
融合多语言特点的无载体信息隐藏
2019-04-09 09:10:58彭博,李晖
微处理机 2019年1期
彭 博,李 晖
(沈阳工业大学信息科学与工程学院, 沈阳110870)
1 引 言
信息隐藏(Information hiding, 或称隐写,Steganography),是指将机密信息伪装为不引人注意的普通信息,从而达到隐蔽传输或隐蔽存储的目的。其技术对国家安全与信息安全的重要意义不言而喻[1]。与图片、音视频等多媒体信息相比,文本信息具有占用空间小、传输方便、生活中应用更广泛等优点[2],因此,对文本信息隐藏的研究具有广阔的发展前景和研究价值。目前对文本信息隐藏的研究主要分为两大类:第一类是基于文本格式的信息隐藏,第二类是基于文本语法语义的信息隐藏。
基于文本格式的信息隐藏主要利用文本的特定格式,将秘密信息嵌入其中,比如利用文本段落的行间距变化[3],文本颜色或字体大小的细微调整[4]等。这类方法的特点是鲁棒性较差,一旦对其进行誊写、影印等攻击,隐藏信息即随之消失。
基于语法语义的信息隐藏则主要利用某一语体的特定语法格式,或者对文本语义进行编码来隐藏信息。比如利用宋词的“韵律-词性”格式进行信息隐藏[5-7],利用同义词或同义句替换进行信息隐藏[8-9]等。这类方法虽大多能抵御普通的基于格式的攻击,却在文本含义表达上略有欠缺,在可读性上表现一般,部分文本语义较为生涩,容易引起攻击者的注意,从而造成秘密信息的泄露。
近几年来,一种新的“无载体信息隐藏”方法得到学者们的认同。“无载体信息隐藏”,并不是不需要隐藏信息的载体,而是与传统信息隐藏方法相比,不再将秘密信息嵌入到载体中(或对载体进行修改),相反,它直接以秘密信息作为驱动,来“生成/获取”含密载体[10],以实现信息隐藏的目的。与传统方法相比,无载体信息隐藏无需对原始载体进行修改及嵌入,有效地提升了信息隐藏的鲁棒性。Zhang J 等[11]、吉红勇等[12]提出构建文本大数据库,利用秘密信息的词级和频率,在大数据库中进行匹配,寻找合适的文本并直接发送。由于该方法无需修改载体,从而减少了被攻击的可能性,但其在嵌入率上仍有待提高。陆海等[13]提出了结合随机码本的无载体试题伪装方法,利用秘密信息生成以试题为形式的伪装,该方法避免了秘密信息的直接传输,减少了被发现的可能性,隐藏容量上也有一定的提高。
故此,提出一种融合多语言特点的无载体信息隐藏方法,首次提出将汉语与英语的特点相结合、利用双语互相翻译转换的方法进行信息隐藏。首先将汉语的秘密信息翻译为英语信息,利用英文字母与汉语拼音的同一性,对翻译后的英文文本进行字母、格式上的处理,最后通过该文本段生成汉语的姓名,并作为秘密信息的载体,从而实现信息隐藏的目的。经该方法处理后的信息具有很好的鲁棒性,不会出现语义生涩等情况,并能在嵌入率上有所提升,具有很强的实用性和广阔的应用前景。
2 研究基础
2.1 算法的基本思想
大多数学者在对文本信息隐藏的研究中只针对某一种语言进行探索,很少有人注意到不同语言之间也存在一定的关系,这就造成了现有方法多针对于某一种语言的局限性。如果在信息隐藏中考虑将多种语言的特点进行融合,那么将会更好地丰富信息隐藏的方法。比如SUHAD M. KADHEM 等人提出了将英文的秘密信息隐藏到阿拉伯文文体之中[14],并取得了良好的隐藏效果。
表1 展示了现今世界各语言使用者的比例。汉语和英语是世界上使用人数最多,使用范围最广的两大语言[15],且两种语言存在一定的相通性,即中文的注音是利用汉语拼音完成的,汉语拼音又与英文的字母构成相同,即由26 个英文字母A-Z 构成。一定程度上,英文可以写成汉语拼音的形式,经过处理后生成新的汉语文本,这就形成了一种全新的文本信息隐藏思路:假设传递的是中文的秘密信息,由于各语言之间具有在互译时句子原意基本保持不变的性质,可以先将其翻译成英文,将得到的英文进行适当处理,再转换成拼音,由拼音所生成新的汉语载体,得到与秘密信息完全不同的文本,从而达到秘密信息隐藏传输的目的。

