
地块系统的空间布局和城市多样性—空间形态中差异性变量的实证研究
2019-04-10 07:40:02拉尔斯马尔克斯伊芙热尼娅波布科娃
城市设计 2019年6期
拉尔斯·马尔克斯 伊芙热尼娅·波布科娃
邓成汝 李帅峥 林 戈 [译]
1 引言:空间容量的理论
在任何城市模型中,最重要的变量都是距离和吸引力[1]。空间句法研究促进了几何关系描述新方法和距离度量方法的发展。它们开辟了新的研究领域,尤其是在捕获行人运动轨迹方面[2]。但是,对吸引点的描述和度量,在该领域却一直未受重点关注。
在更早的一篇论文中,我们将吸引力解释为以密度和差异性的形式呈现的、对距离变量进行补充的空间形态变量。其中,密度和建筑相关,而差异性与地块系统相关。在本文中,我们将把重点放在较少受到研究关注的差异性变量上。早期的实证研究表明,土地划分成地块的程度,与社会经济要素(例如居民和经济活动)的多样性之间存在相关性。在此基础上,我们会在此把对斯德哥尔摩广泛实证研究的结果展现出来,目的在于为提出描述空间形态差异性的空间变量铺平道路。这个变量会直接影响社会经济多样性。本研究将会关注地块系统布局的衡量指标和经济活动的多样性模型之间的相关性。
显然,关于城市多样性众多辩论源于简·雅各布斯(Jane Jacobs)的著作。在她所有关于城市的著作中,多样性都是她的中心主题。其中最广为人知的,便是《美国大城市的死与生》(The Death and Life of Great American Cities)[3],以及她在那本书中提出的产生城市多样性的4个条件—一个以上的主要功能;小街块;不同年代的建筑物;密集人口—体现出了这一主题。在这4 个条件之中,正如接下来会看到的那样,若需要为我们的模型提出一种度量差异性程度的指标,我们会发现,“不同年代的建筑物”这一条件—也许有点让人吃惊,是最有希望被选中的。其原因是,尽管“一个以上的主要功能”这一条件确实对城市的多样性产生很大的影响,但它涉及的纯粹只是多样性的产生过程,而没有与我们想在此寻找的那种空间形式有任何明显的联系。另一方面,“小街块”的概念,更多涉及的是可达性,或者更准确来说,是前面提到的在空间句法理论中所涉及的认知上的距离的布局。[4]最后,密集人口的概念很显然涉及的只是通常意义的密度的概念,而这已经得到充分的讨论。“不同年代的建筑物”的概念,从另一方面来看,似乎在根源上与其他条件有所不同。而且乍一看,这一概念本身看起来既是理论上最乏味的,也是最不具可操作性的——我们如何规划出具有不同年代建筑物的城市,或者就此事发展出一套理论呢?但是,这正是我们将要尝试的。
这里的陷阱是,固执地只把建筑物视为事物,而不视作过程。向后者的转变意味着要把建筑物营造的空间转换为建筑物在其中生长的空间,即不同的领域定义了我们称之为地块的物权。这些空间更多的是从制度上被定义,而不是从实体空间上定义的。但即便如此,它们无疑也代表了城市空间中较为中心和常见的类别。如果我们开始考虑这点,我们就会意识到,将空间划分成若干个单独的空间,对任何建筑工作来说,都具有多么基础的作用——如果没有用墙壁划分空间的艺术,那么建筑又是什么呢?这背后的主要原理正是产生多样性的目的,即为单独的不同类别的“事物”或“活动”,生成各自独立的空间。[5-6]这显然是将建筑物划分为独立房间背后的主要理由。
因此,对土地的水平划分(无论是在实体空间上,还是在制度上),作为一种基本的空间手法似乎是有充分根据的。与此同时,增加变化的方式,可以采取类似于提高密度的基本手法——在竖直方向增加楼层。如果我们将这个概念更具体地引入到城市空间形态模型中,我们可以提出下面的论点:地块的特定区域,作为由一特定集合的物权所界定的一块土地,代表了城市中一个角色的存在。这个角色存在的形式可能是这块土地的所有者,或者是需要在城市的某一特定空间中进行各种活动的类似角色。只要维持在不同机构设定的框架内,例如,地方规划法规,或特定土地的特定物权内,特定角色就可以在此特定区域内自由行动。
此外,此类角色通常会制定一项特定策略,以进一步发展和维护其物权。因此,与地块相对较少的地区相比,地块相对较多的地区似乎有潜力容纳更多这样的角色,从而有更多的策略来开发和维护其地块,而且这很可能也意味着这样的策略更具备多样性。最后,与具有相对较少地块,从而拥有更少角色和更少发展策略的区域相比,这种区域似乎更具备产生出多样化内容的潜力。因此,似乎正是土地的这种划分方式,以及因此在角色和策略中产生出的潜在的多样性,随着时间的流逝,能使现存建筑产生出更大的变化,也就是雅各布斯“不同年代建筑物”的概念。
正是这种假设使我们相信,在地块的数量、形状、大小和布局上,我们可以识别出空间形态的一个变量。这个变量与城市多样性有直接关系,并对这种多样性产生直接的影响。此外,我们提出,将某个区域中的地块数量称为该区域的空间容量,即容纳差异的能力。[5-6]其中,更高的容量会更有潜力产生异质化的内容,而更低的容量则更有可能带来同质化的内容。显然,其他因素(例如土地使用法规,或其他空间变量,还有街道的中心性和建筑物密度)也可以覆盖地块系统的空间形态在此所带来的影响,但是在研究中,我们试图隔离开来的,是这个变量给城市实体或过程所带来的特定 影响。
在下文中,我们将论述出一项实证研究。该研究将进行关联性分析,将不同类型的多样性作为因变量,将被衡量为地块可达性的差异性程度作为自变量。本文的框架如下:接下来的两节将介绍衡量社会经济多样性背景理论的复杂性,其中会特别关注尺度和分类问题。这些章节将会为后文实证研究中所作出的选择打好基础。此后,我们将对实证研究的研究方法进行概述,包括:(1)如何衡量作为因变量的社会经济多样性;(2)如何衡量作为自变量的空间差异性;(3)如何能够解决尺度问题;(4)如何构建统计模型以隔离差异性变量带来的影响;(5)对统计检验的描述。此后将会展示本研究的研究结果。最后的结论将会结合前面介绍过的理论来对研究结果进行讨论,并给将来的研究提供建议。
2 多样性与尺度:何为尺度
尺度这一术语应用于许多领域,并且通常在多学科之间的解释不尽相同。其相关概念如:等级、分辨率、范围和层次结构,也通常用作其替换词或同义词。在城市研究中,对尺度一词的广泛引用,也促使其产生了各种分类,如“本地—全球”、“微观—中观—宏观”、“邻里—地区—城市—区域”。然而,这些术语由于其内在的相对性而具有模糊性。对于特定的情况,它们的定义通常具有关联性,而对于某些术语,如“本地”的理解则因城市而异。这将成为一个问题,因为在任何城市建模或空间分析的研究中,尺度的选择将从根本上影响研究的分析和解释。
根据迈克·巴蒂(Mike Batty)的说法,尺度基本上是指两件事,“我们观察城市的分辨率水平,本质上是地图比例,以及不同大小的地点或城市的功能差异级别”。[7]也就是说,尺度可能涉及分辨率或大小,但两者也很容易被混淆。例如,上面列出的所有分类,例如与高度相关的宏观—中观—微观集,通常指分辨率,尤其是在具体城市环境中应用时可以容易地用于大小分类。例如,邻里作为与“区域”或“城市”尺度相关的特定尺度,在我们谈到“邻里”时,我们是在谈论城市的特定分辨率,即放大一个区域,以便我们可以识别更多有关该区域情况的详细信息,但这当然不会使我们所讨论的城市变小或变大。尽管如此,在这个过程中,我们很容易在一开始把特定的邻里想象成一个小城市,也就是说,我们已经改变了城市的尺度,但显然不是这样。
