
基于关键属性匹配的高校人员信息整合研究
2019-04-23 03:29,,,,
微型电脑应用 2019年2期
, , , ,
(同济大学 1.教育技术与计算中心;2.海洋科学技术研究中心;3.信息化办公室,上海 200092;4.电子与信息工程学院,上海 201804)
0 引言
我国高校信息化经过30年左右的快速发展,逐步重视业务流程优化和服务整合以适应智慧校园建设的需求[1]。由于缺乏统一标准、系统分散管理,造成数据不一致和不完整[2,3]。高校信息化需要通过有效的数据治理手段进一步提高数据质量,实现数据资源在各业务部门的有效整合和共享,使高校变得更加智慧和敏捷[4,5]。
为有效解决当前高校信息化中的数据质量问题,主数据管理受到重视,较好地实现了数据的深度共享和价值发现[6-8]。所谓主数据是信息系统中描述核心业务、实体并且在不同业务系统间共享使用的数据,是企业内部能够跨业务、跨系统重复使用的高价值数据[9]。高校信息化围绕“人”、“财”、“物”产生了大量的数据,而“人”的数据是最基本最核心的主数据。因此,同济大学在进行主数据管理时也从人员出发,设计适合高校人员的主数据模型[10]。高校的人员类型较一般企业复杂,同一个人同时存在多种身份,同时人员管理上也很分散,造成系统数据分散和重复,同一个人在不同的业务系统中,用不同的ID号表达。不同部门信息化管理水平的不同,也使得人员信息的质量参差不齐。只有人员信息经过整合后,才能使高校真正从以业务为核心向以人为核心的转化成为可能[11]。
将不同业务系统中以不同方式记录的人员数据,通过一定的算法识别为现实世界中的同一个人,是人员信息整合的基础。可疑重复处理作为主数据管理的关键技术之一,通过设置匹配关键元素或预置算法发现可能重复的记录[12]。高校人员的关键属性包括姓名、证件类型、证件号码、学号/工号等,本文在深入分析这些关键属性及其各种组合下出现的数据质量问题,提出一种基于关键属性匹配的高校人员信息整合方法,对人员赋予唯一编号标识,在实践中取得很好的应用效果,并促进高校人员的主数据管理工作。
