
文本解析技术及其在法律实践中的应用*
2019-05-06 07:54:06邱昭继
中国法律评论 2019年2期
邱昭继
内容提要:文本解析技术的突破与IBM的“沃森”和“辩论者”程序的研发团队的努力密不可分。“沃森”基于文本的信息提取技术展现了不同凡响的问答本领,“辩论者”已经学会了论证挖掘。深度问答、信息提取和论证挖掘这些技术用更一般性的术语讲就是文本解析。人工智能与法律研究者和技术专家将文本解析与法律推理和法律论证的计算模型整合在一起,创建了一些新的法律应用程序。这些法律应用程序不仅仅是将法律人的处理过程计算机化和标准流程化,更是创造性地处理了一些法律人过去无法完成的任务。文本解析技术的迅速发展将深刻地改变法律实践、法律职业、法律教育和法学研究。
引言
2011年2月,由戴维·费鲁奇(David Ferrucci)领导的IBM研发团队开发的认知计算系统“沃森”(Watson)参加了美国著名智力问答竞赛电视节目“危险边缘!”(Jeopardy!)。该节目以一种独特的问答形式进行:它以答案形式提供各种线索,参赛者以问题的形式做出简短回答。问题设置非常广泛,参赛者需具备历史、文学、艺术、流行文化、科技、地理、政治、体育等多方面知识,还需要理解隐语、反讽等表述方式。“沃森”在节目中表现神勇,一举击败了连胜纪录保持者肯·詹宁斯(Ken Jennings)和最高奖金得主布拉德·鲁特尔(Brad Rutter)。这是IBM历史上继“深蓝”计算机于1997年打败国际象棋卫冕世界冠军加里·卡斯帕罗夫(Gary Kasparov)后,又一次成功地挑战人类。“沃森”在节目中能够回答微妙、复杂、语义双关的问题,这开启了认知计算的新纪元,也标志着人工智能寒冬的终结。1Dr. John E. Kelly III:《认知计算和我们的未来——人类和机器如何锻造认知新时代》,载 IBM商业价值研究院:《认知计算与人工智能》,东方出版社2016年版,第7页。2014年春季,IBM研究院总监约翰·凯利三世在米尔肯研究所年度会议上演示了“辩论者”(Debater)程序。“辩论者”是IBM公司研发出来的新的人工智能项目,它使用“沃森”程序的一些文本处理技术来执行论证挖掘。
文本解析技术的突破与IBM的“沃森”和“辩论者”程序的研发团队的努力密不可分。“沃森”基于文本的信息提取技术展现了不同凡响的问答本领,“辩论者”已经学会了论证挖掘。深度问答、信息提取和论证挖掘这些技术用更一般性的术语讲就是文本解析。“文本解析也称为文本挖掘,是从文本数据中获得高质量和可操作信息和见解所遵循的方法和过程。这涉及使用自然语言处理、信息检索和机器学习从语法上把非结构化文本数据解析成更结构化的形式,并从这些数据中提取出对终端用户有帮助的模式和洞见。”2[印度]迪潘简·撒卡尔:《Python文本分析》,闫龙川、高德荃、李君婷译,机械工业出版社2018年版,第35页。该书的译者将“text analytics”翻译成“文本分析”,我将这个概念翻译成“文本解析”。当被解析的文本是法律时,人们将其称之为法律文本解析。3Kevin D. Ashley, Artificial Intelligence and Legal Analytics: New Tools for Law Practice in the Digital Age, Cambridge University Press, 2017, p. 5.法律文本解析(legal text analytics)又称之为法律文本挖掘(legal text mining),是指“使用语言的统计的和机器学习的技术自动发现法律文本数据档案中的知识”。4Kevin D. Ashley, Artificial Intelligence and Legal Analytics: New Tools for Law Practice in the Digital Age, Cambridge University Press, 2017, p. 397.法律文本解析简称为法律解析。深度问答、信息提取和论证挖掘成为了法律文本解析的核心技术。
“沃森”和“辩论者”程序虽然不会进行法律推理和法律论证,但它们为法律推理和论证的计算模型提供了文本解析技术。两位有远见的作者呼吁法律界认真对待“沃森”技术对未来法律实践的影响。他们指出,“沃森”是应用于法律的最重要的技术,“沃森”改变了人们对于法律知识结构的理解,降低了法律成本,促进了法律信息和数据的组织管理,给年轻律师提供了更多的出人头地的机会,给法律教学带来了全新的挑战,让法学与工程学科的交叉融合提供了可能性,等等。5Paul Lippe and Daniel Martin Katz, "10 predictions about how IBM's Watson will impact the legal profession", October 2, 2014, 载http://www.abajournal.com/legalrebels/article/10_predictions_about_how_ibms_watson_will_impact,2018年10月8日访问。法律文本解析是人工智能时代广泛应用于法律实践的一项新技术。本文试图对法律文本解析及其在法律实践中的应用问题做一番初步的探讨。本文将逐一阐述深度问答、信息提取和论证挖掘技术及其在法律实践中的应用情况。
*本文是国家社会科学基金项目“司法裁判过程中的人工智能应用研究”(项目编辑18BFX008)阶段性成果。
**邱昭继,西北政法大学教授,法学理论教研室主任。
一、深度问答技术及其在法律中的应用
深度问答技术是IBM“沃森”的核心技术。“沃森”是基于自然语言处理、机器学习和高级数据解析的高级问答系统。2011年2月,在美国电视节目“危险边缘!”游戏中,“沃森”“在回答问题时能够搜索其巨大的资料库,并判断预估答案的可信度,当对答案有充分把握时,抢先于人类按动了抢答器”,6[美]约翰·E. 凯利、史蒂夫·哈姆:《机器智能》,马隽译,中信出版社2016年版,第3—4页。从而一战成名。