我们可能会陷入一个包罗万象、更宏伟或更抽象的城市,这样做与现实相对应的直接风险就是将尺度称为等级。用艾伦·威尔逊的话说:“尺度是一种等级,在这方面清晰的构想至关重要。”一个典型的例子是将城市现象分为微观、中观和宏观尺度,这在概念上意味着有一系列的城市是相互重叠的,尽管我们知道事实并非如此。当再次反思时我们会立即意识到这是无稽之谈,但即便如此,从概念上讲,这种失误已经形成,也很难记住我们所说并不是真的。例如,当新空间经济的引入者谈论离心力和向心力可以集聚城市经济活动的时候,我们被诱导着将此想象成某种宏观尺度的作用力徘徊在城市中。[8]实际上,这些作用力是在综合宏观尺度上分析确定的,但它们肯定不是在宏观尺度上表现出来的。相反,这种作用力虽然在宏观上留有明显痕迹,但其必然植根于人类微观层面的日常活动中。
此外,还需要明确我们讨论的尺度的实质是什么。继威尔逊之后,可以说,空间分析人员在分辨率上面临3 方面问题,“需要将相关系统的构成进行界定和分类;其中很多构成部分需要在空间中定位;且其行为需随着时间动态来进行描述”。这导致需要确定尺度的三个特点:可划分性(分类的数量和广度)、空间性(实体所在的区域单元大小)和时间性(为纵向描述和分析提供基础的单位时间长度)。时间解析本身就是一个大问题,因为大多数空间分析简单地排除了时间维度,从而产生了我们所习惯的典型的城市静态描述。原则上来说,这些静态描述是非常不现实的,且对于多数使用此描述的研究得出的结论是有风险的,然而我们在大多数城市研究中用的正是静态描述。另外,在大部分研究中,尺度划分和尺度的空间性都存在。但是,必须跟踪大小和分辨率分别在不同的尺度划分和尺度空间中如何变化,这便再次造成了诸多混淆。划分的实体,即为我们要在空间定位和分析的现象或活动,例如企业可以有不同的规模,也就是说,可以有大型企业和小型企业,但这并不意味着分辨率的变化。然而,我们当然也可以有分类数据的分辨率变化,例如,如何将企业的规模进行分类。举个例子,我们可以使用高分辨率来做到这一点,比如使用绝对员工数量;或者使用较低的分辨率,比如将员工人数进行分组。
另一方面,如果我们想要讨论空间大小,需要另一种路径。首先,需要绝对清楚的是我们要分析的空间大小,其次是从何种角度定义空间大小。例如,如果我们想要比较两个邻里的大小,从两个空间单元相比较的原则上来说,我们当然可以简单地通过比较各个单位的大小,例如通过测量它们的面积来做到这一点。然而,在大多数情况下,这种比较可能不够翔实,而且相当武断。更有趣的是以某种系统的方式衡量空间大小,尤其是考虑到在当代研究中城市系统理论的主导地位。这将涉及以某种方式衡量单个空间单位对整个系统的影响大小或重要性,例如,单个街区在整个地区或城市的作用。还有,它可以涉及从单个空间单位到所有其他空间单位的相对距离,其中短距离可以被认为是一个全局性位置,并被解释为一种衡量个体空间单位的系统规模的方法。此外,这种分析可以在单个空间单位的不同距离半径范围内进行,例如按米制距离设置。反过来,这种半径可以用作不同尺度的分析定义。但现在需要追寻我们在做什么,这些定义是指大小的尺度还是分辨率的尺度?最有趣的是,它们是大小的尺度的定义,因此非常有用。分辨率尺度是由空间单位的选择定义的,而不是由我们定义的半径。因此,这些半径为比较不同空间尺度下个体空间单元的作用和功能提供了重要的可能性!
正如前面所述,这种不同尺度的角色和功能比较对于正确理解城市如何运作是绝对重要的。例如,在一个尺度上被检测为相对均匀的区域可能另一个尺度上被证明是异质的。此外,对重叠尺度的研究是同样重要的,即地区同时在不同尺度上运转会得到加强或削弱,这证明对我们理解城市现象和进程至关重要。此外,对重叠尺度的研究,即在不同尺度上同时表现的地方,从而被加强或削弱,对我们理解城市现象和过程是至关重要的。关于尺度之间的这种关键的相互作用,例如,雅各布斯对规划者建立自治社区的能力提出批判的立场,因为他们顽固地关注邻里尺度,而忽视了从其与整个城市尺度的关联的角度来正确理解街区的运作。正如在其他地方所详细讨论的,雅各布斯可能是第一个提出需要建立一致的城市系统观点的人,比较著名的是她回答了自己提出的问题:“城市问题为何?:恰是组织复杂性的 问题。”[3]
总之,在大多数情况下,对城市现象进行合理的空间分析,需要采用涵盖微观、中观和宏观等多尺度研究方法,以便获得全面的观点,特别是需要在尺度之间移动寻找相互关系和强化弱化手段。更具体地说,如果我们接受城市经济学中关于多样性致使区域城市增长的假设,那么当我们谈论城市的多样性时,我们特指什么尺度就至关重要了。这种增长极有可能是由于尺度之间的相互作用造成的,而非任何其他因素。[9-10]不仅如此,这对城市规划、设计的政策和具体干预非常重要。例如,城市设计通常被认为主要关注地方尺度,但通过更好地了解尺度之间的相互作用,城市设计或许被证明可以间接地影响其他尺度。相反,为了在地方尺度实现目标,可能有必要介入其他尺度。由此,涉及邻里、地区和城市尺度的层次分析至关重要。
为了解决上述问题,我们在几个尺度上测量变量,而且重要的是,我们通过出行网络的可达性来测量变量,例如,通过地块或经济活动的可达性 ,这与空间句法早期发展为地方语法分析的路径相一致。为了解决自变量的局部尺度问题,我们选择测量 500m 半径内地块的可达性1,这通常被认为是步行意愿的近似距离。为了解决中观到一定尺度甚至宏观尺度的问题,我们还在1,000m 和2,500m 的半径处增加了测量值。2对于因变量的局部尺度问题,可通过两种不同的分类来解决,第一种分类旨在广泛捕捉城市尺度的经济活动多样性,第二种分类旨在捕获地区级更具体的经济活动(零售)多样性。
3 多样性与分类法:分类法是何意
任何类型的空间分析基础都是对一个令人满意的分类系统的发展或选择。像大多数实证研究一样,空间分析研究呈现丰富的个体集合,需要以某种方式进行分类,以便进行充分的研究。威尔逊在上文中称之为可划分实体。这样的分类取决于研究的目的,根据这些目的,相同的个体可以被归类到完全不同的类别中。因此,开发一个充分的分类系统需要很高的精度。同时,这被证明为空间分析中最困难的任务之一。一般而言,分类被认为是“我们向来自现实世界的大量信息流施加某种秩序和连贯性的基本过程”,并且它“被视为一种建构现实以检验假设的手段”。这意味着无法独立于研究目的来评估分类系统的充分性。为了使理论和分类之间具有适当的相互关系,一个主要问题或预设假设的重要性经常被提起。在这一方面,正如威尔逊所强调的,我们应该意识到,“没有绝对正确的分类方法”[1]。
在我们的案例中,出于分析和衡量城市空间多样性的目的,需要进行明确的分类。其中类别的选择、数量和属性背后的原理,都将对最终的多样性产生至关重要的影响。例如,当我们衡量一个区域的多样性时,如果考虑其主要职能,如将其分为居住与工作人口,与考虑其经济因素,如办公、商业及工业因素相比,同一区域的多样性结果将大不相同。将分类的层次结构向下移动,衡量商业领域,确切地说是零售领域的多样性时,可以根据所提供商品的类型(例如衣服、鞋子和家具)对其进行分类与排序,这也将产生不同的值。这意味着一个区域可以同时具有较高的多样性和较低的多样性,这都取决于所使用的分类方式。
本文将采用基于OpenStreetMap 和从OSM编码系统提取的两种多样性分类方法。之所以使用OpenStreetMap,是因为可以比较一个国家或多个国家的城市之间的差异。当前我们的研究重点集中于分析一个城市:斯德哥尔摩,但作为更广泛的研究项目的一部分,研究可能将扩展到其他城市。OSM 的类别基于点数据,包括零售与服务、银行、酒店、卫生、教育机构、公共设施、文化与体育设施等类别。另外对零售方面提出了更精细的分类,包括食品店、百货商店、服装店、保健美容店、家居用品店、家具店、电子产品商店、体育用品店、文具店以及书店。基于这些数据,我们提出引入一种多样性:城市层面的多样性(之后可称为总体多样性),以及地区或街道层面的零售多样性。之所以选择零售业作为衡量本地规模多样性的指标,是因为人们普遍认为零售业可以反映城市中与步行相关的经济活动的强度。这两种多样性指数均使用城市研究中常用的辛普森多样性指数计算的,可以很容易地转化为可达性 评价。
