
基于频繁模式的长尾文本聚类算法①
2019-04-29 08:58宋中山张广凯
计算机系统应用 2019年4期
宋中山,张广凯,尹 帆,帖 军
(中南民族大学 计算机科学学院,武汉 430074)
Twitter、微博信息传递的形式为短文本.短文本最大的特点是单条短文本只有几十个字节大小,仅包含几个到十几个词典词语,很难准确抽取有效的语言特征[1].这类非规范化严重的短文本,具有特征信息不足,特征维度高,数据稀疏性高等特点[2,3].因此使用传统聚类方法对此类短文本聚类时难度较大.
“长尾现象”普遍存在口语化的短文本集中.大约40%的短文本信息集中分布在大约20%的空间中,也就是“头”的部分,称之为“热点”,大约60%的信息分布在大约80%的空间中,即“尾”的部分,将所有非热点信息累加起来就会形成一个比主流信息量还要大的信息[4].从这些“尾”部的信息中收集到有用的信息对于政府或者一些投资商了解社会异常以及人们日常动向有很大的帮助[5,6].传统聚类算法,主要通过一次筛选后得到频繁词来表征短文本,因“长尾”部分短文本的特征词权重很小,达不到传统算法中筛选阈值,所以在挖掘频繁词时,会忽略掉小类别短文本的特征词,造成小类别短文本的特征信息不足,在聚类结果中小类别短文本会被划分到不正确的簇里面,导致聚类的精确度降低,因此本文围绕提高“长尾”部分短文本聚类精确度的问题,提出一种频繁项协同剪枝迭代聚类算法(FIPC),首先提取频繁词构建频繁词-文本矩阵,接着使用K 中心点算法对文本进行初始聚类,然后根据协同剪枝策略对原始数据集进行剪枝得到下一次迭代聚类的文本集,重复进行上叙过程,直到得到对小类别短文本聚类的结果簇,从而实现“长尾”文本的聚类.实验结果证明,与传统的K-means 聚类和FIC 算法相比,该算法能够有效的避免类簇重叠问题,提高了“长尾”短文本聚类精确度.
1 相关工作
目前国内外的众多学者已经对于短文本聚类方面技术有了相关研究.基于频繁模式的文本聚类算法,该类算法通过以频繁模式的方式,表征文本进行聚类[7-9].如:栗伟等人提出了ACT 算法[10],该算法将挖掘频繁项来表征文本,以频繁项确定文本簇的中心点,对文本进行完全聚类.该算法所面对的数据集为疾病的病例数据,此类数据格式规范且种类少.但是该算法在进行日常口语化文本信息提取时,算法效率较低.彭敏[11]等人提出了一种基于频繁项集的短文本聚类与主题抽取STCTE 框架,该框架首先对于海量短文本数据进行打分数筛选,留下得分高类别大的文本,结合谱聚类算法CSA_SC 算法与主题抽取模型,实现短文本聚类效果.该算法在处理社交网络中的短文本信息时,前期处理筛掉非频繁的短文本,造成了大量的信息缺失,对一些小的类别文本没有进行聚类,精度不高,效果不佳.基于子树匹配的文本聚类算法,该类算法利用文本生成元数据特征向量,设置分层权重结合语义之间关系构建文本子树,通过子树之间的相似度来进行文本匹配[12,13].该算法不能解决多义词的问题,这对于日常短文本的聚类效果不佳.基于语料库的短文本聚类算法,该类算法在不借助外部文本信息的情况下,引入共轭定义来表征主题词和单词结构,提出文本虚拟生产过程,达到解决文本稀疏性和聚类问题的目的.如:Zheng CT,Liu C,Wong HS[14]提出的基于主题扩展的文本聚类算法,结合特征空间及语义空间达到提高短文本聚类精度的效果,但该算法在对于具有“长尾现象”的文本数据聚类时效果不佳.基于主题模型的文本聚类算法,该类算法主要结合主题模型与传统算法,来对海量短文本进行聚类.如:Hung PJ,Hsu PY,Cheng MS[15]的动态主题的Web 文本聚类,结合EM 算法与动态主题为文本聚类特征对Web 文本进行聚类;张雪松和贾彩燕提出的FIC 算法,首先挖掘频繁词集表示文本,构建文本网络,运用社区划分算法对网络进行大范围划分,最后提取主题词,进行类簇划分[16].该算法在处理“长尾现象”的短文本数据时,聚类精度不高.针对此类问题,彭泽映等人[17]在对实际应用中短文本信息的“长尾现象”进行分析后,提出不完全聚类的思想,即在聚类的过程中集中资源处理大类别的短文本,减少资源在孤立点聚类上的浪费,尽量减少小类别的短文本的聚类时间,增加大类别的短文本聚类机会.但该算法在处理社交网络口语化,小类别文本数繁多的应用中,容易丢失文本信息,精确度较低.
