
一种基于近邻传播聚类的语音端点检测方法
2019-05-08 06:25涂铮铮王庆伟郭玉堂
安徽大学学报(自然科学版) 2019年3期
林 琴,涂铮铮,王庆伟,郭玉堂
(1.合肥师范学院 计算机学院,安徽 合肥 230601;2.安徽大学 计算机科学与技术学院,安徽 合肥 230601;3.安徽威泰智能科技有限公司,安徽 合肥 230088)
语音端点检测[1](voice activity detection,简称VAD)是指从一段包含语音的信号中检测出语音的起始点和结束点的技术,可以把有声段和无声段分开.该技术主要应用于语音识别、说话人识别、语音编码、声音检测等领域[2].在实验室环境下,大多数的端点检测算法效果比较好.但是在真实环境下,语音信号伴有各种各样的噪声,常用的端点检测算法的性能都受影响.VAD方法可分为两类,一类是基于数字信号的时频域提取特征参数算法,另一类是基于模型的算法.基于双门限的时域端点检测[3]是指基于数字信号的短时能量和短时过零率对语音信号和噪声信号进行区分,在简单噪声下能获取不错的效果,但在复杂噪声下效果不理想.基于频域算法如基于线性预测编码[4](linear predictive coding,简称LPC)的欧氏距离测量,是指根据频率特性以及LPC度量能有效区分无音段、语音段和静默音.基于谱熵端点检测[5]是通过信息熵和语音特征相结合进行端点检测.这些算法在简单场景能获取不错的效果,但在低信噪比复杂场景下则效果不佳.基于模型的VAD[6-7]相对比较复杂,它是利用语音的统计特性对有效语音、静音、噪音等建模,比较测试语音在各种模型上的得分实现分类.这种方法在效果上要优于能量VAD,但是需要大量的人工标注过的数据进行训练,并且在测试语音和训练语音信道不匹配时,可能会影响测试效果.近年来,基于深度学习的模型VAD方法[8-9]引起广泛关注,但是基于深度学习的方法同样需要大量的训练样本,对于小样本问题并不适用.
针对上述问题,作者提出了一种基于近邻传播(affinity propagation, 简称AP)聚类的语音端点检测方法,在能量VAD的基础上,采用AP聚类,实现自动判断类别数,自动将有语义的有效语音以及远场噪声、笑声、哭声、无效静音段等聚类分开,通过结合传统能量、过零率和基频等特征[10]的后处理,得到真正的有效语音段.该方法用于声纹确认和声音检测,二者在检测效果上均得到了明显的提升.
1 AP聚类算法
AP聚类算法是一种基于信息传播的有效聚类方法[11].AP聚类算法首先将所有的样本点均作为可能的聚类中心,然后通过样本点在其近邻之间的信息不断传递,迭代搜索合适的作为聚类中心的样本点,并将所有其他的样本点分配到搜索出的这些聚类中心.AP聚类算法相比其他聚类算法具备如下优点:不需要事先指定聚类类别数目、最终聚类结果对初始的设定不敏感、对样本直接的相似度计算无对称性要求.
1.1 算法原理
AP聚类算法的核心[12-13]为通过信息的传递来迭代搜索合适的类中心样本点.该节将对信息传递过程中所涉及的相似度矩阵、吸引度(responsibility)矩阵和归属度(availability)矩阵3个核心概念进行介绍.
相似度矩阵即表示所有样本点的相似度程度.矩阵中s(i,k)表示第i个样本点和第k个样本点之间的相似度.在AP聚类算法中通常使用负的欧氏距离来表示相似度
s(i,k)=-‖xi-xk‖2,
(1)
其中:xi和xk表示第i个样本点和第k个样本点的特征向量.
在AP聚类算法中,将相似度矩阵中的对角线元素s(k,k)(k=1,…,n)单独赋值,称之为参考度P(preference),其值的大小表示当前点被作为聚类中心的概率大小.算法初始阶段假设不同样本点作为聚类中心的概率相同,一般将所有样本的参考度P设置成相似度矩阵中的最小值或者中位数,它的设置也影响了最终聚类的类别数目,参考度设置的越大,最终聚类类别的数目就越多.
将吸引度矩阵和归属度矩阵分别定义为R=[r(i,k)]和A=[a(i,k)].其中:吸引度r(i,k)表示样本点k作为样本点i的聚类中心的合适程度,即样本点k相比其他样本点作为样本点i的聚类中心的优势;归属度a(i,k)表示样本点i选择样本点k作为聚类中心的合适程度.吸引度和归属度的关系如图1所示.归属度在初始化阶段全部初始化为0,然后吸引度矩阵和归属度矩阵的计算交替进行,从而达到信息交替更新的目的.

