
基于知网的词语语义相似度改进算法
2019-04-19 05:24杨丽花
计算机技术与发展 2019年4期
李 蕾,杨丽花
(南京邮电大学 江苏省无线通信重点实验室,江苏 南京 210003)
0 引 言
词语语义相似度计算在信息检索[1]、基于实例的机器翻译[2]以及数据相似度检测等领域有着广泛的应用。目前常用的基于知网的词语语义相似度计算方法大致可分为两类:一类是利用大规模语料统计词语的相关性,即基于统计的方法;另一类是根据某种世界知识计算相似度的方法,即基于世界知识的方法[3]。其中,基于统计的方法是根据词汇上下文信息的概率分布计算词语语义相似度,该方法计算得到的结果精确度较高,但是需要依赖于训练所用的语料库,计算量比较大,计算方法也比较复杂。此外,由于数据稀疏和数据噪声等因素对基于统计的方法干扰较大,故该方法一般很少使用[4]。基于世界知识的方法通常是基于某个知识完备的语义词典中的层次结构关系进行计算,该方法简单有效,不需要用语料库进行训练,也比较直观和易于理解,但这种方法受人的主观意识影响较大,有时并不能准确反映客观事实[5]。
知网是一个以汉语和英语词语所代表的概念为描述对象、以揭示概念与概念之间以及概念所具有属性之间的关系为基本内容的常识库和知识库。基于知网的词语语义相似度计算最终可以归结于义原相似度计算的层面上。例如,文献[6]提出了一种根据义原距离计算词语语义相似度计算方法;文献[7]在考虑义原距离的基础上进一步考虑了义原深度对词语语义相似度的影响;文献[8]提出了一种同时考虑义原深度和义原密度的方法;文献[9]考虑了义原间的反义对义关系及文本情感色彩对词语语义相似度的影响;文献[10]提出一种考虑了义原的公共节点个数和义原深度的词语语义相似度计算方法;文献[11]根据差异以及共有信息进行词语语义相似度的计算;文献[12]提出了一种考虑词语词性因素的词语语义相似度计算方法;文献[13]将关系义原和关系符号义原进行加权合并,提出补充义原是对基本义原的语义补充,并且考虑了最小公共父节点的影响[14];文献[15]深入考虑义原之间的距离和义原层次深度的主次关系;文献[16]提出结合知网与同义词词林两个知识库的词语语义相似度算法。
然而,目前常用的基于知网的词语语义相似度计算方法未深入考虑同一棵树中的两个不同义原的可达路径上所有义原节点的密度对义原距离的影响,且也未考虑义原深度与义原密度的主次关系。对此,文中提出了一种改进的基于知网的词语语义相似度算法。
1 知网简介
