
虚拟数据代理云模型构建及数据布局
2019-04-15 11:25:24胡志刚张欣欣郑美光常成龙李佳杨柳
中南大学学报(自然科学版) 2019年3期
胡志刚,张欣欣,郑美光,常成龙,李佳,杨柳
虚拟数据代理云模型构建及数据布局
胡志刚,张欣欣,郑美光,常成龙,李佳,杨柳
(中南大学 计算机学院,湖南 长沙,410083)
综合考虑数据集间的依赖关系以及数据中心的存储容量,引入一种名为“虚拟数据代理”的新实体,通过建立虚拟数据代理云模型,将数据布局问题转换为2个映射过程,即从数据集到虚拟数据代理的映射以及从虚拟数据代理到数据中心的映射,进而提出一种基于虚拟数据代理的云模型数据布局策略(CDPVDA)。仿真实验结果表明:CDPVDA与典型的数据放置策略相比,可以将数据中心之间的数据传输开销降低5%~20%。
云模型;数据密集型应用;虚拟数据代理;数据布局
数据密集型应用是一种以数据为核心的应用模式,其特点是在运行过程中,需要不断获取、更新、存储大量数据,并对这些数据进行各种计算[1]。这些应用通常需要处理分布在不同数据中心的数据集[2],它们都通过对海量数据进行复杂计算、分析挖掘与处理从而得出丰富的数据,服务于社会生活、生产以及科学研究领域。云计算是数据共享与服务共享计算模式的结合体[3],为数据密集型应用提供了一种全新的部署和执行方式。在分布式计算领域,数据密集型工作流是科学研究和工程计算中最典型的一种任务类型,在执行过程中需要多数据中心协作[4]。当前,许多地理上分布的私有云可以对外提供一部分计算和存储资源,可将此类私有云看作单独的数据中心并通过互联网形成更大的云平台。该云计算平台允许用户执行其应用,并将所需的数据集上传到平台中。对于规模庞大的数据集,有一部分数据集需要存放在某一特定的数据中心上,加之云平台的节点之间存在带宽限制,不可能将所有数据集上传到某一个单独的数据中心,或者在每个单独数据中心存储所有的数据集,而是需要将不同的数据集分别上传到不同数据中心,使用户数据密集型应用的多个子任务并行执行。由于任务之间存在较强的数据依赖关系,数据密集型在运行时必然会产生跨多个数据中心的数据移动任务,涉及大量的数据传输、数据同步等开销,不合理的数据设置将产生高额成本并严重影响工作流执行效率,因此,为云环境下的数据密集型应用设计合理的数据布局方法很有必要。云模型[5]是定性概念和定量论域的不确定性转换工具,本文作者将云模型应用于数据布局策略中,以解决数据布局过程中的不确定性和随机性问题。在数据布局过程中充分考虑数据密集型应用所涉及数据集之间的依赖关系以及数据中心的存储量,从而减小数据密集型应用跨多个数据中心的数据移动以及产生的时间消耗,提高应用执行效率和系统性能。本文中云计算和云模型都涉及“云”,为了将云计算和云模型区分开来,云计算指分布式计算领域中的节点或者集群,它是一种计算范式,而云及云模型等均是不确定性人工智能范畴里云理论中的概念。