
科学家相关性测度典型算法比较与评析
2019-04-19 01:09:44吴振新单嵩岩
数字图书馆论坛 2019年3期
吴振新 单嵩岩
(1.中国科学院文献情报中心,北京 100190;2.中国科学院大学图书情报与档案管理系,北京 100049)
20世纪末期,学术界发起了一系列旨在克服传统科学弊端的学术运动。这些运动凸显了“自由、开放、合作、共享”的理念,与传统科学文化的封闭性形成鲜明的对比,学术界将之称为开放科学运动[1]。开放科学是一个广义的概念,用于描述科学研究开展的方式,包括运用技术使研究活动更具协作性和开放性。开放科学环境为科研人员提供更多的知识获取途径,更为关键的是开放交流模型为科研人员提供更广泛地寻求潜在的科研合作对象/团体的可能,极大地促进了科研合作共享。因此,科研合作也成为开放科学环境中信息服务的一个重要内容。
为了更好地支持科研、服务科研,很多信息服务机构开始提供科研合作预测分析,并将其作为融入科研一线的智能知识服务的一项重要内容,科研合作关系预测的研究引起了更多的关注。作为科研预测研究的关键技术之一,科学家相关性计算随之得到越来越多的重视,取得不错的进展。但随着新技术方法的不断引入,该研究还在不断地改进和提升。
1 科研合作预测领域的作者相关度研究概述
科研合作预测通常在学术论文构建的科研合作网络中进行,目的是预测从未合作过的作者在未来产生合作的可能性。因此在合作网络中,对科学家相关度计算可转为作者相关度计算。作为社会网络的一种,科研合作网络体现了科学家间存在文章或者研究项目等的合作关系。
作者相关度在很多科研合作预测文章中也被称为相似度,在实际预测中,相比衡量不同作者间属性特征是否相似,更关注不同作者在合作网络中是否近邻、是否属于同一知识社区。如在合作网络中,拥有共同合作者但研究领域不同的两位作者,虽然属性特征相似度不高,但网络结构相似性高,作者相关性大。在科研合作预测领域中的作者相关度应用,主要根据作者节点属性及网络的结构特征等信息(如相关人际关系,研究方向、领域、内容、兴趣等计算作者间的相关度),以相关度表示作者未来合作的可能性。
对于目前的科研合作成因来说,两个作者可能合作是因为同处一个学术机构、互为师生关系、研究领域交叉等。而随着开放科学的发展,科学研究整个过程的开放性和互操作性不断增强,对从未合作过的作者在未来合作的预测会越来越复杂,但合作网络自身的拓扑结构优势能够揭示未来合作的可能性程度。如在合著网络中,两位拥有共同同事的作者;或在作者-关键词网络中,两位拥有共同关键词,研究内容相关的作者,就有合作的可能性。因此,作者相关性计算也就成为科研预测领域的关键技术之一。
科研合作预测在本质上是链路预测问题,通过已知的网络结构信息预测节点间未来产生连接的可能性,其中一类主流算法是基于节点相似性的方法。基于节点相似性的方法是根据已知网络中的作者节点拓扑结构,通过计算每一对未相连作者节点的结构相似度,相似度越高,其存在连边的概率越大,即作者未来合作的可能性更高[2]。
