
线性预测技术在AAC时域噪声整形模块中的应用
2019-05-05 08:38:36张洁
中国传媒大学学报(自然科学版) 2019年2期
张洁
(中国传媒大学 信息与通信工程学院,北京 100024)
1 引言
MPEG-4 AAC是MPEG-2 AAC之后推出的一种先进的音频信号编码标准,其最主要的特点为抗错能力强。它可用于12kHz或24kHz采样频率和20-24kbit音频。 通过MPEG-4 AAC和SBR(频带恢复技术)的结合使用,压缩比可以提高40%,同时保持音质,使其成为世界上最强大的压缩技术之一。在48kbit速率下,听者可以获得与原信号相同的主观音质。
MPEG-4 AAC采用模块化方法,由一系列模块构成完整的系统,并用标准化工具对各个模块进行定义,因此在文献中往往把“模块(modular)”与“工具(tool)”看作是等价,具体编码流程如图1所示。
MPEG-4 AAC中所处理的音频信号数据为每帧1024点的PCM格式码流[1]。由图1框图可以看出,时域上的信号数据流在进入音频编码器后被分成两个路径,一是通过心理声学模型的计算得到后续编码过程中所需的信掩比等参数,并基于此确定变换块的类型,另一路则通过滤波器组得到亚采样频谱。采样频谱经强度立体声编码、长期预测编码、联合立体声编码等模块处理后进入量化编码阶段,此时信号才真正得到大幅度的压缩处理。码流在量化过程中,基于心理声学模型计算所得出的信掩比等参数,计算得出缩放因子各自的最佳量化步长,使量化处理后的信号可闻失真达到最小[2],再通过无噪声编码模块进行处理,便可得到编码后的数据。
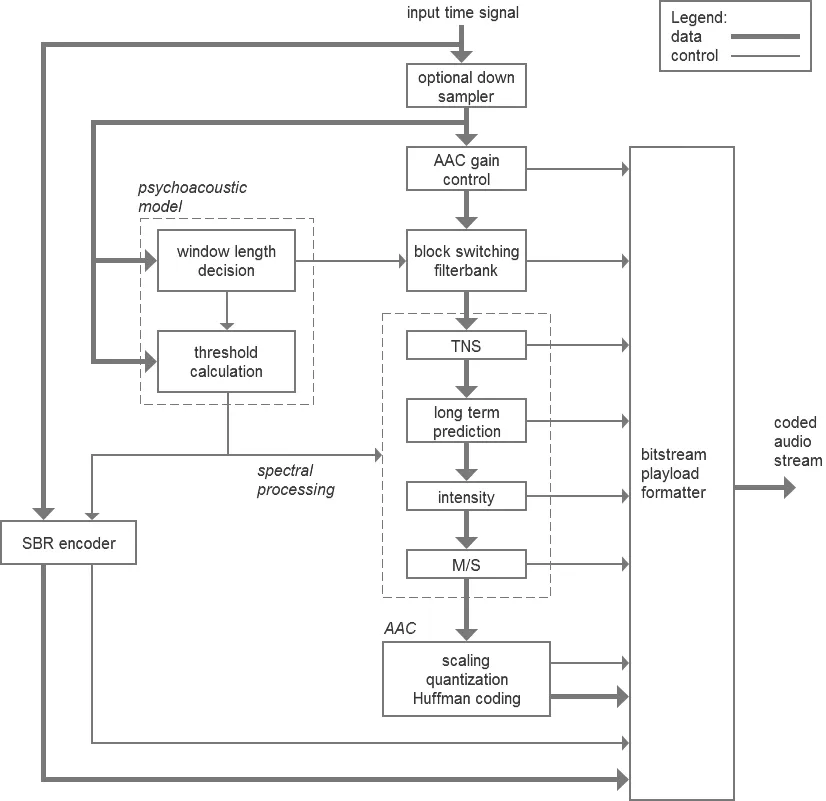
图1 MPEG-4 AAC编码流程框图
本文主要针对编解码系统中的时域噪声整形(TNS)模块进行研究,主要介绍TNS原理,LPC在TNS中的应用及TNS模块的软件实现。
2 时域噪声整形
2.1 掩蔽效应与预回声现象
通过频率位置映射的方法,人耳可实现对感知到的周围声音信号的频谱分析。心理声学方面的研究结果认为,环境中的某一声音信号是否能够被人耳所感知,往往取决于声音的频率和强度这两个方面。然而,这种感知并非是确定的,其还要受到所谓 “掩蔽效应 ”的影响。通俗来说,它指的是较“强”声音信号周围较“弱”的声音很容易被人耳忽视,即被“掩蔽”掉。此时,“强”声为掩蔽声,而“弱”声为被掩蔽声。掩蔽效应包括以下两种:频域掩蔽(同时掩蔽)和时域掩蔽(异时掩蔽)[3]。
