
利用深度残差网络的高分遥感影像语义分割
2019-04-12 06:10:12唐文莉
应用科学学报 2019年2期
李 欣,唐文莉,杨 博
1.武汉大学遥感信息工程学院,武汉430079
2.武汉大学地球空间信息技术协同创新中心,武汉430079
3.武汉大学测绘遥感信息工程国家重点实验室,武汉430079
随着卫星传感器技术的发展,遥感影像不仅在数量上呈指数型增长,空间分辨率、光谱分辨率也得到显著提高.高分辨率遥感影像获取的精细化信息可以更好地应用于影像分析与解译,同时也为影像分割技术带来了新的挑战.传统影像分割通常是根据输入影像的灰度、颜色、形状、纹理等特征,将其分割为互不重叠的独立区域.但是随着空间分辨率的提高,同一个对象将由更多的像素构成,导致传统方法在分类特征、分割标准的选择上难度提高,也突显出传统模型通用性差、自动化程度低的缺点.相对于传统影像分割方法,基于深度学习网络模型的语义分割方法不仅能够自动学习特征,表达单像素语义,而且其分割精度受原始影像数据差异的影响较小.在数据训练样本足够多的情况下,采用优异的网络模型和训练方式,可以自适应并高效地应用于多种遥感影像.
影像语义分割着重于预测单个像素点的语义标签[1],即利用网络自动提取的多维特征来描述单个像素,通过一定的特征组织方式赋予图像中每个像素点所属类别概率,进而逐像素预测语义标签.文献[2]利用全卷积神经网络模型(fully convolutional network,FCN)进行端对端的像素级语义分割研究,此后基于深度学习的语义分割得到快速发展.全卷积语义分割模型在实现像素级输入输出的同时增加了输入影像尺寸灵活性特点,但是全卷积网络的上采样方式不够精细,输出的预测标签图较粗糙,因此文献[3-7]的改进模型应运而生,并通过数据增强、多尺度融合[3,8]、后处理(CRF[9]、voting[10]等)、附加特征(高程信息、植被指数、光谱特征)[11]等优化方式提高模型对地物对象的区分能力.
当前遥感影像语义分割方法通常基于卷积神经网络如VGG[12]、GoogLeNet[13]、ResNet[14]等模型进行优化改进.另外,由于遥感影像语义分割的数据集较少,难以直接训练出一个优秀的语义分割模型,因此现有研究通常利用遥感影像与自然图片在纹理、色彩等特征上的相似性,将在ImageNet这种大型图像分类数据集中预训练的模型参数用于初始化语义分割网络的部分参数,并在语义分割模型的训练过程中进一步对参数进行微调,从而提高语义分割模型的训练效率和效果.本文基于深度残差网络模型构建高分辨率遥感影像多尺度语义分割模型,针对遥感影像不同尺度地物分类精度差异较大的现象,采用多尺度数据增强提高样本数据集尺度多样性,通过引入Atrous卷积实现多尺度融合上采样过程,进而缓解粗粒度上采样方式对预测结果的影响.该模型在未采用任何后处理的情况下依然能够输出精度较高的预测结果.
1 语义分割模型
本文方法采用ImageNet数据集1ImageNet数据集在图像分类、识别检测、分割中应用广泛,下载地址为:http://www.image-net.org/aboutstats进行深度残差网络模型预训练,通过在ISPRS Vaihingen 2D labeling数据集2ISPRS Vaihingen 2D labeling数据集详细描述以及数据下载可通过网址:http://www2.isprs.org/commissions/comm3/wg4/2d-sem-label-vaihingen.html上进行微调,使残差网络模型能够应用于高分辨率遥感影像语义分割任务.目前微调主要使用ImageNet数以百万计带标签的训练集数据,使预训练的模型具有非常强大的泛化能力,这些预训练模型的中间层包含非常多一般性的视觉特征,只需对预训练模型的后几层进行微调,再应用到与自然图像有类似低维特征(如角点、边缘线等)的遥感影像数据上.由于当前使用的遥感影像语义分割数据集相较于ImageNet数据集样本量小、样本多样性不足,且数据类型差异较大,因而直接采用初始模型训练测试不能有效获取优异分割模型.针对遥感影像分割对象尺度多样性特点,本文方法通过多尺度数据增强提高样本数据集鲁棒性,并基于Atrous卷积方法扩大感知区域,改进深度残差网络模型,以实现高分辨率遥感影像多尺度语义分割,本文模型框架如图1所示.