(一)IBM沃森的深度问答
为了在“危险边缘!”游戏中获胜,IBM组建了一支由二十多位科学家组成的核心研发团队,这些科学家是自然语言处理、信息检索、知识表示、自动推理、机器学习和高性能计算等领域的顶尖专家。他们经过五年多时间的研究和开发,实现了技术的突破。“沃森”是作为一个问答计算系统创建的。研发者为“沃森”创造了一种叫做深度问答的学习能力系统。深度问答技术包括问题解析和分类、问题分解、自动源获取与评价、实体和关系检测、逻辑形式生成、知识表达和推断等内容。“沃森”将机器学习提升到了一个新高度。对于每一个问题,“沃森”学习如何从数据库的数百万个文本中提取问题的候选答案,学习使其能够识别该类问题的答案的各种证据,学习与文本相连的各种证据的可信度。研发者“训练沃森识别各类信息,如名人、地点和关系,同时也解析语言。之后,他们又设计了一套统计方法,用来学习不同语境中词语的使用情况。这种技术组合使“沃森”从数据中学习,而不是仅仅按照指示工作。从某种意义上说,“沃森”将学习人类的学习方式,接触大量的事情并从中得出推论并习得经验”。7同上注,第36—37页。深度问答架构将自动问答问题视为大规模平行假设生成和评价任务。深度问答的结果不仅仅是提问与回答,而且是一个执行不同诊断的系统。这个系统基于各种数据收集、分析和评估每个结果的置信水平。通过问题、主题、案例或一组相关问题,深度问答在输入语言中找到重要的概念及其关系,构建用户信息需求的表示,然后通过搜索生成许多可能的回应。对于每个可能的回应,它产生独立和竞争的线索,这些线索从结构化和非结构化数据中收集、评估和组合不同类型的证据。它可以提供排序的回应列表,每个回应都与证据配置文件相关联,该证据配置文件描述了深度问答内部算法是如何对支持证据进行加权的。8参见IBM“沃森”研究团队关于深度问答架构的描述,载https://researcher.watson.ibm.com/researcher/view_group_subpage.php?id=2159,2018年10月3日访问。深度问答软件架构是根据非结构化信息管理架构(Unstructured Information Management Architecture,UIMA)标准建立的。UIMA是一个用于问答系统的开源阿帕奇(Apache)框架,在这个架构中文本注释器被组织到文本处理管道,将语义分配给文本区域。
通过自然语言处理和各种结构化和非结构化数据源组合,“沃森”拥有理解复杂上下文的能力。它可以“读”文本、“看”图像、“听”自然语言,它解读那些信息,提取信息并对信息进行标记和注释,同时伴有推论和推理过程,提供候选答案并对它们成为一个正确答案的可能性进行评估和排名。其实,“沃森”并不真正“知道”答案。“沃森”也会犯错。在第一天的比赛将结束时,“危险边缘!”游戏的终局节目是“美国城市,分值400美元”。答案是“它最大的机场以第二次世界大战的英雄命名;它第二大的机场以第二次世界大战的一场战役命名。”沃森给出的答案是“多伦多是什么?????”,正确的答案是“芝加哥是什么?”芝加哥的第一大机场是以“二战”英雄海军王牌少校指挥官爱德华·亨利·布奇·奥黑尔(Edward Henry “Butch” O’ Hare)的名字命名的,第二大机场中途机场(Midway Airport)是以“二战”著名的太平洋海战命名的。稍有常识的人都知道多伦多是加拿大城市,不是美国城市。“沃森”困惑于这个问题的原因有很多,在美国确实有一些叫多伦多的城市,比如伊利诺伊州的多伦多、印第安纳州的多伦多,并且加拿大的多伦多蓝鸟队的确参加美国棒球联盟的比赛。结果,“沃森”的置信水平非常低,只有14%,正如5个问号所示,它对答案没有信心。然而,“沃森”能够从错误中学习,通过大规模机器学习,“沃森”能从训练和运用中不断改善。9参见Dr. John E. Kelly III:《认知计算和我们的未来——人类和机器如何锻造认知新时代》,载 IBM商业价值研究院:《认知计算与人工智能》,东方出版社2016年版,第9—10页。
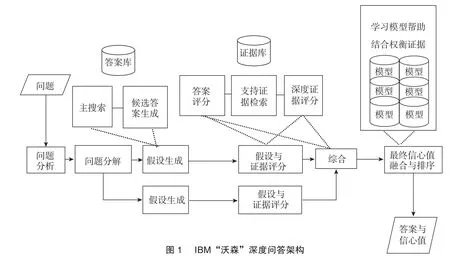
图1 IBM“沃森”深度问答架构
(二)深度问答技术在法律中的应用
“沃森”和“辩论者”程序虽然不会进行法律推理和法律论证,但它们为法律推理和论证的计算模型提供了文本解析技术。IBM试图将“沃森”的深度问答技术应用于法律领域。“沃森”的基本任务是回答问题。法律问答可以让法律知识更容易获得。IBM的总法律顾问罗伯特·韦伯(Robert Weber)指出,深度问答技术能在几毫秒内解析数亿页内容并挖掘它们以获取事实和结论。虽然深度问答技术不会取代律师,但它让律师如虎添翼。这项技术将在两个方面派上用场:收集事实和建构法律论证时识别观点。这项技术甚至可以在法庭上近乎实时地发挥作用。如果证人说某些似乎不可信的内容,律师现场就能检查其准确性。10参见Robert C. Weber, "Why 'Watson' matters to lawyers", The National Law Journal, Feb. 18, 2011, https://www.law.com/nation allawjournal/almID/1202481662966/,2018年8月25日访问。
