
云存储环境下的密文检索研究*
2019-04-23 03:56:38张昌宏
火力与指挥控制 2019年3期
陈 元,张昌宏,付 伟
(海军工程大学,武汉 430033)
0 引言
近些年来,随着IT行业和计算机领域的迅速发展,数据量正呈现爆炸式的增长[1]。为高效存储和处理这些海量数据,云计算[2-3]与云存储技术[4-6]应运而生。用户可以将数据以外包的方式存储至云服务提供商(CSP,Cloud Service Provider),实现资源存储云化。对用户而言,这种存储模式可以降低存储和计算成本,而且云服务器具有按需服务和按服务收费等优势,符合当前绿色计算和低碳经济的发展趋势[7]。
在云服务快速发展的同时,其安全性问题也日益突出,尤其是存储数据的安全性与隐私保护问题[8-12]。如果用户将自身的隐私敏感数据完全暴露给云服务器,将存在极大的安全隐患。用户可以将明文数据加密后再上传至服务器,但这又会影响数据的可用性。当用户需要检索某个文档时,需要将云端的数据全部下载到本地再进行查询,浪费了大量的网络带宽且效率较低。因此,云存储环境下的密文检索技术是目前的研究热点之一。
1 密文检索
1.1 密文检索的应用场景
本文将CSP视为“忠实但好奇(Honest but Curious)”的半可信敌手模型。一方面,CSP能够忠实履行与用户之间的服务等级协定(SLA,Service Level Agreement)[13],向其提供稳定的数据上传、下载及检索等服务;另一方面,CSP出于好奇会对用户的访问行为和记录进行分析,因此,用户隐私敏感信息存在着一定的安全性威胁,例如照片、邮件、通讯录、个人账户等个人用户信息、政务商务机密,以及医疗机构中存储的患者隐私等企业用户信息。
同时,SLA实质上只是一种信任契约,没有统一的标准,缺乏有效的验证途径,因此,无法解决目前存在的信任悖论问题。一方面,CSP会信誓旦旦地承诺服务的安全性和可靠性;另一方面,用户却无法通过行之有效的技术手段对SLA进行验证并阻止CSP的不正当行为。由于信息存在不对称性,用户很难发现服务商的违约行为;而当用户违约时,服务商则能立即发现并制止其行为。信任悖论问题导致用户不敢放心地将数据上传至云服务器进行保存。
1.2 密文检索需求分析
针对云计算与云存储服务中存在的安全威胁和信任悖论问题,相关学者提出了密文检索技术。为保证核心隐私敏感数据的安全,用户可以选择将其加密后再上传至云服务器上进行存储。密文检索技术使得数据查询操作可以直接在密文上进行,既保证了数据的机密性,又极大地提高了检索效率。
1.2.1 密文检索中数据的特点
与传统数据相比,密文检索中的数据通常具有以下几个特点:
1)海量性(Massive):由于云存储用户数量众多,且每个用户所存储的隐私数据量比较大,因此,密文检索中的数据是海量的,一般可以达到TB级甚至PB级;
2)外包性(Outsourced):密文数据以外包的形式存储在云端,用户通过网络与云存储服务提供商联系,因此,根本无法知道数据存储在哪个网络节点上,甚至不知道存储在哪个国家或地区;
3)机密性(Confidential):出于对数据安全性的考虑,用户将其核心隐私敏感数据加密后再发送给云存储服务提供商;
4)可用性(Available):数据的可用性是服务商必须首先解决的问题,也是用户最关心的问题。可检索性也是可用性的一个方面;
5)异构性(Heterogeneous):数据的存储、使用、授权方式和访问控制策略都不尽相同,因此,存在明显的异构性;
6)混杂性(Mixed):云存储平台通常采用多租户机制,因此,一个存储节点上可能同时存储多个用户的数据,一个用户的数据也可能存储在不同的节点上。
1.2.2 密文检索中数据的安全需求
相比于传统的数据存储方式,云存储具有诸多优势,但是出于安全方面的因素,用户仍然不敢将隐私数据存储在云服务器上。目前密文检索中的数据主要有以下几个安全需求:
