
一种平稳时序数据的高效辨识改进算法*
2019-04-09 09:10黄雄波
微处理机 2019年1期
黄雄波
(佛山职业技术学院电子信息学院,佛山528137)
1 引 言
物理系统或工作部件在实际运行过程中,各项性能状态参数可通过安装在某些部位的传感器及专用测试设备加以测量,且系统的工作状况在某种程度上可通过这些状态参数来表征。基于时序数据驱动的系统辨识,就是以采集的过程数据为基础,直接对物理系统的各类可用数据进行分析和处理,以此判断系统在未来可能发生故障的概率,或估计系统失效以至到达寿命阀值的时间节点[1-4]。通常,时序数据在经过相关的函数变换后,总能分解出趋势项、随机项及周期项共三种数据成分,据此,基于时序数据驱动的系统辨识就是对既有序列进行数据成分的分离及建模[5]。
时序数据的随机成分蕴藏了丰富的信息,在系统失效和故障诊断方面有着重要的应用价值。对于线性平稳的随机序列而言,美国学者博克斯与英国学者詹金斯根据序列的自相关函数、偏相关函数或两者是否同时出现拖尾等情形,分别提出了3 种可用的辨识模型:自回归(Auto-regressive, AR)模型、滑动平均(Moving average, MA)模型和自回归滑动平均(Auto-regressive and moving average, ARMA)模型[6]。利用上述辨识模型进行系统建模,就是需要确定辨识模型的阶次和估计辨识模型的参数。由于自回归模型具有模型求解简捷的优点,且其它两种模型亦可用一高阶自回归模型进行逼近,故该模型在实际应用中得到了更为广泛的应用。为了进一步提升现有的自回归模型辨识算法的相关效能,提出一种更为高效的改进算法,并就算法的设计原理及实现过程做更深一层的分析和讨论。
2 问题描述
设平稳时序数据序列为xt(t=1,2,…,n),其p 阶线性自回归模型的数学描述如下式所示:
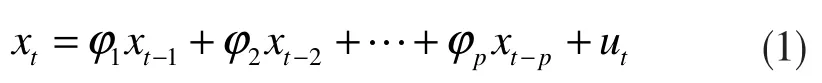
式(1)中,p∈N+,为自回归模型的阶数;φ1,φ2,…,φp为自回归模型的参数;ut是数学期望为0、方差为σ2的随机白噪声干扰,与xt-1,xt-2,…,xt-p不相关。
式(1)中的自回归模型的具体求解过程为:首先基于某一准则确定模型的阶数p,然后对模型参数φ1,φ2,…,φp进行估计[7]。对模型的定阶方法进行归纳,大致可以分为两类[8]:信息量准则法和线性代数法。著名的信息量准则法有平均信息(AIC)准则、最终预测误差(FPE)准则、最小描述长度(MDL)准则、自回归传递(CAT)准则;而典型的线性代数定阶法有行列式检验法、Gram-Schmidt 正交法和奇异值分解法。当确定模型的阶数后,便可用Levinson-Durbin 或Burg 算法对模型参数进行递推估计。
值得注意的是,迄今为止,自回归模型的定阶问题仍然没有得到根本性的解决,不同物理系统往往需要使用不同的定阶准则[9]。例如,段志善等根据辨识精度的需求,从频域角度出发,分低阶和高阶两种辨识情形提出了FFT-AR 谱对照的定阶方法,并在实际的机械故障诊断中得到了较为满意的结果[10];杨帆等针对模型定阶过程中的不确定性,利用冗余定理筛选基于多个回溯阶预测方法的有效信息,设计实现了一种基于遗忘因子的变权组合定阶方法[11];黄雄波等通过对平稳时序数据自相关函数矩阵的秩的下界值进行估计,并以该估计值作为自回归模型的起始阶数对系统进行依次的递阶辨识,得到一种自回归模型的快速辨识算法[12]。