阿什利想象了一个“法律危险边缘!”游戏。主持人透露类别是“体育法”。答案是“美国棒球联盟球队在经济罢工期间不能合法雇用替补球员”。“沃森”抢答道:“多伦多蓝鸟队是什么?”主持人宣布:“答案正确!多伦多蓝鸟队在经济罢工期间不能雇佣替补工人。”“沃森”回答这个问题的方式不同于法律人。法律人首先想到的是美国棒球联盟球队所在国家和州的劳动法规定,看看这些法律规定是否禁止球队在经济罢工期间雇用替补球员。然而,“沃森”不知道多伦多的位置或所属国家也能正确地回答问题。“沃森”是依赖语料库中的信息提取答案。根据1995年《福德姆国际法期刊》发表的《多伦多蓝鸟队的替补球员?——在加拿大安大略省替补工人法与美国替补工人法之间取得恰当的平衡》一文,美国的国家劳动关系法案允许美国的棒球队在球员罢工期间雇用替补球员,而多伦多蓝鸟队受加拿大安大略省劳动法的约束,根据安大略省的劳动关系法案,多伦多蓝鸟队在球员罢工期间不能雇佣替补球员。11Jordan Lippner, "Replacement players for the Toronto Blue Jays? Striking the appropriate balance between replacement worker law in Ontario, Canada, and the United States", Fordham International Law Journal, 1995 (38), pp.2026-2029.只要“沃森”的语料库中包含这篇文章,稍加训练的“沃森”就可以学会将其识别为与此类问题相关的信息,从中提取相关答案,并评估其对答案正确性的置信水平。“沃森”很可能无法解释它所提取的答案。解释答案需要人们理解与法律选择和法律主题相关的规则和概念,而“沃森”不掌握这些知识也不可能使用这些知识。经过适当训练的“沃森”可以学习识别相关问答对的证据类型,包括语义线索,如“合法雇用”“替代工人”“经济罢工”等概念和关系。在评估答案的置信水平时,“沃森”能够学习根据这些证据给予答案多大的权重。12参见Kevin D. Ashley, Artificial Intelligence and Legal Analytics: New Tools for Law Practice in the Digital Age, Cambridge University Press, 2017,pp. 17-18。
“沃森”的深度问答技术被广泛应用于法律市场。法律问答让法律知识的获取变得更容易。“法律上匝道”(Legal OnRamp)是一个使用IBM“沃森”解析合同的应用程序。公司的合同信息推动了大多数业务运营:收入确认、薪酬、服务和产品交付、风险评估、大量研发和知识产权资产创造。当重大的公司活动或交易发生时,公司都会聘请法律顾问审查合同。公司法律顾问希望能够轻松回答以下问题:哪些合同包括特定约定?哪些合同包括诸如对间接损失的免责声明?包含在合同正文而不是附录中的特定类型的约定针对的是哪些合同?使用普通的信息检索工具无法轻松可靠地回答此类问题。“法律上匝道”将合同提供给IBM“沃森”和其他机器学习工具,以自动回答法律问题并加快人工审查流程。由于“法律上匝道”直接与公司合作,因此它可以获得比任何律师事务所更多的合同。在回答问题时,“沃森”分解问题,从合同文本语料库中搜索候选答案,并根据每个候选答案解决问题的信心对候选答案进行排序。13Ibid., p. 27。
加拿大多伦多大学的学生团队创建的“罗斯”(Ross)是运用深度问答技术研发出来的法律应用程序,被称为法律领域的“沃森”。“罗斯”于2015年1月参加了IBM的“沃森”挑战竞赛并获得了第二名的好成绩。“罗斯”利用“沃森”提供的自然语言和认知计算平台的优势,以开发者云为基础向客户提供法律问答服务。他们给“罗斯”取了一个有趣的绰号——“遇见超级聪明的律师罗斯”。“罗斯”几乎模仿人类阅读过程,识别文本中的模式,并提供有关文档片段的语境化答案。“罗斯”接受以简明英语提出的问题,并根据制定法、判例法和其他法律渊源提供答案。比如,你问“罗斯”:“破产公司还能开展业务吗?”“罗斯”就会提供了一个带有引文的答案,并向你提供一些与该主题相关的读物。“罗斯”的演示视频列出了该程序可以处理的示例问题,包括:(1)加拿大公司需要保留哪些公司记录?(2)加拿大公司的董事可以加入一类股票的国家资本账户吗?(3)员工可以开展竞争业务吗?(4)如果员工没有达到销售目标并且无法完成他们的工作要领,他们可以在不事先通知的情况下被解聘吗?14Brian Jackson, "Meet Ross, the Watson-Powered 'Super Intelligent' Attorney". https://www.itbusiness.ca/news/meetross-the-watson-powered-super-intelligent-attorney/53376,2018年9月12日访问。在回答最后一个问题时,“罗斯”屏幕引用了加拿大的雷吉娜诉阿瑟斯案(Regina v.Arthurs,1967)以及该案的摘录和文本。“罗斯”对这个答案给出的置信水平为94%。“罗斯”总结道:如果一名员工犯了严重的不当行为,习惯性疏忽职守,无能,或与其职责不符,或者对雇主的业务造成损害,或者如果他有在实质上对雇主的命令故意不服从,法律承认雇主有权立即解雇不尽责的雇员。“罗斯”建议额外阅读关于“正当理由终止”的制定法、判例法、法律备忘录和其他渊源中的读物。“罗斯”具有从用户反馈中学习的能力。例如,“罗斯”在雷吉娜诉阿瑟斯案这个答案后跟着一个询问,如果答案是准确的,请用户按竖起的大拇指,如果答案是不准确的,请用户按朝下的大拇指。15Kevin D. Ashley, Artificial Intelligence and Legal Analytics: New Tools for Law Practice in the Digital Age, Cambridge University Press, 2017, pp. 351-352.反馈旨在告知“罗斯”这个答案的准确率,这也为“罗斯”更新答案提供信息。