采用时间/频域的编解码的方法可以很好地降低音频信号处理过程中帧间的相关性和部分冗余,有利于数据压缩的实现。但这种方法很可能会引发量化噪声在时域中的扩散,甚至超出信号的起始点,引发预回声这一影响主观音频质量的问题。预回声现象产生的主要原因是:由时间分辨率不足引起的时域中量化噪声的扩散[4]。尤其是当时域中存在某一瞬态信号变换到频域进行量化编码时,量化噪声将在变换后在整个变换块范围内扩散开来,若此时量化噪声不能有效地被信号掩蔽,则此时就会出现影响声音质量的预回声。
主观音频质量的评估不仅会受到由量化噪声产生的预回声现象的影响,人耳本身所具有的时域掩蔽效应也一样起着一定程度的影响。研究指出,人耳本身所具有的前向掩蔽作用时间仅有约20ms,而后向掩蔽拥有约200ms的持续期,由于其较长的后向掩蔽时间,通常可以更好地屏蔽量化噪声,从而避免了其对主观音频质量评估的影响。所以在音频编码器的设计中我们通常不需要考虑这种情况。
为了抑制预回声的产生,我们通常从以下两方面考虑:一是使总量化噪声的最小化,二是对量化噪声进行控制和整形处理,并将其与前向掩蔽效应相结合,将量化噪声控制在人耳可闻阈值以下,完成对预回声的抑制作用。常用的预回声抑制处理主要包括以下四种:(1)预回声控制与比特池技术(2)自适应窗切换技术(3)增益控制技术(4)时域噪声整形技术[5]。
本文所重点讨论的TNS技术的出现,在处理预回声对主观音频质量的影响这一问题上具有非常深远的意义,使AAC能够达到压缩率与音质兼得的效果。
2.2 时域噪声整形的理论基础
由于具有相对稳定的时域信号将在频域中显示出急剧变化,而在时域上具有剧烈变化部分的信号,对应到频域中一般呈现为较为平稳。时域噪声整形技术充分利用该原理,在平稳变化的信号频谱段,对信号的频谱以帧为单位做线性预测,然后对预测残差做编码。
TNS的提出基于如下考虑:
(1)时域-频域的对偶性:对于频谱表现为“非平坦”的信号,编码方式通常有两种可以选择,一是直接对频谱值进行编码,二是对时域信号进行线性预测编码。因此针对时域上的“非平坦”(瞬态)信号通常也就有两种与之相对应的方法:在时域中对信号直接进行编码或在频域上进行预测编码。
(2)基于线性预测编码技术的噪声整形:在时域上对音频信号做前向预测编码,可通过调整编码器设计,使其量化误差功率谱(PSD)与输入信号的功率谱相适应[6]。同样在频域上对信号做线性预测编码,则可通过在解码器的输端调节量化误差的时域形状,可以达到适应输入信号的时域形状的目的。通过以上方法将很大程度上把量化噪声的时域形状置于实际信号之下,有效解决了瞬时信号对主观声音质量的影响的问题。