表1 50年来世界各语言使用者总数的比例
2.2 基于中文姓名载体的信息隐藏
与传统修改载体的信息隐藏方法相比,无载体信息隐藏直接由秘密信息作为驱动生成含密载体,免去了寻找载体、修改载体的繁琐步骤。
目前文本无载体信息隐藏的主流方法是建立海量的文本大数据库[16],将秘密信息进行分解后[17],再与大数据库进行比对,找到合适的文本载体,直接进行传送。这类方法虽能在一定程度上提高算法的安全性,减少被攻击者发现的风险,却带来了两个问题:一是此类算法的嵌入率有待提升,往往一篇文章只能传递一个或几个关键词,对于大段秘密信息的传递效率很低;二是此类算法需要提前构建10GB以上的大数据文本库,才能保证秘密信息段的充分表达,造成存储空间与搜索时间的大量冗余。
为了解决上述问题,使无载体信息隐藏更好地发挥出其特点,本方法采用了完全构造式信息隐藏,即由秘密信息直接生成含密载体,无需构建大数据文本库,进一步节省了资源的开销。为使生成的载体能够完整表达秘密信息,且不引起攻击者的注意,选取汉语的姓名作为最终的含密载体格式。选用汉语人名的更深一层的理由可归纳如下:
1)姓名是每个人独一无二的标志,其具有独特性。中国的百家姓加上不同名字可以有无数种组合,具有极高的灵活性。同时,中国人姓名一般以二字或三字居多,有一定的共性和规律,方便生成合适的含密载体;
2)姓名大多来源于出生时父母的命名,由于父母在为孩子取名时的期望,以及会受当时热门的历史事件或者父母的文化水平等诸多因素的影响,得到的名字也可能千差万别。基于这些原因,即使生成的姓名比较生僻,也很少会引起攻击者的怀疑;
3)在许多场景中,姓名都可以大规模地出现,例如在学校中学生的点名册,出席会议时的参会人员名单,旅游时的旅客名单等等,都可以应用于多种场合,只需要加上一定的修饰,完全不会引起攻击者的怀疑,具有很高的隐蔽性,可以满足保密通信的要求。
3 算法描述
所提出的这一融合多语言特点的无载体信息隐藏方法主要包括3 个环节:1)汉语秘密信息翻译转化成英语信息;2)对英语信息做恰当处理,使其能够正确进行拼音转换;3)构建汉语姓名数据库,由上一步得到的拼音信息自动生成汉语姓名名单,即秘密信息传输的载体。该方法的隐藏过程流程图如图1 所示。