针对以上短文本聚类面临的特征高维,小类别信息丢失的问题,本文提出频繁项协同剪枝迭代聚类算法(FIPC),通过挖掘频繁词集,根据相关文本相似性实现文本聚类,得到部分聚类结果,根据协同剪枝策略,生成主题词检索并且剔除相关短文本,迭代进行此聚类过程,进而实现短文本聚类.具体来说主要有以下2 点贡献:(1)采用逐步降低频繁词的筛选阈值,让权重较小的频繁词被选中来表示短文本的特征,解决了传统聚类中小类别信息被忽略的问题,同时避免了类簇重叠问题的出现;(2)充分利用类簇主题词与文本之间关系,设计协同剪枝策略,减小迭代聚类中每一轮数据集,减小了每轮聚类的时间消耗.
2 模型描述
2.1 频繁词挖掘模型
定义1.文本数据集D由多个文本组成 D ={d1,d2,···,dN},N表示文本集的大小总数,以及文本切词之后得到的词集V,V={t1,t2,···,tn},n表示词汇表的大小.
定义2.特征词:每一个文档dN经切词之后得到词集V={t1,t2,···,tn} ,词集中的每一个词,称为特征词tn.
定义3.文本集D中第j个文本的每一个频繁词对应词集V构成的词空间的一个维度,wM表示每一个频繁词对应的权重,即词空间中的每个维度的坐标.
对于特征词权重的计算方法运用TF-IDF 算法.其中t fij表示在文本dj中的特征词ti的出现的标准化词频,则在文本dj中ti标 准化词频(记做t fij)计算如下:
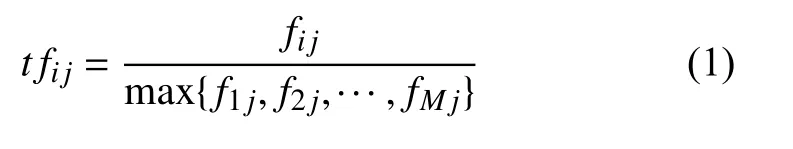
其中,特征词ti的 标准化逆文档频率记做id fi其计算公式如下:

在短文本中不同词性重要程度不同,代表文本的重要程度不同,我们给每一个特征词根据词性赋予一个权值 αi.
最后文本dj中每一个特征词的最终权重wi为词频因子(t fij)与逆文档频率(id fi)与词性权重αi三者的乘积.如式(3)所示:
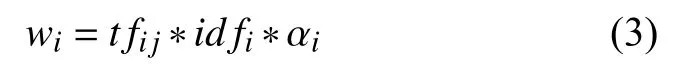
由式(3)所示特征词的权重由三方面的因素来决定:第一方面因素为该特征词在这个短文本中词频因子;第二方面为该特征词在文本集里面的逆文档频率因子;第三方面为特征词的词性因子[18].
定义4.频繁词集:从词集V挖掘权重大于频繁词阈值Y2的频繁词fk组成的集合Fi={fi,f2,···,fk}.
2.2 文本表示模型
向量空间模型(Vector Space Model,VSM)是最常用的文本表示模型[19].VSM 模型采用特征词表征文本构建矩阵,这对于矩阵的维度比较高,本文运用频繁词表征文本,选前K个频繁词构建频繁词-文本矩阵L,L为0-1 矩阵,其中表示矩阵L中文本dj对于频繁词fi的值,若文本dj中含有频繁词fi,则否则的表现形式为:
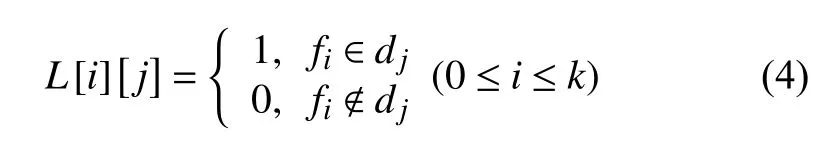
选用前K个频繁词来构建矩阵L,而不选择所有的特征词,这样降低了矩阵的维度,同时也解决了文本稀疏性问题.