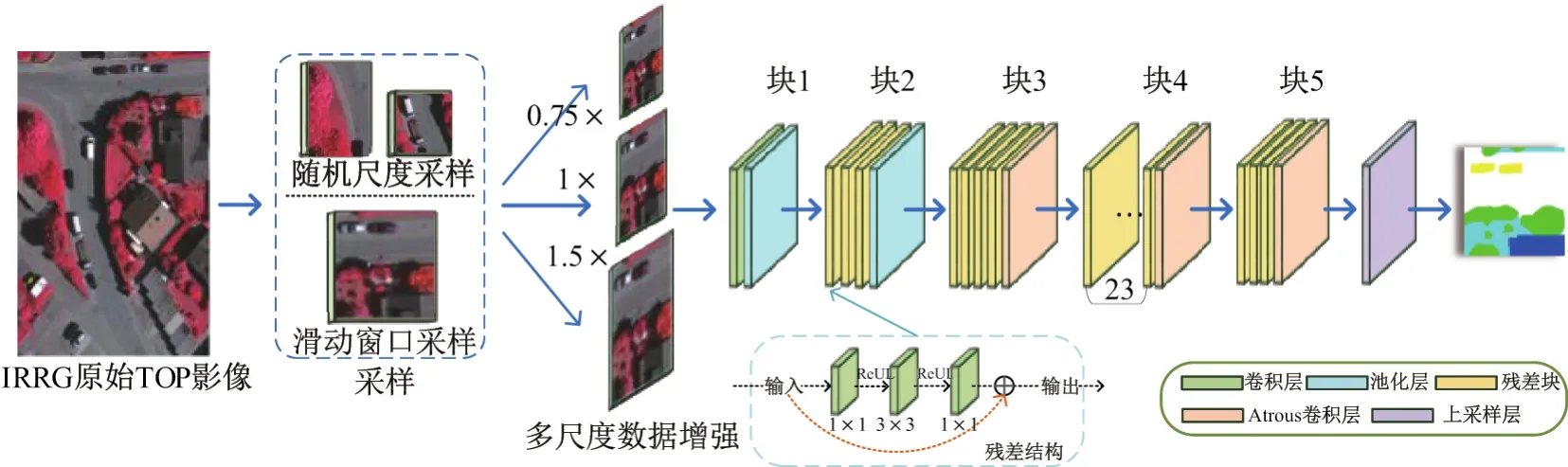
图1 基于深度残差网络的多尺度语义分割模型Figure 1 Multi-scale semantic segmentation model based on deep residual network
1.1 基于全卷积改进的深度残差神经网络
残差神经网络的最大特点是利用残差的形式增加网络深度,进而提高特征描述的维度,有助于更加形象地学习对象,保证了深度网络结构训练有效性的同时极大提高模型精度.而全卷积网络的特点是将传统卷积网络中的全连接层转化为全卷积层,通过在全卷积层中进行上采样获得与输入影像相同尺寸的具有空间信息的输出结果.因此通过将残差神经网络的卷积层以全卷积形式改进,可以获取端到端的像素级分割结果.
残差神经网络的核心思想就是将输入的映射与最优解之间的差值用函数表示出来,通过优化产出的方式加深网络,解决梯度弥散,其核心结构如图2所示.
