
多语言文本情绪分析模型MF-CSEL
2019-05-10 02:00徐源音柴玉梅王黎明
小型微型计算机系统 2019年5期
徐源音,柴玉梅,王黎明,刘 箴
1(郑州大学 信息工程学院,郑州 450001)2(宁波大学 信息科学与工程学院,浙江 宁波 315211)
1 引 言
伴随社交媒体和电子商务平台的快速发展,用户已习惯于通过网络平台发表自己的观点、评论商品的优劣,这些网络文本大多反应用户的真实情感.从这些文本信息中自动准确的识别用户的情绪类别,可以为政府舆情监控、企业管理与决策提供有效的支持[1],也成为学术界近来持续关注的研究热点[2].
现有的文本情绪分析方法[3,4]大多针对单一语种的文本,但在当下开放自由、文化交流日益频繁的网络坏境中,中英文混合的表达方式正逐渐受到人们的喜爱,例如“真心hold不住啊”,“就是这个feel,i like ~”,“下了班店里还分礼物,回到家就收到老姐的红包happy new year!”.已有研究表明,在这种以中文为主体,混合少量英文的网络文本中,英文表达对于文本情绪分析有着至关重要的影响[5],如“hold不住、like、happy”这些带有显著情感信息的单词.然而,单语言文本的情绪分析方法通常分为基于词典和规则的方法[6]、基于机器学习、深度学习的方法[7,8]等,对于上述例句而言,只针对中文文本的情绪分析方法,大多不能有效捕捉句中英文所表达的情感信息.为此,学术界将由多种语言构成的文本命名为Code-switching text,并对此类语言现象展开了广泛的研究[9].Ling和Wang等人[10]从微博中提取超过100万条中英混合文本,从Twitter中抽取大量中英混合文本、英文阿拉伯语混合文本,表明多语言文本被广泛应用于社交网络平台,针对多语言文本的情感分析应用研究也受到众多学者关注.Lee和Wang[11]构建多语言文本语料库,通过分析此类文本中不同语种对于文本情感影响的占比,提出一种基于最大熵模型多分类器组合的情感分析方法,实验结果表明同单语言模型相比,多语言混合模型的分类效果有所提升.
对含有情绪表达的中英文混合文本,合理使用情感词典、词向量、语言知识库等资源学习文本特征对情绪分析任务十分重要.本文提出多语言文本情绪分析模型MF-CSEL(Cost Sensitive Ensemble Learning method based on Multi-Feature fusion),使用词向量、双语情感特征、TF-IDF权值矩阵做为基分类器的输入特征,并通过代价敏感集成学习方法融合不同样本空间下基分类器的分类结果.
2 相关工作
多语言文本的相关任务是自然语言处理的难点之一,且相关探索较少,文本情绪分析的研究方法大多为单语言模型.Peng和Cambria等人[12]从单语和多语种的角度分析了中文情感分析的研究进展,首先总结了情感语料库和词汇的结构,然后通过三种不同的分类框架对汉语中的单语情感分类进行了阐述,最后介绍了多语种方法的情感分类研究.Vilares和Alonso等人[13]重点分析了Twitter上英语和西班牙混合文本的情感分类问题,在带有情感标签的英语-西班牙语混合文本情感分类任务中,没有语言检测的多语言模型效果优于单语模型.Giatsoglou和Vozalis等人[14]对使用不同语言表达观点、意见的文本片段,提出了一种快速、灵活、通用的情感检测方法.该方法研究了多种文档的矢量表示方法,包括基于词典的、基于词嵌入的和基于混合特征的向量化方法,并在四个包含希腊语和英语的用户在线评论数据集上进行实验,评估了这些特征表示方法在情感分类任务的性能.由此作为出发点,文本使用向量表示文本信息,并使用现有情感词典、语言知识库等资源针对不同语种分别提取情感特征,结合TF-IDF权值矩阵作为模型的特征输入,以更加完善地学习文本含有的情感信息.
栗雨晴[15]等人提出一种基于双语词典的微博情绪分析方法,该方法通过构建双语情绪词典实现对中英文混合文本的情感倾向性分析,并同多数投票算法、支持向量机算法、K近邻算法对比,实验结果表明该方法在分类准确率和F1值上均有所提高.Mei Lee和Wang就多语言文本的情感分析提出了三种方法[16-18]:
1)多视角学习框架,该方法从单语文本中提取单语视图,将单语文本和翻译文本结合起来构建双语视图,通过单语和双语两种视角来分析文本情感.实验表明该方法在多语言文本情感分析中具有有效性.
2)基于联合因子图模型的多语言文本情感分析,该方法利用因子图模型的属性函数从每条文本中学习单语和双语信息,用因子函数来探讨不同情感之间的关系,并采用信念传播算法来分析文本情感.
3)基于双语和情感信息的多语言文本情感分析,该方法使用词-文档二分图将双语和情感信息结合起来,提出了一种基于标签传播的二分图学习方法.
不同于上述情绪分析方法,本文提出的MF-CSEL模型将基于CBOW(Continuous Bag-of-Words)模型训练得到的词向量序列化组合为文本向量,将其同双语情感特征、TF-IDF权值矩阵相结合,再使用代价敏感集成学习方法实现多语言文本情感分析.通过基于语义相似度的样本空间重构算法平衡数据集,选择不同的样本空间在基分类器支持向量机(Support Vector Machine,SVM)和高斯朴素贝叶斯(Gaussian Naive Bayes,GaussianNB)上进行情绪分类,使用代价敏感集成策略去融合基分类器的实验结果,以提高情绪分类的精度.
3 多语言文本情绪分析模型MF-CSEL
多语言文本情绪分析模型MF-CSEL将文本情绪归为五类,分别为happiness、sadness、anger、fear、surprise.MF-CSEL的模型框架如图1所示,为使学习到的词向量包含更丰富的语义信息,本文选择扩展语料集,使用标注数据集和从微博爬取的语料集共同训练CBOW模型得到词向量表,序列化组合每条文本所含的词向量构建文本特征向量.不同于使用机器翻译将文本变为同语种后再提取情感特征的方式,本文针对不同语种选用对应的情感资源分别提取情感特征,避免机器翻译带来语义变化,通过TF-IDF权值矩阵表示关键情感词在不同情绪文本中的权值.完成特征工作后,再使用代价敏感集成学习方法实现文本情绪分类.首先,本文使用二元关联将多标签情绪分类问题转换为单标签分类任务,为避免不平衡数据集影响实验结果,本文提出基于语义相似度的样本空间重构算法,依照情绪类别得到不同样本空间;再使用代价敏感集成策略融合基分类器在不同样本空间上的分类结果,得到模型输出.