“罗斯”具有四个方面的优势:(1)设计高度直观,易于使用,罗斯可以无缝地引入律师的工作流程;(2)通过尖端的人工智能技术,律师能够更智能、更快速、更流畅地工作;(3)通过大幅减少研究和流程准备所需的劳动时间来提高效率;(4)通过加快工作流程和提高效率,人们能够将时间和金钱花在高价值的咨询任务和复杂的法律事务上,从而提高盈利能力。16https://rossintelligence.com/,2018年9月15日访问。北美律师事务所按小时收费,平均每小时收取400美元的劳务报酬。由于北美律师收费高昂,许多法律文书工作外包给了印度等其他国家,这些国家的劳动力成本低,他们的律师收费低、服务质量也有保证。“罗斯”问世后法律行业将发生巨大的变化。律师事务所可以将许多工作交给“罗斯”去完成。“罗斯”大大地降低了法律服务的成本,也极大地提高了律师的效率、准确率和盈利能力。根据“罗斯”官网的统计,“罗斯”相比基于“布尔”的搜索节省了30.3%的时间,相比基于自然语言的搜索节省了22.3%的时间,让每位律师增加了13,067美元的年收入。17同上注。
二、从法律文本中自动提取信息
人工智能长期以来寻求从文本中识别和提取语义要素,如概念及其关系。计算机程序从法律文本中提取语义信息,并用它帮助人类解决法律问题。“信息提取是计算机从人类语言书写的文档中提取可识别的信息的行为。”18[美]Douglas Downing,Michael Covington, Melody Covington, Catherine Anne Barrett, Sharon Covington编:《巴朗行业词典—计算机与网络》,清华大学出版社2015年版,“信息提取”词条。典型的信息提取系统的内部工作过程主要包括五个步骤:(1)用一组信息模式描述感兴趣的信息;(2)对文本进行“适度的”词法、句法及语义分析,并作各种文本标引;(3)使用模式匹配方法识别指定的信息;(4)进行上下文关联、指代、引用等分析和推理,确定信息的最终形式;(5)输出结果,例如生成一个关系数据库或给出自然语句陈述等。19参见孙斌:《信息提取技术概述》(上),载《术语标准化与信息技术》2002年第3期。信息提取是从非结构化的机器可读文档中自动提取结构化信息的任务。自动提取信息是法律文本解析技术的一个重要特征。在法律专家系统中,专业知识体现在人类专家用于解决此类问题的规则中,这些规则通常由工程师在知识获取过程中手动构建。而在认知计算中,知识体现在文本语料库中,计算机程序从中提取候选解决方案或解决方案元素,并根据它们与问题的相关性对解决方案进行排序。计算机程序用于评估相关性的知识主要不是手动获取,而是通过使用机器学习从特定领域的数据集中提取模式而自动获取。20参见Kevin D. Ashley, Artificial Intelligence and Legal Analytics: New Tools for Law Practice in the Digital Age, Cambridge University Press, 2017, p. 13。从法律文本中自动提取信息的技术包括:帮助法律信息检索系统考虑意义,将机器学习应用于法律文本以及从法律法规和法律判决中自动提取语义信息等方面。21参见Kevin D. Ashley, Artificial Intelligence and Legal Analytics: New Tools for Law Practice in the Digital Age, Cambridge University Press, 2017, pp. 31-32。
(一)用机器学习从案例语料库中提取信息
机器学习是一种自动化分析模型构建的数据分析方法,它是人工智能的一个分支。机器学习算法可以从数据中学习、识别文本特征模式、总结模型中的模式并做出决策。根据学习方式的不同,机器学习分为监督学习、无监督学习和半监督学习。机器学习为从法律文本中提取信息提供了关键的技术支持。将机器学习应用于法律文本分为两个步骤。第一步是收集和处理原始数据,即自然语言法律文本的语料库。第二步是使用一些语言处理来转换原始文本数据,以标记、规范和注释文本,然后法律文档被表示为特征向量。法律文本中机器学习的目标是对文档进行分类或进行预测。在涉及法律案件的机器学习语境中,目标可能是通过句子在法律意见中发挥的功能对句子进行分类,例如,分为“法律决定或法律裁决”的句子或“基于证据的发现”的句子。在成文法条款的机器学习语境中,目标可能是按行政法、私法、环境法或刑法等主题对条款进行分类。22Ibid., pp. 236-237。
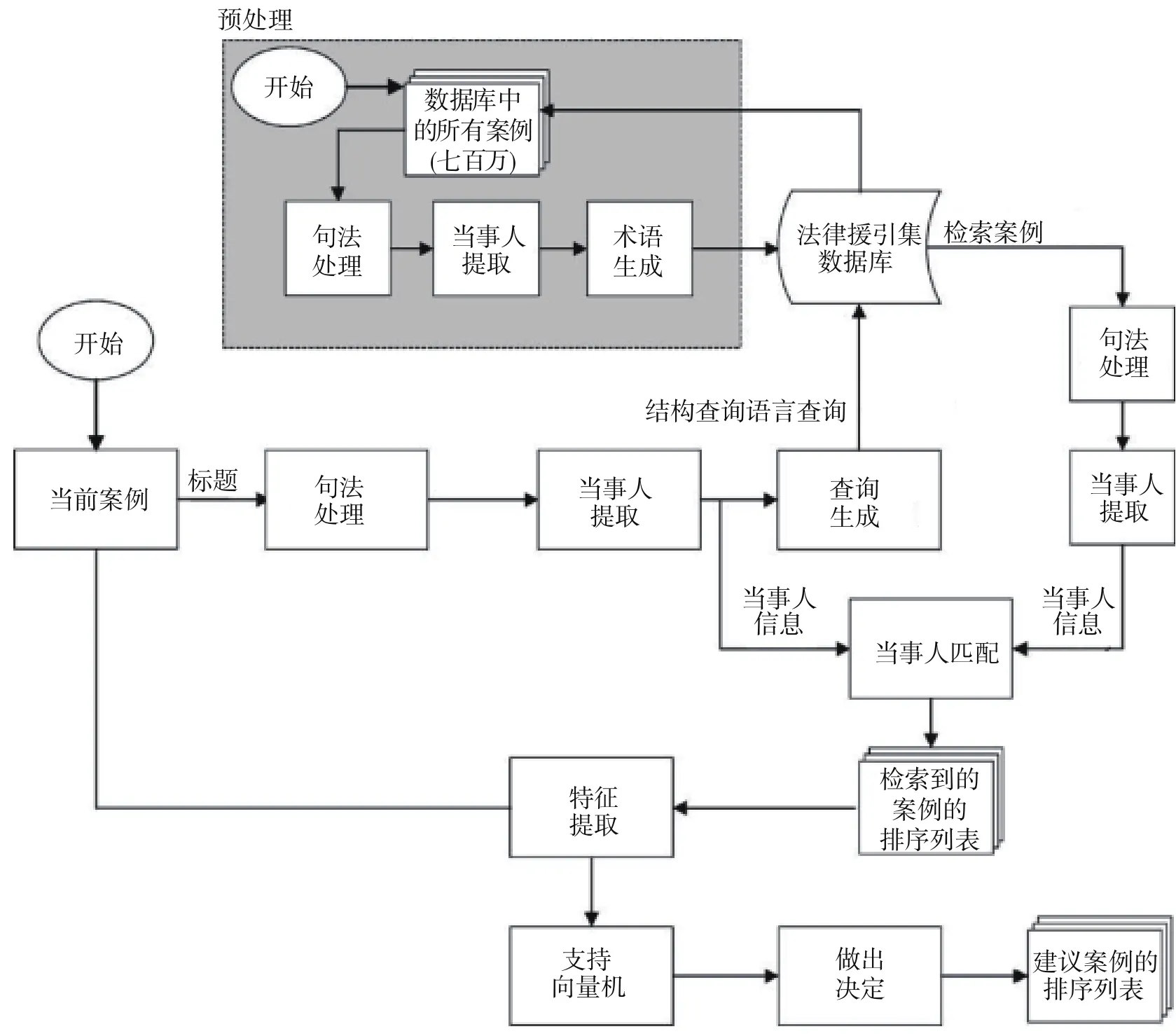
图2 先前案例检索系统的处理模块
“万律历史项目”(Westlaw History Project)是用机器学习从法律案件语料库中提取有用信息的典型系统。该系统“从法院意见中提取信息,并用这些信息建议新案件应当链接的先前案例”。23Peter Jackson, Khalid Al-Kofahi, Alex Tyrrell, and Arun Vachher,"Information extraction from case law and retrieval of prior cases", 150Artificial Intelligence 1-2 (2003), p. 240.先前案例检索识别当前案件中的历史语言影响的案例。所有案例都应以上诉链接(appellate chains)的形式与法律援引集数据库连接在一起。“历史项目”系统把来自文本语料库的信息提取、基于提取的信息的候选案例的信息检索以及基于机器学习的关于候选案例的判断结合在一起。如图2所示,先前案例检索系统的处理模块包括三个主要的组件:信息提取、信息检索和做出决定。信息提取组件处理法院意见及其首部,提取当事人姓名、法院、日期、案卷号和历史语言;信息检索组件生成查询,并把它们提交到法律援引数据集以检索先前案例的候选案例;决定做出组件采用机器学习算法决定哪个候选案例是当前案件的真正先例。24Ibid., pp.274-276.
