
基于关系拓展的改进词袋模型研究
2019-05-10 02:00陈行健胡雪娇
小型微型计算机系统 2019年5期
陈行健,胡雪娇,薛 卫
(南京农业大学 信息科学技术学院,南京 210095)
1 引 言
词袋模型源于文本处理领域,其原理是将目标文档看作若干无序单词的集合,通过统计每个单词在该文档中出现的次数,得到单词频率直方图向量用于文本分类[1].传统词袋模型在机器学习与模式识别等领域均取得了较好的效果,但该模型假设特征单词之间相互独立,忽略了特征单词之间的空间位置信息,在目标对象的特征表示方面还存在局限性.为提高BoW模型的分类性能,提出了一些改进算法.主要可分为三类:一是在局部特征提取阶段选择合适的特征,如Zhang等人提出采用ORB(Oriented Fast and Rotated BRIEF)描述子代替SIFT(Scale-Invariant Feature Transform)优化图像特征,从而提高了检索效率[2];Xie等人通过分析邻域像素和局部图像,引入LQP(Local Quantized Pattern)构建字典,取得了较好效果[3];二是在聚类分析过程中对字典进行优化,如Irfan等人通过对字典降维并使用TF_IDF(Term Frequency_Inverse Document Frequency)算法赋予相应词权重,解决了文本错误匹配问题[4];Zhu等人利用模糊均值(Fuzzy C-Means)代替K均值(K-Means)优化字典,使初始聚类中心的选择更加合理[5];三是在统计信息的基础上融入空间位置信息,如Wang等人引入显著区域提取,结合三角剖分方法融入图像全局信息,得到了较好的预测效果[6];Li等人使用空间金字塔匹配技术(Spatial Pyramid Matching,简称SPM),在图像表示阶段加入局部特征的空间位置信息,从而提高了分类性能[7];Ramesh等人提出上下文词袋特征,结合空间共生矩阵对视觉词组进行特征表示,提高了图像识别的准确率[8].
虽然当前的方法在不同领域均取得了较好的效果,但其中大部分算法仍然是针对局部特征提取或聚类分析过程进行改进,而并未考虑聚类后得到的特征单词之间的空间位置关系,且在结合特征单词空间信息方面,所生成的单词特征表达能力和区分度不足.因此,本文在传统词袋模型的基础上,对聚类后得到的特征单词提出位置关系图谱,并与传统词袋特征相融合,可以使目标对象的特征表述更具有代表性,从而提高分类性能.
2 基于关系图谱的词袋模型
本文主要以字符序列作为研究对象.字符序列被广泛应用于文档、Web用户访问日志、金融数据库的交易序列以及生物信息领域的基因和蛋白质序列等应用中[9].近年来,随着大数据时代的来临,字符数据库呈现爆炸式的增长趋势,字符序列的数据挖掘也逐渐成为机器学习领域的重点研究内容.
传统词袋模型忽略特征单词之间的词序、语法及语义等要素,将目标对象仅仅看作是由若干个无序单词组成的集合,这种方法没有考虑到特征单词之间的空间位置信息,得到的词袋特征表达能力和区分度不足.针对上述问题,本文提出一种基于关系拓展的改进词袋模型,该模型在传统词袋模型的基础上,对序列单词提取位置关系图谱,将得到的关系图谱进行特征转换、降维并与传统词袋特征相融合作为模型最终特征.相比传统词袋模型,本文提出的模型能更加全面地反映目标序列的特征分布规律.其流程如图1所示.

图1 基于关系图谱的词袋模型流程Fig.1 Process of BoW model based on relational graph
2.1 局部特征提取
假定对于任意字符序列,首先对序列进行分割处理提取局部特征,本文采用滑动窗口分割法.滑动窗口分割法即将每条字符序列按照一定窗口进行切分,通过设定窗口大小和滑动间距得到不同长度和数量的序列片段,经特征提取后得到序列单词集合形成构建字典的基础.这种方法能完整保留字符序列的全部信息.本文取滑动间隔为1,滑动窗口大小决定序列单词长度,需满足以下条件:

(1)
其中L1,L2,…,Ln表示数据集中所有字符序列长度,L即为数据集中最短字符序列长度,d为滑动窗口大小,即序列单词长度在L/2到L之间选取,具体值根据实验经验选取.
分割后对序列片段进行特征提取得到特征单词,对特征单词进行K-Means聚类[10]构建字典,将目标序列的各个特征单词映射到与之距离最近的聚类中心,则目标序列可由若干个聚类中心唯一表示,即对于任意字符序列经上述步骤后可表示为:
F=(x1,x2,x3,…,xn),1≤i≤n,n∈Z
(2)
其中F为目标序列,xi表示序列F中第i个特征单词片段所映射的聚类中心标签,n为序列切分长度.