图1 吸引度和归属度关系示意图
吸引度矩阵的计算公式为
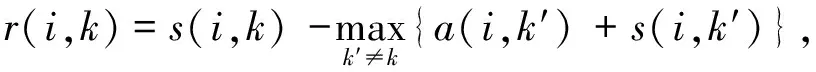
(2)
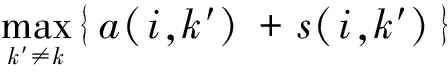
归属度矩阵的计算公式为
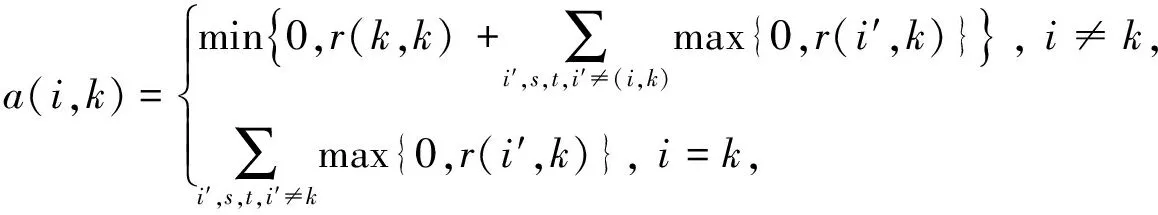
(3)
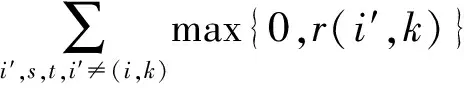
a(i,i)+r(i,i)>0.
(4)
其次,对于未选择作为聚类中心的样本点i的聚类中心,有
k:argmaxk(a(i,k)+r(i,k)).
(5)
在吸引度矩阵和归属度矩阵交替更新过程中,为了避免更新造成的震荡以及为了加速收敛速度,引入阻尼因子λ,则对吸引度矩阵和归属度矩阵的加权更新过程为
Rt=(1-λ)×Rt+λ×Rt-1,
(6)
At=(1-λ)×At+λ×At-1,
(7)
其中:Rt-1和At-1表示上一次迭代的吸引度矩阵和归属度矩阵值.λ∈[0,1).λ越大,矩阵的每次更新值越小;λ很小时,更新较快,易出现震荡[14].
1.2 算法流程
AP算法的具体实现流程如图2所示.具体步骤如下:
步骤1 计算待聚类数据点集X={x1,x2,…,xn}的相似度矩阵S,确定参考度P值,一般取相似度矩阵的中位数或者最小值;将归属度矩阵元素初始化为0.
步骤2 根据公式(2),(3)依次计算当前吸引度矩阵R和归属度矩阵A.
步骤3 引入阻尼系数λ,根据公式(6),(7)更新吸引度矩阵和归属度矩阵,其中,λ0<λ<1越大,消除的震荡效果越好,但会减缓算法的收敛速度(默认值是0.5).
步骤4 根据公式(4),(5)分别确定聚类的中心以及所有样本点的类别.
步骤5 当聚类结果稳定或达到最大迭代次数,则终止迭代过程.
搭建了一种基于AP聚类的端点检测方法,具体流程如图3所示.

图2 AP聚类算法流程图图3 AP聚类的端点检测流程图
2 实验结果与分析
2.1 实验过程与数据配置
首先,输入原始语音,基于能量VAD将语音分段并除去静音帧;其次,进行AP聚类,将有语义的有效语音以及远场噪声、笑声、哭声、无效静音段和人声等聚类分开,形成这些类的分段数据;再次,结合能量、过零率和基频后处理进行有效语音的判断;最后,将判断成有效语音输出,送入到声纹确认和声音检测等系统进行效果验证.
实验采用的数据为电话信道下的移动客服数据,均为正常的电话通话数据,信噪比较高,且为分录语音(主被叫在不同语音数据中),一共含有400个说话人,每个说话人10条通话语音(6条作为声纹实验的注册语音,4条为测试语音),语音时长均在1 min以上.所有数据均经过语音段标注、说话人标注、声音类型标注及文本标注,可进行VAD、声音确认、声音检测实验,通过对几种不同方案下的实验结果进行分析,来确认最优的VAD方法.
2.2 不同检测方法在声音确认、声音检测的比较
基线系统采用传统的能量VAD[15]和基于深度神经网络(deep neural networks,简称DNN)的模型VAD.新系统采用上文介绍的基于AP聚类的VAD以及该方法和DNN模型VAD融合后的系统.DNN-VAD模型未使用与实验数据相匹配的数据训练.在上述移动数据集中实验不同的VAD系统,结果如表1所示.该实验所用指标为有效语音片段的漏警率和虚警率,其中
漏警率=未识别成有效语音段的有效语音段数/总的有效语音段数.
虚警率=识别成有效语音段的无效语音段数/总的无效语音段数.