针对云环境下数据密集型应用的数据布局问题,研究者进行了大量的研究,如YUAN等[6]考虑到数据集之间的依赖关系,提出了一种结合K-means算法的数据布局方案,为所有数据集划分不同的集合类别并为不同的集合分配不同的位置,有效地减少了数据集移动次数,但未考虑数据块存放时,能否使节点负载维持在设定阈值内。刘少伟等[7]在科学工作流建立阶段,根据数据依赖关系图将关系紧密型数据集尽可能放置到同一数据中心。研究结果表明,该策略能有效减少跨数据中心科学工作流执行时的数据传输量。DENG等[8]在YUAN等[6]的基础上,提出一种数据集和任务的协同调度策略。该策略考虑到数据集和应用任务之间的依赖关系,有效地提高调度性能,但此方法主要考虑负载均衡,导致具有高依赖度的数据集可能在不同的数据中心上存储,应用任务在执行过程中可能会产生大量数据集跨数据中心的时间开销。一些研究者考虑到数据依赖关系,用智能方法对数据布局问题进行研究,如:张甜甜等[9]考虑数据依赖特性,设计一种融入释放和重构理论的数据布局策略,能够用更少的时间确定出大规模范围内的最优全局布局方法;PANDEY等[10]则将粒子群算法引入数据布局问题中,该策略在数据中心的负载均衡、算法收敛方面有很好的效果。但上述方法的时间复杂度较高。综合以上分析可知:人们将云环境下的数据密集型应用于数据布局,并得到一些有效方法和策略,但有的为了使负载均衡,而未对跨数据中心数据传输所导致的时间开销进行针对性优化;有的数据布局策略本身时间开销较大,导致数据布局策略灵活性不足;有的没有考虑数据布局过程中存在的不确定性和随机性。为此,本文作者考虑到云环境中数据中心的存储容量以及数据集之间的数据依赖关系,提出一种基于云模型的数据布局策略,以减少跨数据中心传输所产生的时间开销和移动次数。
1 问题概念与定义
1.1 数据布局相关概念
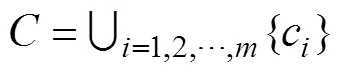
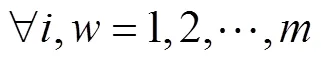


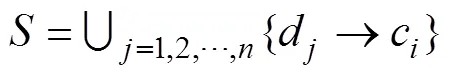
1.2 虚拟数据代理
数据布局为每个数据集在大量数据中心中选择合适的位置,是一个复杂的多次择优过程,并具有不确定性和随机性,同时产生时间及数据移动等各类开销。云模型[5, 11]是在概率理论和模糊集合理论基础上重点考虑随机性和模糊性的关联性发展起来的,是定性知识描述和定性概念与其定量数值表示之间的不确定性转换模型,已在智能控制、模糊评测、进化计算等多个领域得到应用[11−13]。本文为了解决过程中的随机性和不确定性问题,将云模型与数据布局策略相结合。为构建融入云模型的数据布局策略,在云计算系统中引入虚拟数据代理。
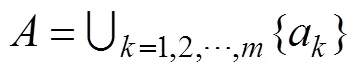
引入虚拟数据代理的数据布局框架如图1所示。