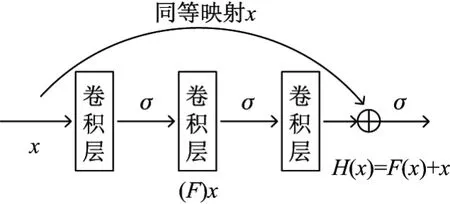
图2 残差网络核心结构Figure 2 Basic structure of residual network
其中,结构包含3层卷积层,卷积核大小依次为1×1、3×3、1×1,x为输入对象,σ为非线性函数ReLU,卷积层权重由左到右依次为W1、W2、W3.则经过3层卷积处理输出结果F(x)为

通过一个同等映射以及第3个非线性函数,可以获得输出H(x)为

当输出H(x)与输入x能够满足恒等条件时,深层模型就等同于浅层模型,即能够避免网络退化问题,因此可以将恒等条件转化为学习残差函数F(x)=0.
以全卷积形式改进后的深度残差网络模型在传统全卷积网络模型的基础上加深网络深度,提高了模型分割准确率.本文考虑到实际任务中分割性能与运行速度需相互权衡,采用基于全卷积形式改进的101层深度残差网络模型,可结合图1右侧的模型核心部分概览,其中包括1层卷积层和1层最大下采样层,以及33个残差块,每个块中包含3个卷积层.
1.2 多尺度Atrous卷积
在卷积网络中,随着池化层的作用特征图解析度逐层降低,最终预测的精细程度也随之下降,利用Atrous卷积方式能够有效减少池化层对特征图解析度的影响.以大小为3×3的滤波器来说明Atrous卷积方式的核心思想Hole算法,如图3所示.
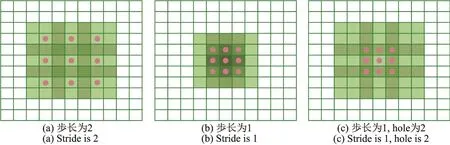
图3 Hole算法示意图Figure 3 Sketch map of Hole algorithm
图3(a)表示直接采用卷积网络中的原始卷积核提取特征并池化时,步长为2的池化层所作用的区域,由于滤波器中相邻的权重作用在特征图上的位置都是物理连续的,池化层的作用区域为7×7个像素大小.而当池化层步长由2变为1时,作用区域范围缩小为5×5,如图3(b)所示.为了保证感受野不发生变化,采用Hole算法,通过设置对应的Hole值将连续的连接关系变成跳跃连接,使得感受野仍然与池化之后的感受野对应,以此在不增加参数的情况下继续进行网络训练,如图3(c)所示.
利用Atrous卷积策略修改后两层卷积块可以在保留更多细节,在已经训练好的模型上进行微调时,能够得到更加精细的密集预测标签.由于遥感影像解译中通常具有多种尺度地物,因此本文提出多尺度Atrous卷积策略,通过设置不同的Hole值大小,得到4种不同范围感受野,对不同尺度的特征图相加融合实现多尺度残差网络语义分割,这种改进后的网络结构为多尺度Atrous卷积,如图4所示.本文在残差块4、5的降采样层均采用多尺度Atrous卷积方法.
1.3 多尺度数据增强
相对于自然图像识别、分类、分割数据集,现有遥感影像数据集通常规模较小,合适的数据增强操作如旋转、缩放、尺度变换等可以提高模型训练精度.本文方法采用随机样本选取与多尺度增强两种方式相结合增加数据集样本量,提高数据集多样性.首先在已有滑动窗口采样基础上,通过随机样本采样增加了更多的图像块作为训练样本,即对每张原始影像,随机在其影像内部裁剪224×512像素的小样本.然后对固定滑动窗口采集的小样本及随机采样图像块以二次线性插值的方法进行多尺度变换,变换倍数分别为0.75、1.0、1.5,进而组成不同输入尺度的样本数据集.