知网中主要包含义项和义原两个概念,义项是对词语语义的一种描述,每一个词可以表达为几个义项,它是用一种知识表示语言来描述的。在知网中,每个汉语词语的一个义项由一个四元组构成:〈W_X=词语 E_X=词语例子 G_X=词语词性 DEF=概念定义〉,其中DEF(语义表达式)是义项的主体,由一个个结合知识描述符号的基本义原组成,每个义原使用逗号隔开,例如义项“男人”的DEF=“human|人,family|家,male|男”。
知网中义原对于义项的描述是通过一种结构化的知识描述语言进行定义的,这种知识描述语言所用的词汇叫做义原,义原是用于描述一个义项的最小意义单位,它是从所有词语中提炼出的,并且可以用来描述其他词语的不可再分的基本元素。义项与义原之间的结构关系如下所示[6]

2 词语语义相似度计算
2.1 基本定义
词语语义相似度不能根据明确的客观标准进行衡量,因此它是一个主观性比较强的概念。文中采用文献[6]所理解的词语语义相似度含义,即两个任意的词语如果在不同的上下文中可以互相替换且不改变文本语义的可能性越大,那么两者之间的相似度就越高,否则相似度就越低。
在知网中,一个词语可以表达为几个义项,比如:对于两个汉语词语w1和w2,若w1有n个义项,即s11,s12,…,s1n;w2有m个义项,即s21,s22,…,s2m,则词语w1和w2的语义相似度可以表示为:
(1)
其中,sim(w1,w2)表示词语之间的相似度;sim(s1i,s2j)表示义项之间的相似度。
根据式1可知,两个词语之间的语义相似度可以由两个义项之间的相似度的最大值表示。而所有的义项最终是用义原来表示,因此义项之间的相似度可表示为[7]:
(2)
其中,β1(1≤i≤4)是可调节参数,且满足:β1+β2+β3+β4=1,β1≥β2≥β3≥β4。
增加网络教学平台的操作培训,让老师了解网络教学平台的所有功能,不仅要讲解网络教学资源的上传方法,还要重点讲授网络教学平台的师生互动操作,由于培训时间有限,老师不一定能马上掌握,老师在教学中操作时会遇到具体问题,网络教学平台的客服应能及时协助老师解决。
由于义项相似度是由义原相似度计算来的,因此,基于知网的词语语义相似度计算最终可以归结于义原相似度计算的层面上。
2.2 义原相似度计算
义原中提供了事件类、属性类、实体类、属性值类、次要特征类、数量类、数量值类、语法类、动态角色类与动态属性类等十棵义原层次树,它们相互之间不存在交集。对于处于同一棵树的两个不同义原,有且仅有一条长度为N的可达路径,并且不同树的义原之间没有可达路径,在此定义两义原间路径的长度为义原的语义距离,即义原距离。一般而言,义原距离越小,义原相似度越大。