将数据密集型应用中任务T1~T8分配到合适的虚拟机VM上,而每个任务涉及大量数据集,需进行科学计算和处理,这些数据集就是可能来自不同数据中心的数据集。数据集映射到数据中心,需通过虚拟数据代理作为中间件来辅助完成,根据数据集之间的数据特性,虚拟数据代理将关系密切的数据集聚簇,1个虚拟数据代理则存储在1个数据中心中。
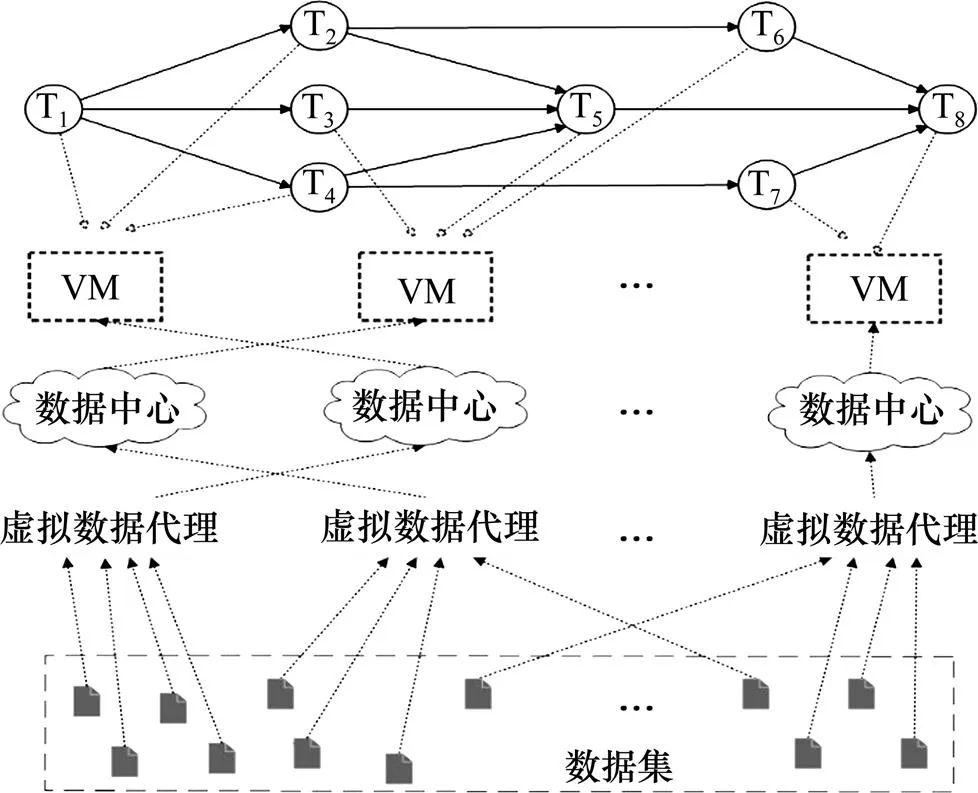
图1 引入虚拟数据代理的数据布局框架
定义2中的虚拟数据代理是1个存储在数据中心的数据集集合,规定它先由一部分数据集开始,而后根据隶属度的计算不断加入新的数据集,直至全部数据集参与运算为止。隶属度是未布局的数据集隶属于某虚拟数据代理的判定值,原则上,隶属度越大,该数据集隶属于虚拟数据代理的可能性越高。为找出确立虚拟数据代理的数据集以及描述高依赖度的数据布局策略,需要对依赖关系等进行定义。
2 虚拟数据代理云模型及数据布局
这里构建虚拟数据代理云模型,并提出数据布局策略。数据集布局到数据中心包含3个关键内容:首先,利用逆向云发生器实现从定量数值到定性概念的转换,确定虚拟数据代理云模型三元组;其次,确定数据集与虚拟数据代理间映射关系,利用正向云发生器,计算各数据集对各虚拟数据代理的隶属度,实现数据集到虚拟数据代理的映射;最后,确定虚拟数据代理与数据中心的映射关系,考虑数据集与数据中心的数据请求关系,实现虚拟数据代理与数据中心的映射。
2.1 虚拟数据代理云模型计算
云模型由期望值x、熵n和超熵e这3个特征参数来表征1个定性概念。云的数字特征如图2所示。x为所表征概念的中心值,它最能有效描述1个定性概念;n综合反映概念的模糊性和概率,表达概念云模型的离散程度,在图2中反映云的跨度;e为熵的熵,表达概念云模型的偏离程度,在图2中反映云的厚度。图2中,横轴表示某一概念的不确定性度量范围,纵轴表示隶属度。隶属度反映所属程度,越接近于0,表明所属程度越低。
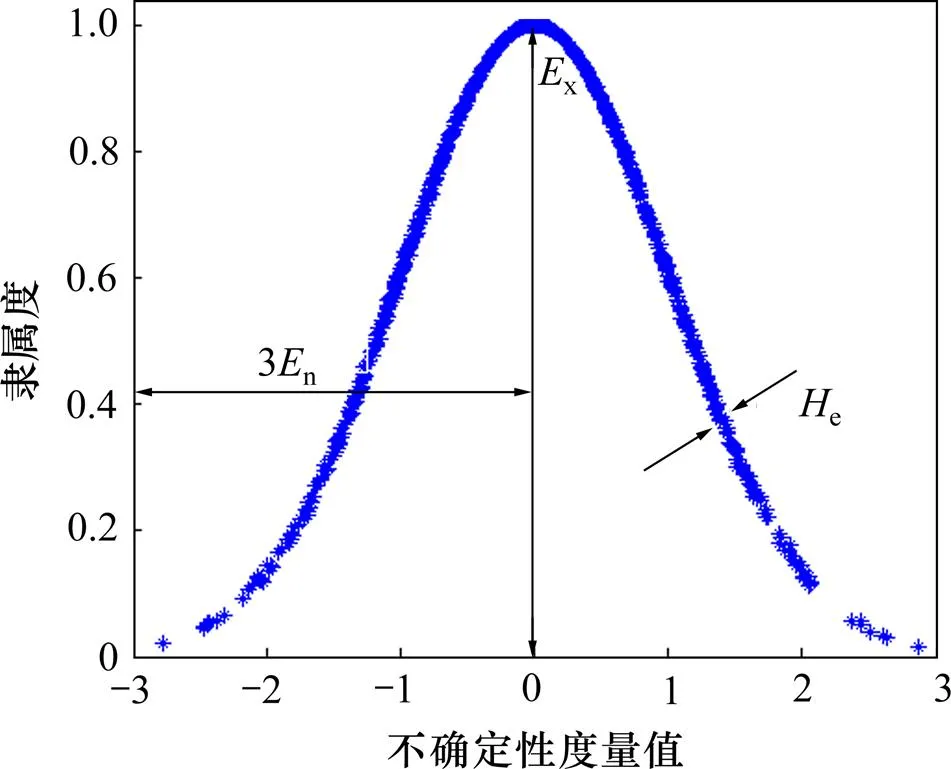
图2 云模型的数字特征
云模型理论有2种云产生算法即2种云发生 器[14−15]:正向云发生器和逆向云发生器。正向云发生器是用语言值描述的某个基本概念与其数值表示之间的不确定性转换模型,是从定性到定量的映射;逆向云发生器是某个基本概念的数值表示和其语言值描述之间的不确定性转换模型,是从定量到定性的映射。
由数据集间不同的依赖关系可能得到不同的数据布局,而在本文中也会确立不同特征值的VDA,这反映了数据布局的随机性。数据集隶属于某个数据中心的可靠程度不同,而本文中数据集隶属于某个VDA的可靠程度也不同,这种可靠程度反映了数据布局的不确定性。
建立虚拟数据代理云模型,采用逆向云发生器生成VDA的3个特征值,即给出VDA的定性描述。定性概念表达其所在区域的整体特征,为了尽可能准确地表达1个定性概念,需要一定数量的数值特征,即提取一定数量的“云滴”构成“云滴组”。为获得1个高质量的VDA,利用数据密集型应用中数据集间的依赖性,找出作为“云滴组”的数据集来共同表达定性概念VDA。云滴组形成的云即表达1个虚拟数据代理。