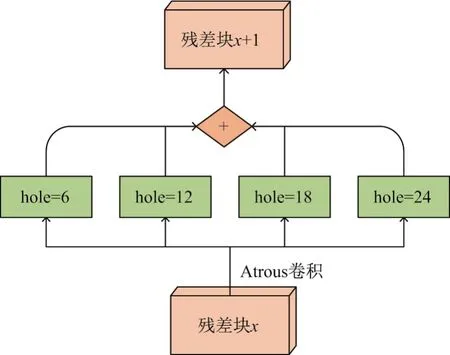
图4 多尺度Atrous卷积Figure 4 Multi-scale Atrous convolution
1.4 评价方法
采用F1分数[15]来评价分割对象的分类精度,将所有分类正确的像素数目占总像素数目的比值作为总精度进行评价,其单类对象精度和总体精度均是由验证集中所有影像精度平均计算所得.F1分数的定义为

式中,Precision为精确率,表示该类被正确检测到的数目占模型预测中属于该类的数目的比例,Recall为召回率,表示该类被正确预测到的数目占样本即真实标签中该类总数目的比例,其表达式为
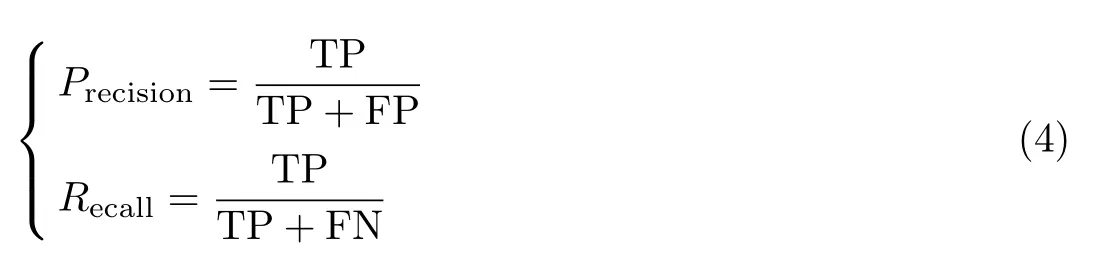
式中,TP(true positive)表示预测结果为该类,真实标签也为该类的像素数目;TN(true negative)表示预测结果不为该类,真实标签也不为该类的像素数目;FP(false positive)表示预测结果为该类,真实标签不为该类的像素数目;FN(false negative)表示预测结果不为该类,真实标签为该类的像素数目。
对于模型分割精度,本文采用总体精度(overall)进行评价.总体精度是模型在所有测试集上预测正确的像素数量与总像素量之间的比值.
2 实验结果与分析
2.1 实验数据
用ISPRS Vaihingen 2D semantic labeling数据集评估本文所提出模型的实验数据.该数据集包含33张不同尺寸的TOP(true ortho photo)影像,均取自德国Vaihingen地区,其地面采样间隔为9 cm,由近红外、红外、绿色3个通道(IRRG)构成.数据集提供了16张影像的真实标签数据用于模型训练与验证,真实标签数据按照像素划分为以下6类:不透水层、建筑物、低矮植被、树木、车辆、其他(背景).图5为其中一张TOP影像及其对应的真实标签数据,标签图颜色与类别对应关系如表1所示.

图5 TOP影像及其对应的真实标签数据Figure 5 TOP image and its ground truth

表1 标签图类别与颜色对应表Table 1 Category and color correspondence of labeled images
模型训练期间将具有真实标签数据的TOP影像划分为训练集和验证集,选取其中15张影像作为训练集(编号:1,3,5,7,11,13,15,17,21,26,28,30,32,34,37),剩余1张作为验证集.最终进行官方验证的分类模型则是采用全部16张带有标注的影像作为训练集产生.
2.2 实验
2.2.1 实验环境
实验环境基于NVIDIA Tesla K80 GPU,Caffe深度学习平台搭建,由于Vaihingen数据集中原始样本影像尺度过大,直接使用原始影像作为输入进行计算会超出GPU显存负荷,因此采用滑动窗口采样方式将原始影像采样为321×321像素大小的影像块作为基础试验样本,采样步长为160像素,即相邻图像的覆盖率为50%.采用poly学习策略,初始学习率设置为10-8,冲量设置为0.9,权值衰减设置为0.000 5.训练策略采用批量随机梯度下降算法.