早期科研合作预测研究基于同构网络(合著网络、引文网络等),采用多种节点拓扑相似性指标,如基于共同邻居指标、到达路径指标和随机游走指标计算作者相关性。Liben-Nowell等[3]率先将基于网络拓扑结构的多种节点相似性指数应用于社交网络链接预测,并在合著网络中进行了实验。随后Zhou等[4]在包括合著网络在内的多种现实网络应用多种基于局部信息的指标实施链路预测,并提出资源分配(RA)指标和局部路径(LP)指标。近年来,越来越多的研究者采用相似度指标在合著网络中通过计算作者相关度来预测合作的可能性。张斌等[5]在7门学科的合作网络中应用多种相似性指标进行链路预测。张金柱等[6]运用多种相似度指标在合著网络中研究合作演化规律。
现实中,科研合作网络往往是异构的,同构网络节点相似性虽然易于计算,但丢失了很多语义信息。传统的节点相似性指标,根据同构信息网络设计,无法直接应用到异构信息网络中。为了计算异构网络中的节点相似性,Sun等[7]于2011年提出元路径的概念,并在异构书目网络中研究了合作关系预测问题,将基于路径指标、随机游走指标扩展到异构网络中。随后多种基于元路径的网络拓扑相似度指标相继被提出,伍转华[8]利用PathSim算法在DBLP文献数据集构成的“论文-作者-术语-会议”异构网络中寻找相关作者。Shi等[9]提出的HeteSim算法度量异质网络中任意节点对的相关性,在ACM(“机构-作者-论文-术语-学科-会议-出版物”异构网络)和DBLP数据集上计算作者节点相关度。孟晓峰[10]提出了一种基于元路径的新型相似性度量算法AvgSim,并在ACM数据集和DBLP数据集上计算作者节点相关度。张舒虹[11]在APS(“论文-作者-机构-术语-学科-期刊-年刊”异构网络)和DBLP数据集上,基于时间动态的路径数、传递相似性的归一化路径数和作者属性的对称随机游走计算作者节点间的相关性。
由于传统链路预测方法使用的网络拓扑相似性指标普遍存在计算效率较低和数据稀疏造成的维数过高问题,很难应用于大规模数据集的科研合作网络的合作预测。随着表示学习的不断发展,新兴的网络表示学习方法能够将图中的节点表示成向量,通过计算向量相似度获得节点相似度。该方法可以高效地计算网络中节点间的语义联系,也能够解决数据稀疏下的语义关联抽取和计算复杂问题[12],因此学者们尝试将新方法应用于合作预测。Tang等[13]提出了LINE算法并在合著网络中进行了实验,在识别相关作者中取得了良好的效果。张金柱等[12]利用LINE网络表示学习方法得到作者的向量表示;通过向量夹角余弦值计算作者间的语义相似度。姚锐[14]构建“论文-期刊-作者”的异构网络,以作者为中心,结合元路径应用Node2vec模型得到作者的向量表示,根据明可夫斯基距离、余弦值计算作者间的向量相似度。Dong等[15]提出了metapath2vec表示学习方法,并在“作者-论文-会议”异构网络中进行了相关作者聚类实验。
2 面向科研合作预测的作者相关度算法分析和比较
利用学术论文构建的科研合作网络主要有同构网络(如合著网络[3])和异构网络(如“作者-关键词”网络[16]、“作者-文献”网络[17]、“作者-文献-术语-会议”网络[18])。基于节点相似性的方法在科研合作网络中进行合作预测,根据作者节点的拓扑信息,利用合著、引用、同属一个机构等连边的语义信息计算作者间的相关性,即利用拓扑相似度算法计算作者网络信息的相似程度。