利用逆向云发生器来确立虚拟数据代理云模型三元组,原则为优先选取具有高依赖度的数据集组成“云滴组”。为获得1个高质量的VDA,利用数据密集型应用中数据集间的依赖性,找出作为“云滴组”的数据集来共同表达定性概念VDA,云滴组形成的云即表达1个虚拟数据代理。本文随机选出个没有依赖关系或依赖关系非常小的数据集作为个“云滴组”的初始数据集,并利用定义5的依赖度阈值分别为每个初始数据集找到一定数量的相关数据集增至各个云滴组中,构造出组“云滴组”。
为每个初始数据集找到的相关数据集个数可能不同,在特征值计算公式(式(2))中将每个云滴组的数据集数量统称为。利用逆向云发生器实现从依照数据特性选定的数据集到定性概念的转换,确立出个虚拟数据代理,“云滴组”数据集则存储在相应的虚拟数据代理中。对于每个虚拟数据代理,按下式计算期望值x、熵n和超熵e:
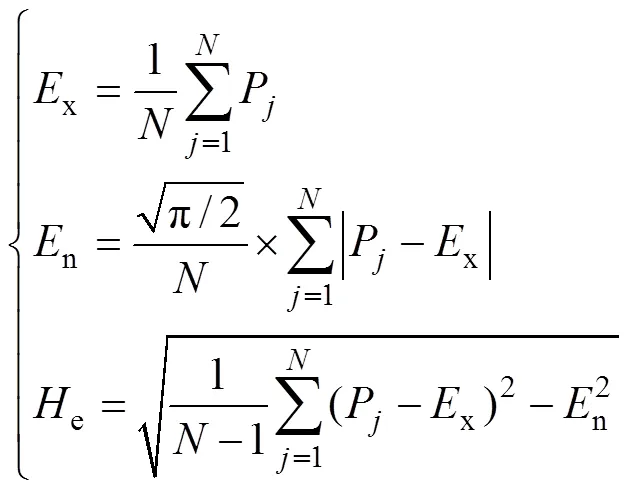
以20个数据集和3个数据中心(即=3)为例,对上述过程进行解释。数据集的初始随机位置P和数据集之间的依赖关系如表1所示。将随机抽取出的3个数据集3,6和11分别作为3个云滴组的初始数据集,依赖度阈值设为3。对于初始数据集a,表1中与其满足高依赖度的数据集为4,将3和4这2个数据集视为一组“云滴组”,由式(2)得出期望值x=2.250,熵n=0.453,超熵e=0.237,即生成3所对应的虚拟数据代理的3个特征值= (2.25,0.453,0.237)。同理,得出6所对应的虚拟数据代理的特征值= (1.45,0.168,0.052),11所对应的虚拟数据代理的特征值=(2.69,0.422,0.276)。
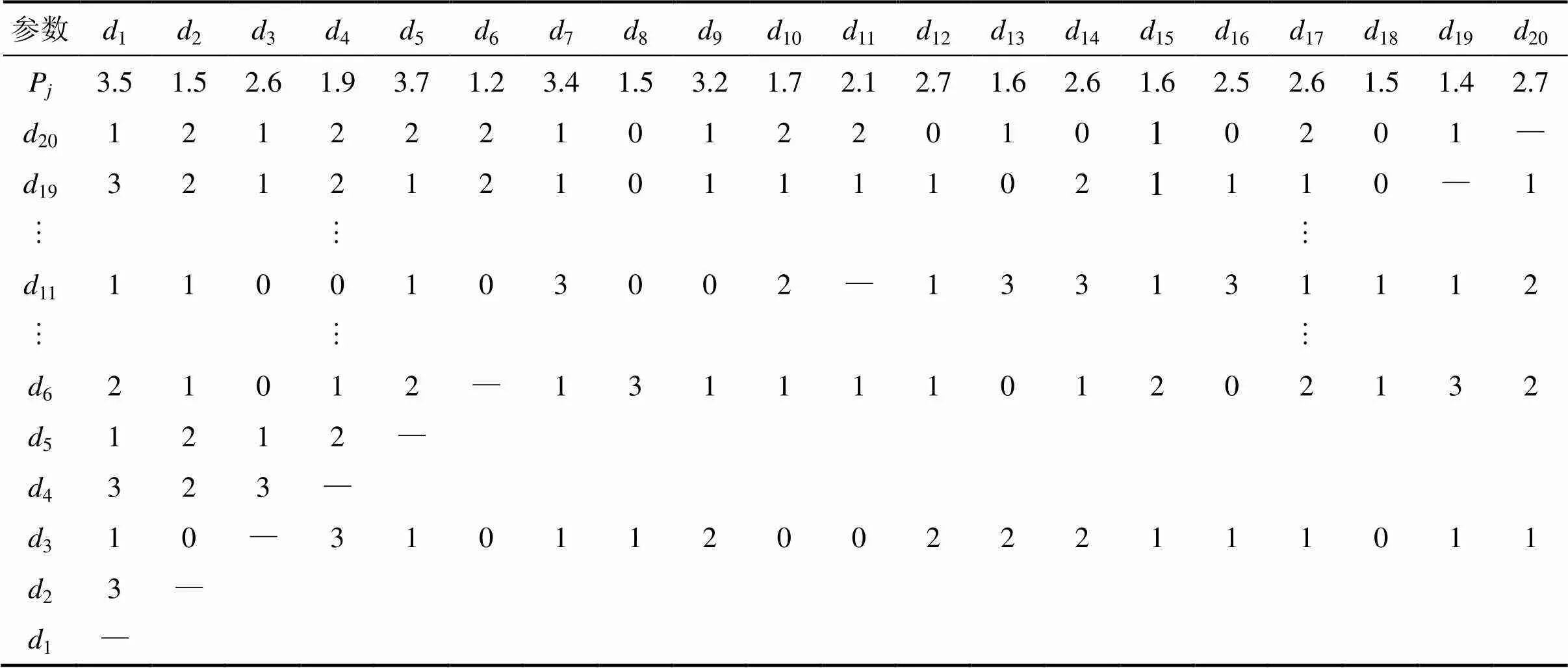
表1 数据集初始位置及依赖关系
2.2 数据集到虚拟数据代理的映射
初始虚拟数据代理云模型确立后,使用正向云发生器,计算数据集对虚拟数据代理的隶属度,从而实现数据集到虚拟数据代理的映射。需要说明的是:构成“云滴组”的数据集默认存储在当前虚拟数据代理中,不再参与隶属度计算。正向云发生器输入云的数字特征(期望值x、熵n和超熵e)以及需要生成的云滴数,输出每个云滴对虚拟数据代理的隶属度。
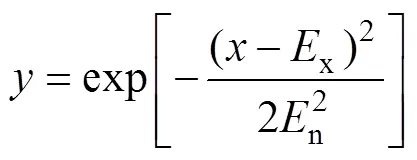
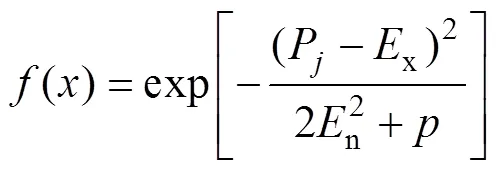
为避免云模型生成过程中虚拟数据代理的数据集数差异过大,使各VDA云模型负载均衡,并考虑到数据中心的剩余存储问题,采取如下策略:当1个数据集相对几个不同的虚拟数据代理具有相同的隶属度时,将该数据集分配到剩余存储量最大的虚拟数据中 代理。