图1 MF-CSEL模型图Fig.1 MF-CSEL model diagram
3.1 基于CBOW模型的文本特征向量学习
CBOW模型是word2vec[19]中的一个神经网络模型,不同于Skip-gram模型,它通过上下文中词的one-hot向量来预测当前词向量.为有效保留上下文含有的语义信息,本文选用CBOW模型训练文本的词向量,并采用负采样(Negative Sampling,NEG)的方法对模型进行求解以减少训练时长,提高算法的效率.NEG使用简单的随机负采样替换哈夫曼树可提高模型训练速度并改善所得词向量的质量.对每条文本,通过序列化融合所有的词向量,构建含有词序信息的文本特征向量.
CBOW模型的网络结构如图2所示,它由输入层、投影层和输出层三部分构成,输入层中wk-c、wk-1、wk+1、wk+c表示当前词wk的上下文Context(w),输出层为wk,表示在已知当前词上下文Context(w)的前提下,预测当前词wk.在双语语料集中,类似“的”、“a”、“the”这种没有太多语义信息的词往往高频出现,为解决高频词与低频词的不平衡性,对词汇表中的每个词wi按公式(1)所得的概率舍去.
(1)
其中,λ是一个设定的阈值,本文设为10-5;f(wi)表示词wi文本集中出现的频次.