4 研究方法
总体来讲,方法步骤包括:(1)测定多样性的因变量;(2)衡量差异性的自变量;(3)通过控制变量(街道中心性与建筑密度)来构建子模型;(4)将数据中的自变量与因变量连接至一个模型;(5)最后,差异性的自变量与多样性的因变量之间的协方差的统计分析。
第一步:测定多样性的因变量。多样性的因变量使用辛普森多样性指数进行测定,该指数可以被转换为可达性评价。辛普森多样性指数是衡量城市活动多样性的公认指标,目前的问题是应该将哪些类别包括在内。如前所述,基于OSM 数据,我们提出使用两种多样性分类,分别针对两种城市规模:总体多样性和零售多样性。总体多样性(下文表示为Dgeneral)包括各种基本的城市服务(不包括办公),它们在整个城市中分布得更均匀,而零售多样性(下文表示为Dretail)通常与步行相关的经济活动的强度相关。
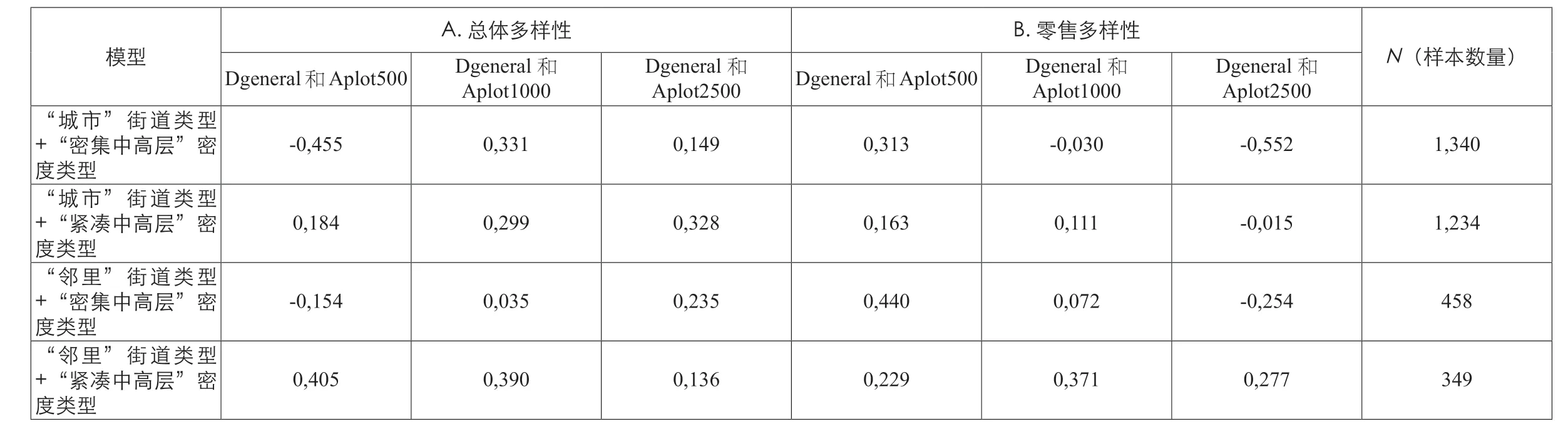
表1 / Table 1皮尔森相关系数的概要统计。对于每个子模型,更高的相关性系数会被加粗。 / Summary of Pearson's correlations. Higher correlations per sub-model are marked in bold来源: 作者提供 / Source: Provided by the author
两个多样性指数(Dgeneral and Dretail)用于计算并衡量为500m 半径内的可达性。首先,计算每个单独类别的可达性,其次计算所有类别的可达性,然后将所得的值计算辛普森多样性指数(D=Σ(n/N)2)3,其中n 是每个类别中活动的量,N是所有活动的总数。
第二步:衡量差异性的自变量。差异性变量可以用更简明的术语描述为地块大小,或者在可达性相关的术语中描述为地块的可达数量,因为当地块较小时,它们通常会很多。因此,根据上述讨论,差异性变量将按照每个地址点的地块可达性绝对数量进行度量,根据几个尺度或半径分为:500m、1,000m 以及2,500m 的步行距离,在下文中将被表示为地块的可达数量或可达性(Aplot500, Aplot1000 and Aplot2500)。
第三步:通过控制变量(街道中心性与建筑密度)来构建子模型。为了评估差异性变量与两种不同的多样性之间的关系,必须要控制另外两种空间形态的变量(街道中心性与建筑密度)。早期研究已经分别根据中心性与密度分析生成了街道与建筑,它们可以用于在我们测量变量的地块选择中,使这些变量保持不变。
利用基于质心的聚类方法生成多尺度的中心性的街道类型,以基于街道路段之间的中心性根据不同的尺度4对其进行分类。聚类分析得出了5 种类型的中心性,其中只有两种类型(“城市”和“邻里”)的观察结果纳入了我们的分析之中,因为在其他3 种类型中几乎没有发现经济活动。街道类型“城市”包括在更大尺度之间的中心性增加的街道路段,“邻里”街道路段的之间的中心性在大多数尺度范围内始终较高,但在大多数本地尺度上明显下降。
建筑密度的类型将使用聚类分析法,基于两个输入变量:容积率(Floor Space Index ,FSI) 和 建 筑 密 度(Ground Space Index,GSI),在500m 步行距离内测量。聚类产生了6 种密度类型,其中选择两种类型进行分析,因为与选中的两种街道类型相似,只有其中两种类型与大量的经济活动相关。选中的两种密度类型为:“密集中高层”(城市中心FSI 和GSI 值最高的组合)和“紧凑中高层”(相比之下,其FSI 与GSI 的值略低)。
这些控制变量得出了4 个子模型(两种街道类型x 三种密度类型,见图1),这让我们可以评估总体或零售多样性与不同尺度下地块可达性之间的相互关系(见图1)。
第四步:连接自变量与因变量的数据。斯德哥尔摩的地址点图层将用于连接所有组件(街道、建筑物、地块及活动),并将它们的属性链接到一个模型中。之所以选择使用地址点是因为地块或建筑物通常可以与不同的街道路段相关联。在这里,地块和建筑物与街道相连,人们可以从街道上进入地块和建筑物,它们可以用地址点来表现。
第五步:统计分析。首先,运行二元皮尔森相关系数分析,在三个尺度下的地块可达性与总体多样性和零售多样性均相关。由于自变量的高度共线性,无法计算多元回归模型,只有一个变量的线性回归才能显示出与皮尔森相关系数分析相似的结果。尽管如此,我们仍然在下一步对相关性最高的子模型进行线性回归拟合,以反映残差值。这样,若在地块之外还有其他空间变量未被纳入本次分析之中,且这些变量会影响到特定区域过高或过低的多样性,这些残差值便可用于评估预测值过高或过低的值。
5 统计分析的结果
若对总体多样性与地块的可达性进行相关性分析,在子模型“Södermalm”以及“城市”这种街道类型中(除了子模型“城市+密集中高层”),在更大的半径范围(Aplot2500)内,相关性会更高。 在街道类型“邻里”与密度类型“紧凑中高层”的组合中,若半径范围较小(Aplot500),与地块类型的相关性就会变 小(表1A)。
若对零售多样性与地块可达性进行相关性分析,对于所有子模型(“邻里+紧凑中高层”子模型除外),较小半径范围的地方(Aplot500)通常相关性更高(表1B)。
我们可以在此得出结论:零售业的多样性确实与从本地尺度衡量的地块可达性更有相关性。这突出了城市中以步行为导向的城市中心的位置。同时,我们先前的论点是,总体多样性在整个城市中分布更均匀。这一发现得到了支持,即在更大的半径范围内,总体多样性与地块可达性相关性更高。但是,这里做出的任何结论仍不够成熟,仍有必要进一步地调查——至少要在其他城市进行类似分析。
我们主要的关注点是地块可达性与零售多样性之间的相关性,因为如前所述,零售业集群通常被认为暗示了步行友好型的城市中心的位置。因此,下一步我们将专门研究地块可达性与零售多样性之间具有最高相关性的子模型,并构建线性回归模型。这是为了查看数据中是否存在空间相关性问题,而该问题无法通过模型来得到解释。把残差值落位到地图上,将便于我们观察预测值过高或过低的样本是否在地图上发生了聚集——因为这意味着子模型中还有其他空间变量覆盖掉地块可达性对零售多样性的影响。因此,我们继续进行研究,对子模型“邻里+密集中高层”(R2=0.194,p<0.05)进行线性回归分析,并把残差值落位到地图上(图2)。
残差值地图(图2)通过突出显示预测值过高或过低的残差值的集中程度,来展示数据中是否存在空间自相关问题。预测值过低的值(图2,棕色),表示该区域的观测值(零售多样性)低于地块可达性所预测的值。反过来,预测值过高的值(图2,绿色)表明观测值高于预期。地图上的黄色区域(图2)表示观测值被较为准确地预测出来。高估值或低估值的集聚区域,对于结果的解读很有帮助,因为根据我们的模型,突出显示的这些区域表明,除了地块可达性以外,可能存在其他一些因素(空间因素或其他因素),导致该区域出现了相比于预期更高或更低的零售多样性。