文中选取了一个以“实体”为根节点的义原层次体系树的分支(如图1所示),并根据该图,对三种常见的义原相似度计算方法进行分析。
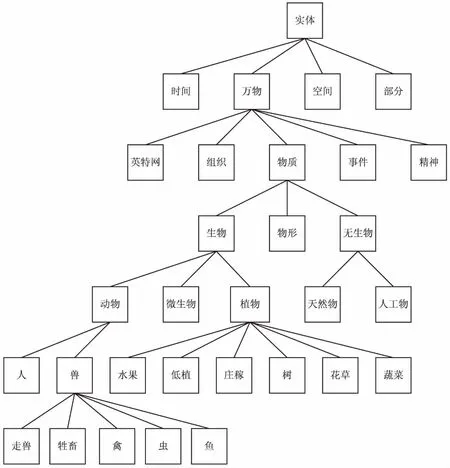
图1 以“实体”为根点的树分支示意
刘群等提出通过计算两义原节点之间的义原距离计算两个义原之间的相似度[6],即
(3)
其中,p1和p2表示义原,dis(p1,p2)为p1和p2在义原层次树中的义原距离,当p1和p2处于不同的树时,dis(p1,p2)将取一个较大常数;α为可调参数。
该方法根据知网中义原之间的上下位关系对词语语义相似度进行计算,但是计算得到的词语语义相似度结果过于粗糙,准确度不高。
文献[13]提出一种根据义原深度和义原密度来计算义原相似度的方法。其中义原深度是指义原层次体系树上的根节点到该义原节点的路径长度,义原深度越小,义原表达的概念越抽象,义原深度越大,义原表达的概念越具体;义原密度是指该义原节点的兄弟节点的个数(含自身),义原密度越大,意味着分类越细致,描述越详细,其携带的语义信息越丰富,位于高密度区域的节点对义原距离小。利用义原深度和义原密度获得的义原相似度计算公式为:
(4)
其中,N是义原p1和p2之间可达路径上的长度;level(i)为两个义原可达路径上边i在义原层次树中的层次;LCN是两个义原在树中的最小公共父节点[14];f(·)函数反映了当前义原所在树中的密度信息,其值为当前义原的兄弟节点的个数(含自身)与树的总节点个数的比值;weight函数是一个随层数k递增而单调递减的函数,表示每一条边的权重,定义为:
(5)
其中,depth为当前义原层次树的树高。
文献[13]虽然在义原距离的计算公式中引入了一个随层数递增而单调递减的边权重函数,但该函数采用的是线性递减策略,顶部边权重衰减过快,不符合知网层次结构的特点。为了避免该现象,文献[16]引入了一个正弦三角函数,即
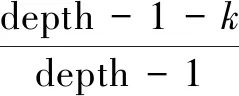
sin(θ*k*π/180))
(6)
其中,θ是调节参数,与树高depth成反比。
文献[16]虽然改进了义原距离计算公式中的边权重函数,但却未考虑义原密度对义原相似度的影响。
3 提出的语义相似度计算方法
现有的义原相似度计算方法虽然考虑了义原树中义原深度和(或)密度对义原相似度的影响,但仅仅只考虑了当前所要计算的义原节点以及它们的最小公共父节点的密度对义原相似度的影响,而未考虑两个义原节点可达路径上所有节点的密度对义原距离的影响。为此,文中提出一种基于知网的词语语义相似度改进方法,该方法基于知网语义词典,通过将义原深度和义原节点间所有节点密度进行联合,并利用权重因子来权衡义原深度和义原密度对义原相似度的影响,获取新的义原相似度计算公式,根据义原、义项与词语之间的关系,最终得到改进的词语语义相似度计算表达式。