表1 不同端点检测方法的实验结果
根据表1的实验结果,对AP聚类+DNN VAD形成的噪声、哭声、人声、无效静音和音乐等不同信息的分段数据取最优,如图4所示.

图4 语音VAD信息分布图
基线系统采用基于总变(total variability,简称TV)空间的因子分析系统,数据为实验数据配置中的400个说话人数据,其中:目标人50人,每个人包含注册语音6条和测试语音4条;非目标人350条,注册语音为6条.在对目标人A进行实验时,A的测试语音为正例,其他均为反例.该实验所用指标为等错误率[16](equal error rate,简称EER),EER即调整阈值使得虚警率与漏警率相等时的数值,其中
漏警率 = 识别成反例的正例数据 / 总的正例数据.
虚警率 = 识别成正例的反例数据 / 总的反例数量.
根据上述数据进行实验,结果如表2所示.绘制出随着阈值变化而变化的检测错误权衡图(detection error tradeoff,简称DET),如图5所示.可以明显看出红色曲线的能量VAD总体趋势的EER得分较高,中间两条曲线DNN VAD和AP聚类VAD曲线变化几乎不大,而AP聚类+DNN VAD的EER得分最低,效果最好.
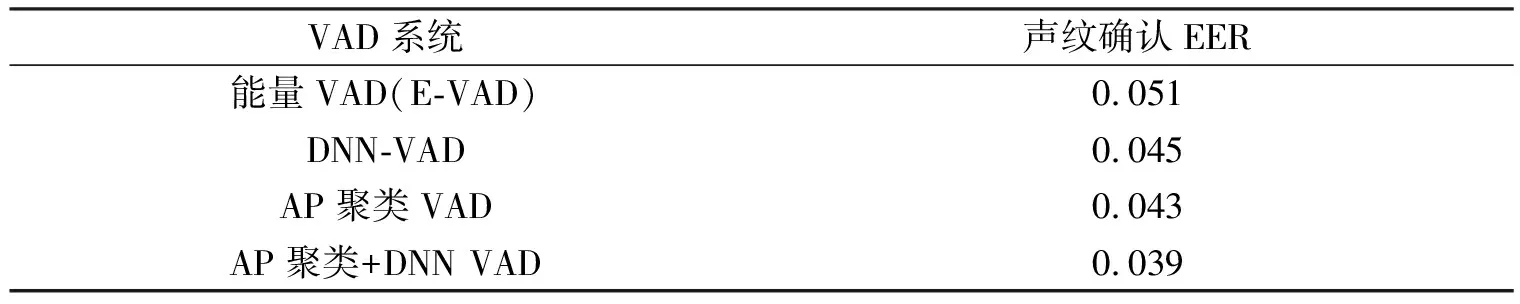
表2 不同端点检测方法的声纹确认结果

图5 DET曲线
声音检测即检测出一个VAD段中声音的类型,类型包括远场噪声、笑声、哭声、无效静音、有效语音等.该实验所用的技术路线是基于因子分析方案提取因子,然后将因子作为特征训练支持向量机(support vector machine,简称SVM)[17]系统,所用指标为声音检测的正确率和召回率.在上述4 000条语音中进行实验,结果如表3所示.

表3 不同端点检测方法的声音检测结果
由上述实验结果可分析,AP聚类VAD在声纹检测的正确率及召回率方面,相比能量VAD和DNN-VAD都有提升,其与DNN-VAD融合方案,取得最佳效果.
3 结束语
提出一种基于AP聚类的语音端点检测方案.该方案相比传统的能量VAD方案,有效语音检出更加准确.与通用的DNN模型VAD方案融合,得到了较好的效果.基于AP聚类得到的各类数据,能够有效用于后续的声纹确认、声音检测等系统,为下一步研究提供了良好基础.如何提取更有推广性的特征,如结合通用的语音增强的深度神经网络、提取Bottleneck特征、进行AP聚类等,是下一步研究的重点.
猜你喜欢
数学物理学报(2022年2期)2022-04-26
中学生数理化·教与学(2019年8期)2019-09-18
阅读(快乐英语高年级)(2019年5期)2019-09-10
电子制作(2019年14期)2019-08-20
电子制作(2019年9期)2019-05-30
小说界(2018年5期)2018-11-26
通信产业报(2018年32期)2018-11-24
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
浙江大学学报(工学版)(2015年1期)2015-03-01
祝您健康(2009年4期)2009-04-08