图1 隐藏过程流程图
3.1 汉语到英语的转化
为保证汉语的秘密信息能够自动并快速地被翻译成英语信息。算法使用了百度翻译提供的API接口,免去了人为翻译对时间、资源等的浪费,保障了信息处理的速度及准确性。
3.2 对英文信息的处理转换
对于翻译好的英文信息进行改写处理,以便利用拼音的形式生成载体。利用拼音字母生成汉语姓名时,由于汉语的“a”,“e”,“i”,“o”,“u”,“v”等字母在自动生成时对应的汉字较少,无法满足算法的需求。为解决这一问题,综合考量了英文字母使用频率和拼音输入法中26 个字母的使用频率,同时还借鉴了生物学中RNA 密码子的对应关系,如表2所示,制定了变换规则,对上述字母进行转换,以便更好的生成载体,满足传输要求。
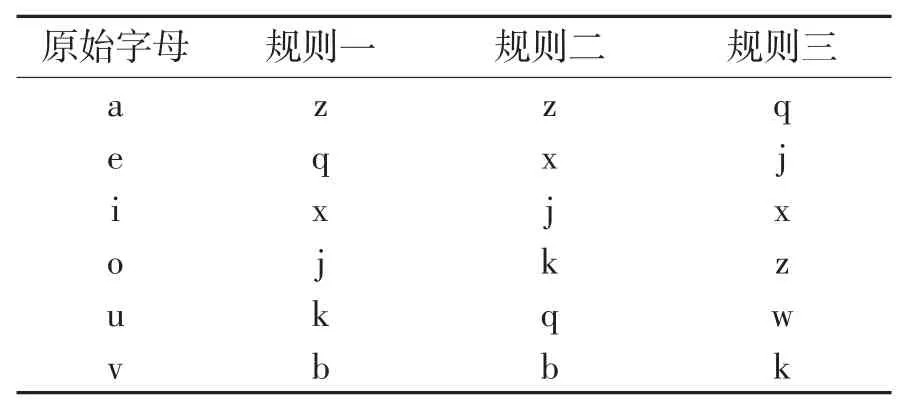
表2 本算法设定的RNA密码子对应规则
利用上述对应规则进行转换后,不但解决了部分字母生成载体困难的问题,也有效地破坏了原英文单词的书写,使其难以被检测识别,进一步增强了系统的安全性。
3.3 构建汉语姓名数据库
中国人的姓名由姓氏和名字两部分组成。为利用拼音快速准确生成姓名载体,分别建立了两个以姓氏和名字为一级索引的数据库;二级索引则为各汉字的拼音首字母。其中,为使算法尽可能简便易行,在姓氏一栏中暂不考虑复姓的情况。表3 展示了姓名数据库的构建方法。
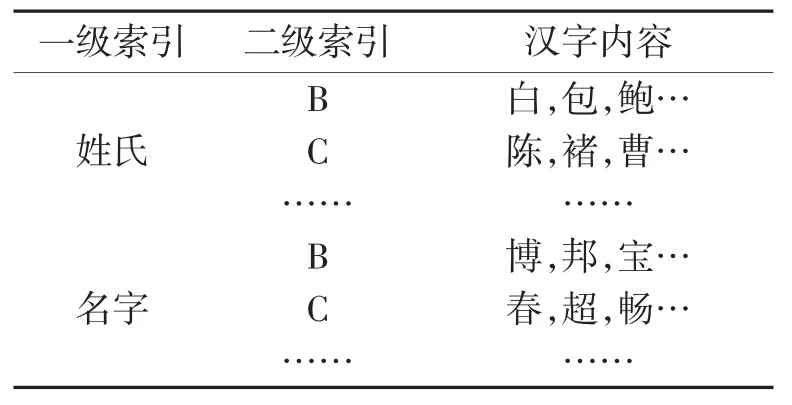
表3 姓名数据库构建方法
3.4 所提方法的完整步骤
3.4.1 信息隐藏过程
本信息隐藏算法分为两部分,即信息隐藏过程和信息提取过程。信息隐藏过程算法的完整步骤详细如下:
Step1:输入秘密信息s;
Step2:根据要发送的秘密信息s,先将其整理为关键词形式或尽量精简;
Step3:将整理好的秘密信息s 通过翻译API 译为英文的秘密信息e;
Step4:将处理后的英文信息e 利用RNA 对应规则进行转换,得到拼音信息k;
Step5:根据拼音信息k 的长度L,生成全部为2 或3的随机数序列,使序列求和等于L,该序列即为生成姓名时的参照序列Q;
Step6:从头至尾遍历拼音信息k,同时访问参照序列Q;
Step7(如果Q 中元素为2):从拼音信息中取两个字母,第一个字母从“姓氏”数据库中提取元素,第二个从“名字”数据库中提取元素;
Step8(如果Q 中元素为3):步骤同7,第一个字母从“姓氏”数据库中提取,其余的从“名字”数据库提取;
Step9:重复步骤6~7,直到遍历所有的拼音信息k;
Step10:生成含密姓名载体c 。
3.4.2 信息提取过程:
提取過程是隐藏过程的逆过程,接收方在接收到姓名名单后,按照以下步骤还原出原始秘密信息:
Step1:接收方接收到载体信息c,利用计算机从姓名名单中提取出汉语拼音的首字母;
Step2:利用双方早先约定的RNA 密码子对应规则,对提取的拼音信息进行逆处理,得到英文消息e';
Step3:补全空格、标点等必要信息,使其成为标准的英文信息e;
Step4:利用翻译API 将英文信息e 翻译回汉语,即得到初始的秘密信息s;
4 实验与分析
4.1 实验例证
实验测试环境为Windows10 操作系统,CPU 为Intel(R) Core(TM) i5-6300HQ,主频为2.3GHz,内存为8GB,编程语言为Python3.5。
由于信息隐藏的应用方向主要在于秘密信息的传递,故实验文本选择了类似地下情报的信息语段,如图2 所示。