图2 CBOW模型结构图Fig.2 CBOW model structure diagram
此时,给定样本S=(w,Context(w)),当前词w为正样本,通过负采样方法从Context(w)中得到负样本集NEG(w),对语料集C,模型的求解问题转换为最大化

(2)
其中,p(u|Context(w))可表示为:
(3)

(4)
从公式(4)可看出,目标函数表示在提高正样本概率的情况下,减少负样本的概率.采用梯度上升法对其求解得到各参数的更新公式[注]https://blog.csdn.net/itplus/article/details/37969979.使用词向量直接构建文本特征向量,常见做法为对每条文本所有词向量累加后取其均值,如公式(5)所示:
(5)

(6)
(7)
为此,本文提出一种序列化融合词向量的方法来构建文本的特征向量,通过公式(8)计算得到单句的特征向量,并对文本中所有的句向量求平均作为该条文本的特征向量,具体过程如算法1所示.
(8)
算法1.文本向量构建算法
输入:分词后的语料集C

1.初始化θ、η,词向量v(u)
2.for eachckin C:
3. for eachwiinck:
4. while 不收敛:
5.e=0
7. for eachu∈{wi}∪NEG(wi)
9.g=η(Lwi(u)-q)
10.e=e+gθu
11.θu=θu+gxwi
12. end for
13. for eachu∈Context(wi)
14.v(u)=v(u)+e
15. end for
16. end for
17.end for
18.for eachckin C:
19. for eachsminck
21. end for
23.end for
其中,ck表示语料集的每条文本,sm表示文本中的每句话,wi表示文本中的每个词,η为学习速率;e为词向量变化值.
3.2 双语情感特征提取
多语言文本中,人们经常使用具有强烈情感意义的词来表达自己的心情,例如“love”、“happy”、“悲催”等.文本中传达的显式情感信息在情感分析任务中变成不可缺失的特征资源,它大多直接决定文本的情绪类别.为提取多语言文本的情感特征,使用机器翻译方法将文本转换为同种语言的方式颇受学术界的喜爱.然而,中英文混合的表达方式风格较为随意,大多不受语法约束,翻译后的文本可能发生语义变化,影响特征提取的精度.为更好的识别文本的情绪表达,提高情绪分析的准确性,本文基于现有的中英文情感词典资源,分析双语文本的语言表达特点,针对不同语种分别提取文本的情感特征.
现常用的中文情感词典有四种,分别为:HowNet情感极性词典、大连理工大学情感词汇本体库、清华大学极性词典、台湾大学情感词典.归纳整理得到基础情感极性词典pos、neg和小规模细粒度情感词典,词典规模如表1所示.
基于上述情感词典,本文从情感倾向词和细粒度情感词两方面分别提取情感特征,特征类别如表2所示.基于情感词典直接匹配情感词的特征提取方式在文本含有否定形式的情况下可能会出现语义理解错误.例如“The meal看起来不是很美味”,句中表达的观点是“不美味”,若直接匹配情感词不考虑否定词就会出现情感理解偏差.为此,本文基于上述情感词典,在提取情感特征时通过否定词表和句法分析识别文本中的否定形式.对于情感倾向词,根据否定词修饰的情感词极性直接转换情感类别,如“美味”前有否定修饰“不”,则情感类别由pos→neg.对于细粒度情感词,否定修饰后的情绪类别变换难以准确判断,如情绪happiness、sadness、anger之间并非完全对立关系,由此,本文针对每类情感词添加对应的否定特征,特征值表示该类情感词前是否存在否定修饰.
表1 情感词典具体描述
Table 1 A description of emotional dictionaries