标题匹配可以有效地减少候选先例的数量,并帮助候选先例的排序。但标题信息不足以确保好的结果。特征提取和表示模块从法院意见、案卷号、法院和历史语言中提取额外的信息。为了最佳地表示每个案例以达到机器学习的目的,每个候选案例用八个特征表示为特征向量。八个特征包括:(1)标题相似性特征,衡量当前案件的标题与候选先例标题的相似性;(2)历史语言特征,这是一个二进制标志,如果自然语言组件直接从当前案件报告中提取历史语言,则该特征赋值为“1”;(3)案卷号匹配特征,这是一个二进制特征,当且仅当当前案件和候选先例被分配了相同的案卷号,则该特征赋值为“1”;(4)检查上诉特征,根据在法院层级中法院之间的关系估计一个法院成为当前法院的先前法院的概率;(5)先前案例的概率特征,估计当前案件实际上具有一个先前案例的概率;(6)引用案例特征,这是一个二进制标志,当且仅当检索的先前候选案例在当前案件中被引时,这个特征赋值为“1”;(7)标题权重特征,估计当前案件标题中包含的信息;(8)AP1搜索特征,这是一个二进制标志,当且仅当先前案例的候选案例通过一个查询检索到并且这个查询是从当前案件的“上诉行”生成时,该特征赋值为“1”。25Ibid., pp.282-283.历史项目团队为了完成任务,采用监督学习并使用支持向量机作为机器学习算法。机器学习算法可以根据文本中的证据区分事实和法律讨论,并学会识别和区分法律案件段落的事实和讨论。
(二)从法律法规文本中自动提取信息
法律是指引和协调人的行为的社会规范。从普通公民到政府官员和法律职业人士都需要理解法律法规文本,了解法律规范的要求并按法律的要求行为。人工智能与法律研究长期以来致力于从电子化的法律法规文本中自动提取有关规范要求的信息。从法律法规文本中提取的信息可以用于自动法律推理和法律论证。自动提取信息技术可以通过各种方式支持认知计算。
从法律法规中提取的信息主要包括如下类型:(1)法律规范的功能类型,如禁止性法律规范、命令性法律规范和授权性法律规范;(2)与功能相关的特征,一些法律规范的功能类型将更具体的信息作为要素或参数,如义务或责任的承担者和受益人;(3)法律规范的逻辑构成,法律规范在逻辑上由“前提条件”、“行为模式”和“法律后果”三部分构成;(4)法律规范所属的部门法类型,如刑法、民法、行政法、环境法或劳动与社会保障法;(5)出现在法律词库或本体中的规章概念,如“欧盟合同”、“少数群体保护”和“渔业管理”。从法律法规文本中自动提取功能信息对于概念信息检索非常有用。
为了从法律法规文本中提取功能信息,意大利的人工智能与法律研究者设计了自动化方法。这种方法包括四个主要的模块:(1)交叉引用解析器,旨在检测交叉引用和建构相关的统一命名;(2)结构解析器,旨在自动化遗留内容的可扩展标记语言的网上规范转换;(3)条款自动分类器,根据条款的模式自动将段落分类为条款类型;(4)条款论证提取器,旨在自动提取条款论证。条款自动分类器能够自动检测立法文本中包含的条款类型。它主要由文本分类算法构成。条款自动分类器的输入是法律条款的文本段落,输出是从一组候选类别中选择的预测类型或条款类别。26E.Francesconi and A.Passerini, "Automatic classification of provisions in legislative texts", Artificial Intelligence and Law,2007 (15), pp. 6-7.条款论证提取器的输入是文本段落和预测类型,输出的是条款的功能信息和特征。下面举一例说明条款论证提取器的输入和输出。27Ibid., p.3.
输入:《意大利个人数据保护法典》第7条第1款规定:“打算处理属于本法案适用范围的个人数据的控制人必须通知其担保人。”
类型:义务
输出:系统提取功能信息:
特征:
接收者:“控制人”
行为:“注意”
对应方:“担保人”
被提取的功能信息可以作为元数据应用于语义标记中的条款。一旦此类信息纳入制定法条款的本体索引,人类用户就可以搜索所有分配“控制人”向“担保人”通知的义务的条款。研究者将机器学习和知识工程方法以互补的方式应用于法律条款。机器学习提取了更多抽象的功能类型,如“义务”。知识工程规则提取了更具体的角色扮演者,如被赋予义务的“控制人”。机器学习和知识工程方法各有优劣。机器学习方法手动注释训练实例,自动使用机器学习算法来生成区别于实例训练集的特征。这种方法更灵活,更少领域依赖,并且需要较少的专业知识,但需要足够大的手动注释训练实例集。知识工程方法为每种类型的条款确定清晰的易于观察的模式,并手动构建规则以识别新文本中的模式并提取相关信息。这种方法不要求手动注释的训练数据,但需要手动创建的专家分类规则来捕获与每类条款相关联的标准短语。28参见Kevin D. Ashley, Artificial Intelligence and Legal Analytics: New Tools for Law Practice in the Digital Age, Cambridge University Press, 2017, pp. 263-266。
三、论证挖掘技术及其在法律中的应用
论证挖掘(argument mining)是以语料库为基础的话语分析的新发展,包括自动识别话语的论证结构,例如前提、结论和每个论证的论证型式,以及文档中论证与子论证以及论证与反驳的关系。论证挖掘的成功要求自然语言技术、语义学、语用学、话语理论、人工智能、论证理论和论证的计算模型等学科提供的跨学科方法,还需要不同领域的不同类型的来源创建和注释高质量的论证语料库。29ACL-AMW, "3d Workshop on Argument Mining at the Association of Computational Linguistics" (ACL 2016). http://argmining2016.arg.tech/,2018年9月22日访问。
(一)IBM的“辩论者”