2.2.2 改进方法实验方案设计
针对本文改进方法,从基础模型、Atrous卷积、数据增强三方面进行试验方案设计.
1)基础模型
采用深度学习方法进行语义分割时,基础网络模型结构起着至关重要的作用,随着卷积层深度增加,卷积网络描述对象多维特征的能力也随之提升,因此本文模型采用基于深度残差网络的模型结构来增加卷积层深度.为了验证基础模型卷积层结构对遥感影像语义分割精度的影响,设计基于深度残差网络模型和基于VGG16网络模型的全卷积网络结构进行遥感影像分割精度实验研究.
2)Atrous卷积
在基于深度残差网络的全卷积结构基础上,通过加入Atrous卷积策略验证该策略对提高模型精度的帮助.由于Atrous卷积从深度残差网络中残差块4中的卷积层开始使用,因而残差块4、5的输入特征图均没有进行池化,残差块4、5中的卷积层hole值依次设置为2、4以对应相同的感受野范围.通过Atrous卷积实验验证Atrous卷积策略对模型精度的提高作用.
3)数据增强
通过旋转、多尺度缩放、随机尺度选取3种数据增强手段,设计实验验证数据增强对模型分类能力是否有提高.在基础试验样本基础上,分别对原始影像进行旋转增强、多尺度缩放(0.75倍和1.5倍尺度缩放),以验证旋转、缩放数据增强方法是否对本文数据集对象识别能力有提升.然后将精度有提升的方法与随机尺度选取(在224×512范围内随机设置图片长宽)相结合,增加样本数据以验证随机选取数据增强方法的全局性优势,提升模型精度.
2.3 结果与分析
为验证深度残差模型、Atrous卷积方式以及多尺度数据增强策略对于基础模型的改进有效性,本文根据使用的基础模型,对是否采用Atrous卷积改进及是否进行数据增强开展对比实验,以总精度来定量评价模型的分割能力,实验结果如表2所示.
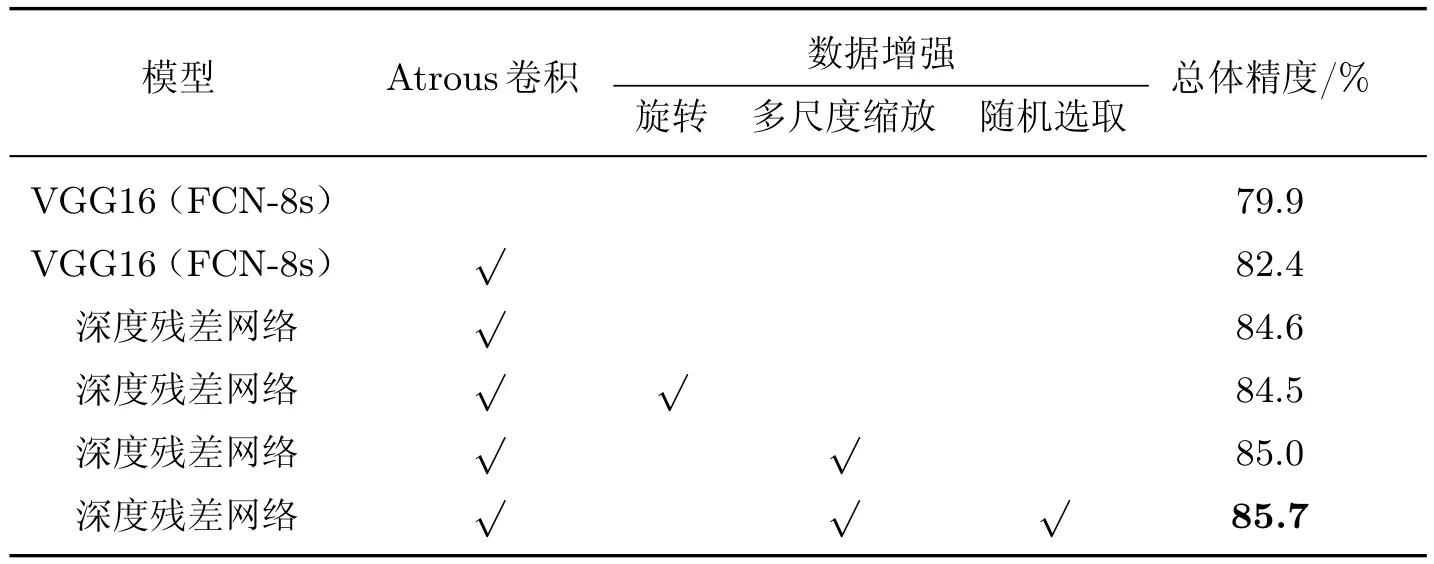
表2 对比实验结果表Table 2 Comparison experimental results