1 高校人员数据的现状
高校人员指在高校中学习和工作过的学生和教职工,高校人员数据是由学校相应管理部门纳入业务管理系统的人员基本数据,诸如:人员的基本信息、学业信息、岗位信息等。
高校分而治之的管理以及各部门管理力度不一,使得高校中人员数据分散,缺乏统一的人员信息模型,没有进行一体化管理,造成数据质量问题。主要体现在以下几个方面:
(1) 人员数据来源多个系统且使用不同的主键标识
目前高校人员管理的主要部门为:人事处、教务处、研究生院、留学生办公室,分别对应管理:教职工、本科生、研究生、留学生,分别对应不同的管理系统,并使用不同的学号或工号(下称“学工号”)作为主键标识。
(2) 同一人员在不同阶段角色不一
同一系统中同一人不同阶段存在多个身份,如:研究生系统中不同的培养层次,如硕士生升入博士生,同一个人有不同的学号对应;人事系统中,从博士后、到派遣人员、到编制类人员或高研院人员,同一个人不同阶段有不同的工号对应。同一人同一身份在不同系统中,如本科长学制学生,在完成学业申请硕士学位前会以同一学号进入研究生系统,同一身份同时存在于两个系统。不同时期拥有相同的身份,如未取得学位的博士生几年后重新考取继续博士学位攻读,博士生阶段就有不同的学号对应。
(3) 源头数据录入带来的数据质量问题
源头数据甚至是关键数据都可能出现重复、不一致、不完整的情况。如:姓名拼写错误,证件号等关键信息为空,简体或繁体,缩写或全称,重复分配学工号,文本字段的不规范填写等。
(4) 历史数据遗留带来的数据质量问题
高校的人员管理系统已经运行多年,早期存在一些数据质量相对较低的人员信息,特别是人事系统中,上百年的教职工信息以及并校等原因,使得有些人员的关键信息不完整、不准确,且无从追查。
高校数据治理中最重要的一环是人员数据的治理,而人员信息的整合是数据治理的第一步。
2 高校人员信息整合的方法
人员数据是高校所有核心数据中的主数据,是学校所有业务运行的基础,其数据质量的好坏直接影响到对师生管理和服务水平的提高。
