
有条件生成对抗网络的IVUS图像内膜与中-外膜边界检测
2019-05-14 01:19袁绍锋吴洋洋刘娅琴
中国生物医学工程学报 2019年2期
袁绍锋 杨 丰* 徐 琳 吴洋洋 黄 靖 刘娅琴
1(南方医科大学生物医学工程学院,广州 510515)2(南方医科大学广东省医学图像处理重点实验室,广州 510515)3(中国人民解放军南部战区总医院(原广州军区广州总医院)心血管内科,广州 510010)
引言
在冠心病的病变评估和介入治疗中,血管内超声(intravascular ultrasound, IVUS)技术已成为必不可少的影像学方法[1]。在IVUS图像中,内膜(lumen, LU)和中-外膜(media-adventitia, MA)边界检测以及动脉粥样硬化斑块分割与识别,对于准确评估冠脉造影难以判断的病变和冠心病介入治疗至关重要[1-2]。临床上,IVUS图像内膜和中-外膜边界检测需要操作者具有完备的知识储备和大量的临床实践。肉眼识别IVUS图像关键边界具有个人主观性、易受图像伪影和干扰因素影响,分析几帧至百帧图像费力耗时,并难以呈现重复结果。在这种情况下,自动识别和检测IVUS图像内膜和中-外膜边界可以有效地克服临床医生之间或之内的主观性误差,抑制图像伪影和干扰影响,同时减少医生诊疗时间[2]。因此,研究自动内膜与中-外膜边界检测技术对临床诊断和治疗冠心病有着重大意义。
大多数现有算法可分成3类。第1种是基于直接检测的方法,其主要利用底层特征,如Haar、DoG等,包括启发式图搜索[3]、活动轮廓[4]和图割模型[5]。在IVUS图像中,斑块钙化灶的存在大大影响这类算法的检测精度[3]。第2种是基于统计和概率的方法[6-7]。这些方法首先对内膜或中-外膜的形状、感兴趣区域进行建模,然后利用最小化能量函数(统计法)或者最大化像素隶属区域概率(概率法)获得最佳边界的轮廓形变曲线。然而IVUS图像中的超声阴影、血管分叉、纤维斑块等因素往往破坏这类算法的假设,使得演变轮廓陷入局部最小值,造成内膜或中-外膜的边界存在较大的突起或凹陷。第3种是基于机器学习的方法,其主要包括人工设计特征提取和分类器优化2个步骤。这类方法包括支持向量机(SVM)[7],AdaBoost[8],纠错输出编码(ECOC)[9]和使用手工特征的浅层人工神经网络(ANN)[10]。虽然这些方法取得了较大成功,但是仅仅使用较底层的手工设计特征,算法的检测精度往往受干扰因素的影响。另外,特征提取过程复杂繁琐,导致其在临床实践中泛化能力较差、适用性较低。
与上述依赖人工设计特征的方法不同,深度卷积网络(deep convolutional networks, DCN)[11-14],特别是全卷积网络(fully convolutional networks, FCN)[15]及其一系列改进框架[16-17],已广泛用于各类医学图像的组织分割、病灶检测、图像增强与生成等研究和应用中[18]。DCN的主要优点是从给定训练数据集中,端到端地自动学习相应任务所需的分层性和区别性特征表达。堆叠沙漏网络(stacked hourglass networks, SHGN)[19]通过堆叠多个FCN学习图像特征,其中上一级网络的输入图像或中间特征将结合其输出结果,作为下一级网络的输入,继续进一步学习,逐渐优化区域分割。本研究构造适用于IVUS图像边界检测的SHGN分割器,堆叠两个FCN,分别模拟检测任务中“区域分割”和“边界优化”两个过程[2]。虽然DCN在许多应用中往往能达到较好的性能,但是其训练过程需要大量的标注样本数据。在医学图像处理中,通常缺乏具有标注信息的数据资源。除了利用迁移学习方法缓解数据匮乏问题[20],还可通过有条件生成对抗网络(conditional generative adversarial networks, C-GAN)[21-22]的对抗学习,为网络优化过程提供具有正则化作用的对抗损失,减少所需标注样本数据的数量,使得图像分割网络有着较好的泛化能力[23]。