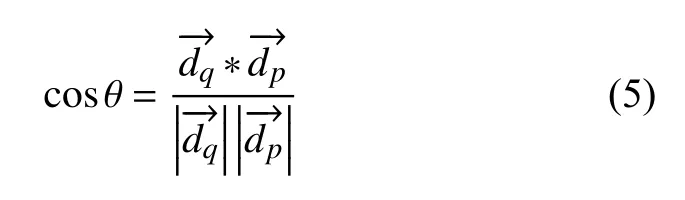
文本向量化后的对文本进行相似度计算,传统的相似度计算的方法有几种,例如余弦相似度和欧氏距离.本文采用余弦相似度来度量:其中,分别代表文档向量化后的向量,设定相似度余弦阈值Q(Threshold),若两者相似度余弦阈值大于Q(Threshold),则将两者归于为1 个类簇.
对于所有文本运用K 中心点算法对其两两进行相似度计算如式(6)所示,将相似的文档来归于到一个类簇中.
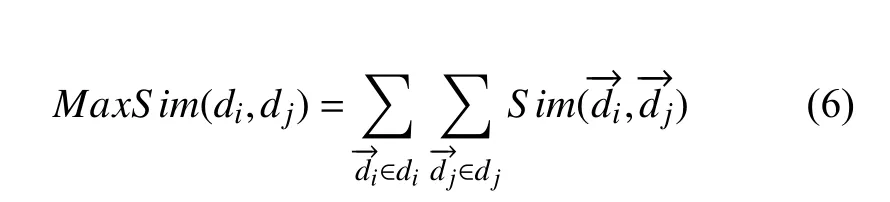
2.3 协同剪枝策略
如何利用主题词与短文本之间的关系,这在提高“长尾”文本聚类的精确度方面有重要的作用.对于上一次聚类结果簇,提取主题词TCi.根据以下规则进行剪枝策略以及迭代聚类.
规则一:对于初始样本文本集D={d1,···,dN},初始聚类后得到初始结果簇Ci,从Ci选取频繁词作为主题词TCi,对于初始数据集中每一个文本dN,若表示dN的频繁词集中包含TCi,则从初始样本文本集D当中剔除掉文本dN,余下文本集作为下一次聚类的输入文本.
规则二:为了防止短文本中孤立点数据对迭代聚类次数的影响,设置固定最小权重阈值P,多次迭代聚类后,对余下文本计算特征词权重,若所有特征词权重中最大的特征词权重值小于最小权重阈值P,则迭代聚类结束.
3 FIPC 算法
FIPC (Frequent Itemsets collaborative Pruning iteration Clustering framework)频繁项协同剪枝迭代聚类算法步骤图如图1所示,该算法首先对初始样本文本集D切词得到具有词性标注的特征词,从其中提取频繁词,然后构建频繁词-文本向量矩阵,在文本向量化后利用K 中心点算法进行聚类[20],初始聚类结束得到部分聚类结果簇,提取每一个簇中的主题词,根据协同剪枝策略对初始样本文本集进行剪枝.同时减小频繁词阈值Y2,再对余下数据集迭代进行第二次、第三次等多次聚类过程,经过多次聚类之后,若余下文本特征词满足规则二,则迭代聚类结束,最后得到聚类结果簇{Ci}.算法中部分参数如表1所示.
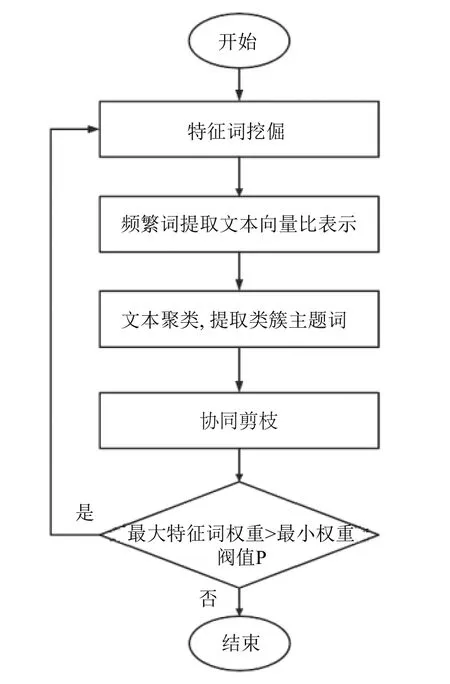
图1 频繁项协同剪枝迭代聚类算法步骤图

表1 部分参数含义表
实验中采用频繁词阈值动态变化逐步减小的规律,上一次实验选取频繁词阈值高,代表文本可信度较高,最后将文本分到指定簇的可信度高于其后实验可信度.使得每一个文本能被唯一指派到唯一的类簇中,避免了类簇重叠问题的生产.