2.3 时域噪声整形在AAC编码中作用
时域噪声整形模块通常用于包含瞬时信号分量的音频块,以滤波器中的变换窗为基本单位,针对信号中每个变换窗的频谱系数做相应的滤波处理,通过计算每个比例因子频带的噪声能量,并与该频带的掩蔽阈值进行比较,当噪声能量超过该频带的掩蔽阈值时,则进行时域噪声整形。
由MPEG-4 AAC编解码器处理过程来看,整个编解码过程是模块化的[7]。其中时域噪声整形模块则可根据不同条件下的编码进行选择,并非编码过程中所必须的。因此可以取同一段音频,首先用编译好的fdk-aac对其进行编码,输出后缀为.aac的音频文件,再将fdk-aac中aacenc_tns.cpp中TNS处理模块中返回值设为0,输出不包含TNS模块的aac格式音频文件。为了验证该处理方法能否得到一个不包含TNS且标准解码器可解的音频文件,首先可播放.aac音频文件的播放器播放,可以成功播放出完整的文件,然后将编码后的.aac文件作为标准解码器的输入,成功地输出.wav文件且可用音乐播放器播放出完整音频,即可以验证该工程可行性。
通过Matlab中audioread函数,可以得到两个aac格式音频文件频谱如图2所示,其中,图片上半部分是含有TNS模块的fdk-aac编码器输出的信号频谱,下半部分是不包含TNS处理过程得到的结果图。从图中波形可以明显地看出,相对于不包含TNS模块的编码器得到的解码音频,包含TNS模块的编码器可以较好地将量化误差控制在实际信号波形之下,避免了瞬时冲击信号对音频质量的影响。
由于不同信号的时域分布各不相同,因此TNS滤波器一定表现为时变,针对不同帧的信号,滤波器系数也表现为不相同的。所以码流中就必须包含有TNS滤波器相关的一系列参数。滤波器系数的确定通常由Levinson-Durbin算法得出,预测增益的大小决定了是否在编码过程中使用TNS滤波器[8]。在AAC编码器中,当前帧的频谱可由当前频谱之前的两帧预测得到,然后再求预测的残差,最后对残差进行编码,具体步骤如下。
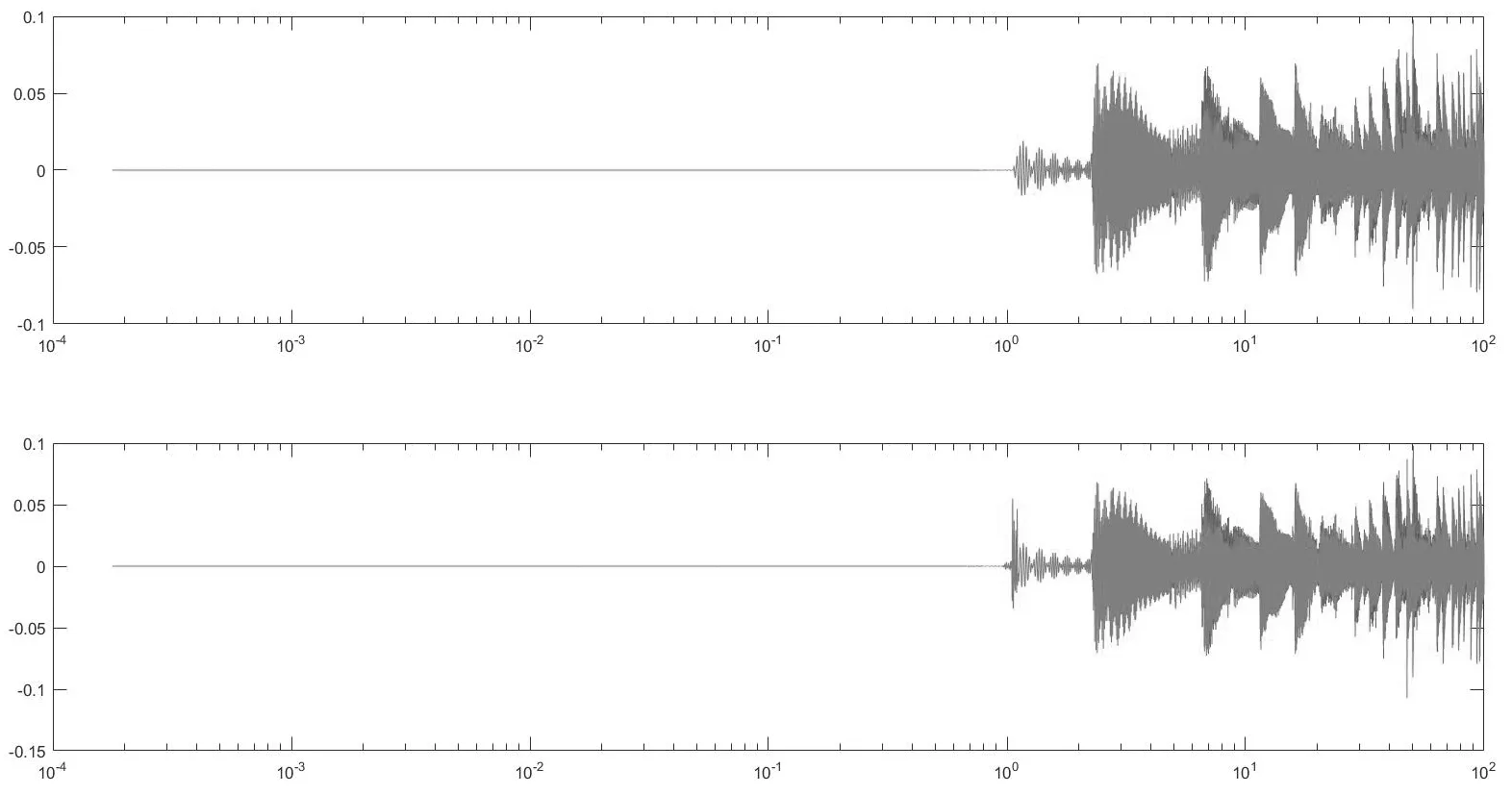
图2 编码器中有(上图)无(下图)TNS模块的对比分析
(1)通过码流中当前帧之前的两帧频谱的重建信号预测当前帧的频谱;
(2)残差信号由当前帧频谱与预测频谱相减得到;
(3)对残差信号进行量化处理;
(4)反量化,并通过预测残差和预测值通过一定的算法重建当前帧的频谱信号;
(5)对预测器参数进行更新。