其中一个最值得注意的案例是,尽管通常可以通过地块可达性来很好地预测零售业的多样性,但其中有个令人惊讶的例外是,繁忙的购物街Birger Jarlsgatan(地图上的棕色),其多样性低于预期。因此,我们可以得出结论,这条街上可能还存在其他因素影响着零售多样化。然而,经过仔细观察,我们意识到这是一条高档时装购物街。这再次强调了对尺度和类别关注的必要性。虽然Birger Jarlsgatan 拥有高档时装业集群,其经济活动的总体多样性不太可能沿着它出现,但其周围的五金店并不多,因为大多数商店都在出售时尚服装。但是,如果我们能对多样性进行更细粒度的分析,把仅出售服装的零售店也纳入考虑范围,Birger Jarlsgatan 将可能表现出很高的多样性。讨论尚为时过早,需要进一步研究,但其强调了多样性研究中尺度和分类的核心问题。
6 结 论
本文有两个目的。首先是通过实证研究展现并检验了城市多样性与差异性变量(地块)之间的潜在的联系;其次是讲述衡量多样性方法的复杂性,这涉及尺度与分类之间相互关联问题。为了解决这两个问题,我们提出可以通过引入不同类型的多样性指标来解决尺度问题。在我们的案例中,这种多样性对应的是总体多样性(全局性)和零售多样性(本地性)。另外,我们提出将其与跨越多个空间尺度的差异性变量进行相关性分析。为了控制实验中建筑密度和街道中心性对结果可能产生的影响,我们引入了几个子模型。其中在每个子模型中,这两个额外的空间变量保持不变。
正如皮尔森相关系数所表示的那样,具有较高总体多样性值(能获得各种基本服务)的区域,在更大的半径范围内,与地块可达性确实具有更高的相关性;而具有较高零售多样性值(能获得各种零售服务)的区域,在较小的半径范围内,与地块可达性的相关性更高。这一发现可以进一步被作为起点,在多个城市中进行更广泛的同类研究。
此外,当我们更详细地研究零售多样性的分布时,通过关注其中一个子模型,把线性回归模型得到的残差值落位到地图上之后,我们发现,某些特定区域的零售多样性无法用区域内出现的较多数量的地块来解释。然后我们建议,可能有必要通过引入一种特定类型的零售商业——时尚商店下的业态分类,来引入更精细尺度下多样性的度量方法。
尽管还没有定论,但这些观察结果确实支持了我们的假设,即地块数量(差异性变量)与城市多样性之间存在重要的联系。这是一个重要的发现。它需要得到进一步和更全面的 研究。
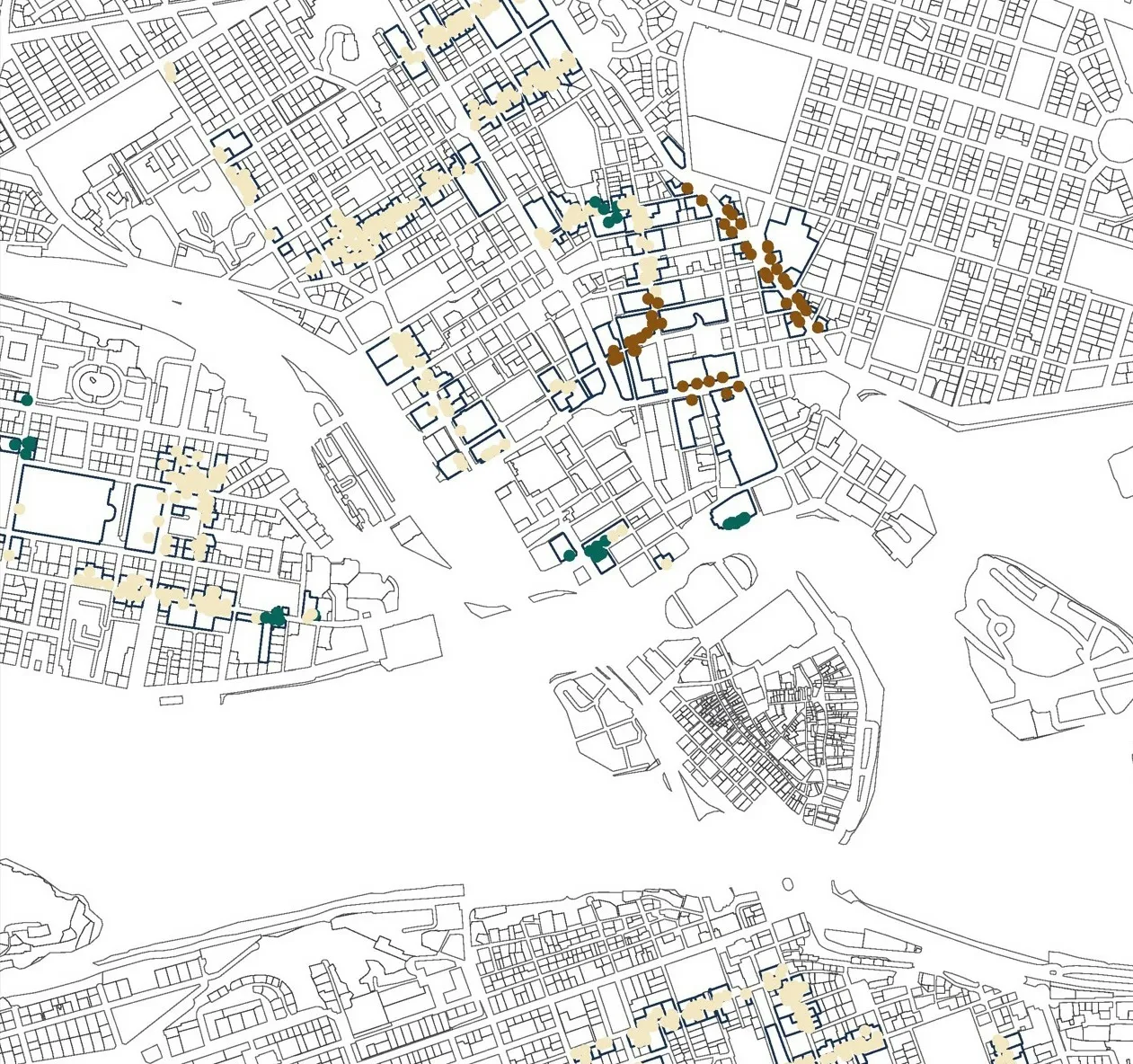
图2 / Figure 2两个子模型的残差值地图:Södermalm和“邻里+紧凑中高层” / Map of residuals for two sub-models: Södermalm and Neighbourhood + Dense mid-rise
ORIGINAL TEXTS IN ENGLISH
Spatial Configuration Of Plot Systems And Urban Diversity:
Empirical support for a differentiation variable in spatial morphology
Lars Marcus, Evgeniya Bobkova
1 Introduction: A Theory of Spatial Capacity
The central variables in any urban model are distance and attraction (Wilson, 2000). Space syntax research has contributed to the development of new geometric descriptions and measures of distance that have broken new ground, not least when it comes to capturing pedestrian movement . However, the description and measurement of attractions has not been central to the field.
In an earlier paper we interpreted attractions as additional variables of spatial form to distance in the form of density and diあerentiation, where the first was related to buildings and the second to plot systems. In this paper we specifically address the far less studied variable of differentiation. Earlier studies have shown strong indications that there is a correlation between the degree of land division into plots (parcels) and the diversity of socio-economic content, such as residents and economic activity. Building on this, we here present results from an extensive empirical study in Stockholm, aiming to pave the way towards a spatial variable of differentiation in spatial morphology, with direct impact on socio-economic diversity. The investigation concerns a correlation analysis between, on the one hand, measures of plot systems configuration, and on the other hand, diversity models of economic activity.
The origin of much debate on diversity in cities is of course the writings of Jane Jacobs, for whom diversity was the central theme throughout all of her texts on cities. Most famously it is spelled out in ‘the Death and Life of Great American Cities’ and the four conditions for generating diversity in cities that she famously proposed in that book: more than one primary function; short blocks; buildings of varying age; and dense concentration of people (Jacobs, 1961). Of these, as we shall see, we will actually find the condition