类型示例规模pos加油、棒、哈哈23177neg可恶、糟糕、哭22717happiness幸福、满足、开心13075sadness难过、哭、伤心2342anger生气、怒、气死我了10670fear害怕、恐怖、吓死人1537surprise竟然、惊人、哇230
表2 中文情感特征类别
Table 2 Chinese affective feature categories

特征类别描述维度Tend-e(pos、neg)是否存在情感倾向词2Tend-f(pos、neg)每类情感倾向词的数目2FgEmo-eemo是否存在细粒度情感词5FgEmo-femo每类细粒度情感词的数目5FgEmo-F否定修饰(细粒度情感词)5
本文使用斯坦福词性标注工具(Part-Of-Speech Tagger)对中英混合文本进行词性标注,并基于SentiwordNet情感词典提取英文情感特征.SentiwordNet情感词典基于WordNet,由意大利信息科学研究所构建[20].它将情感词按词性分为四类,分别为名词(n)、形容词(a)、动词(v)和副词(r),每个情感词对应有正向情感值(PosScore)、负向情感值(NegScore),打分区间为[0,1].词典中含有大量两个单词或及其以上构成的词组记录,但在以中文为主体的多语言文本中,英文词组表达较少且难以准确识别,因此本文只考虑单个单词.按照词典所含四种词性,合并NN、NNS、NNP、NNPS为n(名词),合并VB、VBD、VBG、VBN、VBP、VBZ为v(动词),将JJ、JJR、JJS转为a(形容词),将RB、RBR、RBS合并为r(代词),同时将动词的过去式、名词的复数形式,形容词的比较级形式等进行词形还原[21].同SentiwordNet词典按情感词的词性进行匹配,如公式(9)、公式(10)所示,情感打分为该词性下所有语义的情感值的均值.同中文情感特征一样,在计算情感值时考虑否定修饰对文本情感的影响,对有否定修饰的情感词将其PosScore和NegScore打分互换.
(9)
(10)
其中,N表示文本中英文情感词的数目,syn表示ewi所在词性下的所有语义记录,num(syn)表示syn的数目.
3.3 代价敏感集成学习
代价敏感分类方法是指为不同类型的错误分配不同的代价,以使在最终分类时,高代价错误产生的数量和错误分类的代价和最小[22].多语言文本情绪分析任务属于多标签分类问题,情绪发生的比例不同,导致样本类别存在较大的不均衡性,会影响最终的分类结果.为此,本文选择代价敏感集成学习策略最大程度避免样本不均衡对最终分类精度造成的影响.代价敏感常用的方法有调整样本分布、元代价、代价敏感决策等,本文通过计算文本语义相似度来均衡样本分布,并使用代价敏感决策方法按错分代价制定集成策略,融合不同样本空间下基分类器的分类结果得到最终实验结果.
3.3.1 基于语义相似度的样本空间重构算法
在代价敏感学习中,常用的样本空间重构方法会依据数据类别所占比例调整样本分布,对占比较大的类别进行欠采样,对占比较小的类别进行过采样.这种随机采样的方式可能会降低样本的多样性,造成数据损失.本文通过计算语义相似度,放弃相似度较高的样本,在减少占比较大样本类别的同时尽可能的保留样本类型的多样性.
对前文所得的文本特征向量wvc,依照余弦相似性的计算方法计算文本语义相似度,选择相似度最高的文本按概率δ舍弃,实现样本空间重构,具体过程如算法2所示.
算法2.基于语义相似度的样本空间重构算法
输入:训练集C,文本向量wvc,迭代次数t,δ
输出:新样本集C′
1.time=0
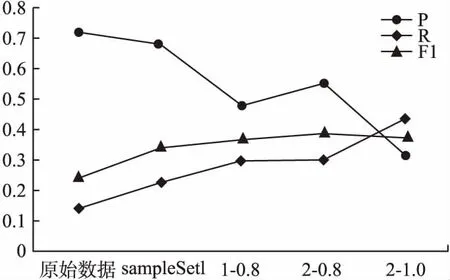