3 线性预测编码
由于语音信号在某一较短时间内表现为平稳随机信号,并且同一帧数据之间通常具有较大的相关性,通过前一个或多个信号对下一信号进行线性预测,然后对实际值和预测值的差值数据进行编码,就可以很大程度上减少编码后的码位,以实现数据的压缩编码。
在AAC编码系统中,语音序列在通过改进离散余弦变换(MDCT)模块进行加窗处理后,便可满足以上条件,即可对其进行线性预测编码(LPC)。
3.1 线性预测的基本原理分析
语音信号中,任何一个采样值都可以通过它之前的p个采样值的线性组合表示,即p阶线性预测,其中每个系数的确定都遵循最小均方差准则[9]。公式如下:
(1)
(1)式中,表示预测值,表示p阶预测中的第i个系数,预测误差如下:
(2)
由最小均方差准则,对预测误差的均方差求的偏导数,并令其为零,即:
(3)
将(2)代入(3):
(4)
其中:为自相关函数。因为预测误差的功率可表示为:
(5)
将(2)代入(5),并用(4)推得的结果可得:
(6)
(4)与(6)结合在一起可以得到Yule-Walker方程:
(7)
将(7)写成矩阵形式:
(8)
该方程组中包含有p+ 1个未知数,在自相关函数已知的条件下,可通过Levinson Durbin算法解出该方程组。
Levinson Durbin算法的递推关系如下:
(9)
其中kp为反射系数。
3.2 语音信号的线性预测仿真分析
为了验证线性预测编码过程所产生的效果,可简单地通过Matlab中的lpc函数实现对语音信号的预测编码。取一段语音信号,通过Matlab中的audioread函数读取信号相关参数,画出原始信号波形如图3.1中最上方图片所示。取语音信号中的某一帧,波形如图3中“a frame of data”所示。对该帧信号进行预测编码并画出预测编码结果波形,如下图中“predicted signal”波形所示,通过预测编码前后比对,可以看出对于语音信号,通过预测编码的方法得到的结果较为接近原始信号。
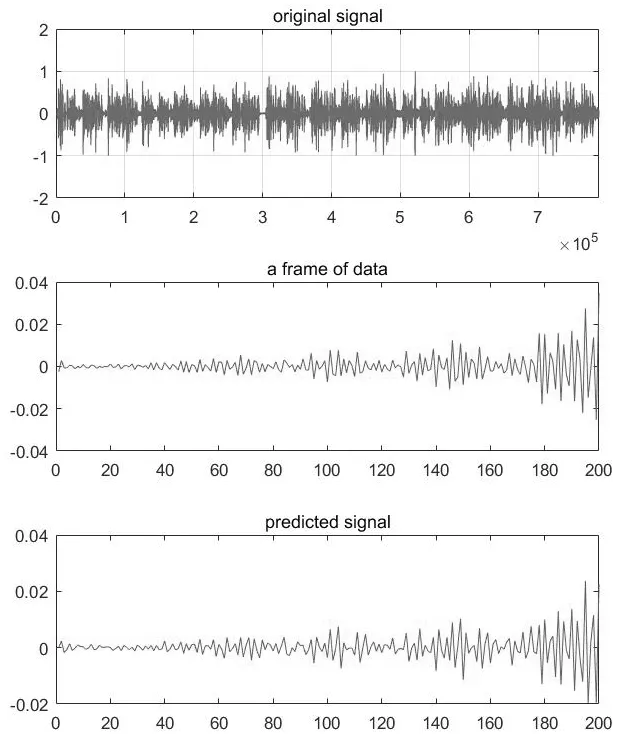
图3 线性预测编码
图3.1中上中下分别表示为,上:原始信号波形,中:原始信号中的某一帧信号的波形,下:所选取信号经过预测编码得到的预测信号。
在语音信号编码算法中,如果通过直接编码的方法对语音进行处理,会出现编码所需的比特数大且速率高的问题。线性预测的方法较好的解决了这一问题且编码效果较为理想。
4 LPC在TNS编码器中的具体应用
TNS的实现框图如图4所示。