2.1 总体思路
将一个人多个系统中不同阶段的多个身份,通过算法将其识别为同一个人,并用校内唯一的人员唯一编号PID(Person ID)予以标识,即将人次转化为人,根据设计的一体化人员信息模型,对其全生命周期进行管理,将不同阶段的信息作为其全生命周期的一个片段,即达到人员整合的目的,如图1所示。
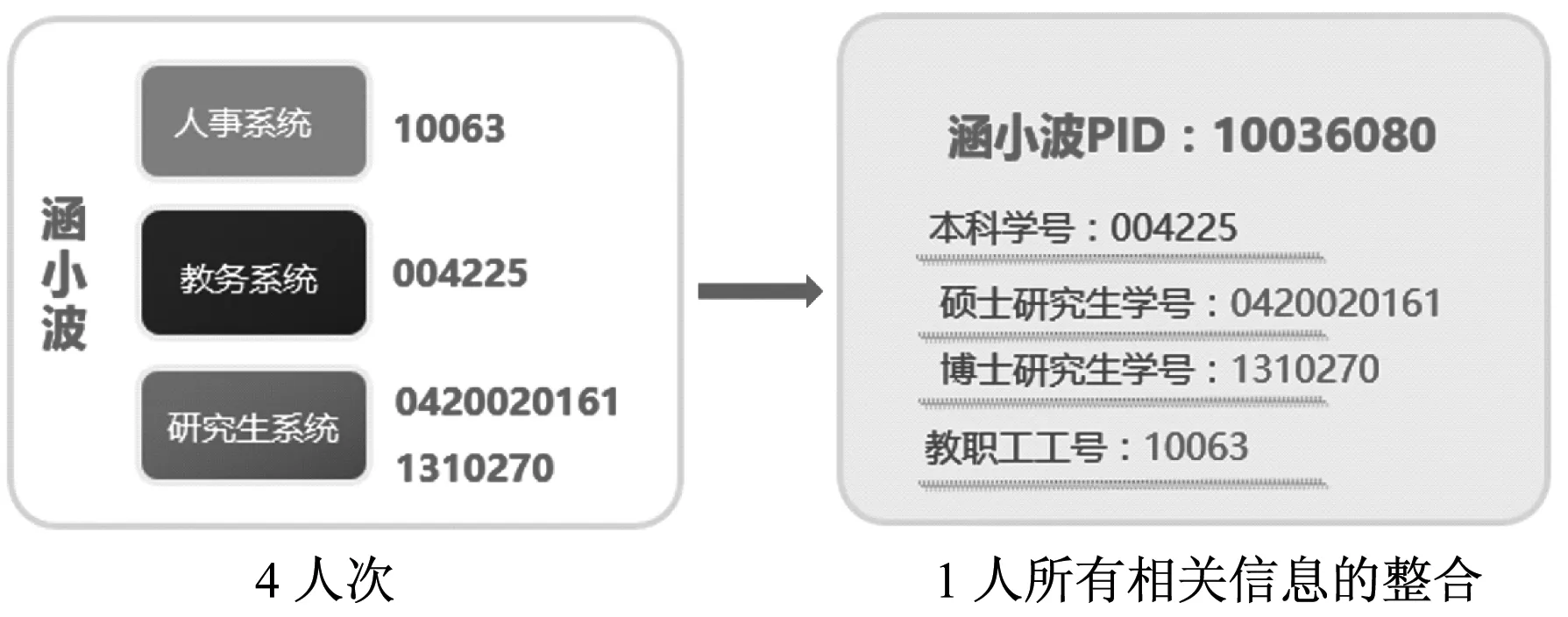
图1 高校人员信息整合的总体思路
2.2 问题分析
解决思路的关键在于从现有纷繁复杂的人员信息中判断是否为同一个人。从图1看出同一个人的学工号并不唯一,只能作为重要参考信息。而作为人员的关键属性如身份证、姓名等理论上是可以唯一确定的,但是因各种数据质量问题使得判断依据变得复杂。
(1) 姓名问题
相同的证件号,在不同系统甚至同一个系统中,姓名存在各种差异,如同音字、生僻字用符号或拼音代替、少数名族姓名中间点等等。
(2) 证件号问题
除很多由于历史遗留问题或留学生护照号获取有延迟,造成证件号为空的情况外,对于有证件号的数据,也存在身份证号不是15或18位的、年份生日不合规的、含有特殊字符的等问题。
(3) 复合问题
从姓名、证件号单一来看,数据都是规范的,但将数据综合起来分析时,会发现较多的问题,诸如:两人共用证件号、两人共用学工号、同一个人在不同系统中的证件号不同等。
2.3 算法流程
针对前文所述的数据特点和数据质量的现状,提出人员信息整合的原则:1)定期获取业务系统的人员数据,并获得增量变化数据;2)选取关键属性进行组合判断:姓名+证件号+证件类型+学工号;3)在算法中多层次考虑组合属性数据质量可能造成的影响判断的因素;4)算法能处理相对规范化的情况,对于个别异常情况的数据,增加可疑数据人工处理的环节;5)历史无从确认的数据,对于关键属性不全的,为其执行一次性的初始化算法,当其后续信息不再改变时,这些历史人员不再纳入算法。
根据这些原则,人员整合的算法流程分为3个步骤实施。如图2所示。
(1) 数据预处理