1)数据的隐私保护能力需要进一步提高。由于在云存储环境下用户数据具有外包性,如果没有可靠的技术手段对数据进行隐私保护,而只是单纯地依靠SLA协定对服务商的行为进行约束,这显然不能满足数据的安全需求;此外,由于数据具有混杂性,在一个节点上会同时存储多个用户的数据,而不是绝对的物理隔离,同样会带来安全隐患;
2)数据的完整性验证机制有待进一步增强。完善和增强数据的完整性验证机制也是目前需要迫切解决的问题。保证数据的完整性是服务双方合作的基础,用户数据在存储和处理的过程中,不能被恶意修改或破坏;
3)数据的可用性需要得到更强大的技术保障。传统的明文数据检索技术通常无法适用于密文的检索,为保证加密后数据的可用性,服务商需要给用户提供安全有效的可检索加密技术。
1.3 密文检索中的挑战性问题
密文检索方法主要分为两种:一种是基于密文的检索方法,用户直接将加密后的文件上传至云端,检索时需要对密文全文进行扫描匹配,得到与关键词相同或相近的密文;另一种是基于索引的检索方法,用户需要事先提取明文中的关键词,构建索引结构,然后将加密后的密文和索引文件上传至云端,检索时只需比对关键词和索引文件即可得到相应的密文。
密文检索中的挑战性问题主要是如何在保证用户核心隐私敏感数据安全性的同时,实现高效的检索匹配以得到相应的密文数据。同时,如何实现密文数据的多用户检索、多关键字检索、模糊检索、区间检索以及支持结果集排序的Top-k检索,也是密文检索中的一个挑战性问题。
2 密文检索的通用模型与基本框架
本文对现有的密文检索方案进行研究和分析,提出云存储环境下的密文检索通用模型与基本框架。
2.1 通用模型
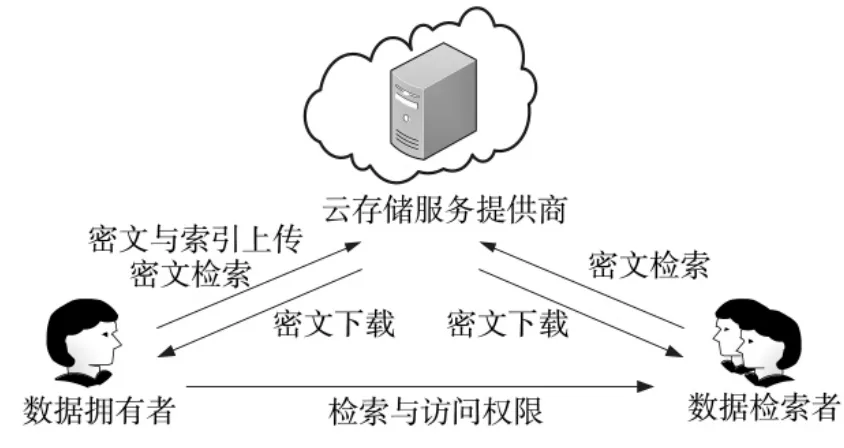
图1 云存储环境下的密文检索通用模型
如图1所示,云存储环境下的密文检索通用模型主要由3个角色组成:数据拥有者(DO,Data Owner)、云存储服务提供商(CSP,Cloud Storage Provider)和数据检索者(DS,Data Searcher)。
1)DO:如果采用基于密文的检索方法,数据拥有者可以直接将自身的核心隐私敏感数据加密后发送给CSP;如果采用基于索引的检索方法,则用户需要事先从明文中提取关键词,并构建索引结构,然后将加密后的密文和索引文件一起上传至CSP;同时DO可以向CSP提出密文检索请求;
2)CSP:向用户DO和DS提供数据存储、下载及检索服务;
3)DS:数据检索者经DO授权后可以向CSP提出密文检索请求并获取相应的数据信息。
2.2 基本框架
本文以基于索引的密文检索方法为例,对云存储环境下的密文检索基本框架进行描述,框架主要由以下几个多项式时间的算法构成:
1)Setup(k;sp,sk):概率密钥生成算法。由数据拥有者DO执行,对系统进行初始化。输入:安全参数k,输出:系统参数sp和系统密钥sk;
2)BuildIndex(D;I):确定性索引构建算法。由数据拥有者DO执行,提取明文关键词并构建文档索引结构。输入:明文文档D,输出:索引结构I;
3)Enc(D,I,sk;ED,EI):确定性加密算法。由数据拥有者DO执行,加密明文文档和索引结构。输入:明文文档D、索引结构I和系统密钥sk,输出:密文文档ED和密文索引结构EI;
4)Trapdoor(w,sk;Tw):确定性陷门生成算法。由数据检索者DS执行,生成关键词陷门。输入:检索关键词w和系统密钥sk,输出:关键词陷门Tw;
5)Search(Tw,EI;ED):确定性检索算法。由云存储服务提供商CSP执行,检索关键词对应的密文文档。输入:关键词陷门Tw和密文索引结构EI,输出:关键词w对应的密文文档ED;
6)Dec(ED,sk;D):确定性解密算法。由数据检索者DS执行,得到检索到的明文文档。输入:密文文档ED和系统私钥sk,输出:明文文档D。