算法描述如下:


4 实验结果与分析
4.1 数据集
其中,文本分类语料库搜狗新闻数据集①包含9 个新闻类,共有17 910 个文本;NLPIR 微博英文语料库②,包含的英文文档数为23 万,其中数据集的文本结构为:Id:文章编号、article:正文、discuss:评论数目、insertTime:正文插入时间、origin:来源、person_id:所属人物的id、time:正文发布时间、transmit:转发.本文中抽取article 中的文本短内容进行聚类,从搜狗数据集随机选取部分数据进行实验,如表2所示.

表2 搜狗数据描述
4.2 聚类评价指标
为了测试FIPC 算法的性能,我们需要选择聚类评价指标,聚类评价指标分为内部评价指标和外部评价指标.我们采用文本聚类中常用的外部评价标准Fmeasure[21],它经常被用作衡量聚类方法的精度,是一种平面和层次聚类结构都适用的评价标准.Fmeasure 综合了召回率和准确率2 种评价标准:
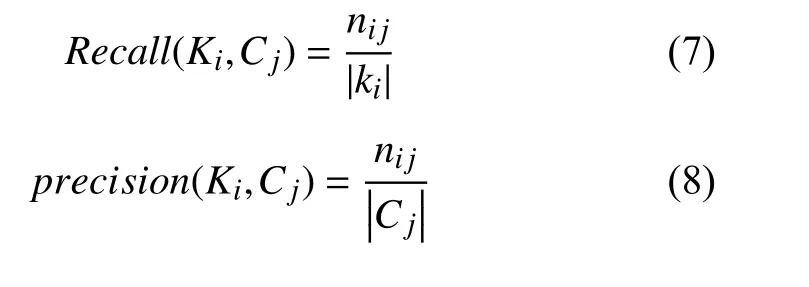
其中,ni j表示簇Cj中 属于类Kj的文本数,由召回率和准确率可得到表示簇Cj描 述类Kj的能力计算:

聚类的总体F-measure 值取值范围在[0,1],值越大表示聚类效果越好.
4.3 实验方案设计
为了验证本文提出的文本聚类方法,我们选用2 个文本聚类中标准的数据集来进行实验,对照常用的基于K-means 文本聚类方法和FIC 算法.
对于原始数据集首先利用python 中的结巴分词(基于机器学习的中文自然语言文本处理的开发工具)进行切词,样本文本经过切词、剔除停用词以及词性标注操作之后,得到具有词性标注的特征词ti,但仍然存在这大量与主题无关或者无意义的词语.因此在本文中需要选取阈值来筛掉不相关和无意义的词语.
本文中有3 处参数需要涉及到阈值的选取,包括挖掘频繁词的频繁词阈值Y2、计算余弦相似度时余弦阈值Q(Threshold)、实验结束时最小权重阈值P.本文通过手动调参,多次试验的方式,来获得聚类最佳效果的参数阈值,其中在频繁词减小的过程中,要保证每次表征文本的频繁词数不少于5 个,选择最后实验结束的最小权重阈值P时,最少保证词频最大的频繁词所出现文本的频数不小于2.对于本次实验,在英文数据集中,选取相似度余弦阈值步长为0.005,由于中文数据中的停用词较多以及每个文档词数量较少,因此采用与英文数据不同的阈值选择方式,采用0.01 的步长,并且以对聚类精度影响最高的相似性余弦阈值进行实验.