2.2 关系图谱
马尔科夫模型是刻画随机过程的重要模型,具有极强的对动态过程序列的建模能力和时序模式的分类能力[11].本文结合马尔科夫模型对特征单词提出位置关系图谱.对于一个随机过程,如果它所处的未来状态仅与它的当前状态有关,并且独立于过去已发生的状态,那么该随机过程被称为马尔科夫过程.对于任意有限状态序列X={x1,x2,…,xt},用x1,x2,…,xt表示该状态序列在T=1,2,…,t时刻所处的状态.则将满足以下条件的状态序列X称为马尔科夫链:
(3)

(4)
基于马尔科夫链,则对于任意目标序列F,假设x1,x2,…,xn表示该序列在N=1,2,…,n时刻所处的状态,则序列F在N时刻所处的状态只与前面已出现的N-1个时刻的状态有关,序列F中任一时刻所处的状态xN满足以下条件函数:
xN=g(xN-1,xN-2,…,x1)
(5)
如果假设影响序列F未来的当前状态仅有一个,即序列F中任一时刻所处状态xN仅取决于上一时刻所处状态xN-1,那么上式将变为:
xN=g(xN-1)
(6)
在一个随机马尔可夫过程中,k阶马尔科夫链表示当前状态仅与前k个相邻状态有关.则对于序列F中任意一个聚类中心xi,xi所映射的单词片段仅与前面已出现的k个聚类中心所映射的单词片段有关,其中k为马尔科夫相关系数,1≤k≤i-1,k=1时表示当前聚类中心xi仅与前面已出现的一个聚类中心xi-1有关,k=i-1时表示当前聚类中心xi与前面已出现的i-1个聚类中心有关,则对于序列F,依次提取F中每个特征单词与前面已出现过的特征单词之间的相邻关系,即可得到位置关系图谱.本文k取i-1.具体算法思路如下:
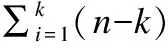
(7)
其中m为聚类中心个数,vij为矩阵D中任意元素值,对应聚类片段(xi,xj)出现的次数,矩阵的行和列分别对应不同聚类中心标签.
提取算法过程如下:
输入:目标序列F,聚类中心个数m,序列切分长度n,初始零矩阵D
输出:位置关系矩阵
1)for(i=1;i≤n;i++)
2)for(j=i-k;j≤i-1;j++)
3)D(xi,xj)+=1
4) 重复步骤3)直至j=i-1
5)vij=D(xi,xj)
6) 重复步骤5)直至i=n
7) 输出D
目标序列F经上述步骤后被表示成一个m*m的位置关系矩阵,将矩阵转化为关系图谱,图谱中各个不同亮度的像素点分别代表相应聚类片段出现的次数.当马尔科夫系数k=1时,提取过程如图2所示.

图2 词袋关系图谱提取步骤Fig.2 Extraction process of BoW relational graph
2.3 特征转换
经上述步骤得到的关系图谱以二维矩阵的形式存在,如果直接展开进行串接表示数据量过大,训练分类器时的内存和时间消耗代价过高.一般用池化的方法来为特征向量降维.池化操作常用于图像处理领域,对图像不同位置的特征进行聚合统计,提取有效特征,减少计算量.常用的池化方法有最大池化(Max-pooling)[12]和平均池化(Mean-pooling)[13].Max-pooling即对邻域内特征点取最大值,能更多的保留图像的背景信息,而Mean-pooling则是对邻域内特征点求平均值,能更多的保留图像的纹理信息.考虑到对矩阵直接进行池化可能会丢失部分信息,因此本文使用卷积神经网络(Convolutional neural network,简称CNN)对矩阵进行特征转换.
已有研究表明,卷积神经网络的全连接层能更为全面的捕捉到全局空间的布局信息,因此本文直接提取全连接层的输出作为关系图谱的特征表示.考虑到经上述步骤得到的关系图谱比较稀疏,为了进一步提高CNN模型的鲁棒性,本文借鉴自然语言处理中的词嵌入方法对稀疏图谱进行密集表示.词嵌入是将词的稀疏向量转换为稠密向量的一类方法.具体方法是随机生成一个m*m的权重矩阵,将上文得到的关系图谱矩阵映射到随机权重矩阵,则矩阵中每一个维度都被转化为密集向量的形式,该过程的输出即为密集图谱[14].将密集处理后的关系图谱送入CNN进行深度特征提取,其网络结构如图3所示.