2.while(time 3. fork=1 tom 6.k=k+1 7. if (m==k) break 8. end for 9.time=time+1 10.end while 11.output C′ 3.3.2 代价敏感集成学习策略 本文使用二元关联(Binary Relevance)将多标签情绪分类问题转换为单标签问题,从数据集大小、数据维度以及训练效率的角度分析,基分类器选择SVM和NB. 由于样本特征值大部分是连续值,根据数据类型选择高斯朴素贝叶斯(GaussianNB)作为基分类器,GaussianNB是指先验为高斯分布的朴素贝叶斯,它假设P(xi|emo)符合高斯分布,也就是: (11) 支持向量机SVM通过在样本空间中找到一个划分超平面,将不同类别的样本分开以实现分类.它在小规模、高维度的数据集中有特有的优势,分类原理为: (12) S.t.yi(ωΤxi+b)≥1-ξi,i=1,2,…,n 其中,ξi为松弛变量,C表示惩罚因子,通过计算核函数k(xi,xj)替代特征向量的内积(本文令k(xi,xj)=xiTxj),得到svm的决策函数为: (13) 对训练数据按情绪类别等比例分割为两部分train、dev,dev为小规模的测试数据,用于计算错分代价制定模型融合策略.如图3所示,对训练数据train调用样本空间重构算法,依照参数δ得到不同的样本分布trainδ,将其分别放入基分类器训练后得到SVMT和NBT,输入测试集dev得到不同样本分布下的情绪分类结果.对每类情绪分别计算每个基分类器对应的错分代价errorCost,比照测试数据dev的样本标签将错误分类归为误报和漏报两种情况,分别设置权重α、β表示对该错误类型的容忍度,计算公式如公式(14)所示.根据错分代价制定融合策略,对每类情绪舍弃其错分代价最高的分类器中该情绪的分类结果,在错分代价最小的分类结果选择含有该情绪的数据记为T,其余的采用投票策略对上述结果进行补充,若超过一半则将其归为正例T,未标注的数据均记为不包含该情绪,具体表示如公式(15)所示.依照该融合策略根据各基分类器对应的错分代价对测试集test调用模型SVMT和NBT得到情绪分类结果进行选择,得到最终的分类结果. 图3 代价敏感集成模型Fig.3 Cost sensitive integrated model diagram 表3 情绪分类结果统计表 GemoTGemoFPemoTnum(PemoT,GemoT)num(PemoT,GemoF)PemoFnum(PemoF,GemoT)num(PemoF,GemoF) 以单类情绪emo为例,表3表示基分类器在测试集dev上的分类结果,Gemo表示样本标签,Pemo表示模型预测样本是否含有情绪emo,num(PemoT,GemoF)表示模型预测情绪emo为T而样本标签情绪emo为F的数目,此类错误为模型误报,num(PemoF,GemoT)表示模型预测情绪emo为F而样本标签情绪emo为T的数目,此类错误属于漏报.本文认为模型误报的错分代价高于漏报,且误报的错分代价与其在预测结果含有该情绪的样本总数num(PemoT)中的占比相关,错分代价计算公式如公式(14)所示: (14) 其中α、β表示根据对不同错误的容忍度分别设置的代价指数,本文令α为2、β为1. 依照错分代价errorCost制定融合策略如公式(15)所示,即对不同样本分布下基分类器的错分代价进行排序,将代价最小的分类器用于测试数据test,并选择标签为T的情绪,将代价最大的分类器直接舍弃,对其他分类器用于测试数据test的分类结果使用投票策略,合并其标注的情绪类别得到MF-CSEL的最终实验结果. (15) 为保证实验结果的可靠性,本文选用nlpcc2018多语言文本情绪识别评测数据集作为实验数据,该数据包含6728条训练数据和1200条测试数据,将文本情绪分为五类,分别为happiness、anger、fear、surprise、sadness,每类情绪分布情况如表4所示. 表4 实验数据情绪分布表 happinesssadnessangerfearsurprisenone训练数据204412066547331532111测试数据5143531245291201 本文选用与nlpcc2018评测任务相同的评价标准,用精确率P(Precesion)、召回率R(Recall)、F1值(F1-measure)以及宏平均的F1值(Macro_F1)来评估本文方法,宏平均的计算公式如下所示: (16) (17) (18) (19) 其中,i表示5类情绪之一,gold(emo=i)表示样本标注情绪为i的数目,sys_correct(emo=i)表示模型预测为情绪i与标注结果一致,sys_proposed(emo=i)表示模型预测为情绪i的数目. 