4.4 实验分析
我们在不同算法上分别对搜狗数据集和NLPIR微博内容语料库进行试验,其中对这3 种算法进行10 次实验取平均值作为最后聚类的精度结果.对于实验初始值聚类的中心点数K值我们设置为5,实验过程中对于聚类结果不在我们初始簇类别里的,则设为一个新的簇类.实验中固定最佳的最小权重阈值P=0.003和频繁词筛选阈值Y2=0.020,如图2所示为相似度余弦阈值Q(Threshold)取不同值时FIPC、FIC 和K-means算法在搜狗数据集下的F-measure 的变化曲线图.
图3为3 种算法在固定最佳的最小权重阈值P=0.003和频繁词筛选阈值Y2=0.020之后取不同相似度余弦阈值Q(Threshold)时,在NLPIR 微博英文料库上的Fmeasure 变化曲线图.
对于本次实验最后产生的类簇进行主题词提取,我们选用提取频繁词来作为主题词.统计该类簇中频繁词出现频率,并且按照前10 的频繁词来描述主题词.

图2 搜狗中文数据集下三种聚类算法的精度
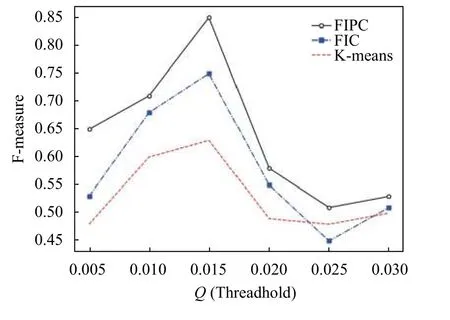
图3 NLPIR 微博数据集下三种聚类算法的精度
如表3所示,可以看出FIPC 算法较之其他方法在精度上面有明显的优势,原因有以下几点:
(1)在数据处理方面,并不只是分词和去掉停用词,为了保留具有代表性的词汇,采用TF-IDF 值结合词性来筛选特征词.
(2)运用频繁词来构建文本表示模型,文本集中挖掘出频繁词,有效的降低了文本表示矩阵的维度.
(3)本文采用协同剪枝的策略,结合主题词与文本矩阵进行协同剪枝,缩小了数据集的大小.
经过10 次试验取平均值作为最后聚类结果得出以下3 个算法在2 个不同数据集中的精确度.
由表3中可以看出FIPC 算法聚类出来的Fmeasure 值相较于其他2 个算法略大,因此体现出该算法的聚类精确度最好.
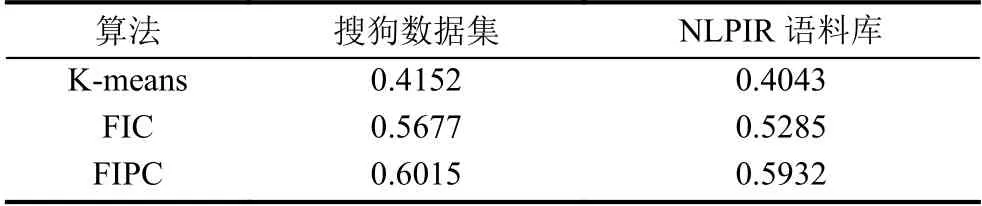
表3 算法F-measure 值
5 结语
本文针对短文本“长尾现象”这一特点,提出一种新的文本聚类算法FIPC,该算法基于频繁词表征文本,解决了高稀疏性的问题,将经典聚类算法K 中心点应用到迭代聚类的框架中,实现对小类别文本进行聚类,更精确的挖掘小类别短文本的信息,提升了聚类的准确性.
本文中采用的K 中心点算法结合协同剪枝策略,但是K 中心点算法一直存在一个问题:如何选取合适的初始中心点,本文中采用人工随机选取初始中心点的方法,若能在选取合适的初始中心点对于实验结果的精确度能有更大的提高.因此在下一步工作中如何有效快捷的选取合适的初始中心点来进行聚类是我们所要思考的.
猜你喜欢
保健医苑(2022年5期)2022-06-10
重庆大学学报(2022年2期)2022-02-28
建材发展导向(2021年19期)2021-12-06
计算机仿真(2021年6期)2021-11-17
计算机应用与软件(2021年11期)2021-11-15
成都信息工程大学学报(2021年6期)2021-02-12
智能计算机与应用(2020年4期)2020-08-31
汽车文摘(2019年3期)2019-03-04
天津诗人(2017年2期)2017-03-16
档案管理(2014年6期)2014-10-30