将2.1节中20个数据集布局到3个虚拟数据代理中,结果如表2所示。
2.3 虚拟数据代理到数据中心的映射

表2 数据集到虚拟数据代理的映射
每个虚拟数据代理最终与1个数据中心一一映射。本文依据数据集和数据中心的数据请求关系来实现VDA与数据中心之间的映射。数据中心会发出数据请求,数据请求取决于当前任务的数据集需求,使得数据集具有一定的先后顺序参与数据密集型应用的运算。1个数据请求可能需要多个数据集,同一数据集也可能被多个请求处理。在数据请求中,对单一数据集的1次请求记为1,数据中心与个数据集的请求关系可采用×的矩阵表述如下:
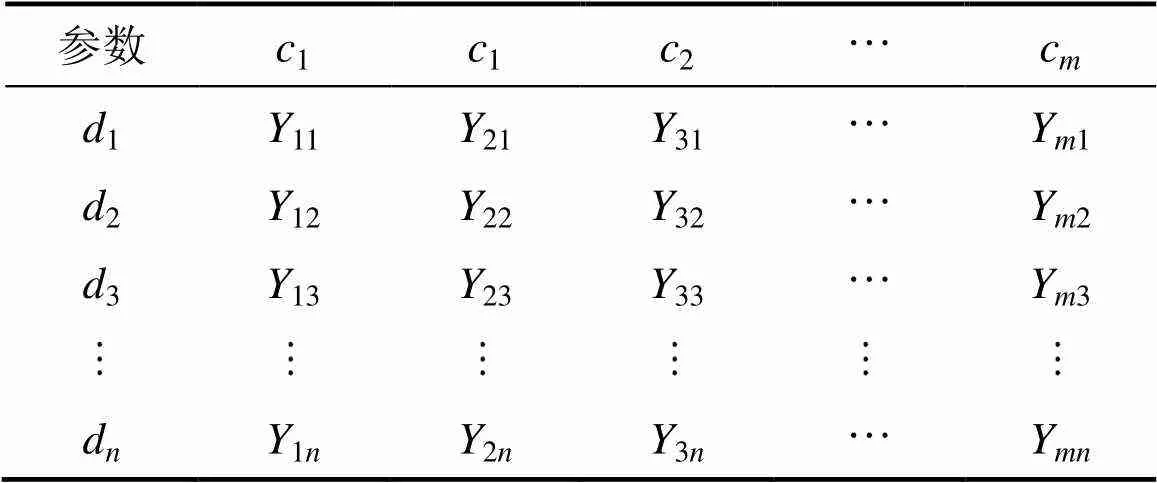
参数c1c1c2cm d1Y11Y21Y31Ym1 d2Y12Y22Y32Ym2 d3Y13Y23Y33Ym3 dnY1nY2nY3nYmn
其中:行向量对应数据中心,列向量对应数据集。依据隶属度计算,2.2节已完成数据集到VDA的映射,各VDA中都包含一组数据集子集。对每个VDA,计算各数据中心对其中所有数据集的总请求次数。总请求次数最大值对应的数据中心即为虚拟数据代理将存放的数据中心。总请求次数计算如下:
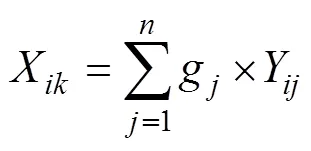
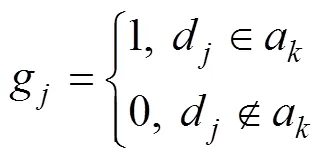
同样采用2.1节中的实例。对于虚拟数据代理=(1.45,0.168,0.052),其被2请求次数最多,因此,将被存储在数据中心2上。为记录方便,设VDA的编号与其所属的数据中心编号一致。同理,得到3个虚拟数据代理与数据中心1,2和3,根据总请求次数所得映射结果如表3所示。
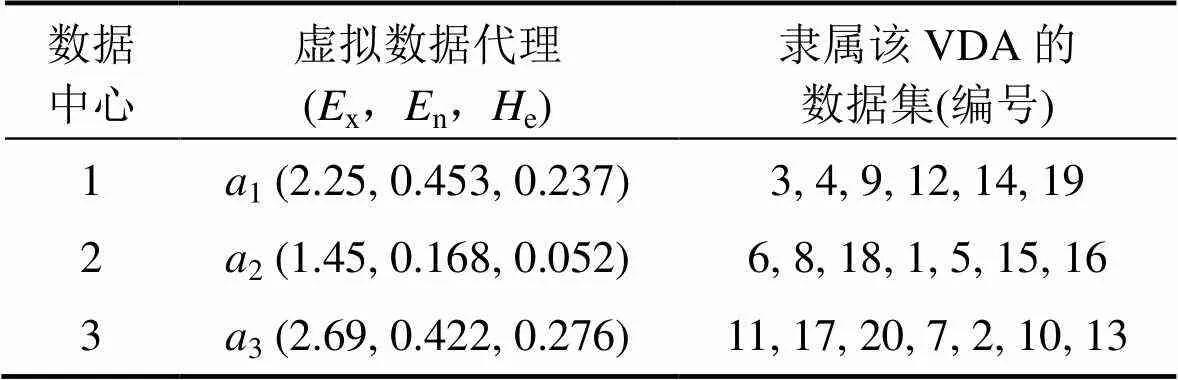
表3 映射结果
2.4 基于虚拟数据代理的云模型数据布局策略
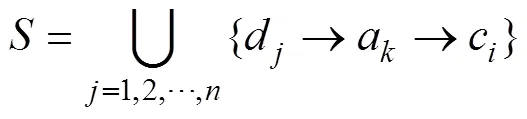
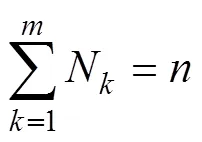
基于虚拟数据代理的云模型数据布局策略(CDPVDA)如下。
输入:个随机数据集
输出:数据布局结果
Begin
步骤1:FOR(=0;<;++) DO
找出与输入数据集之间有高依赖关系的数据集;
步骤2:FOR (=0;<;++) DO
计算式(2) AND
生成3个数字特征(x,n,e),记录生成云滴的个数;
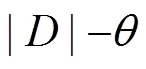
计算公式(3) AND
个云滴及其确定度();
步骤4:FOR (=0;<;++) DO
d放置于对应max(())的虚拟数据代理;
步骤5:FOR (=0;<;++) DO
找出每个数据中心总请求次数最高的虚拟数据代理 AND虚拟数据代理映射到数据中心;
End
3 实验
3.1 实验环境