buildings of varying age to be, perhaps a bit surprisingly, the most promising from our current perspective of the need to develop a measure of diあerentiation for our model. The reason is that while the condition more than one primary function certainly has a strong influence on the degree of diversity in cities, it rather deals with pure programming of diversity than having any obvious connection to spatial form of the kind that we are looking for here. The notion of short blocks, on the other hand, rather deals with accessibility, or quite exactly the configuration of cognitive distances dealt with in space syntax theory as discussed above. Finally, the notion of dense concentration of people clearly concerns the idea of density in general and as such has already been thoroughly discussed (Berghauser Pont & Marcus 2014). The notion of buildings of varying age, on the other hand, seems principally diあerent from the others and at first sight presents itself, perhaps, as the one of both least theoretical interesting and least practically applicable - how do we plan cities with buildings of varying age or, for that matter, build a theory around such a thing. However, that is exactly what we shall attempt.
The trap here is to cling to the idea of buildings as things rather than as processes. A shift to the latter implies a shift from the spaces that buildings create to the spaces in which buildings evolve, that is, the different domains defined property rights that we call plots. These are spaces that are institutionally defined rather than physically defined, but even so they undoubtedly represent a central and common category of spaces in cities. If we start to think about it we realise how fundamental such division of space into several separate spaces is in any architectural endeavour - what is architecture if not the art of dividing space by walls - where the primary rationale behind this exactly is the aim to generate diversity, that is, generate discrete spaces for separate and diあerent categories of ‘things’ or activities; this clearly is the major rationale behind the division of buildings into separate rooms for instance.
It therefore seems well founded to see the horizontal division of land, whether defined physically or institutionally, as a fundamental spatial technique whereby one can support an increase in diあerentiation in a similar manner to how the vertical addition of floor-space is a fundamental technique in increasing density. If we more specifically introduce this concept to a model of urban spatial form, we can make the following argument. The particular domain of the plot, as a piece of land defined by a specific set of property rights, represents the presence in the city of an actor in the form of its owner or proprietor or the like, which, furthermore, entails a very precise location of the activities of that actor in urban space (Marcus 2010; Bobkova et al., 2017). It is within this particular domain the specific actor is free to act, as long as keeping within the framework set by diあerent institutions, for instance, the local planning regulations or the particular property rights of the concerned piece of land.
