
基于深度学习的事件单问题智能系统
2019-04-24 18:27徐懿瑾
中国信息化 2019年3期
徐懿瑾
一、业务背景
截至2019年1月,三大运营商移动用户数已突破15亿,用户量巨大,客户服务工作繁重。运营商客服人员通过10086、营业厅、掌厅、微厅等服务渠道受理用户的查询、咨询、投诉等业务,为了不影响客户满意度,需要及时回复并正确解决客户提出的问题。
该工作当前主要由客服人员依赖其个人业务经验来完成,这对客服人员的业务能力要求较高,由此才能更好地解答用户提出的问题。由于缺乏有效的工具,客服人员过往解决问题的经验知识得不到有效沉淀,大量有效的问题解决方法难以在客服群体中快速普及,这导致客服人员的服务能力差异大,影响客服服务质量。在这种背景下,如何开展人工智能方面的文本挖掘技术,针对该应用场景进行智能化升级,充分发挥客服历史处理经验的价值,提升客服处理效率,提升客户满意度,显得尤为紧迫。
目前,深度学习技术的快速发展以及开源社区取得的各种进展,都为深度学习应用的实施提供了极大的便利。利用深度学习技术,可以充分挖掘文本非结构化数据背后蕴含的信息,发挥数据的价值,从而更好的服务于日常生产运营。
因此,基于海量的事件单数据,我们开发了事件单问题智能系统,通过深度学习算法RNN-LSTM实现事件单问题智能分类功能,自动对投诉咨询问题的标准处理模式进行分类,并根据用户检索内容自动匹配最吻合的处理模式,从而帮助客服人员快捷获取咨询投诉问题的最佳历史处理经验,第一时间解决问题,减少事件单产生,同时提升用户满意度。
二、事件单问题智能系统介绍
(一)整体框架介绍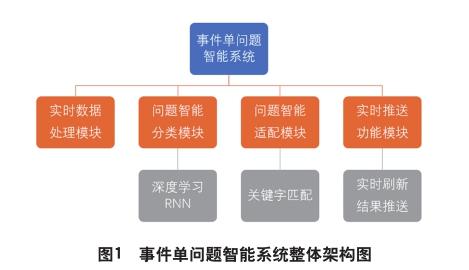
如图1所示,事件单问题智能系统的功能主要包括以下四个方面。
1. 实时数據处理模块:非结构化文本数据实时传输到数据库,处理后输出作为后续模块的有效输入。
2. 问题智能分类模块:基于深度学习算法RNNLSTM构建典型的短文本分类模型。
3. 问题智能适配模块:基于问题智能分类模块的输出,将客服人员输入的用户咨询/投诉内容和标准处理模式相匹配,根据关键字的重合度来计算两者之间的适配度,并通过综合评估方法对适配度进行量化打分。
4. 实时推送功能模块:实时刷新智能分类模型,形成最新的分类和适配结果,并将结果推送至客服系统,帮助客服人员快速获取咨询/投诉问题的最优历史解决方案。
(二)核心技术方案介绍
1.深度学习概述
人工智能,旨在让计算机像人一样思考。作为机器学习的一个新领域,深度学习扩展了人工智能的范围。近年来,深度学习技术和开源框架已经成熟,具有代表性的框架有Tensorflow,keras等等。深度学习是由多个非线性变换(神经网络)组成的多处理层(神经网络),用于数据的高层抽象,其动机是创建模拟人类大脑分析学习和模仿人类大脑解读数据(如图像,声音和文本)的神经网络。
随着谷歌开源Word2Vec(基于深度学习的词向量学习工具),基于深度学习的文本分类方法逐渐成为目前文本分类的主流。目前主要有两个方向:一个是基于神经网络(词向量)的文本表示研究,一个是基于神经网络结构的研究。
循环神经网络模型RNN是近年来在深度学习领域中流行的一种方法。实践证明,RNN对于自然语言处理建模是非常成功。不同于传统的卷积神经网络的多层结构,循环神经网络模型是序列模型,通常可以用于处理序列标注问题。在传统的神经网络模型中,输入层和输出层是相互独立的,并且递归神经网络模型的输出是基于当前输入和上一个周期的输出,RNN具有记忆功能,它可以记住以前的计算信息。而LSTM是比较特别也比较常用的RNN,长期的依赖关系可以被学习。基于RNN的文本语义建模的基本思路是有效地将不同的语义单元有机地结合在一定的结构中,通过自上而下的组合,生成文本的向量表示,如图2所示。
2.技术方案具体内容
本小节主要详细介绍问题智能分类模块中,基于RNN-LSTM的事件单短文本分类模型的构建过程。包括数据预处理和模型训练两部分。
(1)数据预处理
● 数据选取
目前事件单的相对稳定类别有6种,我们从平台选取了6种类别下的事件单作为样本,平台中6种类别的比例近似为4 : 2 : 1 : 1 : 1 : 1。由于样本采集时具有随机性,我们需要对抽取的样本进行相应的扩充或缩减处理,保证样本类别分布均匀,接近平台的总分布。由于样本抽取的随机性,统计各类类别事件单在整个平台的分布,对每类类别下的样本进行扩充或缩减,保证样本类别分布均匀。
● 文本构成
每条事件单短文本由事件单标题、事件单内容、官方回复原因和回复备注组成,能够表达事件单的主要信息。
● 去除无信息模板文字及内容
事件单短文本中包含一些与类别无关的字句,给后面的文本建模带来一定的困难。通过正则匹配去除八类模型文字,例如手机号码、备注提醒、故障标题等。