在义原树中,影响义原距离的因素有义原深度和义原密度,一般而言,义原深度越大,义原距离越小;义原密度越大,义原距离越小。该方法通过在边权重函数中引入义原可达路径上所有义原节点密度对义原距离的影响,给出了一个新的边权重函数表达式,即
(7)
其中,ip,q为义原p与q之间的边,p表示当前义原节点,q是当前义原节点p的上一层父节点;kp为当前义原节点p所在层的编号;θ是调节参数,与树高depth成反比,文中取θ=4;f(·)函数反映了当前义原所在树中的密度信息,其值为当前义原的兄弟节点的个数(含自身);max表示当前义原树中所有义原节点的总个数;c1和c2为权重因子,其主要是用来权衡义原深度和义原密度对义原距离的影响。
利用式8给出的新的边权重函数,得到义原p1与p2之间的距离为:
(8)
其中,G是义原p1与p2的公共父节点。再分别根据式3、式2和式1,从而最终可获得两词语的语义相似度。
4 实验与分析
考虑到义原深度和义原密度对义原距离的影响不同,文中方法引进了权重因子c1和c2来权衡二者的影响。在此设置4组不同的权重因子组合来计算义原距离,通过比较义原距离,选取出符合该方法中的最佳权重因子c1和c2,实验结果如表1所示。在表1中,当(c1=0.4,c2=0.6)和(c1=0.5,c2=0.5)时,“兽”和“人”的义原距离要大于“动物”和“植物”之间的义原距离,这显然和实际情况不相符合,在以“属性和属性值”为根节点的义原层次体系树中,“味道”和“气味”的义原距离要小于“酸”和“甜”之间的义原距离,这与实际情况是相符合的,但是当权重因子分别取(c1=0.4,c2=0.6)和(c1=0.5,c2=0.5)时,两者的义原距离都相差比较大,而权重因子取(c1=0.7,c2=0.3)时的义原距离比较适中,在以“实体”为根节点的义原层次体系树中(如图1所示),“走兽”和“牲畜”、“花草”和“树”这两对义原对同是树中的叶子节点,因此这两对义原对的义原距离相差不大。因此,当c1和c2分别0.7和0.3时,得到的义原相似度更符合实际情况。
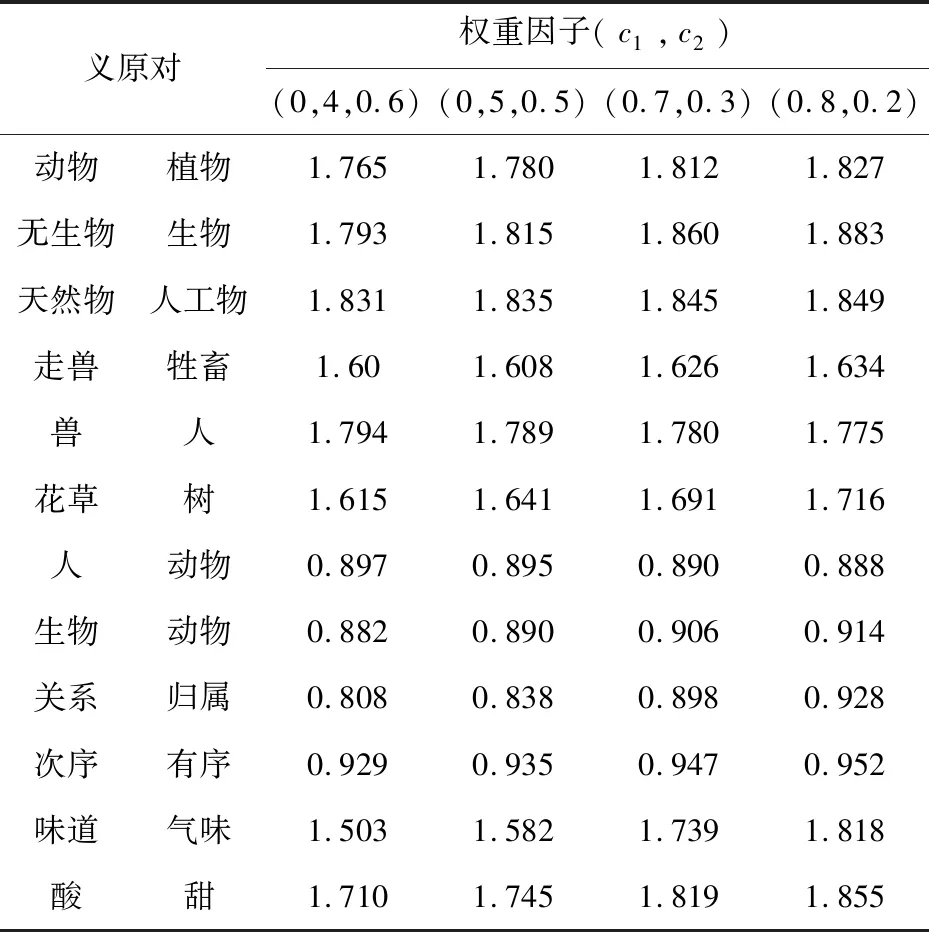
表1 不同权重因子情况下的义原距离比较
为了验证该方法,将其与现有词语语义相似度计算方法进行了仿真验证,如表2所示。