数据仓库每天从源头系统中获取增量数据,检查数据关键信息的完整性,对证件号进行必要的规范化处理,梳理出具备条件进入下一环节的数据,其过程如图3所示。
(2) 基于关键属性匹配的人员唯一性识别
采用人员的关键属性:姓名、证件类型、证件号码(下称“名”、“类”、“号”)作为基本的判断条件,辅以学工号作为补充判断依据,详细过程如图4所示。
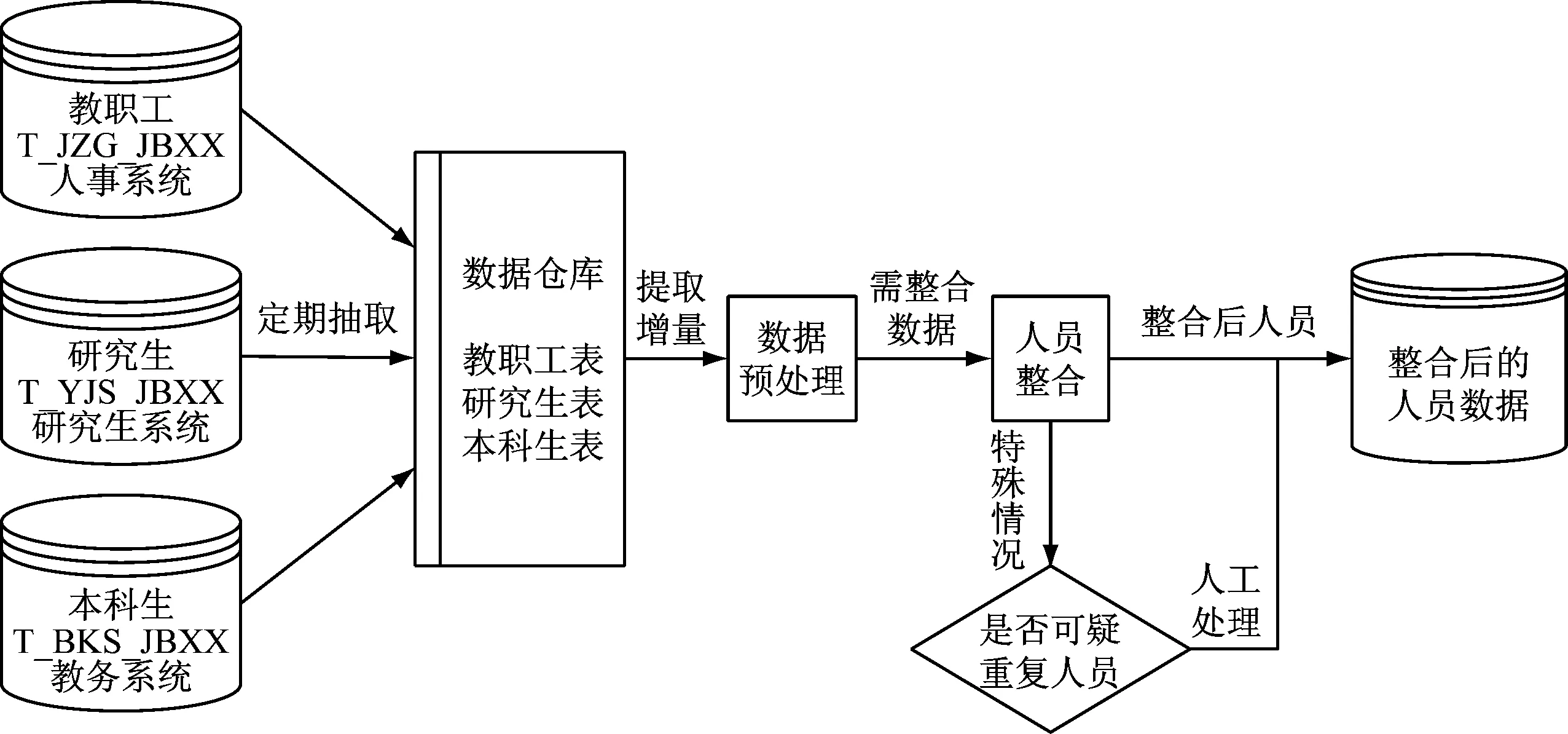
图2 高校人员信息整合的算法流程
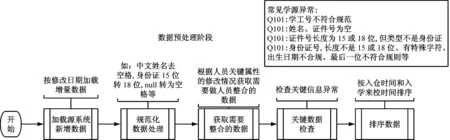
图3 高校人员信息整合数据预处理
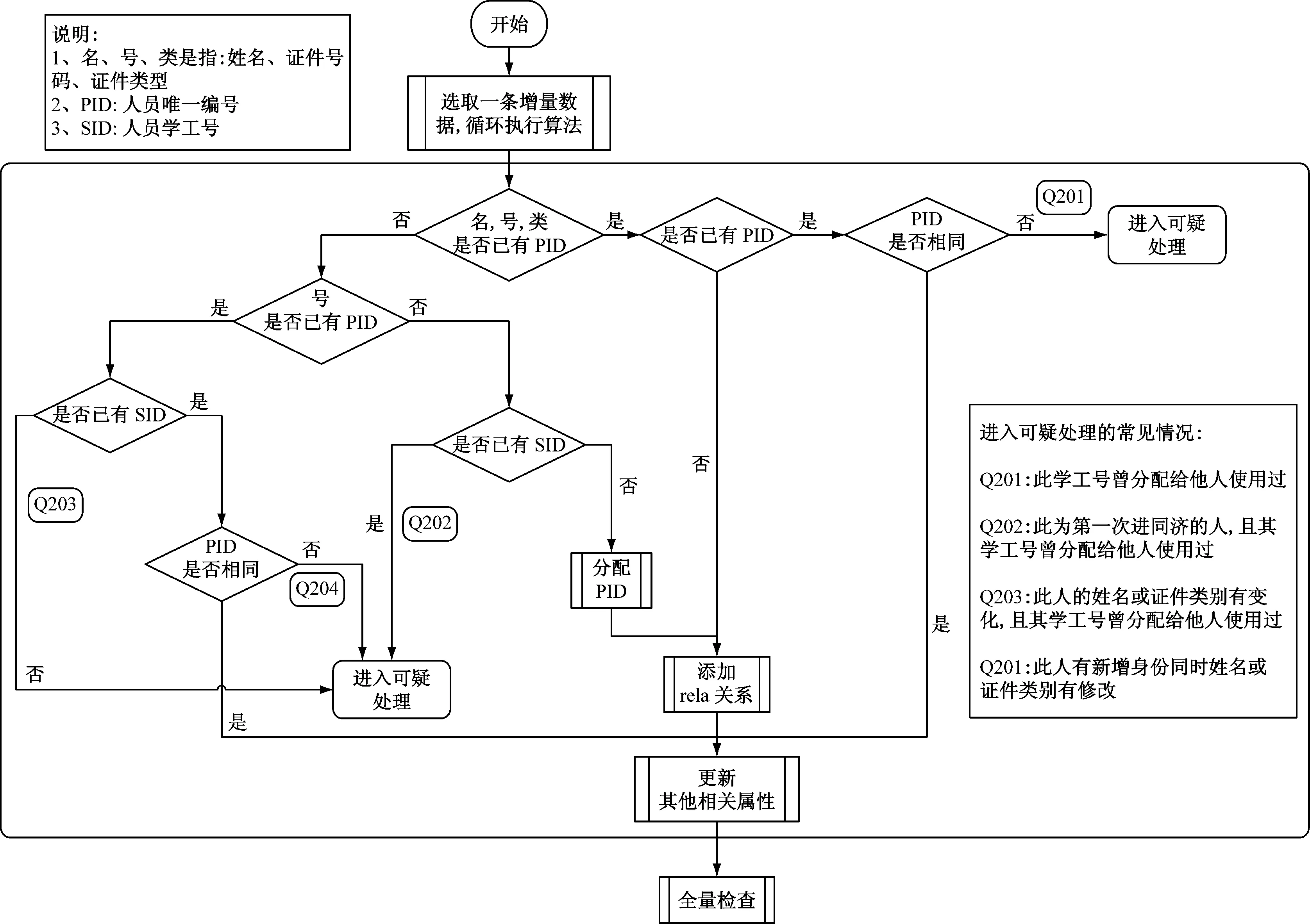
图4 基于关键属性匹配规则的人员识别
将不同阶段用不同身份标识的一个人识别为同一个人,整合后将为其分配唯一编号PID,区别于源业务系统中的学工号(源业务系统为管理需要为人员分配的ID号,下称“SID”)。
人员整合后,将产生一个完整的PID列表存放一个人的PID及对应的关键属性(即PID信息表,下称“info表”),另外还有一个表达PID和SID之间关系的列表(即PID与SID关联表,下称“rela表”)。通过这两个列表,可以将人的所有信息表达完整。
对于所有的人员,正常流程主要有两类,一类是全新的人,第一次进入某一个人员系统,在关键组合信息规范完整的情况下,算法为其分配一个新PID;一类是新的身份,诸如升学本校研究生、留校任教、转编等环节,在关键组合信息规范一致的情况下,算法将现有PID和新SID进行关联。
流程中的异常分支,主要用于处理和识别非正常的情况,如证件号、学工号被共用,录入时证件号、姓名等关键字段不一致等。算法中将这些无法自动识别的信息记录到异常表中,进入可疑处理环节。
(3) 可疑数据人工处理
对于算法无法处理的异常问题,将其详细展示并进行人工处理,如图5所示。由专门人员进行核查,确认需要新增的人员为其分配新的PID,确认是原先存在的人员,将信息合并到原PID中。对于错误的信息,则提交源头系统修正,对于无效的信息,则将异常记录忽略。