2.1 基于同构网络节点相似性指标的作者相关度计算
基于网络拓扑结构相似度衡量作者间的相关度,是将作者实体间的关系连结起来构成网络图,利用图中节点间的连接属性,来判定两个作者的相关性。
衡量同构网络(合著网络)中作者节点的相关性,一般采用节点拓扑相似性指标来计算。相似性指标包含基于邻居的度量(网络局部结构的相似性)、基于路径的度量(准局部结构的相似性)、基于随机游走的度量(网络全局结构的相似性)。这里的“相似性”是相关文献已成习惯的术语,实际上很多相似性指标衡量的并非是节点对是否具有相似的特征,而是衡量节点对在几何或者拓扑空间是否邻近,或者在功能上是否具有较大的关联[19],因此也被称为“接近性”或“相关性”。其中最简单的相似性指标是共同邻居(Common Neighbors,CN),两个节点如果有更多的共同邻居就可能更相似。基于路径度量的相似性算法考虑到使用共同邻居指标进行计算时,相似性分数可能分布过于集中,使得预测结果没有区分度。因此,将两个节点的共同邻居扩展到“n阶共同邻居”[5]。基于随机游走的度量是利用一个节点到其邻居的转移概率来描述当前节点随机游走的目的地,可以根据整个网络图的信息来计算节点相似度,即使两个节点之间没有公共邻居节点也能计算(见表1)。

表1 代表性节点拓扑相似度指标
拓扑相似性指标只涉及网络的结构信息,相似性指标计算比较简单,但不同指标在不同网络中的预测能力不一致,其预测的精确度取决于对网络结构特征刻画的好坏[20]。在高凝聚性的网络中,基于邻居和路径的相似性指标表现良好;在稀疏网络中,基于随机游走的度量预测效果比较好。在合著网络中识别作者相关度,基于邻居和路径的相似性指标表现良好,尤其是CN指标、Adamic/Adar指标、RA指标和Katz指标。
合作关系所形成的合著网络是一个熟人网络,日常生活中往往通过他人介绍或者更间接推荐来认识某个人进而与其合作。CN指标能很好地衡量两位作者的直接合作者,Katz指标和LP指标能很好地衡量两位作者的间接合作者。但是随着路径的增加,越间接的合著者对产生合著关系的影响越小,因此随机游走指标在合著网络中表现不理想。Adamic/Adar指标、RA指标是改进指标,赋予度数小的共同邻居节点更大的权重,比共同邻居指标取得了更好的效果,因为度数小的作者选择的合作者与其相关性更高。而Jaccard相关系数不考虑邻居权重因此表现一般。PA指标表示度数大的节点更容易产生连接,在合著网络中往往取得的效果不好,因为两位度数大的作者即影响力大的作者通常合作概率小[3,5,6,20]。
2.2 基于异构网络的元路径拓扑相似度指标的作者相关度计算
科研合作网络通常是异构的,即网络中存在多种类型的节点或连边。同构网络只是异构网络的投影,如合著网络是由“文献-作者”网络投影形成的,虽然合著网络易于计算分析,但失去了原异构科研合作网络中丰富的语义信息。近年来,学者通过异构网络来解决科研合作预测问题,常见的方法包括基于元路径。