为验证CDPVDA算法的性能,选用墨尔本大学网格实验室的CloudSim云计算仿真平台[16]进行实验。数据密集型工作流应用分别通过模拟设置和实际工作流应用这2种方式产生。
本文开发了数据密集型应用(data-intensive application, DIA)集成测试平台,自动化定制生成数据密集型应用,验证数据密集型应用是否满足数据密集型特征,以及在验证数据密集型应用满足数据密集型特征后,存储所生成的数据密集型应用。平台基于IOZone[17]中3个核心原子操作(R, W, RW)自动定制生成一种典型数据密集型应用IOZones,用户可输入IOZones的主要参数(最大节点数、最小节点数、DAG图的层数、最大宽度以及RW任务的个数)对IOZones应用进行定制,并且将数据密集型应用以DAG图的形式保存在本地。在生成DIA时会产生2个文件,分别是保存DIA各个节点之间依赖关系的DAG图信息文件iozones_dag.txt以及保存每个节点中的命令信息iozones_command.txt.iozone。任务是文件系统测试基准工具IOZone中的任务,是典型的数据密集型任务,每一个iozone操作都是独立的测试任务,具有原子性。
综合以上问题参数,通过分别改变工作流应用的数据集(文件数据)个数以及数据中心个数这2种参数,共生成(3×30+3)×5×4=1 860组测试实例。将COPVDA与随机Random算法和最具代表性的K-means聚类算法[6]进行对比试验,3种数据布局策略从应用执行过程中的数据移动次数以及传输时间情况这2方面进行对比和分析。实验结果取所有实验组数的平均值。
实验的硬件环境为Intel(R) Core(TM) i5 CPU 1.60GHz,RAM 4.00GB;软件环境为Ubuntu 16.04.2LTS,gcc version 5.4.0,qt version 5.6.2。
3.2 数据移动次数对比
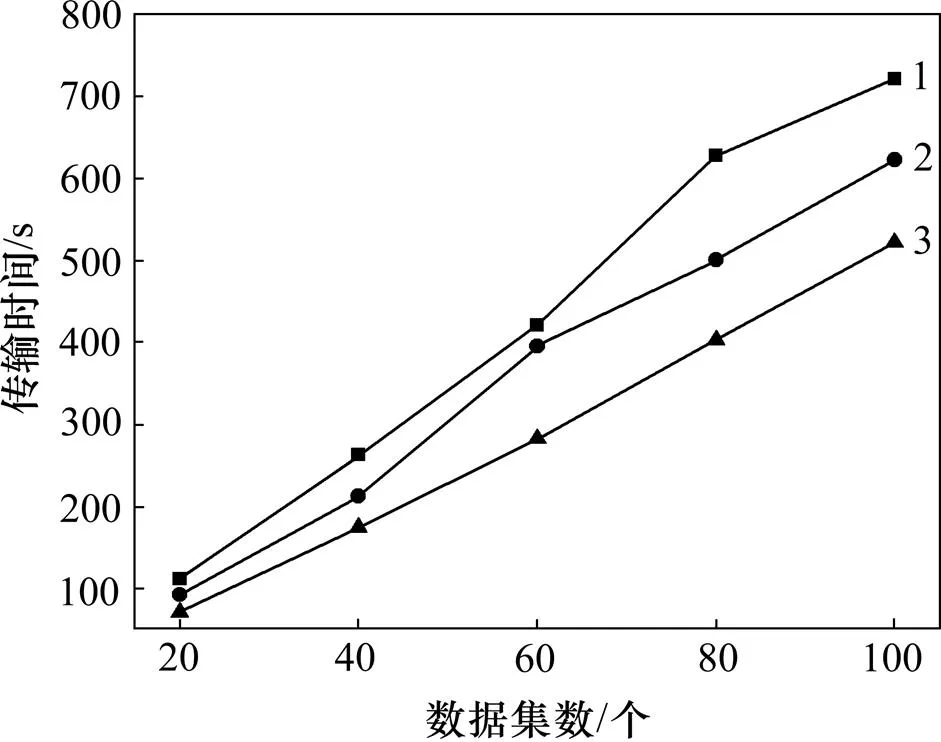
数据移动次数为科学工作流执行过程中数据集在不同数据中心的传递次数。数据集个数对移动次数的影响见图3(其中,横坐标表示数据集的数量,数据集数量由20增到100;纵坐标表示跨数据中心的数据移动次数)。从图3可见:随着数据量增多,3种策略的数据移动次数明显呈上升趋势,但本文策略对应的传输次数最少。
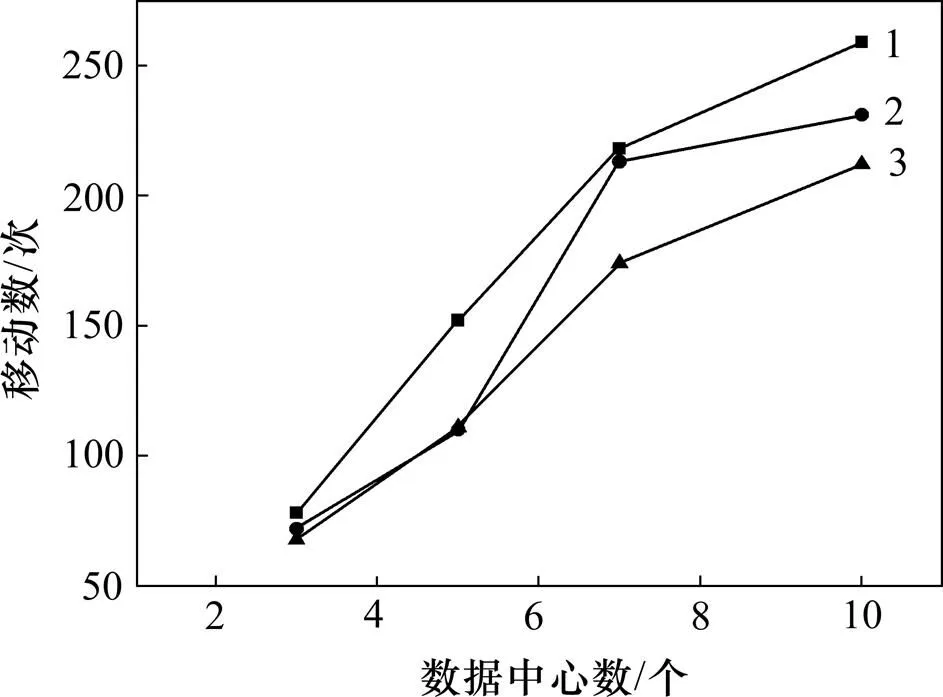
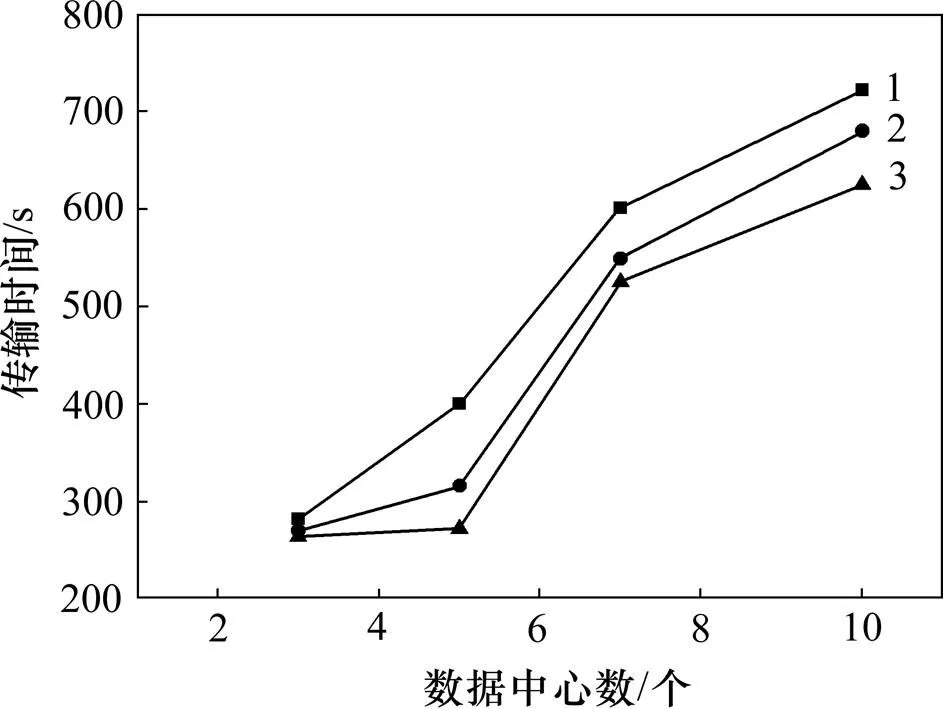
数据中心个数对移动次数的影响见图4(其中,横坐标表示数据中心的数量,纵坐标表示跨数据中心的数据移动次数)。从图4可见:当数据中心数量由3增到10时,3种数据布局策略所对应的跨数据中心数据移动次数都相应增加;虽然当数据中心数量较少时,本文策略与聚类策略相差很小,但综合来看,随着数据中心数量增多,本文策略的跨数据中心数据移动次数最少。