本研究提出一种结合堆叠沙漏网络SHGN和有条件生成对抗网络C-GAN的IVUS图像内膜和中-外膜边界检测方法C-ivusGAN-SHGN。首先采用有效的数据扩充方法,增加训练数据集中IVUS图像的样本量;然后训练C-ivusGAN-SHGN, 将IVUS图像分割为3种不同区域:血管外周组织、斑块区域和内腔区域;最后利用阈值处理方法,检测IVUS图像内膜和中-外膜边界。本文研究采用现有的国际标准IVUS图像数据集(10位病人435幅),计算面积交并比(Jaccard measure, JM)、面积差异百分比(percentage of area difference, PAD)、Hausdorff 距离(Hausdorff distance, HD)和平均距离(average distance, AD)指标分数,对所提出方法进行定量分析,证明其性能优于现有、近年较好的8种算法[24]和基于堆叠稀疏自编码器的深度学习算法[10],以及Pix2Pix模型[25]。
1 方法
本研究算法流程如图1所示,其主要过程包括:
1) 图像数据扩充。将用于网络训练的IVUS图像数据及其对应的临床医生手动标注信息进行数据扩充,目的缓解C-ivusGAN-SHGN训练阶段时生成器和判别器的学习过拟合问题。
2) 组织区域分割。利用经过对抗学习的C-ivusGAN-SHGN模型,将测试待分割IVUS图像划分为3种不同组织区域:血管外周组织、斑块区域和内腔区域。
3) 中-外膜MA和内膜LU边界检测。在C-ivusGAN-SHGN分割结果上,采用阈值处理,获取内膜与中-外膜边界。在图1中,实线箭头表示训练阶段,虚线箭头表示测试阶段。

图1 本算法框图Fig.1 The flowchart of the algorithm in this paper
1.1 IVUS图像数据扩充
为了降低过拟合的影响,首先对IVUS图像进行数据扩充。采用的数据扩充方法[26]如下:
1) 旋转变换。将IVUS图像及其对应标注信息朝逆时针方向每隔10°旋转一次,旋转35次后获得35倍增量数据。
2) Gamma变换。将IVUS图像进行灰度拉伸,Gamma因子取值范围是{0.5, 0.6, 0.7, 0.8, 0.9, 1.1, 1.2, 1.3, 1.4, 1.5},可获得10倍数据。
3) 翻转处理。将IVUS图像和标注信息进行上下和左右镜像翻转操作,可获得2倍数据。
4) 尺度变换。将IVUS图像首先进行缩放处理,然后进行零值填充以恢复到原始空间大小,缩放因子取值范围是{0.50, 0.55, 0.60, 0.65, 0.70, 0.75, 0.80, 0.85, 0.90, 0.95},可获得10倍数据。因此,进行IVUS图像数据扩充,可增加57倍数据量。
上述4种扩充方法由Matlab的相关内置函数实现。
1.2 IVUS图像区域定义
为了准确地描述IVUS图像内容,根据血管组织解剖结构以及成像特点,将IVUS图像分为3个主要区域,如图2所示。图2(a)为IVUS图像,图2(b)中黑色区域定义为血管外周组织;灰色区域定义为斑块区域,即各种易损斑块存在的区域,其边界为中-外膜MA;白色区域定义为内腔区域,即血液流动的区域,其边界为内膜LU。

图2 IVUS区域定义。(a) IVUS图像;(b) 区域定义Fig.2 The region definition of IVUS image. (a) IVUS image; (b) Region definition
1.3 C-ivusGAN-SHGN网络框架