在基于密文的检索方法中,不存在文档索引结构,因此,其基本框架中不存在第二步;另外,检索时需要对密文全文进行扫描匹配,得到与关键词相同或相近的密文文档。
3 密文检索方案的评价体系
国内外专家学者提出许多针对云存储应用场景下的密文检索方案,其评价指标主要包括以下几个方面:
1)安全性:要求数据的上传、下载和检索都是在密文状态下进行,以保证用户核心隐私敏感数据的安全性,包括明文、关键词索引及陷门和检索过程的安全性。高安全性的方案能够抵御统计分析攻击,具有适应性不可区分安全、适应性语义安全和抵抗非自适应性选择关键词攻击的语义安全(IND-CKA、IND-CKA2)等[14];
2)高效性:符合绿色计算的要求,既要减小存储空间,又要保证密文检索的效率,这里所说的存储空间主要是指关键词索引所占的存储空间。高效性的衡量标准主要包括时间复杂度和空间复杂度;
3)正确性验证:方案支持检索结果的正确性验证,通常采用正确率和召回率作为检索结果的验证参数,其中正确率是指检索结果中与检索陷门相关的文档数占检索结果总文档数的比例,召回率是指检索结果中与检索陷门相关的文档数占用户云端密文总文档数的比例;
4)可靠性:方案能够给用户提供可靠的数据存储和密文检索服务。
4 不同类型的密文检索方案对比分析
根据检索方法的不同,可以将其分为基于密文全文的检索方法和基于密文索引的检索方法。
4.1 基于密文全文的检索方法
Song等人[15]首次提出可搜索加密(SE,Searchable Encryption)的概念,并设计实现了一种基于对称密码体制的密文检索方案。方案用由伪随机数和校验数生成的流密码对用户数据进行加密,只有加密后的用户数据、检索陷门和检索结果会暴露给不可信的服务商,保证了数据的安全性,同时证明了方案具有一定的可行性。但是方案采用基于密文全文的检索方法,直接将陷门关键字与密文全文进行线性比对,效率比较低,方案只适用于单用户、单关键字的精确检索,且不支持结果集排序。
文献[15]方案主要由以下几个步骤组成:
1)Setup(k;sp,sk):概率密钥生成算法。由数据拥有者DO执行,对系统进行初始化。输入:安全参数k,输出:系统参数sp和系统密钥sk;
2)Enc(D,sk;ED):确定性加密算法。由数据拥有者DO执行,加密明文文档。输入:明文文档D和系统密钥sk,输出:密文文档ED;具体做法如下:首先将明文单词的长度均转换为n bit,采用分组加密函数和系统密钥加密明文单词;通过流密码生成一组长度为n-m bit的伪随机数;将加密后的明文单词分成长度为n-m bit和m bit的L和R两部分;通过散列函数处理L得到密钥sk’;通过伪随机函数和密钥sk’处理n-m比特位的伪随机数,得到长度为m bit的数,然后将其填充到n-m位的伪随机数后,得到长度为n bit的数;最后将其与加密后的明文单词按位异或,得到密文ED;
3)Trapdoor(w,sk;Tw):确定性陷门生成算法。由数据检索者DS执行,生成关键词陷门。输入:检索关键词w和系统密钥sk,输出:关键词陷门Tw;采用步骤2)中的分组加密函数和系统密钥加密检索关键词w得到关键词陷门Tw;
4)Search(Tw;ED):确定性检索算法。由云存储服务提供商CSP执行,检索关键词对应的密文文档。输入:关键词陷门Tw,输出:关键词w对应的密文文档ED;依次将关键词陷门Tw与密文中的单词按位异或;
5)Dec(ED,sk;D):确定性解密算法。由数据检索者DS执行,得到检索到的明文文档。输入:密文文档ED和系统私钥sk,输出:明文文档D;首先将n-m位的伪随机数与密文的前n-m位按位异或,得到L;然后由散列函数和L得到sk’,最后解密密文得到密文D。
