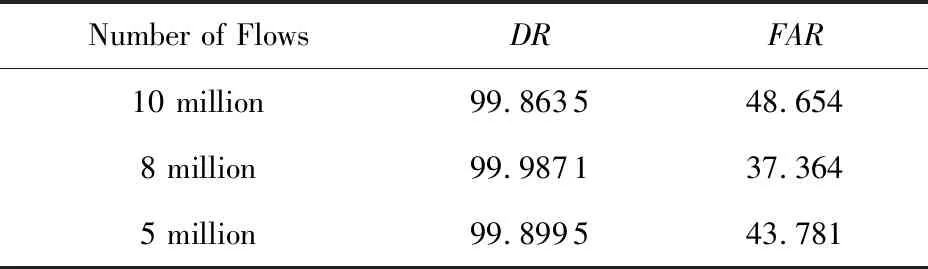
由实验结果可知,基于信息熵的异常流量检测方法具有极高的识别率,证明该方法能够有效地识别DDoS攻击流量,虽然其具有较高的误报率,但是这并不影响其作为初检方法的有效性.
3.3 DNN模型实验结果分析
实验的数据集是我们采集的SDN网络中的真实流量.我们总共采集了12万条流量数据,其中正常流量7万条,DDoS攻击流量5万条.其中将79 970条数据作为训练数据集,40 030条数据作为测试集.如表5所示:

Table 5 Description of the Dataset表5 流特征数据集
DNN模型的隐含层数的选择会影响模型对DDoS流量识别的准确率.选择具有多少层的DNN作为检测模型是十分关键的.因此,我们分别构建了隐含层数分别为5层、10层、20层、50层和100层这5种DNN模型.在实验中,我们采用相同的数据集对这5种DNN模型分别进行1 000次的迭代实验,通过准确率(ACC)来评估每个模型的性能.表6显示了5种不同结构的DNN模型在相同的训练集下训练1 000轮后,使用相同测试集测试后的结果对比.

Table 6 Accuracy Rate of DNN Models with Different Structures表6 不同结构DNN模型的识别准确率
由表6结果可知,DNN模型并非层数越多训练结果越好,过多的隐藏层数甚至会造成识别结果准确率的下降.因此实验模型选择10层的DNN模型.
使用我们采集的实际流量数据集,分别与文献[24]中的XGBoost模型和文献[25]中的SVM模型进行对比实验,同时进行对比的还有传统机器学习算法K-近邻(KNN)模型.结果如表7所示.
从表7可以看出,本文实验使用的DNN模型在检测率、准确率和误报率的指标上均好于传统的机器学习检测方法,并且DNN深度模型的检测准确率可达到97.87%,并且误报率有明显的下降.从实验结果可以看出,我们提出的基于深度学习的DDoS流量检测模型优于传统的机器学习所构造的模型.
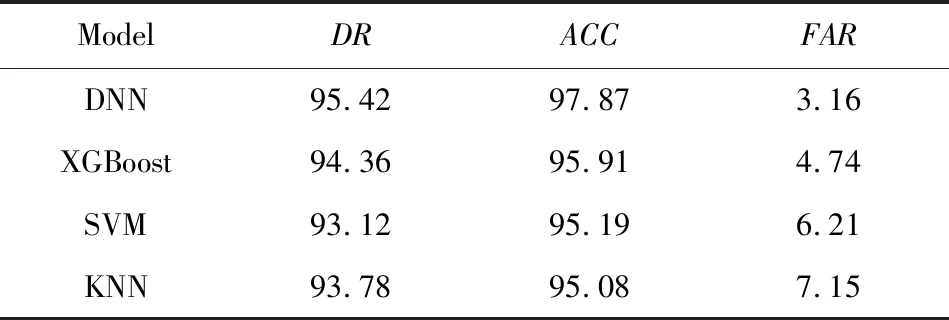
Table 7 Performance Evaluations Comparison of Other Models and DNN Models表7 不同机器学习模型与DNN模型的评估指标 %
同时,我们进行了2组对比实验,利用实验数据集使用DNN模型进行DDoS流量的检测.第1组实验直接使用OpenFlow字段直接提取的17个特征字段作为模型输入;第2组实验除了直接提取17个特征字段外,实时手动构建2个特征“平均数据分组数”和“平均数据分组比特数”,将这19个特征作为模型输入,同时计算2个不同流量特征输入下的异常流量准确率与耗时.结果如表8所示:
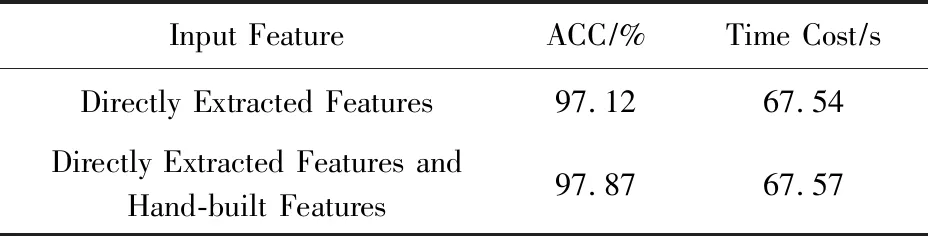
Table 8 Comparison of Accuracy Rate and Time Cost of DNN Detection Model with Different Input Features表8 不同输入下DNN检测模型的准确率与耗时对比
由表8可知,加入了2个手动构建的特征后,模型识别的准确率上升了0.75%,而模型耗时只增加了0.03 s.由此证明了手动构造特征的有效性.
此外,我们还进行了2次对比试验,对相同的流量数据,第1次只使用基于深度学习的检测模块对流量进行检测,而第2次试验利用基于信息熵的初检模块进行初检和基于深度学习的检测模块进行检测.结果如表9所示:

Table 9 Comparison of Two Structures With and Without Entropy表9 是否具有信息熵初检模块的影响对比
从检测准确率看出,2种方法对于异常流量识别都具有较高的准确率,都达到了97%以上,都具有良好的识别效果.但是基于信息熵和深度学习的检测方法节省了CPU使用率,并且减少了处理时间.基于信息熵的初检方法属于轻量级的计算,其对计算资源的占用率并不高,而且具有更快的处理速度.
通过调整DNN层数、手动设计输入特征等手段,得到了适用于该实验环境最佳的DNN检测模型.同时,与之前的研究方法进行了对比试验,结果表明:基于信息熵和深度学习的检测模型对于识别流量中的DDoS流量具有很高的准确率,更少地占用计算资源和更快的处理速度.
4 结束语
本文提出了一种基于信息熵与DNN的DDoS攻击检测模型,并提出了用于计算信息熵的异常流量分析指标和用于DNN模型的19维流量表特征向量.基于信息熵的初检模型能够有效地识别异常流量,DNN检测模块对流量进行确认.该模型不仅解决了基于信息熵的检测方法精度不高的问题,还缓解了深度学习方法检测时间长、占用计算资源等问题.实验表明,该方法能够有效识别DDoS异常流量,为网络管理员提供有效的信息,为SDN的网络安全提供了有效的保障.
猜你喜欢
军民两用技术与产品(2022年1期)2022-06-01
计算机与数字工程(2022年3期)2022-04-07
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
民用飞机设计与研究(2020年4期)2021-01-21
健康体检与管理(2021年10期)2021-01-03
物联网技术(2018年8期)2018-12-06
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
中国水运(2016年11期)2017-01-04