目前,基于学习的两种生成模型分别是变分自编码器(variational autoencoder, VAE)[27]和生成对抗网络(generative adversarial networks, GAN)[21],其广泛用于图像生成。前者由用户指定图像的概率密度函数,具有显式的分布;后者适用于不具备显式函数分布的图像数据。GAN由生成器和判别器两个网络构成。生成器用于生成逼真的自然或医学图像数据,包括组织分割的图像;而判别器通过目标函数鉴别所生成图像是否逼近真实数据,改善生成图像的质量。早期GAN模型为无条件型,即将从某概率分布中采样获得的随机噪声(用于生成图像)和从给定真实图像数据集中抽取的某一样本作为网络输入。通过对抗训练,网络可拟合给定真实图像数据集的分布,训练好的生成器从而生成逼真的图像样本。为了稳定GAN的训练和生成图像的效果,人们提出可用深度卷积网络DCN[11-14]替代多层感知器,设计深度卷积生成对抗网络(deep convolutional generative adversarial networks, DCGAN)[28]。但是文献[22]指出,无条件型GAN难以控制生成数据风格,需要引入额外信息即条件信息,由用户去控制数据生成过程。这些条件信息可以是类别标签、文本或者部分图像内容,甚至是其他模态数据。
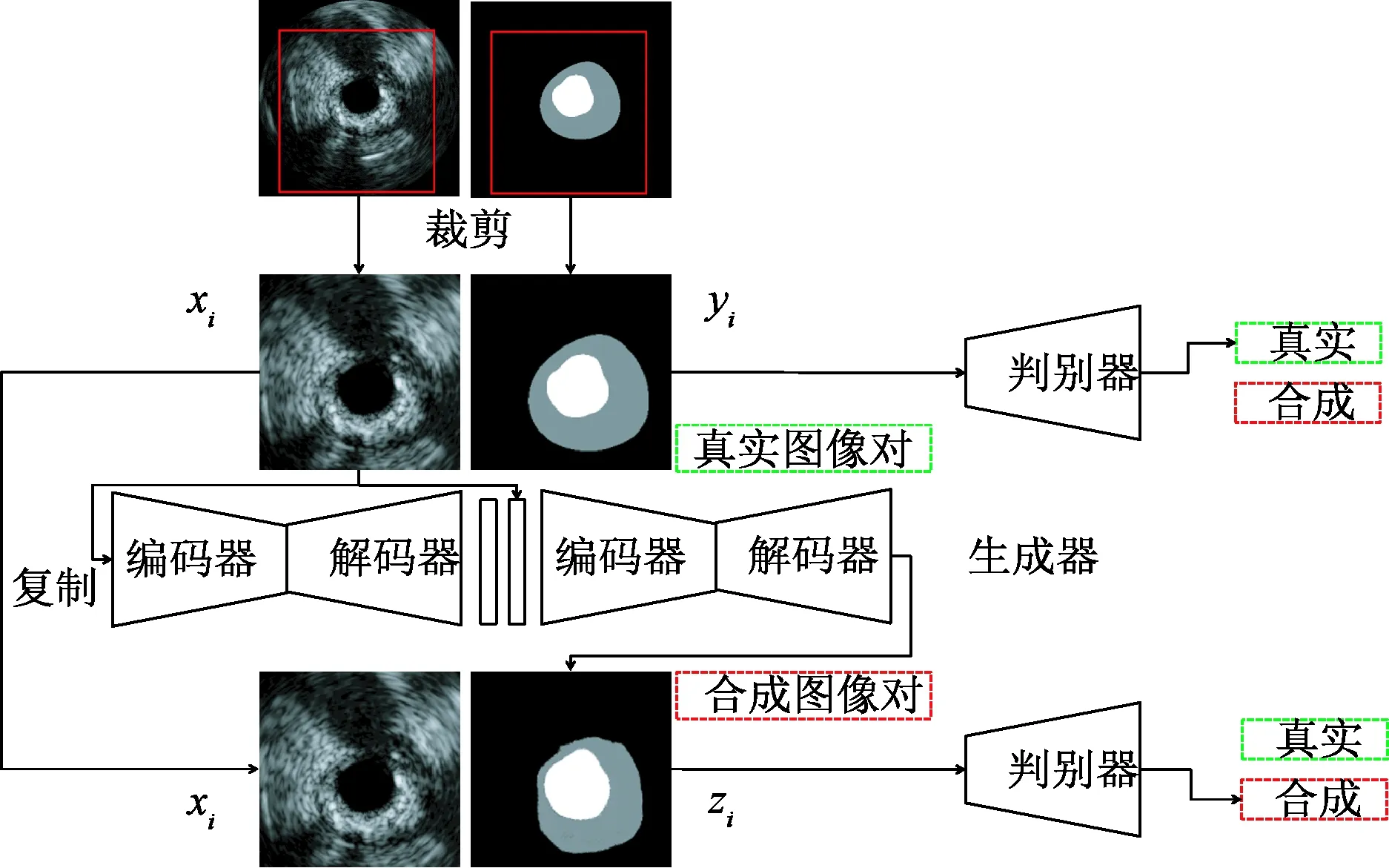
图3 C-ivusGAN-SHGN的结构Fig.3 The architecture of C-ivusGAN-SHGN
总之,无条件GAN学习过程寻找随机噪声向量n与输出图像y之间的映射关系,即f∶n→y;而有条件GAN学习过程则是随机向量n、观测输入图像x(或者附加条件)与输出图像y之间的关系,即f∶(x,n)→y。针对IVUS图像边界检测任务,本研究提出一种适用于IVUS边界分割的有条件GAN模型,简称C-ivusGAN-SHGN,如图3所示。
首先,从训练数据集{xi,yi},i=1, 2,…,N中随机抽取图像对,经裁剪采样得到IVUS图像xi以及其分割图yi,再输入到C-ivusGAN-SHGN的生成器中;接着,生成器以IVUS图像xi为条件信息,生成分割图zi;然后,图像对(xi,yi)和(xi,zi)被送入C-ivusGAN-SHGN的判别器中,由判别器鉴别生成器的分割效果是否接近医生手动分割。上述有条件GAN的目标函数定义为
LC~GANG,D=Ex,y~pdatax,ylogDx,y+
Ex~pdataxlog1-Dx,Gx
(1)
式中,分割生成器会最小化目标函数,而对抗判别器将最大化目标函数。
有条件GAN的目标函数可引入重建损失函数,L1距离[25]或L2距离[29],其将约束生成器产生准确的分割结果zi。重建损失函数定义为
LLp(G)=Ex,y~pdatax,y‖y-Gx‖p
(2)
式中,p=1表示L1距离,而p=2表示L2距离。
结合式(1)和(2),在C-ivusGAN-SHGN模型的学习过程中,总的损失函数改写为
Ltotal=αLcGAN+βLLp
(3)
式中,a、b为超参数。在实际应用中,a超参数一般设置为1,b超参数由网格搜索法来确定。
1.4 C-ivusGAN-SHGN的生成器
生成器/分割器是上述C-ivusGAN-SHGN网络框架的重要组成部分。在IVUS图像边界检测中,生成器扮演着分割目标区域的角色。受经典深度卷积网络SHGN[19]、DCGAN[28]、视觉几何小组网络(visual geometry group networks, VGG-Net)[12]启发,本研究构造一种适用于IVUS图像边界检测的分割图生成器,如图4所示。在SHGN的设计思想上,该生成器考虑了DCGAN在生成对抗网络中的设计技巧,以及VGG-Net在深度分类网络中的设计特点。下面分别简述SHGN、DCGAN、VGG-Net的特点。
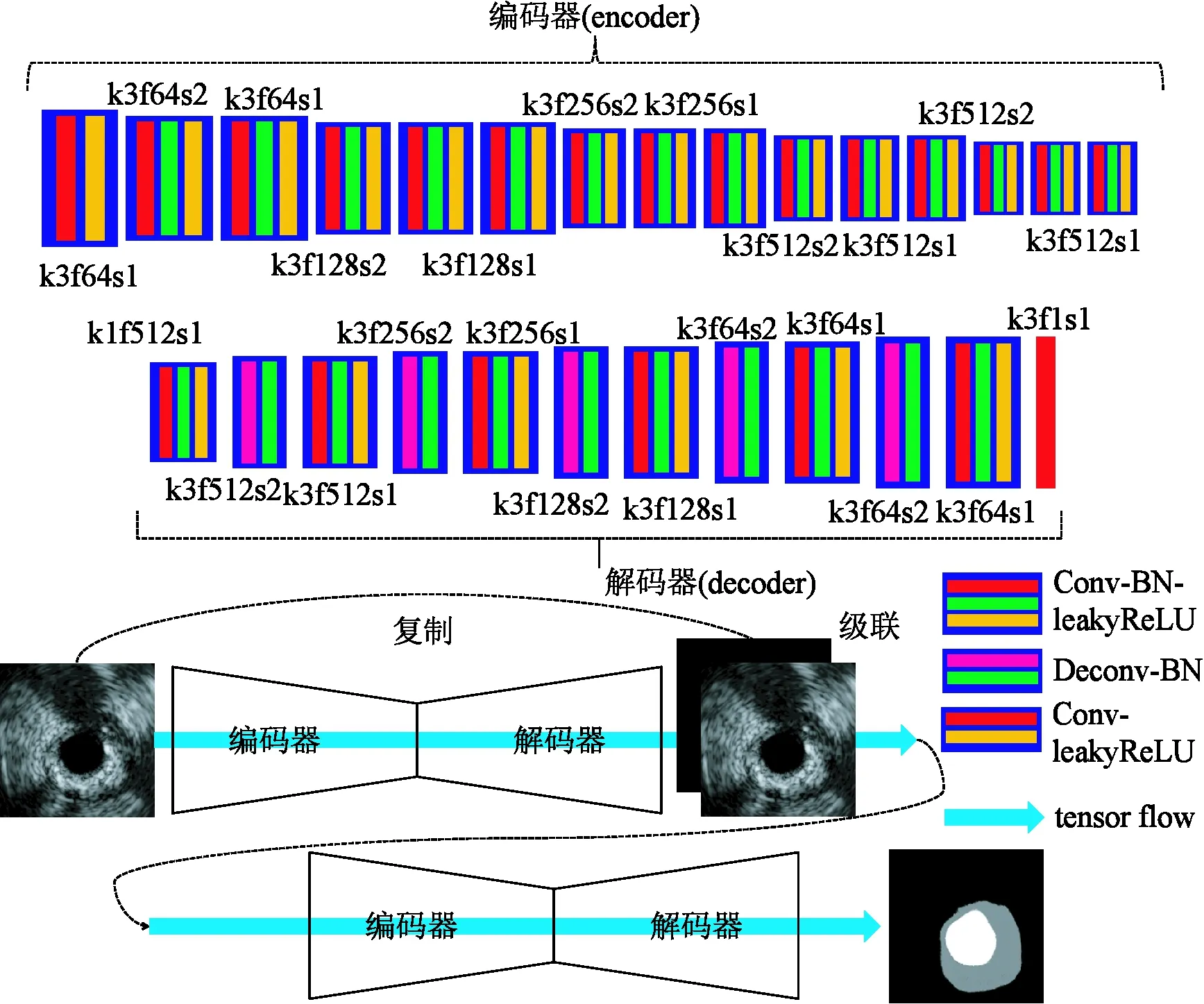
图4 生成器的结构Fig.4 The architecture of generator