上述方案虽然实现了基本的密文检索功能,但是安全性和效率都比较低,不能抵御统计分析攻击,不支持检索结果的正确性验证;同时,采用由伪随机数和校验数生成的流密码作为密钥,给密钥的管理带来了困难。
Dan Boneh等人[16]提出一种基于公钥加密的关键词检索方案,同样需要对关键词和密文进行扫描匹配,适用范围较小且效率较低。为了提高检索效率,Bethencourt等人[17-18]在文献[15]方案的基础上提出了基于Paillier加解密算法[19]的密文检索方案,方案采用非对称密码体制,并通过缓存器来存储一些数据流,检索效率比较高且算法具有部分同态加密的性质。Curtmola等人[20]在文献[15]方案的基础上,提出了可搜索对称加密方案SSE1、SSE2,通过增加和优化索引结构提高了检索效率,同时方案将应用场景由单用户检索扩展到多用户检索,密文检索用户不再限制于数据拥有者,授权用户同样可以对云端密文进行检索。
在基于密文全文的检索方法中,用户数据加密、陷门生成和数据解密都是在客户端完成,只有密文检索部分是在服务器上执行,因此,CSP不会获得明文信息,保证了用户数据的机密性。但是检索时需要将陷门关键词与密文全文进行线性地扫描匹配比对,效率较低,不能满足云存储场景下海量数据的应用需求。
4.2 基于密文索引的检索方法
针对基于密文全文的检索方法不能满足云存储场景下海量数据的应用需求问题,相关学者提出基于密文索引的检索方法。用户需要事先提取明文中的关键词,构建索引结构,然后将加密后的密文和索引文件上传至云端,检索时只需比对陷门关键词和索引文件即可得到相应的密文。
Goh等人[21]定义了一种基于伪随机函数和布隆过滤器的安全索引—Z索引,构建了安全模型,并形式化地证明了模型具有可以抵御非自适应选择关键字攻击的语义安全,方案效率较高并且可以抵抗选择明文攻击。
文献[21]方案主要由以下几个步骤组成:
1)Setup(k;sp,sk):概率密钥生成算法。由数据拥有者DO执行,对系统进行初始化。输入:安全参数k,输出:系统参数sp和系统密钥sk;sk由伪随机函数映射生成;
2)BuildIndex(D,sk;I):确定性索引构建算法。由数据拥有者DO执行,提取明文关键词w并构建文档索引结构。输入:明文文档D和系统密钥sk,输出:索引结构I;索引结构通过布隆过滤器存储;D中包含文档的唯一标识符 Did;计算和;然后将y插入到布隆过滤器中,并将其作为文档的索引结构;
3)Enc(D,sk;ED):确定性加密算法。由数据拥有者DO执行,加密明文文档。输入:明文文档D和系统密钥sk,输出:密文文档ED;
4)Trapdoor(sw,sk;Tw):确定性陷门生成算法。由数据检索者DS执行,生成关键词陷门。输入:检索关键词sw和系统密钥sk,输出:关键词陷门Tw;为查询单射函数;
5)Search(Tw,I;ED):确定性检索算法。由云存储服务提供商CSP执行,检索关键词对应的密文文档。输入:关键词陷门Tw和密文索引结构I,输出:关键词w对应的密文文档ED;计算和,然后查询y是否在索引结构布隆过滤器中,完成检索;
6)Dec(ED,sk;D):确定性解密算法。由数据检索者DS执行,得到检索到的明文文档。输入:密文文档ED和系统私钥sk,输出:明文文档D。
上述方案的第 1、2、3、4、6 步均在客户端完成,只有第5步检索部分是在服务器上执行,因此,CSP不会获得明文信息,保证了用户数据的机密性。同时,布隆过滤器的存储空间较小且存储和检索效率较高,但是查询比对时存在误判率和假阳性,不适合对检索匹配精度要求比较高的场景。
