
一种预测后置应用延迟的方法与实现
2019-04-25 17:15潘钢
中国信息化 2019年4期
潘钢
现阶段移动经营分析的数据流大致分为数据接口、数据处理、数据分发、数据应用四个层级,每个层级内有数量庞大的运行程序,按照实际业务需求分成很多小层级,形成后置程序依赖前置程序的关系。而且每个程序的前置程序数量不固定,大于等于一个,就这形成了极其庞大且相互缠结的程序集群。程序间的依赖关系非常繁杂。每天凌晨开始,大量数据(大于100T)流经这些程序时,偶尔会有个别程序发生运行延迟。发生延迟程序会对后置造成多大范围的影响、多深的影响是未知数。而且现有脚本和手工查证的方式不便,因为速度太慢,当查证出后置延迟应用时往往已错过了时效性。即使让有丰富经验的工作人员操作此流程,也不能缩短这个时间,也不能达到理想的效果。
一、目标与成果
本次研究目标包括:
(一)一种预测后置应用是否延迟的方法,重点解决数据库生产和运维过程中的问题预测问题,实现从“发现问题-找原因-处理问题”,转变为“发现波动-提出预警-启动预案-消灭问题”问题。
研究一种结合数据和机器学习方法,进行自动预测的方法,以数据监控和算法预测代替人工,大幅降低数据生产过程中出现的后置应用延时等问题;
研究方法实践中所需要的方法论,包括采用的算法分析、模型构建、参数调整和模型调优等。
(二)研究一种数据库内生产调度优化的方法,重点解决数据库内前后置应用配置不合理的问题,实现理论和经验调度向数据化、智能化调度的转变。
研究一种结合数据和机器学习方法,判定程序启动时间是否合理的判别方法,以历史运行数据为基础,以模型判定为依据,大幅降低由于调度导致后置程序延迟和前后置依赖不合理的问题,解决长期困扰运维人员的数据生产程序的基础配置问题。
研究方法实践中所需要的方法论,包括采用的算法分析、模型构建、参数调整和模型调优等。
二、技术方案
本方法分为三个步骤实现:扫描程序、预测模型、优化模型,如图1所示。

(一)步骤一:扫描程序
为了得到当前应用的运行情况和应用的历史信息,参见图一中扫描程序的流程图,具体步骤如下
1. 数据采集
从当日应用运行记录中提取应用的运行信息,包含接口、处理、分发、应用等层级的全量元数据。经过数据清洗、数据匹配得到应用名、是否重要、是否延迟、是否完成、结束时间、延迟时间、标杆时间等信息。其中每个应用的标杆时间来自最近一段时间段内的统计值,如下图二所示,x轴为最近一段时间内某个应用的历史结束时间间隔记录,y轴为次数。