对于与源头确认修改正确的人员数据,实现合并、失效、更新等操作,将确定正确的修改直接作用到人员整合结果集中。如:当源头修改了一个现有人员(PID、SID已有)的证件号时,算法抛出Q202异常,并将异常详细信息展示出来。异常信息经过源业务管理员确认,若是该人员修改了证件号,则将新证件号关联到原PID上;若是该SID给了一个新进人员使用,则为该人员分配一个新PID,将证件号与新PID进行关联;若是本次证件号修改为一个误操作,则将该异常忽略,不做任何改动。
经过人工确认后的异常,如果是需要源系统修改的问题,源头管理人员操作修改后的数据将进入下一轮的算法整合,正确的修改便直接作用到人员整合结果集中。
主要问题包含:1)数据完整性不够:如身份证号为空或不符合规范,这类问题须源头将数据进行完整化后再行处理。2)源头纠错产生的各种异常情况需要确认:如源头发现同一个人分配了多个工号后,将其中一个工号重新分给了另外一个新进校人员等。此类非常规性问题,需要数据源头进行确认后进行对应操作。3)全量检查异常问题:源头系统中人员或历史数据经过人员整合步骤后,并未为其生成PID的情况。有些异常数据由于师生离校时间太长,源业务管理人员也无法确认其数据的正确性,这些数据将保留在异常数据历史表中存放,管理人员可方便地在平台上查看,待时机成熟时再行处理,如图5所示。

图5 可疑数据处理
3 高校人员信息整合的实践效果
以同济大学为例,从2014年开始建设数据仓库,现已将所有重要业务系统的重要数据都入仓,并每天抽取一份全量数据,人员整合方案便是建立在数据仓库的基础上进行的。
通过人员整合算法,第一步对学校所有在系统中管理的人员实施整合,截止2017年10月20日,将原有的234 519人整合为205 732人,效果如图6所示。

图6 高校人员信息整合效果
一个人在校园生活中存在的多个身份也能直观地展示出来,如图7所示。