首先,本研究所提出的网络基于SHGN的级联思想,即采用两级堆叠全卷积编码-解码网络[30],分别模拟IVUS图像边界检测中“区域分割”和“边界优化”两个过程。与本研究基于SHGN的级联思想类似,文献[31]通过堆叠反卷积网络DeconvNet,进行街景图像分割,文献[32]直接将基于ResNet[14]的SHGN应用于高分辨率航空图像分割,文献[33-34]分别通过堆叠U-Net[35]和FCN[15],对磁共振和超声图像进行分割。本研究的SHGN通过堆叠沙漏网络学习IVUS图像特征,并将输入IVUS图像或特征引入到下一级网络的学习,优化区域分割。在图4中,沙漏网络指全卷积编码-解码网络[30],由1个编码器和1个解码器构成。编码器主要完成深度特征学习过程,其中第1个模块采用Conv-leakyReLU组合,剩余14个模块采用Conv-BN-leakyReLU组合。Conv-leakyReLU模块适用于与输入图像直接连接的情况,而Conv-BN-leakyReLU模块适用于不与输入图像直接连接的情况。卷积层(convolution, Conv)用于提取特征;批规范化层(batch normalization, BN)使得每一模块中的卷积特征尽可能保持在同一分布(均值为0,方差为1)中;泄露矫正线性单元(leaky rectified linear unit, leakyReLU)则为网络提供非线性,使得网络可模拟任意复杂的函数。每3个模块组成一个滤波器组,采用了VGG-Net的设计特点。每1个滤波器组具有相同数量的卷积核,如第1个滤波器组的卷积核数量为64,第2个滤波器组的卷积核数量为128,以此类推。解码器主要完成区域形状恢复过程,其中除了最后一层仅采用1层卷积Conv输出分割图之外,由Conv-BN-leakyReLU和Deconv-BN两种模块组成。Deconv-BN模块对特征图进行2倍上采样学习,反卷积层(deconvolution, Deconv)将压缩的深度特征放大2倍。其后紧跟着Conv-BN-leakyReLU模块,该模块对放大后的深度特征进行适应性调整学习。在图4中,k(kernel)表示卷积核大小,f(feature map)表示输出特征图数量,s(stride)表示卷积核之间步长,若s=1,则输入输出特征大小相等;若s=2,则经卷积后输出特征大小减半,而经反卷积后输出特征大小则加倍。
其次,本研究所构造的SHGN还考虑了DCGAN在生成对抗网络中的设计技巧。DCGAN在有效地训练深度GAN模型上提出了很多行之有效地建议。比如,在生成器中,应使用批规范化层BN和leakyReLU激活函数,应采用大步长(s=2)的卷积层Conv替换分类模型中的池化层,等等。在图4中,Conv-BN-leakyReLU模块在Conv-ReLU的基础上进行修改,其目的在于稳定深度GAN模型的训练。采用步长s=2的卷积计算,在模拟池化层降低特征图分辨率的同时,减少了下采样过程时造成的信息损失,对稳定深度GAN模型的训练起着一定作用。
最后,本研究所构造SHGN的组成模块考虑了VGG-Net在深度分类网络中的设计特点。VGG-Net使用3 × 3小卷积核,一方面为了节省显存的开销,另一方面为了抑制网络的过拟合问题。此外,VGG-Net利用滤波器组(2~3卷积层组成)替代卷积层,一方面滤波器组可实现较大的感受野,避免使用占用内存较多的单层大卷积核卷积计算;另一方面滤波器组中可使用更多的非线性激活函数,为网络提供更强的函数拟合能力。根据上述深度卷积网络的优点,本研究借鉴VGG-Net的设计,构造一种多滤波器组(5组,每组3层卷积)编码器。
1.5 C-ivusGAN-SHGN的判别器
