
基于Caffe深度学习框架的标签缺陷检测应用研究
2019-04-23 05:50李培秀李致金
中国电子科学研究院学报 2019年2期
李培秀,李致金,韩 可,朱 超
(南京信息工程大学 电子与信息工程学院,江苏 南京 210044)
0 引 言
人工智能是工业智能化的重要标志,是国家由制造向智造转型的战略支撑,同时也是工业4.0背景下研究的热门话题。基于深度学习的人工智能技术正在发挥着其不可替代的作用,尤其是在工程应用领域更是独树一帜。据此本文提出了基于Caffe深度学习框架的标签缺陷分类检测系统模型,紧跟时代的发展步伐,使得工程检测领域人工检测效率低、漏检错检率高的问题得到缓解。
以往标签缺陷检测算法是针对特定的图像制定出相应的特征模板,通过待检图像与特征模板的差分运算得出待检图像是否存在缺陷的结论,该方法模板制作繁琐,且存在人为不确定性因素影响检测效果,随着机器学习技术的发展,人们提出了基于SVM的标签缺陷检测算法,该算法较前一种算法无需复杂的模板制作[1-2],只需进行简单的图像处理就可以进行图像的特征提取及分类,但是该算法只适用于简单特征图像的分类检测,无法进行高精度图像特征分类处理,遇到一些特征不是很明显的图像就会出现漏检错检的问题,因此本文一种基于Caffe深度学习框架的标签缺陷检测算法应用研究,能够为解决上述两类算法遇到的问题提供一种很好的思路,在工程应用领域具有广泛的应用价值。
1 Caffe简介
近年来,智能研究领域的学者们都在关注深度学习(Deep Learning)这个技术。科研人员开发出众多的开源框架,如Caffe、Thensorflow、Theano等, Caffe(Convolutional architecture for fast feature embedding)是比较成熟的一类深度学习框架。伯克利视觉和学习中心(BVLC)在C++/Python/CUDA语言的基础之上开发出Caffe这个开源的卷积神经网络框架,该框架以‘层’为单位,使得框架结构清晰,代码的执行效率高且不失灵活性[3]。由于该框架使用了MKL、OpenBLAS、cuBLAS等计算库,并且兼容GPU加速,这使得它在处理大量数据时效率非常高,Caffe深度学习框架在图像特征提取方面具有很大的优势,尤其是它在处理数据时能实现可视化,使得提取图像特征的过程更加明了;不仅如此,Caffe更加人性化的提供了训练、预测、微调、发布、数据预处理及自动检测等一整套的工具。Caffe框架的提出,使得深度学习技术应用与研究的难度系数大大降低。
2 算法设计
2.1 标签缺陷识别系统
标签缺陷检测主要分为四个步骤:1)原始标签图像的采集;2)标签图像尺寸的调整,将原始采集到的图像设置成统一尺寸,为后续的特征提取做准备;3)图像特征提取,首先对图像特征点进行抽象,然后再进行特征的提取;4)图像识别,在Caffe深度学习框架下对含有相应特征的图像进行识别分类[4-5]。如图1所示该流程图为图像识别过程。

图1 标签缺陷识别流程图
2.2 卷积神经网络
卷积神经网络是在动物视觉原理的启发下设计而成,其包含卷积层、池化层及全连接层,它是前馈网络,具有很强的大数据处理能力。卷积神经网络具有三个特点,那就是局部感受野、权值共享和下采样。局部感受野可以找到图像的局部特征,如一段弧或者一个角度,更高层将局部信息综合整理到全局信息数据中,这种思想类似于人对外部信息从局部到全局的理解。权值共享能够精简训练及识别参数,下采样能够实现局部特性不变,相对于传统的图像分类算法,卷积神经网络具有鲜明的层次感[6]。
不仅如此,卷积神经网络就类似于一个黑盒子,使用者无需知道是如何进行的特征提取以及提取的何种特征。由于特征提取是在训练数据时进行自主学习的,该方法提取的特征更具有说服力以及一般特性。大大的提高的分类检测的效果。现在大多数应用的检测和识别系统都是基于该方法进行的数据处理及预判。
2.2.1 前向传播
如图2所示,卷积层、池化层及全连接层是经典神经网络的标准配置。在前向传播的处理过程中,卷积层利用卷积核与上一层输出的特征值进行卷积运算,然后再通过激活函数处理,得到卷积过后的特征图,作为下一层的输入数据,其中输出特征图的个数取决于卷积核的个数,计算方程为
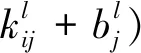
(1)
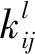
池化层即卷积层的特例,池化层采样核是依据算法的需要而设计的固定参数,不会在训练和学习的过程中发生改变,采样核函数逐个作用于输入的特征数据,并得到与之相应的特征输出值。因此特征图的输入输出数量相等,但是压缩了特征图的数据,有效的提高了特征图的鲁棒性[7-8],公式如下:
(2)
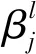
全连接层向前传播算法与传统BP神经网络算法基本相同,在计算前首先要将特征图从二维转化成一维向量,再执行全连接计算操作。其计算公式为:
(3)
卷积神经网络具有很强的图像分类效果,本文使用Softmax为分类损失函数,主要是因为其结构简单、效率高、且支持多种分类。前向传播中的损失计算如公式(4)所示:
(4)
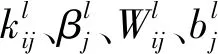