结合人员整合的运维功能,从运维平台界面上可以直观地查看每天整合完成的情况,如图8所示。
4 总结
人员信息整合后形成的人员“黄金视图”,是精确的、完整的、可信任的人员信息,是提供个性化、精细化、精准服务的基础。同济大学于2015年开始引入同心云平台,成为了学校正式使用的官方云平台,其中聚集着各类师生的服务应用,有专门针对教师的、有针对学生的、有向全体开放的、有只对研究生开放的等等,这些应用统一通过整合后人员对外提供接口,自动识别用户是否为该应用的合法用户。除此之外,整合后的人员信息还正在用于支撑学校的身份认证系统、校级的综合性应用、校友的精准服务等。
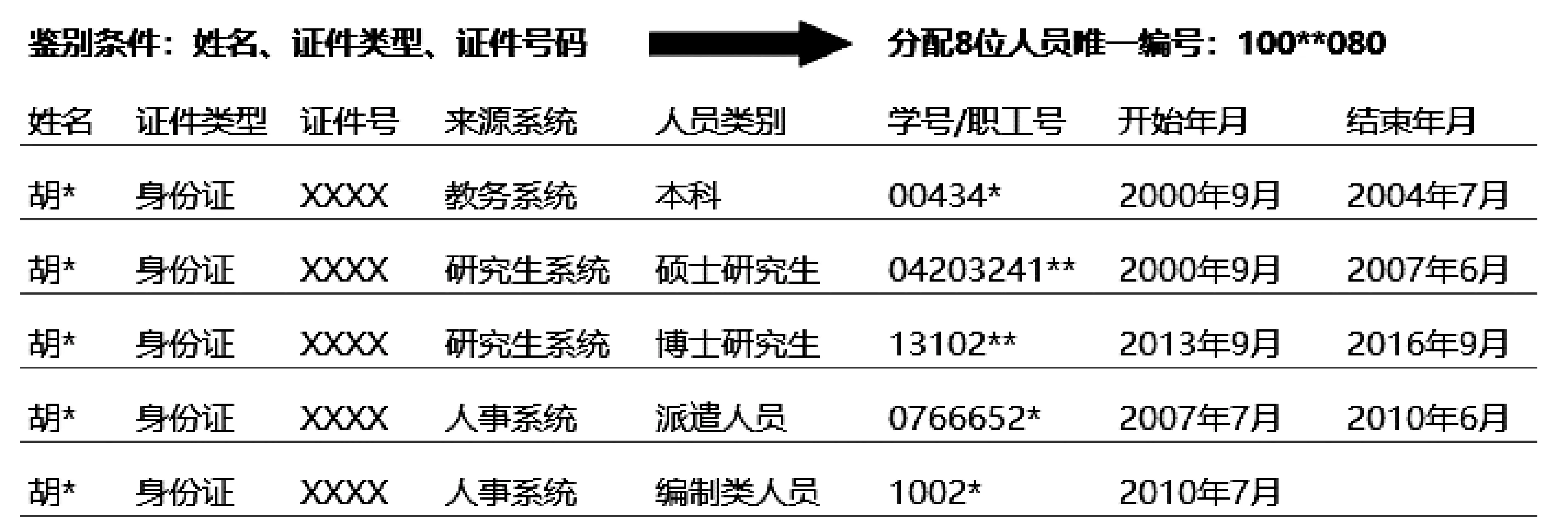
图7 高校人员的多重身份展示效果
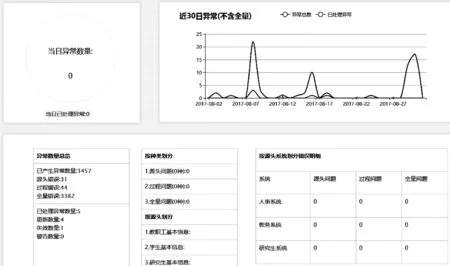
图8 高校人员信息整合运维平台
目前人员信息整合还是数据治理的第一步初探工作,焦点主要集中在梳理人员既有数据,致力于形成一套经过整合可信赖的人员库,目前已经基本达到该既定目标。但人员信息整合和数据治理的目标还远远没有达到,接下来主要从以下两个方面进一步探索:1)与主数据管理相结合,在人员信息的产生环节就进行人员整合,减少产生数据质量问题的源头,从而形成更加有效的整合机制;2)探索逐步形成数据治理闭环机制,从数据的产生、整合处理、应用各环节形成闭环,完善数据处理的管理规范,从而长效地促进治理体系和治理能力的提升。
猜你喜欢
小雪花·初中高分作文(2021年3期)2021-08-27
中华诗词(2019年10期)2019-09-19
长江丛刊(2019年16期)2019-07-12
湘潮(上半月)(2019年6期)2019-05-22
课程教育研究(2018年14期)2018-06-07
劳动保护(2018年5期)2018-06-05
新校园·上旬刊(2017年11期)2018-01-23
百科知识(2016年16期)2016-10-29
小说月刊(2015年12期)2015-04-23