元路径是定义在网络模式上,用于描述异构网络中组合关系的路径。不同的元路径具有不同的语义来描述节点之间的相似程度。通过考虑依据不同元路径的路径,可以将同构网络中基于邻居和路径的属性拓展到异构信息网络中。例如,如果区别看待不同类型的邻居节点,并且把一阶邻居扩展为n阶邻居(某一节点和它的邻居之间的距离为n),则两个作者间共同邻居属性就变成两个作者之间依据不同元路径的路径数目[14]。
基于元路径的相似性计算首先用元路径定义两个节点之间的拓扑结构,然后在具体的拓扑上定义不同的度量标准。该方法考虑异构信息网络中不同拓扑结构的丰富语义信息和形成原因来进行计算。如包含作者(A)、论文(P)、出版物(V)3种节点的合作异构网络,两个作者节点间的元路径有:A1-P1-V1-P2-A2代表A1和A2在同一出版物上发表过文章;A1-P1→P2-A2代表A1的论文P1引用了作者A2的论文P2。
在元路径相似度指标中(见表2),以路径数和随机游走为基础的相似性度量适用于具有高出入度的对象,基于成对的随机游走的相似性度量适用于集中的对象(即大部分的链接属于小部分节点)[8]。

表2 代表性元路径相似度指标
在科研合作异构网络中,连接两个作者之间的元路径越多,两者越相关,元路径相似度指标均能取得不错的效果,其中归一化路径数指标表现更突出。PathSim指标更倾向于发现对等作者,如领域和声誉类似的作者。对称随机游走更倾向于高出入度的作者节点,表示在网络中越容易相互到达的作者更相关,如合著论文数越多的两位作者越相关。HeteSim指标思想为与相关对象相连的对象是相关的,如相关的作者会在相关会议中发表论文,它能够有效地度量作者相关度,但计算复杂性高也无法处理大规模网络。AvgSim指标以HeteSim指标为切入点,能够有效地度量作者相关度,同时降低了计算复杂度[7,8,10]。
表示两位作者拥有共同合作者、在同一出版物上发表论文、研究相关领域和引用相同论文的元路径,这些都在识别作者相关度中发挥了重要作用。虽然越长的元路径携带信息越多,但随着元路径长度的增加,算法的复杂性也在增长,其精度增长幅度不大,因此长度一般控制在6个节点以内。
2.3 基于新兴网络表示学习方法的作者相关度计算
除在科研合作网络中采用结构相似性指标计算作者节点相关度外,随着表示学习的发展,基于深度学习的网络表示学习方法也得到了广泛的应用。网络表示学习方法将图中的节点表示成低维、实值、稠密的向量形式,通过计算向量间的距离判断节点的相关度。
基于神经语言模型的网络表示学习是目前的研究热点(见表3),其基本原理和思路来源于代表性的词向量生成工具Word2Vec[21]。Word2Vec工具包含CBOW模型和Skip-gram模型,通过选取输入词的前后n个词作为上下文,学习到包含语义信息的输入词的向量表示。针对网络结构和神经语言模型的特点,网络表示学习把节点类比为词,把在网络中获得的节点序列类比为句子,将节点序列作为Word2Vec的输入,根据每个节点的上下文信息,得到节点的向量表示。根据节点序列获取方式的不同形成了以DeepWalk[22]、LINE[13]、Node2vec[23]、Metapath2Vec[15]等为代表的基于神经语言模型的网络表示学习方法。