Such actors, furthermore, will normally develop a particular strategy for the further development and maintenance of their property. An area with comparatively many plots therefore seems to have the potential to carry more such actors and thereby more strategies for the development and maintenance of its plots than an area with comparatively few plots, and this, most likely, will also imply a greater diversity of such strategies. In the end, such an area seems to have the potential to more easily develop a diverse content than the area with comparatively few plots and hence few actors and strategies. Consequently, it seems to be exactly this division of land and the subsequent creation of potential diversity in actors and strategies that over time can generate a greater variety in the building stock, that is, Jacobs’ notion of buildings of varying age.
It is this hypothesis that makes us believe that we in the number, shape, size and configuration of plots can identify a variable of spatial form with a direct relation and influence on urban diversity. Moreover, we propose that the number of plots in an area can be called the spatial capacity of that area, that is, the capacity to carry diあerences, where a high capacity creates a greater potential for a heterogeneous content, while a low capacity does the same for a more homogenous content (Marcus, 2000; 2003; 2010; Bobkova et al. 2017ab). Obviously other factors like landuse regulations or other spatial variables, such as street centrality and building density, certainly can override the eあect of the spatial form of plot systems here, but what we are trying to isolate in our study is the particular influence of this variable on urban entities or processes.
In the following we will present an empirical study that relates different kinds of diversity as dependent variables to the independent variable of diあerentiation measured as accessibility to plots. The outline of the paper is as follows. In the next two sections, theoretical complications behind measuring socio-economic diversity will be presented, with particular focus on the issues of scale and categorization. These sections will provide the support for the choices made for the empirical tests presented next. Thereafter, we will present a methodological overview of the empirical study, including: (1) how to measure the dependent variable of socio-economic diversity, (2) how to measure the independent variable of spatial diあerentiation, (3) how to address the issue of scale, (4) how to construct the statistical models that allow for isolation of the diあerentiation variable, and (4), the description of statistical tests. Thereafter the results from the study will be reported and, in the conclusion finally, the results will be discussed in relation to the theories earlier introduced with suggestions for future research.
2 Diversity and Scale: What We Mean By Scale
The term scale is used in many fields and is often interpreted quite diあerently in one discipline from another. There are also many related concepts like level, resolution, extent, and hierarchy, often used as replacements or synonyms. In studies on cities, not least, there is a wide range of references to scale, which also have given rise to a variety of categorisations, such as "local-global", "micromeso-macro", "neighbourhood-district-city-region". However, these terms are by rule vague due to their intrinsic relative nature. They typically are defined in relation to each other for a particular case and what is understood as, for instance, "local" varies from city to city. Together this makes scale one of the most easily confused concepts in the study of cities. This is problematic since choice of scale fundamentally influences both analysis and interpretation in any study of urban modelling or spatial analysis.
According to Mike Batty, we by scale basically mean two things: “the level of resolution at which we observe the city, which is essentially map scale, and the level of functional differentiation that takes place in different sizes of location or city” (Batty, 2005). That is, scale can concern resolution or size but these two are easily confused. All the categorisations listed above, for example, such as the highly relative macro-meso-micro set, typically refer to resolution but can easily be taken for categories of size, not least when applied in concrete urban settings. For instance, when speaking about "neighbourhood", as a particular scale in relation to "district" or "city" scale, we speak about a particular resolution of cities, that is, we zoom in on an area so that we can identify more detail about what is going on there, but this does of course not make the city where we do this smaller or larger. Still, it is an operation where it is easy to begin thinking about the particular neighbourhood as a small city, that is, that we have changed size of the city, but this is obviously not the case.
The immediate risk here of slipping into some overarching, grander or more abstract city that easily takes on life of its own, is encouraged by the fact that we often speak of scales as hierarchies. In Alan Wilson’s words: “Scale is a form of hierarchy and clarity of vision in this respect is critical” (Wilson 2000). A typical case is the categorisation of urban phenomena into micro, meso and macro scale, which conceptually imply, even though we know that it is not true, that there is a series of cities, so to speak, on top of each other. Once again, upon reflection we instantly realise that this is nonsense, but even so, conceptually the slip has already been made and it is diきcult to keep in mind that we do not really mean what we say. For instance, when the introducers of the new spatial economy talk about centrifugal and centripetal forces on the concentration of economic activity in cities (Fujita et al., 1999), we are enticed to envision these as some kind of macro scale forces hovering over cities. In reality, these are forces that analytically are identified on an aggregated macro scale, but that is certainly not where they are acted out. On the contrary, such forces, while leaving distinct traces on aggregated level, are by necessity rooted in human everyday activity on the micro scale.
Moreover, we also need to keep our vision clear concerning what entity it is that we discuss the scale of. Following Wilson (2000), we can say that spatial analysts face the question of resolution in three ways: “entities that are components of systems of interest have to be defined and categorised; many of them have to be located in space; and their behaviour has to be described over time”. This leads to three aspects of scale necessary to decide on: “sectorial (number and breadth of categories), spatial (size of area units within which entities are to be located) and temporal (length of time units which provide the basis for longitudinal description and analysis)”. Temporal resolution constitutes a big issue in itself in that most spatial analyses simply leave out the time dimension, giving rise to the typically static descriptions of cities that we have grown accustomed to. In principle, these are highly unrealistic and for most uses risky to draw conclusions on, however, that is exactly what we do in most studies of cities. The sectorial and spatial aspects, on the other hand, are in most studies there. However, it is important to keep track of how both size and resolution can vary in both, once again, creating many reasons for confusion. Sectorial entities, that is, phenomena or activities that we want to locate and analyse in space, for instance businesses, can vary in size, that is, we can have large businesses and small businesses, which does not imply variations in resolution. However, we can certainly also have variations in resolution of sectorial data, for instance, in how we categorise size in businesses. We can do that with high resolution using, for instance, absolute number of employees, or with a lower resolution where we, for instance, group the number of employees into bundles.
If we want to discuss spatial size, on the other hand, we need another way of entry. First of all, we need to be absolutely clear about what it is that we want to analyse the size of and, second, from what point of view we define size. For instance, if we want to compare the size of one neighbourhood to another, in principle comparing one spatial unit to another, we can of course do this simply by comparing the size of the individual units, for example by measuring their area. Such comparison, however, is in most cases likely to be rather uninformative and quite arbitrary. More interesting, it seems, is to measure size in some systemic way, not least given the predominance of systems views of cities in contemporary research. This would concern to somehow measure the size of impact or importance of the individual spatial unit on the system as a whole, for instance, the role of the individual neighbourhood on the whole district or city. It could, for example, concern the relative distance from the individual spatial unit to all other spatial units, where a short such distance could be argued to represent a strategic location and be interpreted as one way of measuring the individual unit’s systemic size. Moreover, such analysis could be conducted within diあerent distance radii of the individual spatial unit, for instance set by metric distance. Such radii could, in turn, be used as definitions of analysis at diあerent scales, but now we really need to keep track of what we are doing. Are these definitions of scale of size or scale of resolution? Most interestingly, they are definitions of scale of size and therefore extremely useful. The scale of resolution is defined by the choice of spatial unit, not by radii as we have defined it. These radii, therefore, open for the valuable possibility to compare the individual spatial units’ role and function at diあerent scales of size!