本文共提取3类特征:文本特征向量wvc,双语情感特征bil-feature,TF-IDF权值矩阵.如图4所示,纵轴表示各类的F1值,Baseline为评测主办方以unigram为特征、svm为分类器得到的实验结果. 对于基分类器NB而言,仅使用文本特征向量wvc所得的实验结果就已优于Baseline,说明本文基于CBOW模型所得词向量的文本向量构建方法具有有效性,在叠加双语情感特征后,marco-F1值也有显著提升.对基分类器SVM,本文以TF-IDF为特征得到的实验结果,marco-F1值略低于基线模型,但在叠加文本特征向量wvc和双语情感特征bil-feature后,分类效果得到显著提升.因此,本文对不同的分类器分别选择各自最优的特征组合方式NB′和SVM′.另外,对比实验数据分布情况,情绪anger、fear、surprise的F值相对较低的原因可能与样本分布不均衡有关. 图4 不同特征组合的分类结果对比图Fig.4 Comparison of classification results of different feature combinations 分析训练数据中各类情绪的分布情况,无情绪样本none的数目高于全部数据的三分之一,而情绪surprise只有153条,数据的不平衡性可能造成分类器偏向于占比较高的类别.本文使用二元关联实现多标签分类,即对于情绪fear而言,无情绪样本none和其他4类情绪样本组成负样本,这样分类器会更倾向于将情绪fear归为无.为此,首先调整无情绪样本none的比例,对此类样本按t=2,δ=1调用算法2进行缩减,得到新的训练集sampleSet1,此时,调用基分类器得到实验结果如图5、图6所示,二者的marco-F1均比使用原始数据分类有所提升.从图中可明显看到,NB的分类结果中除情绪sadness外其他各类的召回率均高于精确率,说明分类结果中误报率较高,会导致错分代价过高.SVM实验结果的marco-F1值较原始数据提高了5个百分点,但除情绪happiness外其他各类的精确率均大幅高于召回率,表明在此数据分布下漏报率依旧较高.因此,后文主要针对SVM分析在样本空间重构算法中不同参数对实验结果的影响. 图5 NB基于sampleSet1的实验结果Fig.5 Experimental results with NB in sampleSet1 图6 SVM基于sampleSet1的实验结果Fig.6 Experimental results with SVM in sampleSet1 图7 样本空间重构算法参数的选择Fig.7 Selection of parameters for sample space reconstruction algorithm 以情绪anger为例,介绍参数选择的过程.如图7所示,横轴表示不同的样本空间,1-0.8分别表示算法2的参数t和δ.将训练集sampleSet1中除情绪anger外的各类数据按t=1和δ=0.8调用算法2后的得到新的训练集,F1值和召回率均有提升,但精确率大幅下降.按同样概率进行二次迭代,召回率有微小提升,再次缩减负样本召回率显著提高而精确率随之降低,F1值也开始下降,说明样本缩减过多.因此,以F1值为主要参考指标,对情绪anger的最优样本空间本文取t=2、δ=0.8.类比此过程,本文最终选出原始数据、sampleSet1以及分别对应四类情绪的happiness(1-1)、sadness(1-0.5)、anger(2-0.8)、fear(1-1)共计六种样本空间(情绪surprise在训练集sampleSet1的表现效果最好). 为验证模型的有效性,本文共设计两组对比实验:MF-CSEL模型同未改进文本向量学习方法和简单平衡数据集后的实验分类结果对比,验证含有序列信息的文本向量和代价敏感学习方法对实验结果的影响;同nlpcc2018评测任务Emotion detection in code-switching text的结果做对比,验证本文方法的有效性. 