图3 CNN模型结构Fig.3 Model structure of CNN
卷积神经网络主要由输入层、卷积层、下采样层、全连接层和输出层等五个部分组成.其中,输入层即为关系图谱X,卷积层则通过制定不同的窗口值对X进行特征提取,池化层使用最大池化对特征图进行降维来减少后续层的参数.全连接层将卷积层或者池化层中具有类别区分性的分布式特征映射到高维向量输出.本文采用纠正线性单元(Rectified Linear Unit,简称ReLU)作为激活函数.为了有效地缓解训练过程中的过拟合现象,在卷积层和全连接层中均使用了Dropout技术,经验值取0.5.实验选取Cross-Entropy作为损失函数,并引入Weight-Decay对参数进行正则化,提取全连接层的输出作为关系图谱的最终特征表示,其向量维度为p.
2.4 特征融合
基于关系图谱的特征表示方法虽引入了局部特征的空间位置信息,但其缺少特征单词的全局统计信息,分类性能仍有待提高.因此本文利用多特征融合的方式对图谱特征及词袋特征进行进一步处理以提高模型精度.将提取到的两种不同的特征向量拼接形成最终特征,经过融合后的特征向量能更加全面地反映目标序列的全局信息,其最终表示为:
V=[vt1,vt2,vt3,…,vtm,vs1,vs2,vs3,…,vsp]
(8)
其中vt为词袋特征向量,vs为位置特征向量,m和p分别代表相应特征向量维数.由于拼接后得到的向量维数较大,因此本文使用主成分分析(Principal Component Analysis,简称PCA)的方法进行降维.将降维后的数据经标准化后作为模型最终向量送入分类器进行分类.
3 实验与分析
为检验模型性能,将其应用到蛋白质亚细胞区间定位预测研究中.蛋白质亚细胞区间定位对于确定蛋白质功能、设计药物靶标、揭示分子交互机理等方面都有很大的促进作用,是生物数据挖掘中的研究热点[15-19].蛋白质序列是由20 种氨基酸残基以不同的字母形式组合而成的生物字符序列.蛋白质亚细胞区间定位预测即根据蛋白质序列预测其所处的亚细胞区间,属于分类问题.
3.1 实验环境
本文使用Pytorch作为深度学习框架,实验环境为:Intel Core E5-2650 v4 CPU,2.2GHz主频,GTX 1080Ti显卡*2,16G内存,1T硬盘.Windows10操作系统,Anaconda开发平台.
3.2 数据集
在蛋白质亚细胞区间定位研究中,传统实验方法所需时间周期较长,人工标注完善的蛋白质序列数据库规模有限.本文采用国际公认有效且使用较为广泛的ZD98、ZW225及CL317作为实验数据集.其中ZD98由Zhou和Doctor[16]构建,共有98条蛋白质序列,分为4个亚细胞区间类别;ZW225由Zhang等人[17]构建,共有225条蛋白质序列,分为4个亚细胞区间类别;CL317由Chen和Li[18]构建,共有317条蛋白质序列,分为6个亚细胞区间类别.
3.3 检验方法与评价指标
实验基于一对一算法(one-versus-one)构造支持向量机(Support Vector Machine,简称SVM)多类分类器进行预测.采用Jackknife进行假设检验.Jackknife是蛋白质亚细胞定位预测中使用最多的测试方法,即每次从数据集中取出一条蛋白质序列作为测试集,其余序列作为训练集送入分类器进行训练,以此类推直至所有序列均预测完毕,是一种客观有效的假设检验方法[19].本文使用准确率(Acc)作为最终评价指标,其定义如下:
(9)
其中,TPi代表第i类蛋白质序列亚细胞区间预测正确的条数,FNi代表第i类蛋白质序列亚细胞区间预测错误的条数,M为蛋白质亚细胞区间类别总数.
3.4 实验结果与分析
为了验证本文模型的有效性,将本文方法在三种数据集上的预测结果列于表1中,同时将选取的在蛋白质亚细胞区间定位中具有代表性的氨基酸组成(Amino acid composition,简称AAC)算法[20]、伪氨基酸组成(Pseudo Amino acid composition,简称PseAAC)算法[15]及二肽组成(Dipeptide,简称Dipe)算法[21]得到的预测结果一并列出,如表中AAC、PseAAC及Dipe所示,其中Dipe是蛋白质序列特征表示方法中使用较多的位置信息提取算法.