数据布局策略:1—Random;2—K-means;3—CDPVDA。
数据布局策略:1—Random;2—K-means;3—CDPVDA。
3.3 数据传输时间对比
数据传输时间为科学工作流通过HEFT任务调度算法来仿真模拟运行任务的整体时间。数据集变化和数据中心变化对传输时间的影响分别如图5和图6所示。从图5和图6可见:数据集以及数据中心的数量越大,3种数据布局策略所对应的跨数据中心数据传输时间越多,而本文策略所对应的数据传输时间开销一直最少。
上述实验结果表明:在云环境中实现数据密集型应用,随着数据量增多和数据中心增多,应用在执行过程中涉及的跨数据中心数据移动次数和时间开销都不断增大,而本文策略与基于随机算法以及聚类算法的数据布局策略相比时间开销减少,所获得的结果 较优。
数据布局策略:1—Random;2—K-means;3—CDPVDA。
数据布局策略:1—Random;2—K-means;3—CDPVDA。
4 结论
1) 针对数据布局问题中现有技术和方法存在的不足,构建虚拟数据代理云模型,设计出一种面向数据密集型应用的基于虚拟数据代理的云模型数据布局策略。与其他数据布局策略相比,本文的数据布局策略具有较好的性能,跨数据中心的数据移动次数降低,时间开销较少。
2) 数据布局过程中的核心即确立虚拟数据代理,其结果对第1个数据集很敏感,而本文采取的是随机抽取方法对数据布局策略有一定影响。下一步将进一步研究能够反映真实情况的云模型数据布局算法,并将该方法应用于具体的数据密集型领域。
[1] 宫学庆, 金澈清, 王晓玲, 等. 数据密集型科学与工程: 需求和挑战[J]. 计算机学报, 2012, 35(8): 1563−1578. GONG Xueqing, JIN Cheqing, WANG Xiaoling, et al. Data-intensive science and engineering: requirements and challenges[J]. Chinese Journal of Computers, 2012, 35(8): 1563−1578.
[2] BRIAN V E, HENRY H, SASHA A, et al. DI-MMAP—a scalable memory-map runtime for out-of-core data-intensive applications[J]. Cluster Computing, 2015, 18: 15−28.
[3] SENYO P K, EFFAH J, ADDAE E. Preliminary insight into cloud computing adoption in a developing country[J]. Journal of Enterprise Information Management, 2016, 29(4): 400−422.