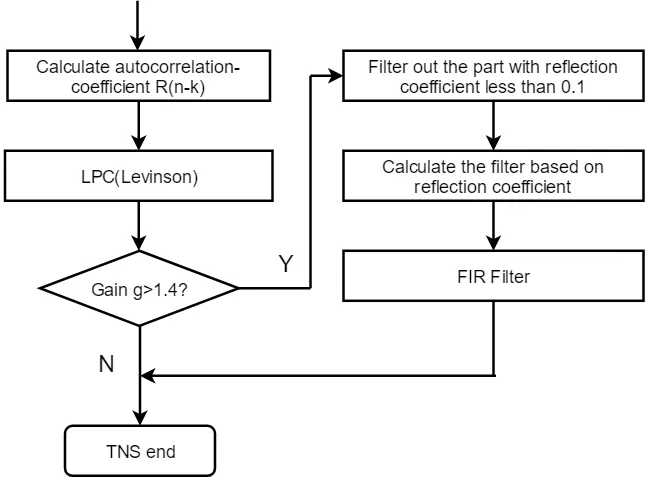
图4 TNS模块实现流程框图
由框图可知时域噪声整形模块具体实现步骤如下:
(1)TNS处理是否进行的判断由心理声学模型输出的感知熵决定,如果超过阈则进行处理。
(2)求出MDCT输出信号的自相关函数R(i,k)及信号的功率PI。
(3)对信号进行阶数小于20的线性预测。由Levinson Durbin算法可得出反射系数k及预测误差功率Pe。
(4)若预测增益gain=PI/ Pe大于阈值t(标准推荐值t=1. 4),则进行TNS处理,否则跳过TNS模块处理。
(5)对反射系数进行量化和编码处理,提供给解码器中反TNS变换使用。
(6)将反射系数中小于阈值p(标准推荐值p=0.1)的部分通过滤波器滤掉,剩下的反射系数的数量作为FIR预测误差滤波器的阶数。
(7)FIR滤波器的系数将由剩余的反射系数得到,然后对信号进行滤波并将预测残差进行编码。
5 TNS解码器的软件实现
TNS解码过程中所需要的一系列参数可通过tns_data()函数从码流中解析出来,具体方法如图5所示。

图5 TNS模块中参数获取
其中所包含的主要参数定义如下:
n_filt指每个帧内tns滤波器的个数;length指通过tns滤波器过滤的频域系数的个数;order表示tns滤波器阶数;由于瞬态信号通常是双向的,所以tns滤波器便存在着方向的问题,通过direction表示滤波器方向,“0”为upward,“1”即为downward;coef_compress用于判断noise shaping filter filt系数在最显著位在传输中是否被省略,1表示被省略,0表示未被省略。
TNS的解码过程中,传输滤波器系数首先被解码出来,并转换成为有符号数,通过反量化的方法将其转换成为LPC系数。解码过程的软件代码实现如下:
/*TNSdecodingforonechannelandframe*/
丰信农业创始人、总经理董金锋在接受《中国农资》记者采访时表示,未来,农业高质量发展离不开农服,农业挖潜离不开农服,农服一定会成为农业发展的一股洪流并将势不可挡。农服企业要联系实际,不断加强技术创新、组织创新、运营创新、服务创新,为现代农业发展助力。
tns_decode_frame()
{