在C-ivusGAN-SHGN网络模型中,判别器是另一个重要组成部分,其作用是为网络优化提供对抗训练,鉴别生成器产生的分割图zi和医生手工分割图yi,促使生成器生成准确的分割图。采用与AlexNet[11]和DCGAN[28]类似的网络构架,判别器结构由8个卷积层Conv、7个leakyReLU层、6个批规范化层BN和1个Sigmoid层组成,如图5所示。以原始图像、真实分割图或生成分割图为级联体作为判别器输入数据,判别器将数据维数[256, 256, 2]压缩编码成[4, 4, 1],再经过Sigmoid映射为概率向量。在Pix2Pix[25]模型的判别器基础之上,本研究加深判别器的网络深度。将判别器由PatchGAN修改为ImageGAN的原因:一是在C-ivusGAN-SHGN中使用了更复杂更深层的生成器;二是不同于自然图像生成中要求图像含有丰富的色彩、纹理等方面的逼真性和多样性,IVUS图像的语义标签图像生成要求图像在全局上应与临床医生手动勾画的分割图像尽可能相似。
1.6 C-ivusGAN-SHGN的训练
本研究的相关实验在TensorFlow机器智能开源软件框架[36]上实现。网络优化算法采用Adam优化器[37]。网络超参数设为:总训练轮数epoch为200,其中本文第2.3节的epoch设置为20,批量大小batchsize为1,原始图像大小为384像素×384像素,裁剪图像大小cropsize为256像素×256像素。在Adam优化器中,学习率设定为0.000 2,b1动量超参数设定为0.5。在式(3)中,a超参数设置为1,b超参数设置为100。在编码器、解码器和判别器中,所有leakyReLU激活函数的负斜率设为0.2。
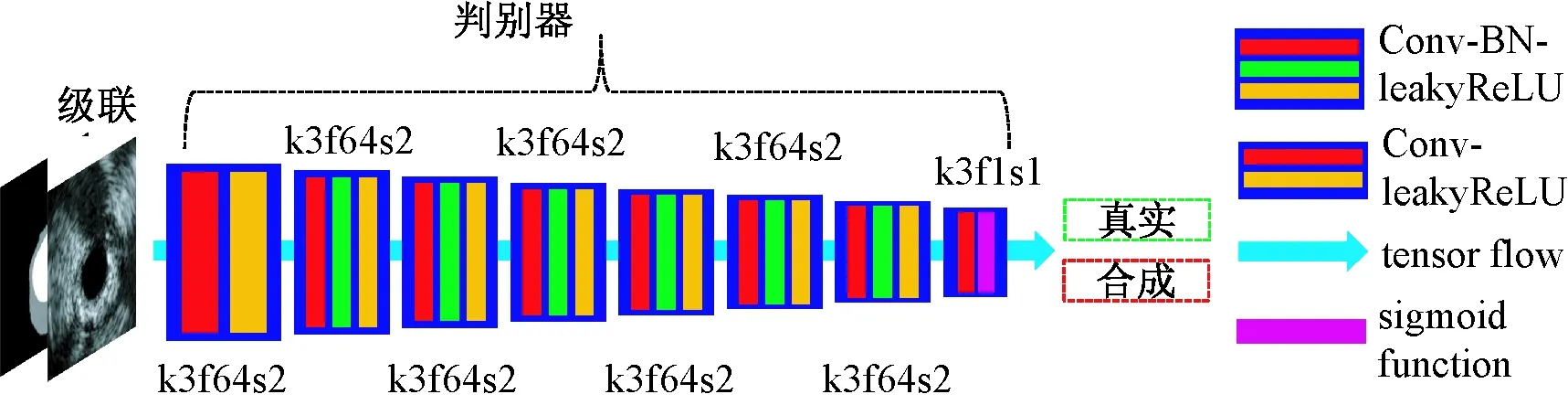
图5 判别器的结构Fig.5 The architecture of discriminator
1.7 实验材料
以Simone Balocco等所建立的国际标准IVUS数据集为主要实验对象[24]。该IVUS数据集来自10位病人冠状动脉序列的435幅图像数据,成像系统为Si5(Volcano公司),探头为20 MHz电子相控阵式。数据涵盖大多数可能出现的血管形态,比如分叉、斑块、声影、探头贴近导管等。在本文第2.1和2.2节中,训练集从数据集中随机抽取80%,剩余20%数据作为测试集,获得5组不同数据组合,用于交叉验证评估。在本文第2.3和2.4节中,为了更公平地与已有算法比较,训练集从标准数据集中随机抽取217幅IVUS图像,剩余218幅图像作为测试集。另外,从广州军区广州总医院收集100幅临床实践的IVUS图像数据,由已训练网络(生成器)完成相应的自动标注信息,其目的是验证本研究所提出网络模型的跨数据集泛化能力。实验在Ubuntu 14.04、TensorFlow 1.0.0、MATLAB R2016a上实现,采用NVIDIA GTX 1080 (8G VRAM) 显卡进行加速。
1.8 评价指标
采用面积交并比指数JM、面积差异百分比PAD、Hausdorff距离HD和平均距离AD 4个评价指标,评估中-外膜和内膜边界检测性能[2,24]。这些评价指标定义为
(4)
(5)
(6)
(7)
式中,下标auto和manual分别代表算法检测和临床医生手动勾画的边界结果,R代表区域,A代表面积,C代表曲线,d(a,b)表示计算欧式距离。
2 结果
2.1 联合损失函数影响
C-ivusGAN-SHGN的联合损失函数定义为式(3),由两部分组成:一部分为重建损失,另一部分为对抗损失。文献[25]和[29]分别使用了L1和L2距离作为GAN的重建损失,让生成器的输出结果与临床医生的单次勾画结果尽可能一致。本节主要分析对抗损失式(1)和不同重建损失函数式(2)对IVUS图像区域分割的影响。
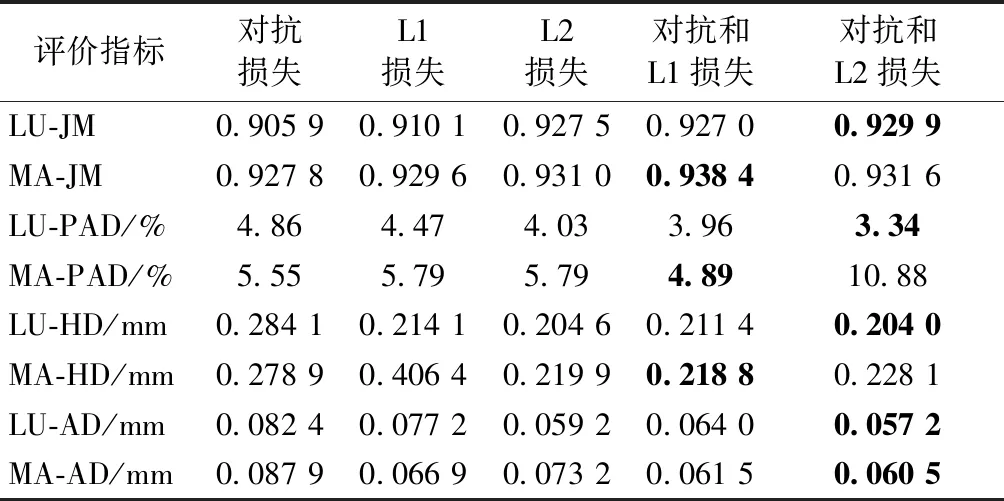
表1 生成对抗网络联合损失函数的分析Tab.1 Analysis of joint loss function in C-ivusGAN-SHGN
注:LU表示内膜边界,MA表示中-外膜边界。
Note: LU denotes Lumen and MA for Media-Adventitia.