论证挖掘技术的发展与IBM“沃森”的兄弟项目“辩论者”(Debater)紧密地联系在一起。“辩论者”是IBM公司研发出来的新的人工智能项目,它使用“沃森”程序的一些文本处理技术来执行论证挖掘。“辩论者”不仅能从文本中提取信息,还能“理解”信息并运用它们进行推理。2014年春季,IBM研究院总监约翰·凯利三世在米尔肯研究所年度会议上演示了“辩论者”程序。演示的辩论主题为“向未成年人出售暴力视频游戏应该被禁止”。“辩论者”的任务是检测相关主张并返回对正方主张和反方主张的预测。“辩论者”以近乎完美的英语回应道:“扫描了400万篇维基百科文章,返回10篇最相关的文章,扫描了这10篇文章中的3000个句子,检测到包含候选主张的句子,确定了候选主张的边界,评估候选主张是支持正方还是反方,构建了一个具有最高主张预测的演示演讲,然后准备提交!”“辩论者”能够自动地从维基百科中提取信息,消化所提取的信息,并运用这些信息进行推理,然后用自然语言呈现它的论证。“辩论者”在视频中的输出是听觉的,可以用视觉术语呈现其输出的文本。图3顶部框包含论辩的命题。与实线相连的主张支持该命题,与虚线相连的主张攻击该命题。从输入主题到输出论证的时间是3—5分钟。值得注意的是,“辩论者”并不真正理解所提取内容,它只是在数据上运行算法并进行概率分析以得出结论。30George Dvorsky, "IBM's Watson Can Now Debate Its Opponents", 2014年5月5日, https://io9.gizmodo.com/ibms-wats on-can-now-debate-its-opponents-1571837847,2018年9月23日访问。
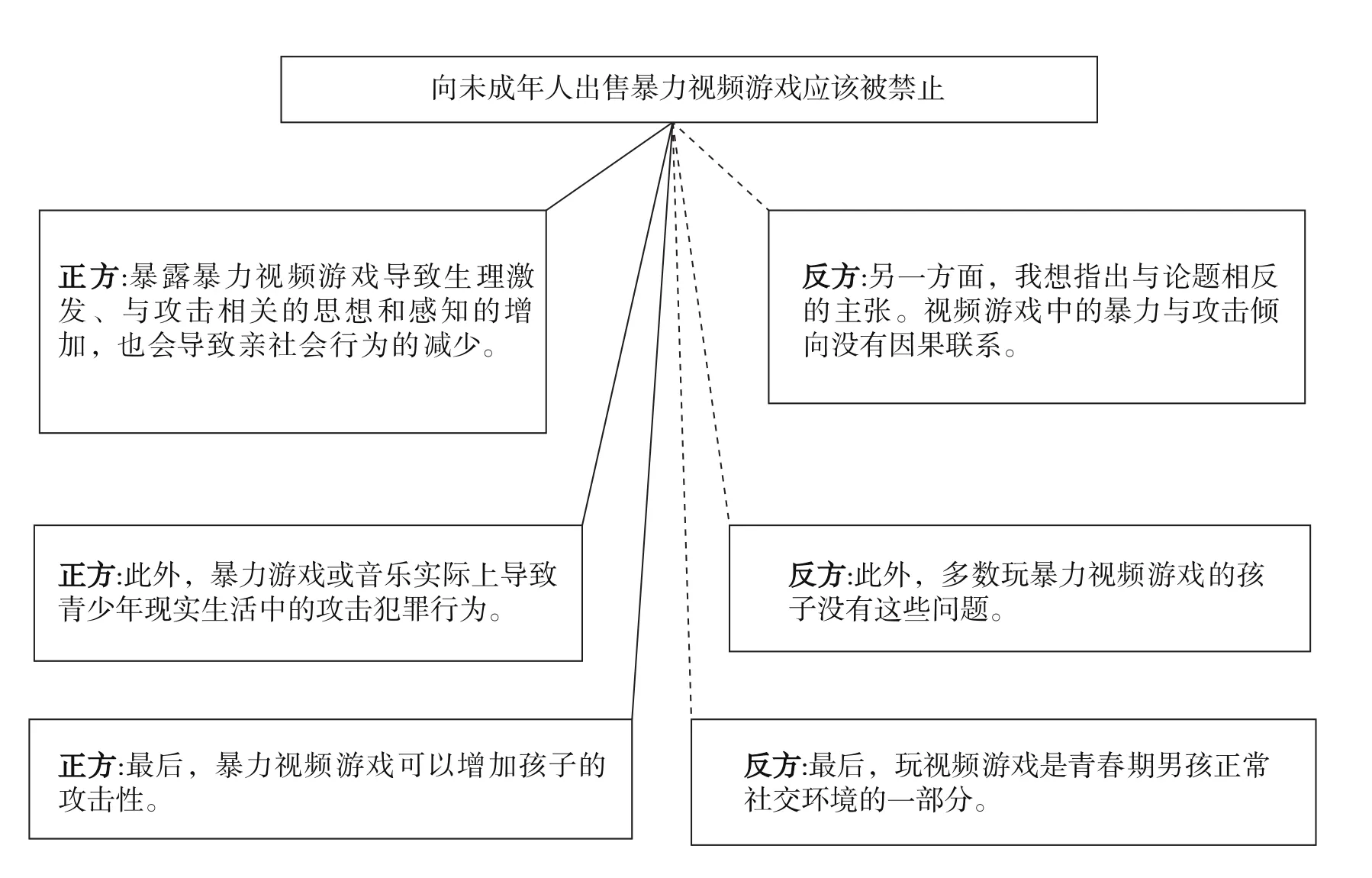
图3 IBM“辩论者”针对暴力视频游戏主题输出的论证 31
2018年6月18日,“辩论者”程序在旧金山IBM办公室举办的辩论赛中击败了人类顶尖辩手。它的对手是以色列国际辩论协会主席丹·扎菲尔(Dan Zafrir)和2016年以色列国家辩论冠军诺亚·奥瓦迪亚(Noa Ovadia)。这次辩论赛共分两场,以现场观众的感受判断输赢。两场辩论赛的题目分别是“我们是否应该资助太空探索”和“我们是否应该更多地使用远程医疗”。“辩论者”程序皆为正方。给定一个辩题后,“辩论者”程序迅速搜索其庞大的语料库,寻找最相关的证据,然后挑选最有说服力、多样性的论点,并安排论点来构建一个具有完整说服力的叙述,以此来支持或反对论点。32参见Lee:《人工智能如何参与辩论》,载《电脑报》2018年6月25日。
IBM“辩论者”团队开发了一种手动注释训练集的方法,以便机器学习可以从文本中提取信息。“辩论者”检测上下文的主张,直接支持或辩驳特定主题的一般性陈述,还检测依赖上下文的证据,在给定主题的语境中支持依赖上下文的主张的文本片段。在给定主题和相关文章的情况下,句子组件选择200个最佳句子,边界组件在每个句子中界定候选主张,排名组件根据句子和边界分数选择50个最佳候选主张。“辩论者”使用机器学习完成句子选择、边界设置和候选主张排名这三个步骤。“辩论者”的机器学习取决于人类注释者执行高质量的训练文档集注释的能力。注释者被要求将文本片段标记为依赖上下文的主张。“辩论者”团队开发了一种系统的方法来组织人工注释工作以最大化可靠性。33参见Kevin D. Ashley, Artificial Intelligence and Legal Analytics: New Tools for Law Practice in the Digital Age, Cambridge University Press, 2017, pp. 306-307。
论证挖掘技术已被用于法律文本解析。论证挖掘技术自动地识别案例文本中最终可用的与论证相关的信息,并随之产生法律实践中智能技术的新典范:基于论证相关信息的可靠的概念法律信息检索,也称为论证检索。34Ibid., p. 12。论证挖掘支持律师从法律文本中提取信息建构回答手头问题的论证。论证简单地说,就是举出理由以支持某种主张或判断。35参见颜厥安:《法与实践理性》,中国政法大学出版社2003年版,第88页。有关法律主张、判断、决定或裁判的证明或辩护就是法律论证。论证挖掘就是要识别和提取法律文本中与法律论证有关的信息。与法律论证相关的信息包括:法律论证的命题、前提或结论,连接前提与结论的论证型式和论证规则,陈述法律规则的句子,陈述案件事实的句子,影响论证强度的信息等。
(二)从案例文本中提取与论证相关的信息
使用机器学习、自然语言处理和提取规则从案例文本中提取与论证相关信息的项目有很多,比如莫查莱斯和莫恩斯研发的系统、智能索引学习(Smart Index Learner,SMILE)项目和法律领域的非结构化信息管理架构(Legal UIMA,LUIMA)系统。莫查莱斯和莫恩斯研发的系统在法律论证挖掘方面做出了开拓性的贡献,它确定了在论证中起作用的句子,应用机器学习将句子划分为命题、前提或结论。智能索引学习是基于问题的预测程序的自然语言界面,它充当问题的自然语言描述和预测案例结果的计算模型之间的桥梁。智能索引学习项目致力于识别和提取实质性法律因素和事实模式,它们加强或削弱一方的法律主张。非结构化信息管理架构是用于问答系统的开源阿帕奇架构,IBM“沃森”的技术就是建立在UIMA基础上的。36参见Kevin D. Ashley, Artificial Intelligence and Legal Analytics: New Tools for Law Practice in the Digital Age, Cambridge University Press, 2017, p. 287。LUIMA是应用于法律领域的以UIMA为基础的类型系统。它聚焦于概念、关系和提及,以识别司法裁判中句子的论证功能。LUIMA系统是一种非常成熟的法律文本解析技术,因而本文主要介绍LUIMA系统提取与论证相关的信息的方法。
LUIMA采用基于规则的注释器和机器学习注释器用语义信息注释案例文档。句子分割是注释案例文档的第一步。句子分割是将案例文本语料库分解成句子的过程。任何文本语料库都是文本的集合,其中每一段落都包含多个句子。执行句子分割有多种技术,基本技术包括在句子之间寻找特定的分隔符,例如句号(.)、换行符( )或者分号(;)。37参见[印度]迪潘简·撒卡尔:《Python文本分析》,闫龙川、高德荃、李君婷译,机械工业出版社2018年版,第80页。LUIMA注释还标记了一些预设信息,包括事实和语言概念以及与受规制领域相关的提及。LUIMA注释在案例文本中标识此类预设信息为:(1)术语,例如疫苗术语,疾病术语,因果关系术语。(2)提及,例如疫苗提及,其中包括疫苗首字母缩写与疫苗术语[“麻腮风(MMR)疫苗”],疫苗接种事件提及,因果关系提及。(3)规范化,疫苗提及的规范化,疾病提及的规范化,即句子中提到的疫苗或疾病的规范名称。38参见Kevin D. Ashley, Artificial Intelligence and Legal Analytics: New Tools for Law Practice in the Digital Age, Cambridge University Press, 2017, p. 302。基于规则的注释器根据提及和子句类型自动注释句子。如果一个句子包括提及原告、必须关系的术语(比如,证明),那就把这个句子注释为“法律标准表述”(Legal Standard Formulation)。在“根据该标准,请求人必须证明疫苗接种更可能是受到伤害的原因”这个句子中,包括“请求人”术语和“证明”术语,因而把这个句子注释为表示法律标准的句子。