图2 卷积神经网络
2.2.2 反向传播
网络各层参数因反向传播而获得的梯度值进行相应调节,其中卷积层、池化层、损失层主要根据链式求导法则进行反向逐层计算。计算损失层梯度的公式,如式(5)所示:
(5)
式(5)中,L为最后一层输出数据,计算全连接层梯度公式,如式(6)所示:
(6)
(7)
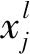
(8)
由上述基本理论得出各层参数的梯度,然后逐层更新参数,完成学习过程。
2.3 网络结构
文中使用的Caffe深度学习网络架构如图3所示,该架构在CaffeNet网络架构基础之上做了相关的调整,网络总有8层。输入数据为224×224的彩色图片,以及对应的标签,第一层为数据输入层,主要是将采集的数据图像读入到深度学习网络中,第二层是卷积核为5×5的卷积层,其卷积步长是1,卷积过后通过激活函数ReLU得到一个220×220尺寸的图片;第三层就是池化层,本文使用的是最大值池化的方法,采用2×2池化核,且步长为2,经过池化层运算之后网络输出110×110尺寸的图片;第四层和第五层重复上述第二第三层的卷积和池化操作之后,输出53×53尺寸的图片,第六层是我们常说的全连接层,该层有500个神经元,与第五层输出的神经元进行全连接操作,并通过激活函数ReLU运算后输出,第七层是全连接层,与第六层输出的神经元进行全连接操作,通过激活函数ReLU运算后输出,第八层也是全连接层,采用损失函数Softmax作用后输出,该层有4个输出神经元对应4类标签[9-13]。该网络的池化层能具有去除噪声功能,使网络适应性有所增强,ReLU层有助于网络的收敛,accuracy层计算测试精度,loss层计算训练过程中的损失值,并计算误差梯度。

图3 网络结构
3 实验与分析
3.1 实验条件
本文实验是在3.3GHz Intel Core i5-4590CPU的硬件和Ubuntu16.04LTS,Caffe等的软件配置下进行的。实验从印刷厂家分拣出的图片进行数据采集,制作实验数据集。参考文献[1]相比,本文算法无需进行识别图像的模板制作、模板匹配、差分运算后的对比识别等一系列复杂工作,且减少这些工艺过程中人为造成的误差,降低检测精度及效率。基于Caffe的深度学习模型,仅仅需要将数据集输入到模型后,该网络会根据数据集的特征进行相应模型的训练,以满足检测识别的要求。简化了检测程序,使得检测系统易于推广。
3.2 实验流程
该实验的基本流程如图4所示:

图4 算法流程图
首先是系统初始化,输入数据训练模型,由于深度神经网络需要大量的数据进行模型训练,才能防止模型的过拟合提高模型的泛化能力和分类准确率,而我们目前提供的数据集远远达不到训练模型时数据量的要求,因此,我们应该对训练数据集进行相应的数据扩充,主要根据数据采集时可能出现的亮暗程度的变化,对数据集扩充,其次我们对存在缺陷的数据集缺陷形状进行分析研究,比如线缺陷和面缺陷的形状进行镜像,以此扩充数据集,使其数量上满足训练要求,经过数据集的扩充之后进入模型的训练,经过5000次的迭代训练之后,该数据集通过学习得到一个比较稳定且检测效果的模型,该模型测试准确率可以达到97.66%,如图5所示。

图5 模型测试准确率
将相同的数据集按照参考文献[1]中提到的方法,首先进行图像模板制作,将多张完好的图像进行叠加运算后,制作出相应的模板图像,然后再将待检图像与模板图像进行配准操作,过程中存在许多的人为误差,最后进行图像差分运算,将运算后得到的特征图像输入到识别模型进行缺陷的识别,其识别准确率仅96.67%,与本文提出的算法相比检测准确率稍微偏低。
3.3 识别结果与分析
本文提出的基于Caffe框架深度学习模型在四类样本图像集基础之上进行试验,其中样本数据集分别是完好图片数据、点缺陷图片数据、线缺陷图片数据、面缺陷图片数据各700张进行实验。该模型训练损失曲线如图6所示:

图6 训练损失曲线
如图6所示,随着迭代次数的增加,该模型的损失曲线逐渐下降,根据深度学习理论知识可以得出,该模型随着迭代次数的增加,模型一直在学习新的特征,使得模型逐步得到优化,当迭代到5000次时,该模型损失曲线在0.1以下徘徊,此时该模型已经达到最佳效果,即图5所示模型的测试准确率达到峰值97.66%。
4 结 语
实验表明,本文提出的基于Caffe框架的深度学习算法模型,与参考文献[1]所提到的算法模型相比,本文算法无需进行检测前期的模板制作、校验及差分运算等工作,使得检测程序简单易于应用,同时该算法检测准确率也有了一定的提高,基本满足工程应用领域的检测要求,具有较好的应用前景。
猜你喜欢
现代电力(2022年2期)2022-05-23
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年13期)2020-01-14
电子制作(2019年19期)2019-11-23
电子制作(2019年11期)2019-07-04
电子制作(2019年24期)2019-02-23
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
北京航空航天大学学报(2018年1期)2018-04-20
Coco薇(2015年11期)2015-11-09