由表1第3~6列数据比较可得,仅仅使用L1或L2重建损失,C-ivusGAN-SHGN所检测的内膜和中-外膜,计算8个评价指标均不能取得最高的分数。换言之,采用了对抗学习思想,生成器的输出分割结果会更好。这是因为,对抗损失驱使生成器的分割结果与临床医生在某一数据集上的不同勾画轮廓在分布上尽可能相似。
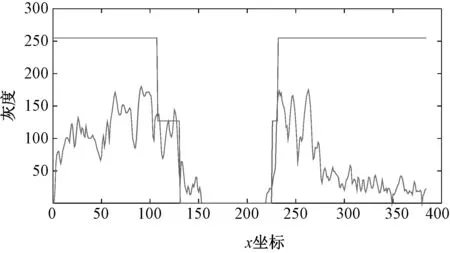
图6 内膜与中-外膜的剖面线分析Fig.6 Analysis of LU and MA border profiles in IVUS
由表1第5、6列数据比较可得,重建损失采用L1距离适合于中-外膜MA分割与检测,而采用L2距离则适合于内膜LU的分割。由L1和L2损失的性质可知,L1对异常值比较稳健,而L2则非常敏感。如图6所示,导管区域和内腔区域可视为灰度很一致的区域,因此两区域可合并成同一个区域A。采用L2损失对区域A进行分割而检测内膜,评价指标的分数取得一致较高。斑块区域与区域A在灰度上是很不一致的,如图6所示,两区域之间存在突变。如果斑块区域存在钙化斑块,则灰度值会突变得更为剧烈。将斑块区域和区域A合并为区域B,也就是把某一些异常值加入到区域B中,那么采用L1损失对区域B进行分割进而获得中-外膜,则更为适合,各个评价指标的分数会较高。
如表2所示,当超参数a=1时,超参数b由1变化到128并采用L1作为重建损失,根据统计评价指标JM,可确定超参数b的最佳值。当b=64时,C-ivusGAN-SHGN对IVUS图像中的中-外膜检测效果最好。当b=32时,C-ivusGAN-SHGN对IVUS图像中的内膜边界检测效果最好。如表3所示,当超参数a=1时,采用L2作为重建损失。当b=64时,C-ivusGAN-SHGN对IVUS图像中的内膜边界检测效果最佳。当b=128时,C-ivusGAN-SHGN对IVUS图像中的中-外膜边缘检测效果最好。综合表2、3可知,超参数b对分割结果影响不大;设置32~128之间可获得比较好的边界检测效果。本研究后面的实验统一设置b=100。
2.2 生成器网络结构影响
C-ivusGAN-SHGN对IVUS图像进行分割的结果不仅取决于所采用的损失函数,而且取决于所使用生成器的网络结构。FCN、U-Net、SegNet、DeconvNet等网络是经典的语义图像分割网络,均可作为C-ivusGAN-SHGN中的生成器。本小节研究3种不同生成器结构的分割效果,这些生成器的网络结构如图7所示,其中Pix2Pix-1的生成器采用U-Net结构[35],而Pix2Pix-2则采用Encoder-Decoder结构[30]。U-Net结构的特点主要是解码器重用编码器中的底层特征,用于准确恢复原始图像的分辨率或者生成准确的分割图像。Encoder-Decoder结构的特点是由编码器和解码器两部分组成。本研究所采用SHGN结构的主要特点:一是将Encoder-Decoder结构视为一种沙漏单元,然后堆叠这些单元构建生成器,设计思路基于“由粗到精”思想[10];二是堆叠沙漏网络可引入原始输入图像,该中间信息作为网络中沙漏单元的输入,设计思路受文献[34]启发。

表2 采用重建损失L1的影响Tab.2 Effect of L1 reconstruction loss
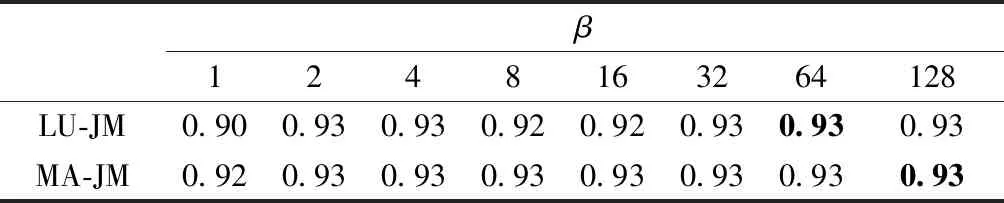
表3 采用重建损失L2的影响Tab.3 Effect of L2 reconstruction loss
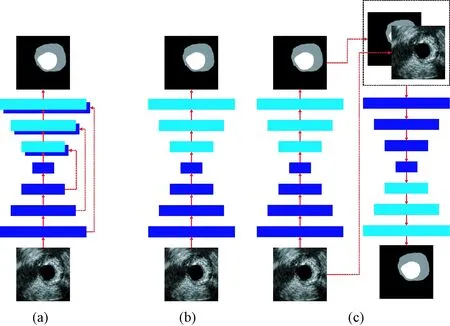
图7 C-ivusGAN-SHGN中3种不同的生成器网络结构。(a) U-Net; (b) Encoder-Decoder; (c) SHGNFig.7 Three architectures of generator in C-ivusGAN-SHGN.(a) U-Net; (b) Encoder-Decoder; (c) SHGN
表4的对比结果表明,采用Encoder-Decoder结构和没有中间信息的堆叠沙漏网络(方法1)作为C-ivusGAN-SHGN中的生成器,其分割性能均稍差于基于U-Net结构的Pix2Pix-1模型。然而,利用中间信息的堆叠沙漏网络SHGN(方法2)则优于Pix2Pix-1模型,这说明中间信息利于沙漏单元对分割图像和原始图像进行编码和解码,优化中间的分割结果,获得较好的最终分割结果。另外,所提出的堆叠沙漏网络结构更为紧凑,模型大小小于Pix2Pix-1模型。
2.3 与已有算法比较