在科研合作网络中利用网络表示学习方法预测科研合作,学习作者在网络中的上下文语境信息,得到每位作者的向量表示,将合作预测变为作者向量相似度计算问题,相似度越高,尚未合作过的作者越有可能进行合作。
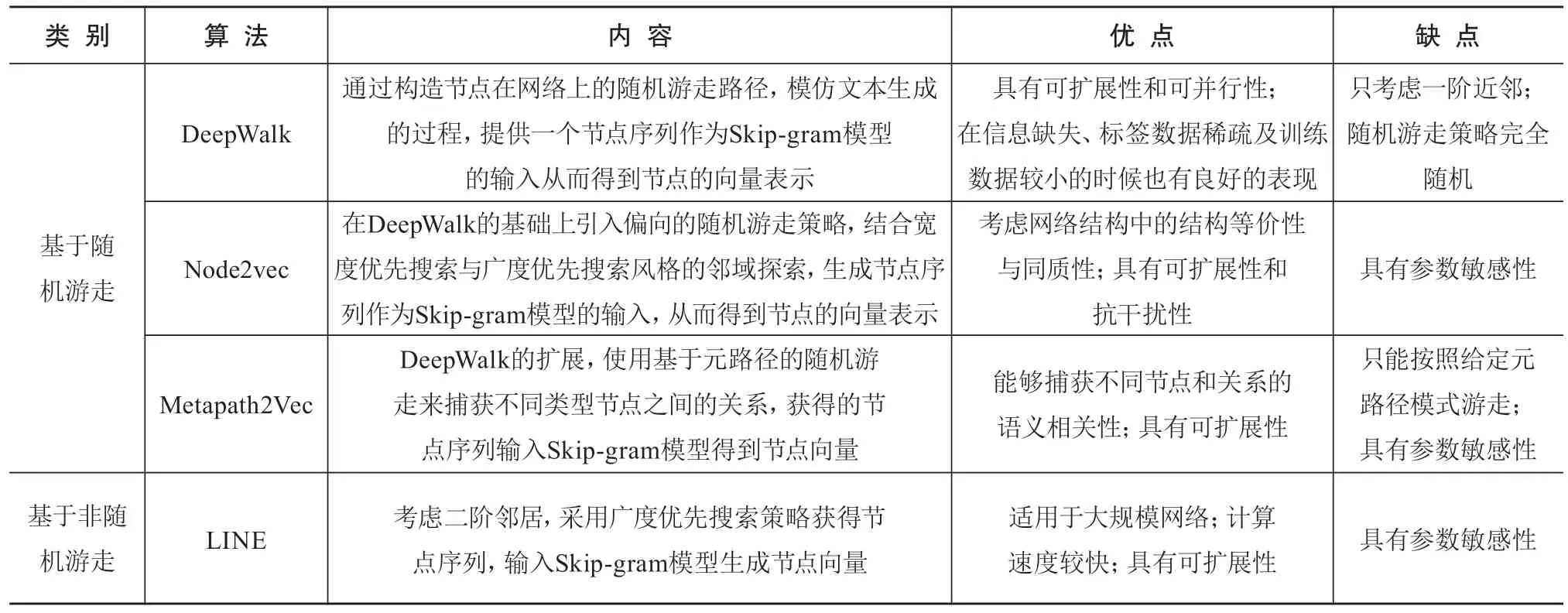
表3 基于神经语言模型的网络表示学习代表性算法
网络表示学习为复杂网络分析提供了新的视角,部分研究者开始初步探索将其应用到科研合作网络。在合著网络中,DeepWalk、LINE、Node2vec都能取得不错的效果,其中Node2vec因为更灵活地选取邻居节点,同时考虑了合著网络结构中的结构等价性与同质性,在计算作者相关性方面表现得更好,但是能解决的网络规模不如LINE。LINE更适合稠密大规模网络,能够在具有高度数节点的合著网络中有效识别相关作者。DeepWalk更适合稀疏的网络,但提出时间早,完全随机的随机游走策略在竞争力方面不如之后提出来的改进算法。Metapath2Vec能够考虑不同类型节点间的不同语义,在科研合作异构网络中计算作者相关度方面取得良好的效果[13,15,23]。网络表示学习能在大规模数据集中自动提取合作网络中作者关联语义,在计算作者相关度方面有广阔的研究应用空间。
3 结语
在科研合作预测领域,作者相关度计算方法的研究发展紧跟新兴技术发展步伐。通过科研合作网络结构信息判断作者相关度,经历了从同构网络到异构网络的发展,在越来越复杂的研究中不断的精细化、精准化。
从上述研究不难发现网络表示学习方法将在作者相关度计算中得到进一步应用。随着词向量在文本相似度计算上的成功,涌现出一批借鉴语言模型完成的网络图表示学习的方法已在合作网络中尝试应用,那么其他基于深度学习的网络表示学习方法能否有更好的表现,以及网络中其他结构的表示(如子图向量、图向量)能否应用到作者相关度计算将成为今后探索的方向。此外,构建科技知识图谱能够为作者相关度计算提供更多支持。与简单的科研合作网络(如合著网络、二分网络、三种节点网络等)相比,构建拥有更全面的作者及相关实体节点、更丰富的作者语义信息的科技知识图谱,能够更全面地比较作者间相关度,因此在知识图谱中寻找相关作者也将有更多应用场景。
开放科学给科研合作领域带来了挑战,也带来了机遇。作者相关度计算作为基础研究问题已经取得诸多成果,随着新兴技术与作者相关度研究不断交叉融合,该研究成果势必会进一步推动科研合作预测领域的发展。
猜你喜欢
数学物理学报(2022年5期)2022-10-09 08:56:44
机械工业标准化与质量(2022年6期)2022-08-12 02:07:42
小学教学研究(2022年5期)2022-04-28 21:29:36
国际眼科杂志(2021年9期)2021-09-15 03:24:42
装备制造技术(2020年2期)2020-12-14 03:09:16
河北画报(2020年8期)2020-10-27 02:54:20
电信科学(2016年11期)2016-11-23 05:07:56
浙江大学学报(工学版)(2016年2期)2016-06-05 09:20:51
通信电源技术(2016年6期)2016-04-20 06:21:36
中国卫生(2015年12期)2015-11-10 05:13:34