As already touched upon, such comparison of role and function at different scales of size is absolutely central for a proper understanding of how cities work. For instance, an area detected as relatively homogeneous at one scale may prove to be quite heterogeneous at another. Moreover, it is not least enquiries of overlapping scales, that is, where localities simultaneously perform on different scales and thereby are reinforced or weakened, that prove critical for our understanding of urban phenomena and processes. Concerning this critical interplay between scales, Jacobs, for instance, took a critical position to planners’ ability to establish self-governing neighbourhoods, given their stubborn focus on the neighbourhood scale and negligence in putting it in relation to the over-all city scale for a proper understanding of the functioning of neighbourhoods. As discussed thoroughly elsewhere, Jacobs was probably the first to argue the need of a consistent systems view of cities, famously answering her own question: What kind of a problem is a city?: “Cities happen to be problems in organized complexity” (Jacobs, 1961).
To summarise, proper spatial analyses of urban phenomena in most cases necessitate having a multi-scale approach that covers, for instance, micro-, meso- and macro-studies, in order to get the full perspective and especially there is a need to move between scales looking for interrelations and reinforcements or lack thereof. More specifically, if we accept the presumption in urban economics that diversity leads to regional urban growth (Glaeser et al., 1992; 2001), the issue of what scale we are referring to when we speak of diversity in the city is critical. Most likely such growth is due to interaction between scales more than anything. Not least, this is important for policy and concrete interventions in urban planning and design. For instance, urban design is normally understood to concern primarily the local scale but through better knowledge about the interaction between scales urban design can perhaps be proven to indirectly influence also other scales. Conversely, to achieve aims on the local scale, interventions on other scales might be necessary. In this regard, hierarchical analysis covering neighbourhood, district and city scale, suggests itself as critical.
To address the issues described above we measure our variables at several scales, and importantly, we measure them as accessibility through the movement network, for instance, as accessibility to plots or economic activity , in line with earlier developments of space syntax analysis into place syntax analysis. To address the local scale of the independent variable, we choose to measure accessibility to plots within a 500m radius, which is commonly recognized as an approximate distance for the willingness to walk (Gehl, 2010). To address the meso and, to a certain extent, the global scale, we also add measures at a radius of 1,000m and 2,500m. For the dependent variable, scale is addressed by applying two diあerent categorisations, where the first is aimed to broadly capture diversity in economic activity at the urban scale, and the second to capture more specific diversity in economic activity (retail) on the district level. The problem of categorisation in diversity is discussed in the next section.
3 Diversity And Categorisation: What We Mean By Categorisation
Fundamental for any type of spatial analysis is the development or choice of a satisfying system of classification (Harvey 1969; Wilson, 2000). As in most empirical studies, spatial analysis studies present a rich set of individualities that needs to be sorted one way or another to be accessible for adequate study, what was called sectorial entities by Wilson above. Such a classification depends on the aims of the enquiry, where the very same individuals can be sorted very diあerently depending on these aims. Hence, the development of an adequate classification system requires great precision. At the same time, this has proven to be one of the most diきcult tasks in spatial analysis. Generally speaking, classification is regarded as “the basic procedure by which we impose some sort of order and coherence upon the vast inflow of information from the real world”, and [It is] “regarded as a means for structuring reality to test hypothesis” (Harvey, 1969). This implies that the adequacy of a classification system cannot be evaluated independently of the purpose of the study. The importance of a primary question or a presupposed hypothesis is often stated, in order to have a proper interrelationship between theory and classification (Harvey, 1969). In extension of this, as emphasised by Wilson, one should be aware that: “there is no absolutely right way to do categorization” (Wilson, 2000).
In our particular case, the need of a clear classification arises from the aim of analysing and measuring diversity in urban space. The principles behind the choice of classes, the number of classes, as well as their attributes, will all have crucial eあects on the final diversity values. For example, if we measure the diversity in an area concerning primary functions, for instance, divided into residential and working populations, this will be very different from the same areas diversity concerning economic sectors, such as oきcial, commercial and industrial sectors. Moving down the hierarchy, measuring the diversity in, for example, the commercial sector, and more specifically retailing, which, for instance, can be classified and sorted based on the type of goods oあered, such as clothes, shoes and furniture, this will yield diあerent values yet. This means that an area can have a high diversity and a low diversity at the same time, all depending on the classification used.
In this paper we will use two types of diversity classification that is based on OpenStreetMap and extracted from OSM coding system. The reason of using OpenStreetMap, is justified by the possibility to compare diあerences between cities within one country or in several countries. Our current study focuses on analysing one city of Stockholm, but has the ambition to be potentially extended to other cities as a part of larger research project. OSM categories are based on point data and include such categories as retail and services, food, banks, hotels, health, education, public facilities, culture and sports. It also proposes more fine-grain categorisation of retail activities, that include food and department stores, clothes, health and beauty, households, furniture, electronics, sport and stationary and books. Based on this data we propose to introduce to kind of diversity: diversity on the city level (further referred to as general diversity), and retail diversity on district or street level. The choice of retail as a measure of local scale diversity, is justified by the fact that it is generally recognized to indicate the intensity of pedestrian-related economic activities in cities (Scoppa & Peponis, 2015; Sevtsuk, 2014; Sevtsuk, 2010; Sevtsuk, 2010; Krafta, 1996). Both diversity indices are calculated using Simpson Diversity Index, that is commonly used in urban studies (Talen, 2008), and can be easily translated into accessibility measure.
4 Methodology
The general methodological steps include measuring the dependent variable of diversity (1), measuring the independent variable of diあerentiation (2), constructing sub-models by controlling variables of street centrality and building density (3), linking data on dependent and independent variables in one model (4), and finally, statistical analysis of co-variation between independent variable of diあerentiation and dependent variable of diversity (5).
Step 1. Measuring general and retail diversity
The dependent variable of diversity is measured using Simpson Diversity Index that is translated into an accessibility measure. Simpson Diversity Index is a generally recognized indicator for measuring diversity of urban activities (Talen, 2008), and our question at hand is what categories should be included. As described earlier, it is proposed to use two categorisations of diversity based on OSM data, that address two urban scales: general diversity and retail diversity. General diversity (referred further as Dgeneral), includes all kinds of basic urban services (excluding offices) that are more evenly distributed across the city, and retail diversity (referred further as Dretail) is usually associated with the intensity of pedestrian-related economic activities in vital city centers (Scoppa & Peponis, 2015; Sevtsuk, 2014; Sevtsuk, 2010; Sevtsuk, 2010; Krafta, 1996).
Two diversity indices (Dgeneral and Dretail) are calculated and measured as accessibility within a 500m radius. First, accessibility to each separate category is calculated, second, accessibility to the total number of categories is calculated, and then the resulting numbers are used to calculate Simpson Diversity Index (D=Σ(n/N)2) , where n is the number of activities within each category, and N is the total number of all activities.
Step 2. Measuring independent variable of diあerentiation
The differentiation variable can in more simple terms be described as plot size, or, in accessibility terms, as the accessible number of plots, because if plots are smaller, they typically are many (Bobkova, 2017a). Hence, the diあerentiation variable is measured as the absolute number of plots accessible from every single address point, across several scales or radii, according to the discussion above: 500m, 1000m and 2500m walking distance, and is further referred to as the accessible number of plots or accessibility to plots (Aplot500, Aplot1000 and Aplot2500).
Step 3. Constructing sub-models by controlling for street centrality and building density
To evaluate how the variable of diあerentiation is related to the two diあerent kinds of diversity, two other variables of spatial form (street centrality and building density) have to be controlled for. Typologies of both streets according to centrality and buildings according to density has been analytically generated in earlier research that here is used in our selection of locations from which our variables are measured (Berghauser Pont et al., in review) so that these variables remain constant.