在IVUS图像边界检测任务中,文献[24]综述了8种相关算法,并且在国际标准数据集上使用统一评价方法,对这些算法进行详细比较。在这些算法中,有一些仅能检测IVUS图像中的某一条边界,比如图8(a)中的方法6只检测中-外膜,图8(b)中的方法2、5、7无法检测中-外膜。另外,方法3的性能是最好的,是近年来较好的IVUS图像分割算法之一。在国际标准数据集435帧代表性IVUS图像上,比较所提出算法与文献[24]所述算法以及基于神经网络方法[10]的性能。图8的定量对比结果表明,本研究算法在JM、PAD、HD等3种评价指标上均优于文献[24]所述算法和基于双稀疏自编码器方法[10](内膜JM为0.919 7,中-外膜JM为0.917 1),其所检测的IVUS图像内膜和中-外膜边界更贴近临床医生勾画的标注轮廓。本算法的分割性能主要取决于两个因素,其一为先进的生成器网络结构;其二为基于IVUS图像特点的竭力数据扩充方法(训练样本量为217×58=12 586)。表4的对比结果表明,本研究所提出的C-ivusGAN-SHGN生成器网络结构好于文献[25]采用的U-Net,将输入图像作为中间信息可以提升整个网络的分割效果。图8(a)中的内膜平均JM为0.928 9,而图8(b)中的中-外膜平均JM为0.951 4,这两个指标均好于表4中的相关数据。该结果表明,采用旋转(35倍)、灰度拉伸(10倍)、翻转(2倍)、尺度变换(10倍)共57倍数据扩充方法,可有效地提升分割性能,降低过拟合的影响。
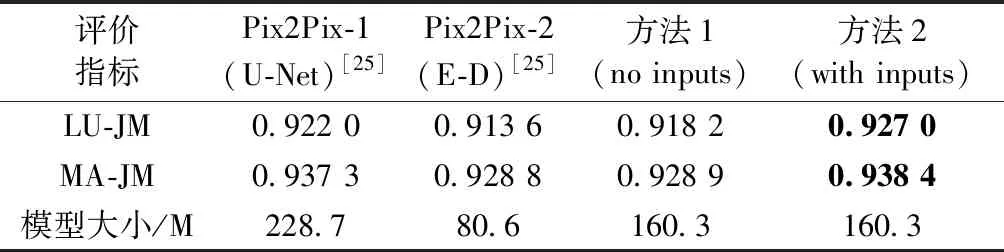
表4 不同生成器网络结构的影响Tab.4 Effect of different generator in C-ivusGAN-SHGN
注:E-D表示编码器-解码器。
Note: E-D denotes Encoder-Decoder.

图8 本研究算法与文献[24]所评价8种算法、文献[10]所提出方法的分割性能比较(1~10分别为形状驱动、测地线活动轮廓、快速步进、三维图搜索、三维堆叠序贯学习、HoliMAb、Bayesian、ANGIOCARE、双稀疏自编码器、本研究方法)。(a) 内膜分割性能比较;(b) 中-外膜分割性能比较Fig.8 The comparison of segmentation performance between algorithms evaluated on references [10, 24] and our method(From 1 to 10, methods are shape-driven, geodesic active contours, fast-marching, 3D optimal graph search, 3D stacked sequential learning, HoliMAb, Bayesian, ANGIOCARE, double sparse auto-encoders, the proposed method). (a) Comparison of LU border segmentatinon performance; (b) Comparison of MA border segmentation performance
2.4 检测结果的定性分析
如图9所示,展示了正常、含钙化斑块、含纤维斑块、含超声阴影、血管分叉、血管侧支6种情况的IVUS图像内膜和中-外膜边界检测实例。图9(a)为IVUS图像,图9(b)为本算法的边界检测结果,图9(c)为临床医生手动勾画的边界,图9(d)为自动勾画与手动勾画的比较。从图9可以看到,本算法提取的两条关键边界能不受斑块和超声阴影影响,如图9第2、4、8~10列。这归因于结合重建损失和对抗损失的联合损失函数对钙化斑块进行有效的识别,尤其是L1重建损失对异常值非常鲁棒。另外,本算法的检测还不受血管分叉和侧支影响,如图9第5~7列。图10展示了10个在广州军区广州总医院跨数据集上的检测实例。检测结果说明了本方法具有较好的泛化能力。但是由于ECG门控数据(见图9)与非ECG门控数据(见图10)之间存在非常大的差异,所以本研究模型在其他数据上所能成功检测的实例显得较为单一,如图10所示。更好地提升本模型的泛化能力,依赖于训练集和测试集是否服从较为同一的分布。这将是未来可深入研究的问题,使得跨数据集的IVUS图像(非ECG门控)转换成ECG门控数据,再利用C-ivusGAN-SHGN模型检测图像中的内膜和中-外膜边界。
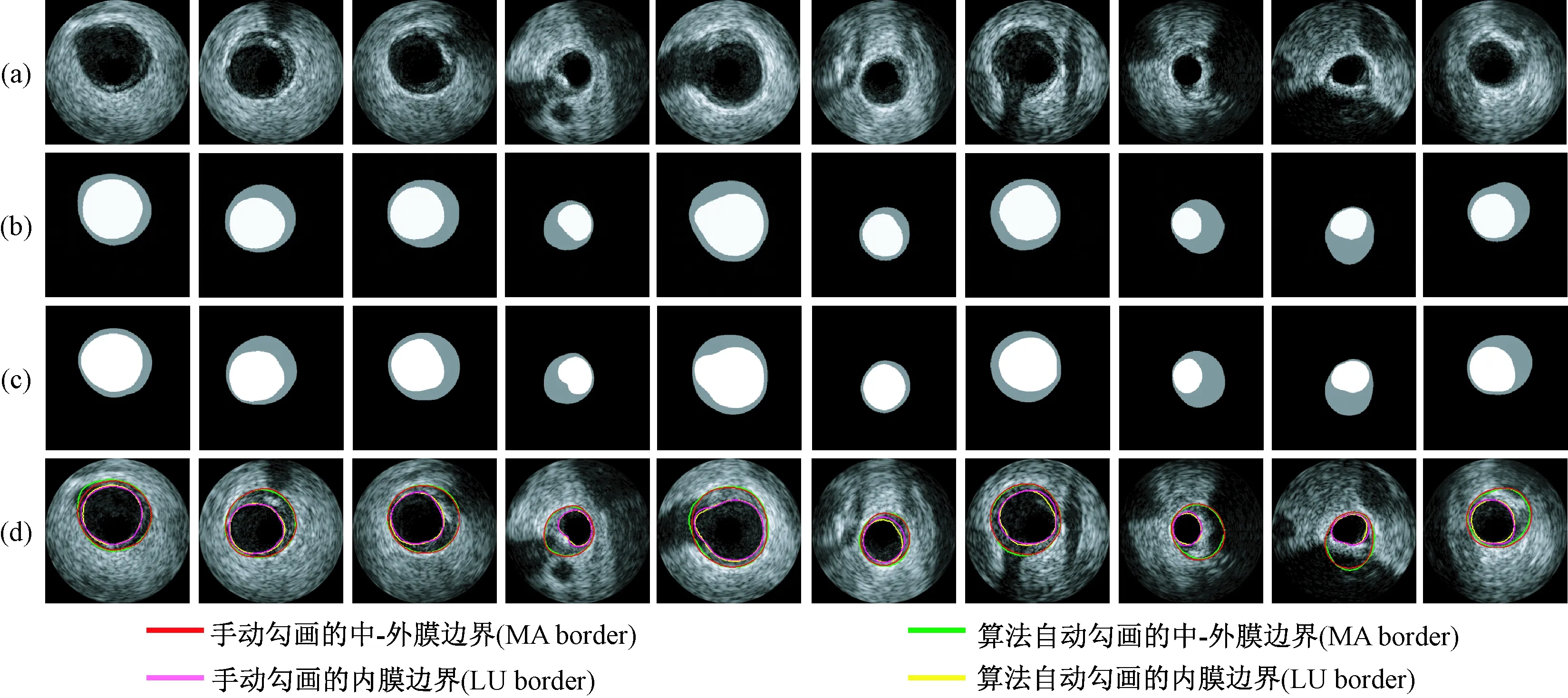