基于关系图谱的特征表示方法在实际应用中也取得了不错的效果,为了便于比较,本文也列出了基于各种序列位置特征提取算法的实验结果.其中Markov为Bulashevska等人通过计算蛋白质序列在一阶马尔科夫链下的状态转移矩阵进行预测的实验结果[22];Seq_Index为Liao等人基于横向和纵向编码整合氨基酸残基位置分布信息进行预测的实验结果[23];Bow_Index为本文结合传统词袋模型基于Liao等人的实验方法提取片段位置信息进行预测的结果;Bow_Matrix为将本文关系图谱作为最终特征表示进行预测的结果.
此外,本文列出了Zhao等人将传统词袋模型应用到相同数据集进行预测的实验结果[24],如表中BoW所示,同时也进行了多次基于不同改进算法的预测实验.其中TF_IDF为文献[4]中的词频-逆文档频率算法;FCM为文献[5]中的模糊均值聚类算法;SPM为文献[7]中的空间金字塔匹配算法.不同对比算法在局部特征提取阶段均使用AAC进行特征提取,预测时均使用SVM作为最终分类器,最终比较结果如表1所示.
表1 数据集预测准确率比较
Table 1 Comparison of the accuracy of data sets

MethodsZD98ZW225CL317AAC[20]0.80610.80440.8196PseAAC[15]0.83330.82670.8228Dipe[21]0.82290.81780.8196Markov[22]0.88780.83110.7911Seq_Index[23]0.86730.84780.8386Bow_Index0.88780.84000.8611Bow_Matrix0.91890.84450.8924BoW[24]0.90820.86220.8829TF_IDF0.89790.86220.8544FCM0.89790.85780.8924SPM0.86730.84890.8386Max_Pooling0.88780.83110.8228Mean_Pooling0.86730.84000.8196Bow_Flatten0.90820.85780.8924Our0.94890.89780.9304
从表1可以看出,本文模型相比传统蛋白质序列特征提取算法AAC、PseAAC和Dipe等在ZD98、ZW225和CL317数据集的总体预测精度上最大提升了约11个百分点,实验证明本文模型能有效增加蛋白质亚细胞区间定位预测的准确率.对比Dipe、Seq_Index与Bow_Matrix的实验结果,进一步证实了本文关系图谱对序列位置特征提取的有效性.将本文方法与基于传统词袋模型(BoW)及其改进算法(TF_IDF,FCM,SPM)的实验结果进行对比,在相同数据集上的准确率也都提高了约2到5个百分点,实验表明本文模型较传统词袋模型及其改进算法具有显著优势.
对比Markov、Bow_Index与Bow_Matrix的实验结果可知,就蛋白质亚细胞区间定位预测研究而言,经词袋模型处理后的蛋白质序列所表示的单词信息量比单个字符更加丰富,其相邻切片类别的先验知识信息优于只考虑序列相邻氨基酸残基关系的先验信息,故其预测精度优于基于位置先验信息的马尔可夫算法.
对于关系矩阵,文献[12,13]中有多种处理算法,如将矩阵直接串接形成一维向量(Bow_Flatten),及当前应用较广泛的池化算法(Max_Pooling,Mean_Pooling),提取关系矩阵每一列的最大值或平均值,然后串接形成一维向量等.实验结果表明,直接连接形成一维向量会造成维数灾难,降低模型精度,池化提取特征又忽略掉关系矩阵每一列的大量信息,导致特征表达能力不足,通过CNN提取关系图谱的全局信息,能更加全面地反映序列位置特征的分布规律,提高分类准确率.
4 结束语
本文提出了一种基于关系拓展的词袋模型,引入位置关系图谱对聚类单词提取位置信息,并与统计信息相融合作为模型最终特征,对提升传统词袋模型特征表达能力方面具有重要意义.实验表明,本文提出的关系图谱能有效解决传统词袋模型中统计信息区分度不足的问题,改进了传统词袋模型的应用性能.结合卷积神经网络对关系图谱进行特征提取,相比池化等方法效果更优.此次针对传统词袋模型进行了一些改进,在字符序列特征提取方面做了研究工作并取得了一些成果,接下来将在对稀疏矩阵的特征提取算法上做进一步的改进,并尝试在其他应用领域做进一步的拓展,重点关注图像识别以及文本分类等.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
北京航空航天大学学报(2022年8期)2022-08-31
计算机应用与软件(2021年7期)2021-07-16
中国传媒大学学报(自然科学版)(2021年5期)2021-02-24
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
新城乡(2018年6期)2018-07-09
电机与控制学报(2018年9期)2018-05-14
领导科学论坛(2016年9期)2016-06-05