从表2可以看出,基于VGG16模型的实验精度最低引入Atrous卷积后精度显著提高了2.5%,因此在之后的实验中均加入Atrous卷积.在无数据增强的前提下,由深度残差网络替代基础模型精度上升2.2%,一定程度上说明更深层的神经网络对对象特征的学习能力更强.为了进一步提高网络精度,对数据集进行旋转数据增强,结果表明旋转增强对总体精度提高没有帮助.去除旋转增强,对原始数据集采用多尺度增强相对于无数据增强时精度有微弱提高,进一步加入随机样本增强后,两种增强方式结合的情况下精度提高了1.2%.说明本文方法对于分割精度有明显改善.
此外,将基础模型与基于Atrous卷积及多尺度数据增强的深度残差模型分别与真实标签图进行对比,可以看出本文方法的模型分割结果能够更好地表达建筑物规则性,对小对象(如车辆)的识别能力更强,相比于基础模型,本文模型对小对象周围的像素分类错误识别的概率更低,在树木与低矮植被的区分能力上也有显著提高,如图6所示.
将验证集加入训练样本中,得到的深度残差网络多尺度语义分割模型在ISPRS测试集下的结果提交至ISPRS官网3本文结果在官网结果页面名称为WUH_W3,详细结果可通过该网址查看:http://ftp.ipi.uni-hannover.de/ISPRS_WGIII_website/ISPRSIII_4_Test_results/2D_labeling_vaih/2D_labeling_Vaih_details_WUH_W3/index.html,表3为该数据集部分高分辨率遥感影像语义分割结果,可以看出,本文模型精度较高,且在不透水层与车辆类别上均有较高的分类精度.特别是对车辆类别,相较于其他方法具有更好的优势,说明本文的多尺度数据增强改进大大提高了小目标对象的分类精度.
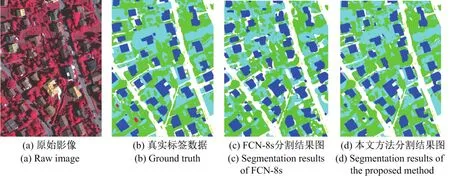
图6 分割结果Figure 6 Segmentation results
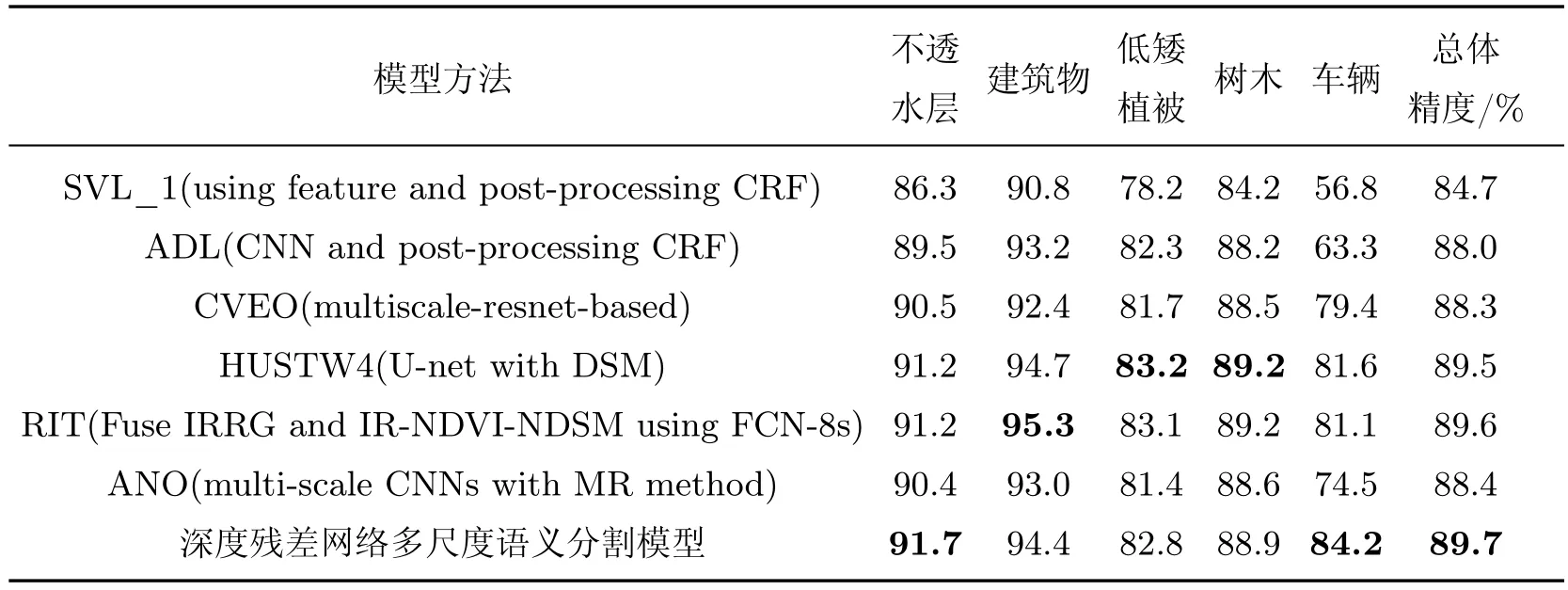