表5 MF-CSEL模型实验结果 类别PRFHappiness0.6590.7960.726Sadness0.4900.5330.510Anger0.5440.4520.493Fear0.1720.3270.225Surprise0.4920.3260.392Macro-F10.469 MF-CSEL模型的实验结果如表5所示.表6为文本向量wvc取词向量的均值,以及简单减少无情绪样本平衡数据集后的实验结果,对比可知,在改进文档向量的学习方法和使用代价敏感学习方法后,分类结果得到了有效改善,各情绪的F值和整体Macro-F1值都有了大幅提升,表明本文多语言文本情绪分析模型的有效性,含有序列信息的文本向量和代价敏感学习方法在一定程度上提升了模型的分类效果,但情绪fear的精确率、F1值依然较低,一方面是由于样本数目差别过大,另一方面说明对该类情绪文本,情感特征的学习仍有待提升. 表6 对比模型实验结果 类别PRFHappiness0.6800.6950.687Sadness0.6900.3340.450Anger0.4770.3310.390Fear0.1650.3270.219Surprise0.3700.3260.347Macro-F10.419 将本文方法同NLPCC2018的评测结果对比,如图8所示,横轴表示类别,纵轴表示各类的F1值.其中,average-result为评测的平均成绩,zzuhhjx为本文团队在评测中提交的结果,DUTIR_938为评测第二名成绩,DeepIntell为评测最优成绩.本文改进特征工作和使用代价敏感集成方法后,实验结果较zzuhhjx在各类F1值上均有所提升,marco-F1值提升5.1个百分点,仅次于评测最优成绩,略高于评测第二名,各类情绪的F1值均明显优于评测中位成绩,表明本文方法具有有效性. 图8 对比实验结果Fig.8 Contrast experimental restults 本文分析了多语言文本情绪分析的研究现状,提出多语言文本情绪分析模型MF-CSEL,将基于多特征融合的代价敏感集成学习方法用于中英文混合文本情绪分类任务.本文基于CBOW模型训练词向量,将其序列化组合为带有语序信息的文本向量,融合双语情感特征、TF-IDF权值矩阵,使用基于语义相似度的样本空间重构算法平衡数据集,按照代价敏感集成策略融合基分类器的分类结果,实验结果表明本文方法具有有效性. 本文在多语言文本情绪分析上的研究仍存在许多不足需要进一步改进.从文中的实验结果可以看出,本文的marco-F1值虽略优于评测第二名成绩,但同评测最优还有一定差距.后续将进一步优化特征工作,在基分类器的选择上也可以做更多尝试,以达到提高情绪分类精度的效果.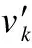


Table 3 Emotion classification result statistics table

4 实验结果与分析
4.1 数据集与评价指标
Table 4 Experimental data emotional distribution table
4.2 特征组合

4.3 样本空间重构算法参数的选择


4.4 对比实验
Table 5 MF-CSEL model experiment results
Table 6 Contrast model experiment results

5 结 论
猜你喜欢
现代电子技术(2022年15期)2022-07-28
新高考·高一数学(2022年3期)2022-04-28
电子产品世界(2022年4期)2022-04-21
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
计算机系统应用(2021年2期)2021-02-23
计算机测量与控制(2019年4期)2019-05-08
海峡姐妹(2017年12期)2018-01-31
语文世界(初中版)(2017年5期)2017-06-22
作文与考试·初中版(2017年12期)2017-04-19
高中生学习·高三版(2016年9期)2016-05-14