图2 传递的秘密信息语段
根据上述的算法步骤,可生成的含密姓名载体,如图3 所示。

图3 生成的姓名载体格式
在信息的提取过程中,根据前文所述的提取步骤,得到原始的秘密信息,如图4 所示。

图4 提取的秘密信息语段
由实验结果得知,经过本信息隐藏算法处理,原始秘密信息转变成了姓名形式的含密载体,且其没有在新的载体中出现;对比提取到的秘密信息与原始信息,提取信息与原始信息略有不同,不过却没有改变原始信息的含义,从实现了信息的隐秘传输。
4.2 性能分析
对于某一种信息隐藏算法,其主要评价方法一般由嵌入效率、鲁棒性以及抗检测性三方面组成。
嵌入效率一般由如下计算公式得出:

其中,H 表示算法嵌入效率,Lc为秘密信息的字节长度,Lr为含密载体的字节长度。
在第4.1 节的实验举例中,该示例的嵌入率为31.4%。在多次随机实验中,其嵌入率波动情况如图5 所示。可知,平均嵌入率为34.2%,嵌入率最高值可达到46%,最低则为23%。

图5 本文算法嵌入率波动图
造成这种波动现象的原因是,在算法第一步翻译过程中,部分汉语词语对应的英文翻译较长,形成部分冗余。对于此种现象,可在通信前由通信双方进行约定,对某些事物进行代号标记,则可保证嵌入率更加稳定上升。对比以往的文本信息隐藏算法,该算法在嵌入率上的提升情况,可见表4 中的具体对比。
由于本方法不属于基于格式的信息隐藏,故其可以抵御任意的誊写、重抄、影印等攻击,甚至可以以语音的方式进行隐秘通信。同时,本方法以中文姓名作为载体,可以抵御语义分析、词频分析等统计学检测手段,具有较好的鲁棒性。

表4 嵌入效率对比图
在抗检测性方面,该方法的优点可归纳如下:首先,由于采用了无载体信息隐藏,没有对载体进行修改,所以不会造成语义的生涩或格式上的异常;其次,在载体上以中文姓名名单作为形式,适用于各种场合的伪装;最后,创新性地提出了中英文结合的信息隐藏方法,这在以往的研究中并未被人提及。此外,攻击者在进行检测分析时会更注意中文的格式和语义等,忽略其注音等情况,也为抗检测性增加了保障。
5 结束语
提出了一种融合多语言特点的无载体文本信息隐藏方法,将多语言之间的关系融合到信息隐藏技术中,摆脱了以往文本信息隐藏只在一种语言中寻求方案的局限性,拓宽了思路。利用计算机进行程序编写及仿真后的实验结果表明,该方法可以有效地进行隐秘通信,抵抗现有的隐写分析手段,并在嵌入率上做到了一定的提升。由于本方法基于中英文的翻译展开,对于较为抽象的中文信息,如唐诗、宋词等,其嵌入率会大打折扣,所以后续的研究重点是针对此类复杂情况改进该方案,使其具有更好的普适性。
猜你喜欢
艺术品鉴(2020年11期)2020-12-28 01:36:56
下一代英才(酷炫少年)(2018年4期)2018-04-28 08:29:31
小溪流(画刊)(2016年11期)2017-01-05 12:26:31
少年博览·小学低年级(2016年10期)2016-11-24 06:38:49
作文与考试·小学低年级版(2015年22期)2015-12-07 01:29:59
小学科学(2015年11期)2015-12-01 22:25:22
小天使·一年级语数英综合(2015年8期)2015-07-06 06:16:26
小天使·一年级语数英综合(2015年3期)2015-04-20 05:57:18
小天使·一年级语数英综合(2015年2期)2015-01-14 06:07:04
小溪流(画刊)(2014年4期)2014-06-28 19:27:00