[4] SHANGPengju, WANG Jun. A novel power management for CMP systems in data-intensive environment[C]//IEEE International Symposium on Parallel and Distributed Processing. Anchorage, Alaska, USA, 2011: 92−103.
[5] WANG Shangguang, SUN Qibo, ZHANG Guangwei, et al. Uncertain Qos-aware skyline service selection based on cloud model[J]. Journal of Software, 2012, 23(6): 1397−1412.
[6] YUAN Dong, YANG Yun, LIU Xiao. A data placement strategy in scientific cloud workflows[J]. Future Generation Computer Systems, 2010, 26(8): 1200−1214.
[7] 刘少伟, 孔令梅, 任开军, 等. 云环境下优化科学工作流执行性能的两阶段数据放置与任务调度策略[J]. 计算机学报, 2011, 34(11): 2121−2130. LIU Shaowei, KONG Lingmei, REN Kaijun, et al. A two-step data placement and task scheduling strategy for optimizing scientific workflow performance on cloud computing platform[J]. Chinese Journal of Computers,2011,34(11): 2121−2130.
[8] DENG Kefeng, REN Kaijun, SONG Junqiang, et al. A clustering based co-scheduling strategy for efficient scientific workflow execution in cloud computing[J]. Concurrency and Computation: Practice & Experience, 2013, 25(18): 2523−2539.
[9] 张甜甜, 崔立真. 基于释放和重构的科学工作流数据布局策略[J]. 计算机研究与发展, 2013, 50(S2): 71−76. ZHANG Tiantian, CUI Lizhen. A data placement strategy based on relaxation and reconstruction for scientific workflow applications[J]. Journal of Computer Research and Development, 2013, 50(S2): 71−76.
[10] PANDEY S, WU Linlin, GURU S M, et al. A particle swarm optimization-based heuristic for scheduling workflow applications in cloud computing environments[C]// IEEE International Conference on Advanced Information NETWORKING and Applications. Aina, Perth, Australia, 2010: 400−407.
[11] XU Changlin, WANG Guoyin, ZHANG Qinghua. A new multi-step backward cloud transformation algorithm based on normal cloud model[J]. Fundamental Informaticae, 2014, 133(1): 55−85.
[12] CHEN Jinpeng, LIU Yu, LI Deyi. Enhancing recommender diversity using gaussian cloud transformation[J]. International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems, 2015, 23(4): 521−544.
[13] MA Hua, HU Zhigang, LI Keqin. Toward trustworthy cloud service selection: a time-aware approach using interval neutrosophic set[J]. Journal of Parallel & Distributed Computing, 2016, 96(C): 75−94.
[14] ZHANG Xinxin, HU Zhigang, ZHENG Meiguang, et al. A novel cloud model based data placement strategy for data-intensive application in clouds[EB/OL]. [2018−08−21]. https://doi.org/ 10.1016/j.compeleceng.2018.07.007.
[15] WANG Guoyin, XU Changlin, LI Deyi. Generic normal cloud model[J]. Information Science, 2014, 280: 1−15.
[16] AUFFHAMMER M, HSIANG S M, SCHLENKER W, et al. Using Weather Data and Climate Model Output in Economic Analyses of Climate Change[J]. Review of Environmental Economics & Policy, 2013, 7(2): 181−198.
[17] BAUN C. Mobile clusters of single board computers: an option for providing resources to student projects and researchers[J]. Springer Plus, 2016, 5(1): 360.
[18] DALEY C S, GHOSHAL D, LOCKWOOD G K, et al. Performance characterization of scientific workflows for the optimal use of burst buffers[J]. Future Generation Computer Systems, 2017, 53: 69−73.
[19] HU Zhigang, LI Jia, ZHENG Meiguang, et al. Hypergraph-based data reduced scheduling policy for data-intensive workflow in clouds[C]// ICPCSEE 2017. Third International Conference of Pioneering Computer Scientists, Engineers and Educators. Changsha, China, 2017: 335−349.
Cloud model construction of virtual data agent and data placement
HU Zhigang, ZHANG Xinxin, ZHENG Meiguang, CHANG Chenglong, LI Jia, YANG Liu
(School of Computer Science, Central South University, Changsha 410083, China)
Considering the dependence between data sets and the storage capacity of data centers, a new type of entity called virtual data agent was introduced. The data placement problem was converted into two mapping processes namely mapping from the data set to the virtual data agent and mapping from the virtual data agent to the data center. Cloud model based data placement algorithm with virtual data agent(CDPVDA) was proposed. The results of simulation experiment show that compared with two typical data placement strategies, CDPVDA can reduce data transmission overhead between data centers by 5% to 20%.
cloud model; data-intensive application; virtual data agent; data placement
TP391
A
1672−7207(2019)03−0587−09
10.11817/j.issn.1672-7207.2019.03.012
2018−04−10;
2018−06−05
国家自然科学基金资助项目(61602525,61572525) (Projects(61602525, 61572525) supported by the National Natural Science Foundation of China)
郑美光,博士,副教授,硕士生导师,从事云计算、大数据等研究;E-mail: zhengmeiguang@csu.edu.cn
(编辑 陈灿华)
猜你喜欢
中国民间疗法(2021年1期)2021-04-20 02:30:48
海峡科学(2021年12期)2021-02-23 09:43:28
山东冶金(2019年3期)2019-07-10 00:53:56
小天使·六年级语数英综合(2019年6期)2019-06-27 06:42:53
趣味(数学)(2018年12期)2018-12-29 11:24:00
现代营销(创富信息版)(2018年8期)2018-09-08 08:51:50
酒·饮料技术装备(2018年1期)2018-04-28 09:09:07
学生天地(2016年23期)2016-05-17 05:47:15
地球环境学报(2016年1期)2016-03-06 11:55:09
广州广播电视大学学报(2015年2期)2015-12-29 11:02:13