表3 ISPRS Vaihingen 2D labeling竞赛结果表Table 3 Contest results of ISPRS Vaihingen 2D labeling
3 结语
本文利用深度残差模型实现端到端的遥感影像语义分割任务,并通过引入Atrous卷积、改进池化层和降采样层来改善分割网络结构,进而获得更加精细的分割结果.此外,针对遥感影像数据量较少的特性,引入多尺度和随机样本的数据增强,提升模型对小样本的分辨能力,从而提高模型的分类精度和泛化能力.在ISPRS 2D Vaihingen语义分割数据集上的试验结果表明,本文方法在对小目标对象的分类上明显优于现有的基于深度学习的遥感影像分割算法.
为了进一步提升现有模型的分割精度和泛化能力,未来工作改进方向如下:1)在模型中引入高程信息,与TOP影像数据融合,一方面可以增加信息量,另一方面可抽取特征作为先验纠正卷积神经网络的分类结果;2)加入后处理方法,如CRF等优化分割结果;3)针对遥感影像数据量少的特性,引入对抗神经网络(GAN)来增大数据的多样性.
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23 13:26:48
北京航空航天大学学报(2020年10期)2020-11-14 09:26:02
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06 09:08:52
开放教育研究(2020年2期)2020-03-31 01:54:14
自动化学报(2019年6期)2019-07-23 01:18:32
太空探索(2016年5期)2016-07-12 15:17:55
现代语文(2016年21期)2016-05-25 13:13:44
河南科技(2015年8期)2015-03-11 16:23:52
大连民族大学学报(2015年2期)2015-02-27 08:28:11
时代英语·高三(2014年5期)2014-08-26 17:01:17