泊松分布的参数λ是单位时间(或单位面积)内随机事件的平均发生率。泊松分布适合于描述单位时间内随机事件发生的次数。
2. 数据处理
对来自不同层级的数据进行处理,得到数据格式一致的数据集。如有些数据接口的应用名得加上前缀,完成状态采用统一的编号格式,结束时间使用同一种格式。
这里采用简单的六西格玛计算。对于每一个前置应用程序,连续60天的完成情况可以构成一个简单时间序列,可以反映一定时间内的数据生产完成情况。那么这个时间序列的均值μ反映该程序的平均完成情况;时间序列的σ反映程序完成情况的波动性。从生产角度来说,为了控制的严格程度,往往需要生产的及时性控制在更小的范围内,因此,我们设定t≤μ+σ,即生产的波动性应控制在1个σ的范围内,如果一个程序完成时间大于μ+σ,我们认为该程序延迟,延时记为1,未延时记为0。例,假设一个程序的平均完成时间为20分钟,误差为5分钟,今天该程序10分钟运行完毕,我们认为没有延时,记为0;如果该程序运行30分钟,我们判定该程序延时,记为1。
3. 数据保存
把应用的属性,如:是否重要、是否延迟、是否完成、结束时间、延迟时间、标杆时间等信息,提取出来后放入一个对象中。以应用名为键(key),应用对象为值(value)统一保存。
4. 历史数据统计
统计最近三个月内每个应用的平均运行时长和等待时长。运行时长指的是应用从开始执行到结束执行中间所耗费的时间。等待时长指的是应用众多前置中最晚结束的时间到本应用开始执行之间的间隔时长。
(二)步骤二:预测模型
通过递归计算得到未执行应用的延迟可能性,参见图一中预测模型的流程图,具体步骤如下:
1. 设置延迟阀值
设置初始延迟的阀值和范围,这里圈定数据接口、数据处理、数据分发、数据应用四个层级中的重要应用,阀值为延迟30分钟以上。如果此应用还没执行完成,则把当前时间代指应用的结束时间,在此基础上累加后置时间。以结束时间作为标记时间,即本分支推算到当前应用的标记。
2. 得到关系树
在程序血缘关系表中记录着应用的前后置关系,每条信息是一对一关系,但总体上是多对多关系,也就是说一个前置會对应多个后置,一个后置会有多个前置应用。逐个拿到图1的步骤二预测模型的第一个环节中判定的延迟应用名,在关系表中取得它的后置应用名。
3. 验证应用有效
验证后置应用是否有效,最近三个月是否有运行记录,如果没有的话则忽略此应用。
4. 查看是否已执行
查看后置应用当日是否已经执行过,如果已经执行过则更新标记时间,即本分支推算到当前应用的标记。直接把后置应用的结束时间覆盖标记时间。如果还未执行则跳至图1的步骤二预测模型的第六个环节进行判定。
5. 查看是否已预测
查看后置应用是否已经预测过,因为一个前置有多个后置应用,意味着现在这个后置可能会出现在别的应用的后置中,所以有必要查看此后置应用是否已被预测。如果已经被预测过,则比较预测结束时候是否早于标记时间加上等待时长和运行时长,取更大的那个时间覆盖预测结束时间。这是因为应用得等待每个前置完成后才能开始执行。如果没有预测过,则跳至图1的步骤二预测模型的最后一个环节。
6. 预测应用
进入此环节的便是待预测的应用,累加标记时间、应用等待时长、运行时长,减去标杆时间得到预计延时长,如果为负数或0表示不会延迟。使用预计延时长通过线性拟合算法得到此后置的预计延时几率。但无法保证此后置应用没有再下一层的后置,所以需要从图1的步骤二预测模型的第二个环节开始使用递归算法,把此后置应用作为前置,运算它的下一层,即后置的后置。如果没有下一层则自动终止。
(三)步骤三:优化模型
验证预测出的延时几率的可信度,参见图一中优化模型的流程图,具体步骤如下:
1. 关联预测
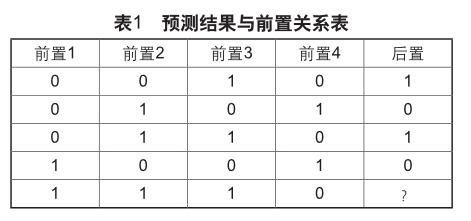
对比每个预测出来的结果和对应的前置的关联关系,即在历史记录中查看当前置们发生延迟时后置是否也会发生延迟,得到如下的关系表,其中1表示延迟,0表示未延迟。
逻辑性的思维是指根据逻辑规则进行推理的过程;它先将信息化成概念,并用符号表示,然后,根据符号运算按串行模式进行逻辑推理;这一过程可以写成串行的指令,让计算机执行。然而,直观性的思维是将分布式存储的信息综合起来,结果是忽然间产生的想法或解决问题的办法。这种思维方式的根本之点在于以下两点:1、信息是通过神经元上的兴奋模式分布储在网络上;2、信息处理是通过神经元之间同时相互作用的动态过程来完成的。
结合BP网络结构,误差由输出展开至输入的过程如下:

本模型在输入层使用的节点数和前置数相同,设置两个隐藏层,输出层直接输出0和1用来代指后置应用是否会延迟。如下图3所示。

3. 保存结果
保存预测出的应用名和延时几率
4. 使用结果
延时几率大于50%的应用自动发送给运维管理人员,对这些应用进行重点观测或看情况进行重新调度。如果该延迟应用超过一定时间仍未完成则自动重新调度。
三、结论
本文提出预测后置应用延迟的方法,解決了当前、后置关系呈金字塔状的情况下的自动预测,现有的预测模型更多解决的是链式关系下的逐层排查问题。在算法方面,使用的是自行设计的基于业务的推演算法,顺着关系树逐个节点计算出预计完成时间,递归至整个关系树,得到每个未完成节点的总的延时概率。在应用成效上,预测结果的准确率经过验证达到94%以上。
猜你喜欢
快乐作文(1.2年级)(2022年5期)2022-05-31
辽宁教育·管理版(2022年5期)2022-05-25
中国药学药品知识仓库(2022年1期)2022-03-23
三悦文摘·教育学刊(2021年31期)2021-09-22
三悦文摘·教育学刊(2021年52期)2021-04-27
山东青年(2018年7期)2018-11-06
魅力中国(2018年41期)2018-03-22
理科考试研究·高中(2017年7期)2017-11-04
中学生英语·外语教学与研究(2016年9期)2016-10-09
软件导刊(2016年7期)2016-05-14