在表2中,方法1是文献[6]所提方法,方法2是文献[13]所提方法,方法3是文献[16]所提方法。在仿真中,α=1.6,β1=0.5,β2=0.2,β3=0.17,β4=0.13,γ=0.2,δ=0.2。可看出,方法1中“男人”(取义项“human|人,family|家,male|男”)与“女人”(取义项“human|人,family|家,female|女”)和“和尚”(取义项“human|人,religion|宗教,male|男”)的词语语义相似度是相同的,这是因为方法1中没有考虑义原层次树中节点的层次深度和密度对义原相似度的影响,但在实际情况中,义原“男”和“女”与“家”和“宗教”的相似度显然是不同的,所以方法2、方法3和文中方法比方法1更能区别不同词语之间的语义相似度,但是其中有些词语语义相似度的计算结果也不太合理,如方法2中“女人”和“男人”的相似度大于“和尚”和“男人”的相似度,这与人的直觉是不相符合的,因为“和尚”和“男人”都为男性,它们之间的相似度应该比“女人”和“男人”的相似度要高,并且根据方法2和文中方法中所定义的义原相似度计算方法,义原“家”和“宗教”的相似度比义原“男”和“女”的相似度大,所以“男人”和“女人”的相似度应该比“男人”和“和尚”的相似度要小。另外,从6-11这6组词语对的相似度计算结果中可以看出,方法2的结果要远大于方法1、方法3和文中方法的结果,而在方法1、方法3和新方法的词语语义相似度的计算结果中,6-11这6组词语对的词语语义相似度计算结果差距较小,较为合理。因此,文中方法计算的词语语义相似度结果更加合理和准确。
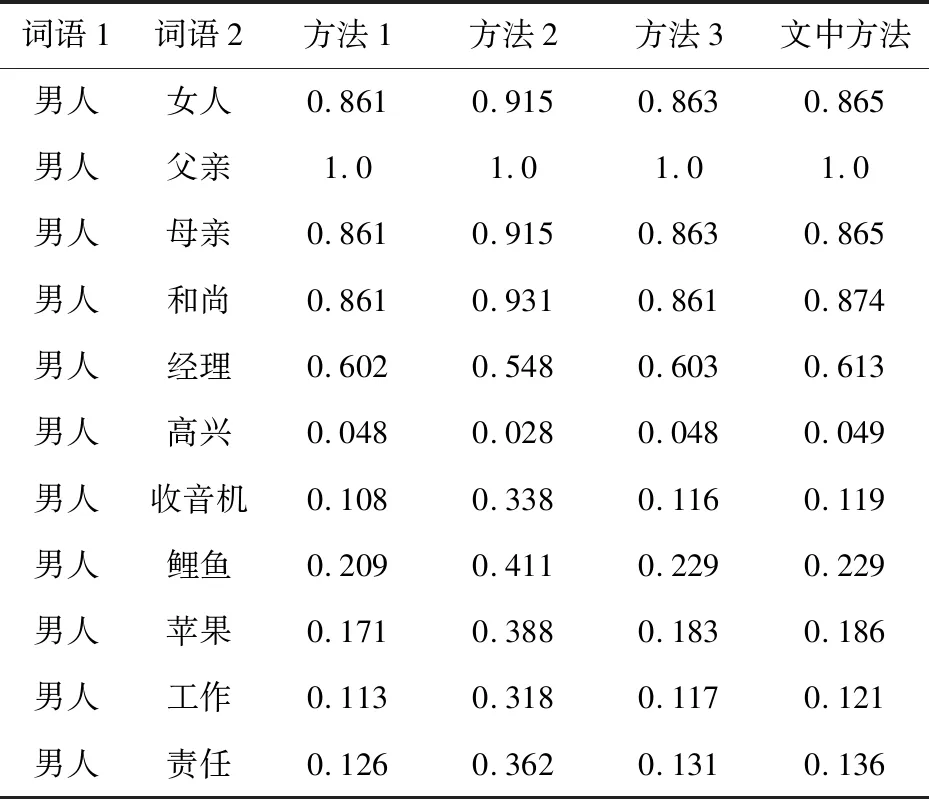
表2 词语语义相似度计算结果比较
5 结束语
利用义原深度与两义原间可达路径上所有义原节点的密度提出了一种改进的词语语义相似度计算算法,并通过一权重因子来调整义原深度与义原密度的主次关系。实验结果表明,该方法所计算的词语语义相似度结果更加合理和准确。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
长江学术(2016年4期)2016-03-11
中学生数理化·八年级物理人教版(2015年12期)2016-01-25
中学生数理化·八年级物理人教版(2015年12期)2016-01-25
中学生数理化·八年级物理人教版(2015年12期)2016-01-25
知识窗(2015年1期)2015-05-14
长江学术(2015年1期)2015-02-27
中学生英语高效课堂探究(2008年1期)2008-03-26