图9 本算法的内膜与中-外膜边界检测结果。(a) IVUS图像;(b) 算法自动勾画结果;(c) 临床医生手动勾画结果;(d) 自动方法和手动方法的比较Fig.9 Lumen and media-adventitia border detection results of the algorithm in this paper. (a) IVUS images; (b) Results from our method; (c) Results from manual method; (d) Comparisons between automatic and manual methods

图10 跨数据集检测实例Fig.10 Border detection examples from cross-dataset
3 讨论
有条件生成对抗网络,不但具有表征学习能力,而且可通过对抗学习缓解过拟合问题。通过编码网络组合不同层次的特征,然后形成高层抽象特征,最后利用解码网络生成所需要的自然图像RGB图、医学图像分割图等。这种自动学习的深度特征相对于传统的手工设计特征而言,在概念表达方面具有较强的鲁棒性和较复杂的抽象性。然而,深度学习算法普遍需要规模较大的训练数据集,否则神经网络训练会受到过拟合问题影响。在不同的图像领域中,数据采集与标注的难度显然不尽相同,采集医学超声图像和手工勾画图像中的感兴趣组织要求经验丰富的医生。因此,在医学图像分析中,训练数据集规模会限制深度网络性能。
利用对抗学习的正则化特性,缓解深度网络在小数据集上的过拟合问题,是应用深度网络在数据量不足的医学图像训练集上进行训练优化的有效方式。因此,本研究结合对抗学习和数据扩充的方式来综合改善深度全卷积网络分割性能。另外,针对IVUS图像边界检测的特点,本研究进一步设计基于VGG-Net和DCGAN的堆叠沙漏网络SHGN。实验量化的结果表明,本研究提出的C-ivusGAN-SHGN模型有效、鲁棒和精确地检测出IVUS图像中的中-外膜和内膜,其分割精度优于8种在国际标准数据集上评估的传统方法和1种基于双稀疏自编码器的深度学习方法。另外,本研究验证了所提出生成器的有效性。在重建损失上,本研究通过实验说明,L1距离适合于检测中-外膜边界,L2距离适合于内膜边界的检测。然而,本研究仍然存在一些不足之处。首先,所采用的国际标准IVUS图像数据集规模较小(435幅),虽然在一定程度上可以反映本研究所提出C-ivusGAN-SHGN模型的分割性能,但使用规模更大的数据集将更具说明性,这是以后所需改进的地方之一。其次,该数据集的采集环境存在ECG心电门控。因此,其数据分布与广州军区广州总医院所采集到的临床实践中非ECG心电门控IVUS图像数据分布存在较大的不一致性。在2.3.4节,虽然通过跨数据集验证说明本研究所提出模型具有较好的泛化性能,但是应用已训练模型对测试图像进行分割,其成功检测率仅为60%,依然存在提升的空间。在未来的研究中,可以通过给训练集加入非ECG心电门控IVUS图像或通过领域适配/迁移学习算法来提升深度网络识别的跨数据集泛化性能。另外,本研究所提出网络C-ivusGAN-SHGN在IVUS上的潜在应用包括斑块钙化灶的分割[38]和易损斑块的识别[39-40]。
4 结论
本研究提出一种结合堆叠沙漏网络SHGN和有条件生成对抗网络C-GAN的IVUS图像内膜和中-外膜边界检测改进方法。首先利用对抗训练和C-GAN,学习以超声图像为约束条件,输出其分割图像的映射关系,将IVUS图像分割为三大不同区域:血管外周组织、斑块区域和内腔区域;然后在分割结果基础上,利用阈值处理检测最终的内膜与中-外膜边界。相比文献[24]所述8种算法和基于双稀疏自编码器方法[10],本算法性能更具有优势。相比文献[25]的Pix2Pix模型,本算法C-ivusGAN-SHGN采用堆叠沙漏网络作为生成器,具有结构紧凑、参数较少的特点,其性能好于基于U-Net的Pix2Pix模型。由于本研究采用的训练数据为ECG门控IVUS图像,所以算法在非ECG门控IVUS图像上的检测结果较为单一,这将是未来需要克服的问题。
猜你喜欢
今日畜牧兽医(2022年10期)2022-12-23
中国免疫学杂志(2022年10期)2022-07-21
北京航空航天大学学报(2021年9期)2021-11-02
健康博览(2021年1期)2021-01-11
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
中国生殖健康(2019年3期)2019-02-01
中国比较医学杂志(2019年9期)2019-01-08
中西医结合心脑血管病杂志(2018年1期)2018-08-15
北京航空航天大学学报(2018年1期)2018-04-20