Multi-scalar centrality street types were generated using centroid-based clustering to classify street segments based on their individual betweenness centrality profile through different scales (Berghauser Pont, et al., in review). The cluster analysis resulted in five centrality types, where only observations from two of these ("City"and "Neighbourhood") have been included in our analysis, because in the other three types economic activity was hardly found at all. The street type "City" includes street segments of increasing betweenness centrality at higher scales and "Neighbourhood" has segments with consistently high betweenness across most scales, but dropping clearly at the most local scales (ibid.).
Building density types were developed using cluster analysis (Berghauser Pont et al., 2017), based on two input variables: Floor Space Index (FSI) and Ground Space Index (GSI) (Berghauser Pont & Haupt, 2010), measured within 500m walking distance. The clustering generated six density types, of which two types were selected for our analysis, because, similarly to the two selected street types, only these were associated with a substantial number of economic activities. The two selected density types were "Dense midrise" (the highest combination of FSI and GSI characteristic for city centres) and "Compact mid-rise" (slightly lower FSI and GSI values compared to "Dense mid-rise").
Including these control variables gives us 4 sub-models (two street types x three density types, see figure 1), that allows us to evaluate co-relation between general or retail diversity and accessibility to plots at diあerent scales (figure 1).
Step 4. Linking data on dependent and independent variable
A layer of address points for Stockholm is used to join all the components (streets, buildings, plots and activities), and link their properties in one model. The choice of using the address points is justified by the fact that a plot or a building typically can be associated with diあerent street segments. Here, plots and buildings are linked to the streets from where one can enter it, which is represented by the address point (Berghauser Pont et al., in review).
Step 5. Statistical analysis
First, bivariate Pearson’s correlations are run, where accessibility to plots at three scales is correlated both with general and retail diversity. Because our independent variables are highly collinear, multiple regression models are not run, since linear regression for only one variable only would show the similar results as the Pearson’s correlation results. Nevertheless, we still run linear regressions for the sub-models with the highest correlation on the next step, in order to map residual values. They allow to evaluate underpredicted or overpredicted values, if there is any other spatial variable besides plots not included in our analysis, that influences higher or lower diversity in particular area.
5 Results Of Statistical Analysis
When general diversity is correlated with accessibility to plots, correlation generally gets higher at higher radii (Aplot2500) in sub-model "Södermalm" as well as in street type "City", except the sub-model "City + Density type Dense Mid-rise". In Street type "Neighbourhood" combined with Density type "compact mid-rise", the correlation with plot types gets lower at the lower radii (table 1A).
When retail diversity is correlated with accessibility to plots, correlation generally gets higher at lower radii (Aplot500), for all sub-models except "Neighbourhood + Compact Mid-rise" (table 1B).
We may conclude here, that retail diversity indeed corresponds better to accessibility to plots measured locally, and highlights the location of pedestrian-oriented urban centres found in the city. At the same time, our earlier argument that general diversity is more evenly distributed across the city, is supported by the finding that it is correlated better with accessibility to plots at larger radii. However, any conclusions here are still premature. There is need for further investigation, not least through similar analysis in other cities.
Our key interest is the correlation between the accessibility to plots and retail diversity, because, as mentioned before, retail clusters are often recognised as indicating the location of pedestrian-friendly urban centres. Hence, in the next step we look specifically at the sub-models with the highest correlation between accessibility to plots and retail diversity and then run linear regression models. This is done in order to see if there is a problem with spatial correlation in the data, which cannot be explained by the model. Mapping residual values then allows to see if there are concentrations of observed values on the map that are over-predicted or under-predicted, which would mean that there are other spatial variables in our sub-model that override our explanation of retail diversity through accessibility to plots. Hence, we proceed and run linear regression analysis for the sub-model ‘Neighbourhood + Dense Mid-rise’ (R2=0,194, p<0,05) and mapping residual values (figure 2).
The map of residual values (figure 2), shows whether there are any problems of spatial auto-correlation in the data by highlighting the concentrations of under- or over-predicted residual values. Underpredicted values (figure 2, brown), mean that the observed value (retail diversity) in the area is lower than predicted by the accessibility to plots. In turn, overpredicted values (figure 2, green) show that observed values are higher than expected. Yellow areas on the maps (figure 2) show that observed values are relatively well predicted. Clustered areas of over- or underpredicted values are useful for the interpretation of the results, because they highlight the areas where it might be that some other conditions, spatial or other, besides accessibility to plots contribute to higher or lower retail diversity in the area than expected according to our model.
A case of principal interest is that even though retail diversity is generally well predicted by accessibility to plots, a surprising exception is the busy shopping street Birger Jarlsgatan (brown on the map), where diversity is found to be lower than expected. We may therefore conclude that there may be some other condition influencing retail diversity along this street. On closer scrutiny however, we realise that this is a street for high fashion retail, which again highlights the necessary concern for scale and categorisation. While general diversity of economic activity is unlikely along Birger Jarlsgatan with its high fashion cluster, neither is it very diverse in retail, there are not many hard ware stores around, since most shops carry fashion clothes. However, if we would make an even more fine-grained analysis of diversity, concerning only retail that carry clothes, Birger Jarlsgatan is likely to demonstrate a very high diversity. This discussion is yet premature and calls for further studies, but it draws attention to the central issue of scale and categorisation in studies of diversity.
6 Conclusion
The aim of this paper was twofold, first, to present and test empirically potential link between urban diversity and the variable of diあerentiation (plots) and second, to present the whole complexity of measuring diversity, that is related to the interconnected issues of scale and categorisation. In order to deal with these two problems, we proposed that scalar issue can be tackled by introducing diあerent kinds of diversity, in our case general (global) and retail diversity (local). In addition, we proposed to correlate it with the variable of differentiation across several spatial scales. In order to control our tests for possible influence of building density and street centrality on the results, we introduced several sub-models, where within each sub-model, these two other spatial variables remain constant.
As it was shown by Pearson’s correlations, areas that have higher general diversity values (access to variety of basic services) are indeed better correlated with accessibility to plots at higher radii, while areas that have higher retail diversity values (access to variety of retail services) correlate better with accessibility to plots on lower radii. This finding can further serve as a starting point, to conduct a more extensive study of similar kind, but across several cities.
In addition, when we investigated distribution of retail diversity in more detail, by focusing on one of the sub-models and mapping residual values from linear regression, it was found, that retail diversity of some particular areas cannot be explained by the higher number of plots present in the area. We suggested then, that there is possibly a necessity to introduce diversity measure at even finer scale, by introducing categorisation within one particular kind of retail: fashion stores.
While still far from conclusive, these observations do support our hypothesis that there is an important connection between the number of plots (differentiation variable) and urban diversity; an important finding that calls for further and more comprehensive investigation.
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:25:56
小学生学习指导(高年级)(2021年4期)2021-04-29 02:17:10
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06 09:08:52
河北理科教学研究(2020年2期)2020-09-11 06:15:48
中学生数理化·七年级数学人教版(2019年4期)2019-05-20 10:06:32
中学生数理化·七年级数学人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年级(2017年9期)2017-10-13 22:27:46
太空探索(2016年5期)2016-07-12 15:17:55
数学年刊A辑(中文版)(2015年2期)2015-10-30 01:56:14
新高考·高二数学(2014年7期)2014-09-18 00:42:02