● 分词
使用python最著名的分词工具jieba,结巴支持几个模式,精确模式、全模式、搜索引擎模式,各个模式有不同的适合场景。
● 生成索引词典
分词后的结果会包含很多无效的停用词等信息,会增加词典的冗余,引入停用词词典去除停用词,去除长度为1的词,去除数字和标点符号信息。将剩余有效词,按照词频从大到小排序,从0开始生成索引词典,每个词对应唯一序号索引。
● 文本向量化
使用 keras 的 Tokenizer 来实现,将文本处理成单词索引序列,单词与序号之间的对应关系靠步骤一的索引词典来记录。设置文本向量长度Max_len,然后用 keras 的pad_sequences将长度不足Max_len的文本用 0 填充(在前端填充)。最后通过 keras 的 to_categoric将标签处理成 one-hot 向量,例如 6 处理成 [0,0,0,0,0,1]。
(2)模型训练
对于RNN-LSTM模型的训练,共建立三层神经网络,分别为embedding层、LSTM层、Dense层,优化算法选择Adam(Adaptive Moment Estimation,自适应时刻估计)方法。参数设置见图3所示。首先embedding层将文本处理为向量,对于每个文本处理为Max_len * N的二维向量,Max_len是每个文本的固定长度,N为单词在空间中的词向量。其次,经过LSTM层将一个序列的词向量压缩成一个句向量,输出1 * N的向量。最后,一个Dense全连接层将长度收敛到6,对应6个类别。最终输出结果也是模型对于每个类别的预测概率值,且和为1。例如,输出结果为(0.8,0.1,0.1,0,0,0),说明此文本为类别1的概率为80%。在训练的过程中,可以将整个数据集分成若干个batch,每个batch包含一定数量的样本,然后每次更新一个batch的训练集参与运算,该方法不仅可以加快收敛速度,也减少了机器压力。为了防止过拟合,在LSTM层的各节点的训练中引入Dropout策略。
3.模型效果
基于RNN-LSTM的短文本分類器在训练集上表现很好,准确率达到92%,而在测试集上约为78%,个别类别达到85%。
三、平台应用效果
事件单问题智能系统的主要目的是支撑事件单的高效分类以及解决方案的自动匹配,以提升事件单处理的效率。系统应用过程中,关于事件单问题分类模型,每当平台中新的事件单生成,模型会自动对事件单进行处理并分类,并根据分类结果自动进行解决方案的匹配。解决了手工分类的问题,大大提高了事件单的处理速度。模型未上线时,事件单短文本分类主要依靠人工手工分类,平均每周用来处理手工分类的工作量至少需要8人时,模型上线后,通过自动分类匹配,后台模型运行平均耗时30分钟,较人工处理效率大幅提升,整体效率提升超过16倍。
同时,鉴于模型的自动分类,对于重复事件单的合并优化效率大幅提升,较人工手工分类时,事件单数量减少幅度超过30%,事件单量的显著下降有助于事件单系统的效率提升。
事件单问题智能系统上线测试后,“提效降量”效果显著。如图4所示系统上线的当年年底,事件单存量减少了63.6%,总量同比下降14.0%。事件单返单率较上线前降低了6.3%,打回率降低了8.53%,返单率和打回率均低于10%的目标值。
四、总结与展望
本文以AI人工智能技术为核心,通过深度学习RNNLSTM算法构建了事件单问题智能分类模型,极大地提高了短文本分类的准确率,实现了事件单非结构化文本数据的自动分类的应用。
在接下来的工作中,仍有一些问题值得研究和探讨:
模型准确率仍有提升空间,可以从样本和算法方面对模型进行优化。在样本方面,通过丰富训练样本数量,增加某分类下的样本数,进而提升模型对各类问题的文本识别能力,进而提升整体准确率。还可以通过梳理优化分词词典,优化分析结果。在算法方面,可以尝试集成学习方法 ,增加支持向量机等传统文本挖掘模型。
目前事件单问题智能系统只包括事件单分类和适配两大模块,功能相对单一,之后可以将应用范围扩展到舆情分析、热点话题识别等方面,同时结合数据可视化技术,将分析挖掘结果更好的在系统中呈现。
猜你喜欢
中国教育信息化·高教职教(2022年4期)2022-05-13
新高考·高一数学(2022年3期)2022-04-28
计算技术与自动化(2022年1期)2022-04-15
读者·原创版(2020年2期)2020-02-20
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
软件(2017年6期)2017-09-23
故事会(2016年21期)2016-11-10
高中生学习·高三版(2016年9期)2016-05-14
爆笑show(2015年12期)2016-01-07
新高考·高二数学(2015年11期)2015-12-23