for(w=0;w bottom=num_swb; for(f=0;f top=bottom; bottom=max(top-length[w][f],0); if(!tns_order) continue; tns_decode_coef(tns_order,coef_res[w]+3,coef_compress[w][f], coef[w][f],lpc[]); start=swb_offset[min(bottom,TNS_MAX_BANDS,max_sfb)]; end=swb_offset[min(top,TNS_MAX_BANDS,max_sfb)]; if((size=end-start)<=0) continue; if(direction[w][f]){ inc=-1;start=end- 1; }else{ inc=1; } tns_ar_filter(&spec[w][start],size,inc,lpc[],tns_order); }}} 其中TNS_MAX_BANDS为一个常数,其定义了TNS可以应用的sfb的最大数目。常数TNS_MAX_ORDER定义了线性预测阶数的最大可能值,其值依赖于AudioObjectType和窗长的参数,如下表所示。 表1 TNS_MAX_ORDER取值对照表 MPEG-4 AAC是当前使用较为广泛的一种高质量音频编码系统,其主要特点包括:较高压缩比,较好的音频信号重建质量,编解码程序以模块化的形式呈现,灵活的参数配置。同时预测技术在音频信号编码器对于主观质量的提升具有非常显著的效果,已被广泛地应用于多种音频编解码算法中。 本文简要介绍了MPEG-4 AAC编码器的处理过程,TNS的基本原理、步骤以及其主要解决的问题,LPC基本原理和其在TNS模块中的应用,TNS模块的软件实现分析。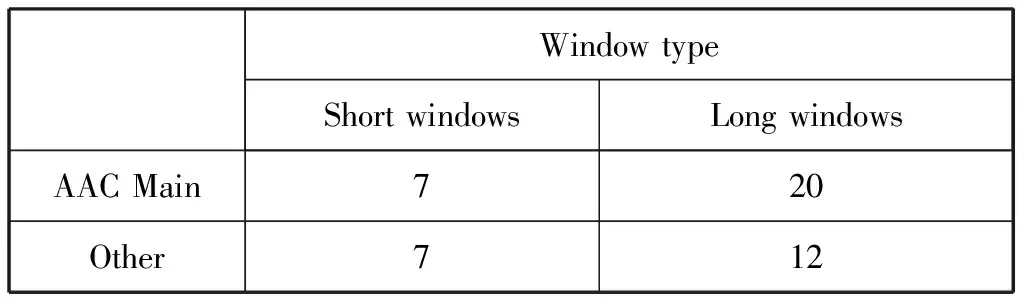
6 总结
猜你喜欢
空间科学学报(2021年6期)2021-03-09 06:20:14家庭影院技术(2018年11期)2019-01-21 02:20:52测控技术(2018年7期)2018-12-09 08:58:22测控技术(2018年11期)2018-12-07 05:49:02电子制作(2018年19期)2018-11-14 02:37:08电子制作(2017年9期)2017-04-17 03:00:46系统工程与电子技术(2016年7期)2016-08-21 13:59:14西北工业大学学报(2015年4期)2016-01-19 03:31:55人间(2015年8期)2016-01-09 13:12:42无线电通信技术(2015年3期)2015-12-23 11:37:00