LUIMA注释案例文档的另一种技术是机器学习。机器学习将案例文档的句子分为三类:法律规则句子,基于证据发现的句子,不属于这两类句子的句子(标记为“非注释”句子)。出于机器学习的目的,句子文本被表示为特征向量。每个特征向量的值是这个特征在文本中沿着特征维度的量。量可以是“0”,表示文档不具有该特征,或“1”表示它具有该特征。比如,在“罗珀诉卫生与公众服务部部长”一案中,“在本案的证词中,莱西博士进一步解释了他的观点,即破伤风疫苗接种可能导致请求人罗珀女士的胃轻瘫”被注释为证据句子,而不是基于证据发现的句子,因为它报告的不是法官做出的结论,而是专家证人莱西博士做出的结论。因此,机器学习注释器将这个句子表示为“非注释”句子。
LUIMA然后根据注释过的信息执行论证检索,即识别和提取与论证有关的信息。论证检索帮助人类用户建构支持一种主张的可行论证或反击对手的最佳论证。论证挖掘技术使法律推理和法律论证的计算模型能够直接处理法律数字文档,帮助人们预测和证成法律结果。在疫苗伤害赔偿的案例中,请求人必须证明疫苗接种更可能是受到伤害的原因。只有在疫苗接种导致伤害的情况下,请求人才能获得赔偿。因而必须确定疫苗接种与伤害之间存在因果关系。请求人必须通过优势证据确定:(1)疫苗类型与伤害类型之间有着“医学理论上的因果关系”;(2)特定疫苗接种与特定伤害之间存在“因果关系的逻辑顺序”;(3)疫苗接种和伤害之间存在“近似时间关系”。法律论证的计算模型将适用的制定法和规章要求表示为“规则树”,即权威性规则条件以及法律判决中的推理链,将证据断言与特殊法官对这些规则条件的事实发现联系起来。39Ibid., p. 161。
四、结语:法律文本解析对未来法治的影响
深度问答、信息提取和论证挖掘这些文本解析技术为法律实践带来了革命性的变化。IBM“沃森”、“辩论者”和UIMA等为这种变革种下了革命的种子。人工智能与法律研究者和技术专家将法律文本解析与计算模型整合在一起,创建了一些新的法律应用程序。这些法律应用程序能完成许多传统上只能由人完成的智能任务。法律应用程序在定制商品化法律服务中发挥重要作用。它能用法律文本推理,使实践系统能够根据人类用户的特定问题定制其输出。“法律应用程序不仅会以适合人类用户特定问题的方式选择、预订、突出和汇总信息,还会探索信息并以前所未有的新方式与数据互动。”40Kevin D. Ashley, Artificial Intelligence and Legal Analytics: New Tools for Law Practice in the Digital Age, Cambridge University Press, 2017, p. 13.法律文本解析技术产生时间较短,但在不到十年的时间里却涌现了六十余种成熟的法律应用程序。41Jonathan Marciano, "Automating the Law: A Landscape of AISolutions", Jun 10, 2017, 载https://www.topbots.com/automatingthe-law-a-landscape-of-legal-a-i-solutions/,2018年10月4日访问。代表性的法律应用程序包括美国的法律集中营(LegalZoom)、法律机器(Lex Machina)、法律机器人(Legal Robot)、拉威尔(Ravel)、既判力(Judicata)和法律过滤器(Legal sifter)、加拿大的织布解析(Loom Analytics)、英国的法律智能支持助理机器法律人(Robot Lawyer LISA)、以色列的LawGeex和爱尔兰的布赖特旗(Brightflag)等。这些新兴的法律应用程序不仅仅是将法律人的处理过程计算机化和标准流程化,而是创造性地处理一些法律人过去无法完成的任务。
法律文本解析或许是这个时候最重要的技术,它的迅速发展将深刻改变法律实践、法律职业、法律教育和法学研究。萨斯坎德(Susskind)指出,许多信息技术是颠覆性的,这些技术不支持或兼容传统的工作方式,它们将彻底挑战和改变传统习惯。对法律行业也是如此,这些无处不在、急速增长的信息技术会颠覆和改造律师和法院的运作方式。42[英]理查德·萨斯坎德:《法律人的明天会怎样?》,何广越译,北京大学出版社2015年版,第23页。数百年来,诉讼律师运用法律方法分析案件的事实构成,总结案件的争议焦点,寻找适用于手头案件的法律法规或判例,推理将事实涵摄于法律之下,最后提出诉讼策略并做出法律预测。法律文本解析颠覆了律师的工作方式,它将法律工作分解为不同的任务并逐项以尽可能高效的方式完成。诉讼律师的工作可以分解为文件审阅、法律研究、项目管理、诉讼支持、电子披露、策略、战术、谈判和法庭辩论等任务。这九项任务中除了策略、战术和法庭辩论,其他的重复性事务性的工作任务都可以用不同方式分包出去。43同上注,第41—42页。这些分包出去的工作都可以由法律应用程序而非法律人完成。法律文本解析挖掘案件文件和卷宗中的数据,然后汇总这些数据,从中发现一些有用的洞见,包括法官、律师、法院、律师事务所和当事人的各种信息。诉讼律师使用法律文本解析来揭示过去诉讼中的趋势和模式,然后根据这些趋势和模式制定手头案件的诉讼策略并预测法律结果。44Owen Byrd, "Legal Analytics vs. Legal Research: What's the Difference?" June 12, 2017,载https://www.lawtechnolog ytoday.org/2017/06/legal-analytics-vs-legal-research/,2018年8月21日访问。法官运用智能审判系统实现对起诉状、答辩状、庭审笔录等案件卷宗信息的智能解析和信息提取,提取各类卷宗材料文书所需的核心信息,然后自动生成判决、裁定等法律文书。法律文本解析技术在法律实践中的广泛应用将极大地节省律师和法官处理案件的时间,过去他们花上数周完成的工作现在几分钟就能完成。