Cao等人[22]首次定义并解决了云计算环境下基于隐私保护的密文多关键字排序查询问题,方案将密文索引和检索陷门通过编码的方式转换为向量,并将两者的内积作为匹配相似值,虽然实现了多关键字的密文排序检索,但是由于检索过程中需要线性扫描密文索引,所以效率较低,同时查询前需要检索用户掌握索引的列表及位置信息。Fu等人[23]提出支持同义词查询的密文多关键字排序检索方案,在文献[22]方案的基础上引入了二叉树结构存储密文索引及其向量,检索效率有所提高。杨旸等人[24]提出基于域加权和语义相似度的多关键字密文排序检索方案,通过域加权评分和语义相似度评分构建索引,创建文档向量并将其分块处理,通过匹配文档向量和查询向量实现了密文排序检索,方案的效率比较高但是安全性有所降低。那海洋等人[25]将B+树形结构的思想引入索引构建方案中,降低了索引空间的复杂度并提高了检索效率,方案通过关键字匹配和相关度分数实现了检索结果集排序,但是安全性不高且不支持检索结果的正确性验证。
在基于密文索引的检索方法中,用户的核心隐私敏感数据、索引结构以及检索陷门都是以密文的形式发送给CSP,保证了数据的机密性。与基于密文全文的检索方法相比,基于密文索引的检索方法安全性和效率都比较高,更适用于云存储环境下的密文检索场景。
5 密文检索的发展趋势分析
1)目前大多数密文检索方案只适用于单用户检索,但是在云存储环境下,数据通常都是由多个授权用户共享的,因此,设计适用于多用户的密文检索方案是十分必要的。
2)在云存储环境下,由于用户数据规模较大,如果密文检索方案只支持单关键字检索,将会检索出大量与用户需求无关的文档;多关键字检索可以设置多个检索条件和陷门,可以检索出更符合用户需求的文档,而且可以节省网络带宽。因此,密文检索由单关键字检索逐渐向多关键字检索扩展。
3)根据检索匹配精度的不同,可以将密文检索技术分为精确密文检索和模糊密文检索。在传统的明文检索技术中,由于检索用户掌握的数据与真实数据之间存在着误差,仅仅依靠精确匹配无法完成相应的检索功能,因此,支持模糊匹配是十分必要的。同样,在密文检索中,即使明文数据之间存在较小的误差,加密后的密文之间的误差也会变得很大,因此,需要服务器检索系统支持模糊检索功能。
4)区间检索是对数据进行检索的主要方式之一。在明文区间检索中,用户向服务器提供检索区间,然后服务器将关键字在检索区间内的所有数据反馈给用户。但是在密文区间检索中,为保证敏感数据的机密性,用户需将加密后的检索区间陷门发送给服务器,服务器运行检索算法后将符合条件的密文反馈给用户,由私钥解密后得到相应的明文数据。由于检索需要在密文状态下进行,所以如何在保证安全性的同时实现高效的区间检索是目前的主要难题。
5)由于在云端存储的用户密文文档是海量的,而且检索成功的文档也比较多,因此,需要对检索结果集进行排序,以返回最符合用户需求的Top-K个结果,同时可以节省网络带宽和资源开销,降低用户成本。
6 结论
本文首先介绍了云存储环境下密文检索的应用场景,分析了密文检索中数据的特点和安全需求,并提出了其中的挑战性问题。通过研究现有的密文检索方案,提出了云存储环境下的密文检索通用模型与基本框架,并构建了方案的评价体系。根据检索方法的不同,将密文检索分为基于密文全文的检索方法和基于密文索引的检索方法,并详细分析了其中的一些经典方案。最后,指出了当前密文检索方案中主要存在的问题,并对密文检索的发展趋势进行分析。
猜你喜欢
知音励志·社科版(2016年8期)2016-11-05 04:07:52
科技视界(2016年18期)2016-11-03 22:37:55
现代经济信息(2016年19期)2016-10-20 20:32:47
考试周刊(2016年79期)2016-10-13 22:42:09
科技视界(2016年24期)2016-10-11 00:00:21
考试周刊(2016年76期)2016-10-09 09:22:30
成才之路(2016年27期)2016-09-30 16:28:59
商(2016年11期)2016-05-04 15:03:21
北方文学·中旬(2016年3期)2016-04-29 08:43:16