法律职业也将因法律文本解析技术的应用而发生翻天覆地的改变。如果法律应用程序能够完成许多以前只能由法律职业者完成的工作,那么部分法律职业者将要失业。2013年9月,牛津大学的卡尔·弗瑞(Carl Frey)和迈克尔·奥斯本(Michael Osborne)发表了《就业的未来》研究报告,调查各项工作在未来二十年被计算机取代的可能性。根据他们研发的算法估计,到2033年,法律秘书有98%的概率会失业,律师助理的概率为94%,行政法官和听证官的概率为64%,书记员的概率为41%,法官和地方法官的概率为40%。45Carl Benedikt Frey and Michael A. Osborne, "The Future of Employment: How Susceptible Are Jobs to Computerisation?",17 September 2013, pp. 62-71. https://www.oxfordmartin.ox.ac.uk/downloads/academic/The_Future_of_Employment.pdf,2019年1月5日访问。又见[以色列]尤瓦尔·赫拉利:《未来简史》,林俊宏译,中信出版社2017年版,第293页。当然,淘汰传统的法律的工作的同时也会产生一些新的法律工作。根据萨斯坎德的总结,法律人的新工作包括法律知识工程师、法律技术专家、跨学科法律人才、法律流程分析师、法律项目管理师、在线纠纷解决师、法律管理咨询师和法律风险管理师。例如,法律知识工程师负责研发法律标准和流程,在计算机系统中组织和表达法律知识。法律技术专家是同时具备法律和系统工程及信息技术管理两个领域的训练和经验的专业人士。46[英]理查德·萨斯坎德:《法律人的明天会怎样?》,何广越译,北京大学出版社2015年版,第129—131页。这些新的法律职业人士从事的工作迥异于传统法律职业者所做的事情。
法律文本解析技术将改变法律教育的内容和教学方式。多年来,如何利用技术去讲授法律一直是一个法学界不关注的问题,现在漠视技术发展的时代将要终结。技术让法学教育变得更有效更实际提供了可能性。现如今,同步远程学习模式、非同步远程学习模式、大规模开放式网络课程、翻转课堂、在线教学、在线协作等创新技术已经广泛地应用于法学院的法律教育。47[美]米歇尔·皮斯托:《法学院与技术——我们现在何处并将驶向何方》,周亚玲译,邱昭继校,载王翰主编:《法学教育研究》第15卷,法律出版社2016年版,第259—272页。IBM“沃森”为法律教育开辟了新的可能性。法学院擅长的苏格拉底教学法将受到严重的挑战,老师在《合同法》课程中提出的各种问题都可以交由法律应用程序回答,在线课程将逐渐取代面授课程。法律人工作方式的改变对法律教育提出了新的要求。传统的法律教育以培养专业基础扎实、熟练掌握法律职业技能的法律人才为目标,未来的法律教育应根据法律实践的变化做出相应的调整。根据理查德·格拉纳特(Richard Granat)和马克·劳里森(Marc Lauritsen)的调查,美国有10所法学院非常重视法律文本解析技术,开设了多门相关课程或成立了相关的研究中心。比如,密歇根州立大学法学院建立了一个再造法律实验室,开设了电子发现、创业律师、法律信息工程与技术、法律解析、诉讼、数据、理论、实践、过程、律师定量分析和21世纪的法律实践等法律实践技术方面的课程。萨福克大学法学院建立了法律实践技术与创新研究所。法学院提供智能机器时代的律师培训、流程改进和法律项目管理、法律文件自动化和21世纪律师和决策支持系统的调查等课程。48Richard Granat and Marc Lauritsen, "Teaching the technology of practice: the 10 top schools", Law Practice Magazine,2014: (4) ,载www.americanbar.org/publications/law_practice_magazine/2014/july-august/teachingthe-technology-of-practicethe-10-top-schools.html. 2018年10月3日访问。
法律文本解析技术将导致法学研究产生相应的变化,它将促使法学与理工科的交叉融合。法学与哲学、社会学、政治学、人类学、经济学等哲学社会科学的紧密联系人们已经很熟悉了,而法律文本解析技术将法学与统计学、信息科学、计算机科学和脑科学等学科紧密地联系在一起。著名法学家霍姆斯早在120年前就预言:“对于法律的理性研究而言,研究历史文本的人或许是现在的主人,而未来的主人则属于研究统计学之人和经济学专家。”49[美]霍姆斯:《法律的道路》,载[美]霍姆斯:《法律的生命在于经验——霍姆斯法学文集》,明辉译,清华大学出版社2007年版,第221页。法律的经济学研究早在20世纪70年代就异军突起,成为法学界的显学。人们没有想到的是,统计学会成为法学研究的主导学科。人工智能时代,统计学的重要性越发凸显,人工智能法学的研究越来越需要统计学的支持。
法律文本解析技术方兴未艾,这是我国法治发展的重大战略机遇。法律文本解析技术在法律信息搜索、法律咨询、法律解释、证据收集、案例分析、法律文件阅读与分析、法律推理和法律论证等方面大有用武之地。它的应用是我国智慧法院、智慧检察院、智慧律所、智慧公安和人工智能法学院建设的重要抓手。
猜你喜欢
中学生数理化·高一版(2021年4期)2021-07-19 09:00:56
法律方法(2021年3期)2021-03-16 05:57:02
中国工业和信息化(2020年2期)2020-03-27 12:11:25
做人与处世(2018年14期)2018-08-10 08:33:36
语文世界(小学版)(2018年3期)2018-03-22 17:50:54
商周刊(2017年12期)2017-06-22 12:02:01
摄影之友(影像视觉)(2016年2期)2016-08-16 06:43:16
山东青年(2016年1期)2016-02-28 14:25:30
中国卫生(2015年1期)2015-11-16 01:05:56
浙江人大(2014年5期)2014-03-20 16:20:27