然而,以上方法并没有把定阶过程和估参过程有机地融合在一起,即整个模型的求解过程中仍然遵循着先定阶后估参的次序,这严重制约了算法的计算效能的提升。为解决这一问题,张思宇等通过预留少量数据递补进入求解模型的方式,并结合矩阵递推求逆的方法,提出了一种融合定阶和估参同步进行的自回归模型求解算法[13]。该算法的主要思想与演算步骤如下:
基于最小二乘理论定义如下式所示的辨识残差平方和:
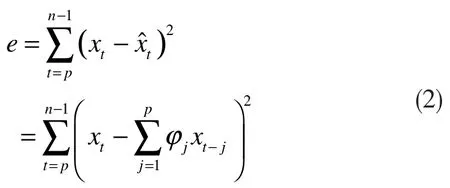
将样本序列排列为{x-v,x-v+1,…,x-1,x0,x1,…,xt},其中子序列{x1,…,xt}称为候补数据序列。对于AR(p)模型而言,选用的数据序列为{x-p+1,…,xp},求式(2)的最小二乘解,有:
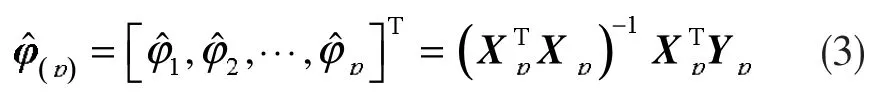
其中:

每次升阶时,即AR(p)→AR(p+1),则可由候补数据序列依次递补一个数据,此时式(3)中的X、Y 矩阵应调整为:
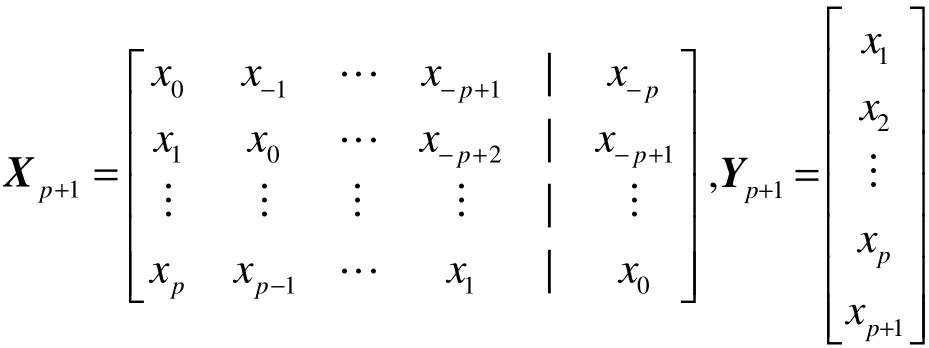
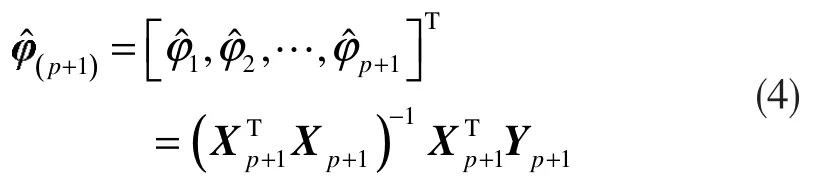
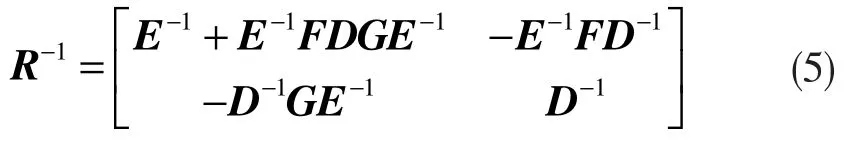
其中,D=H-GE-1F。
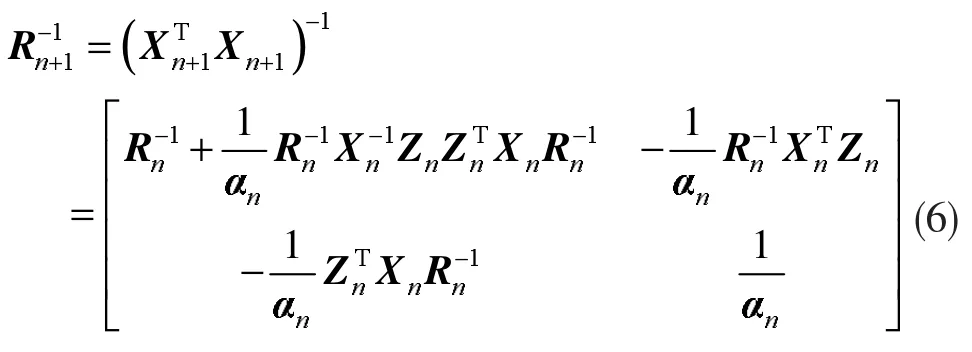
上述算法在自回归模型的求解过程中,以升阶的方式进行定阶,并利用矩阵分块求逆的方式同步进行估参,其优点是获得了较好的计算性能,然而此算法本身也存在两点需要改进的地方:1) 从式(1)可见,式(3)的自回归模型仅考虑了数据样本既有的观测值,而忽视了白噪声随机干扰ut的作用,因此将引起一定的辨识误差,事实上,根据Yule-Walker 方程可知,仅当系数矩阵X 的元素为自相关函数时,式(3)才得以成立;2)以分块矩阵的递推求逆方式进行自回归模型求解,其矩阵求逆过程中所积累的误差也不容忽略,应予以消除。
针对上述问题,拟设计一种更为高效的平稳时序数据的自回归模型辨识改进算法。
3 改进算法
3.1 基于重抽样的随机白噪声干扰估计
如前所述,式(3)在利用候补数据序列进行升阶辨识的过程中,由于忽略了随机白噪声ut的作用而导致了辨识结果的不可靠,对此,引入重抽样方法,从辨识序列xt中估算并消除ut,进而使得式(3)的辨识计算更为精确。
注意到随机白噪声ut为一具有高斯正态分布的完全随机型序列,据此,需要对其数学期望和方差进行估计。对于一个容量为n 且来自未知分布F的数据样本而言,近年来出现了一种名为重抽样(Bootstrap)的实用统计推断方法[14-15],其推断过程如图1 所示。
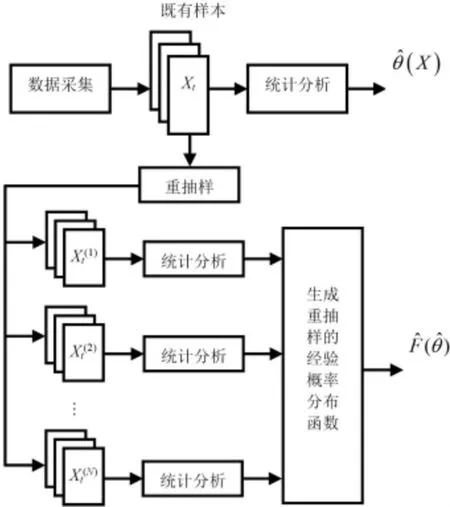
图1 Bootstrap重抽样的统计推断过程
由图中可见,此算法是先从既有数据样本中按放回抽样的方法抽取一个容量为n 的样本,并称这种抽样样本为Bootstrap 样本;之后相继地、独立地自原始样本中抽取一定数量的Bootstrap 样本,并利用这些Bootstrap 样本对总体F 进行统计推断。
根据以上的Bootstrap 重抽样的统计推断分析,估计随机白噪声ut的数学期望和方差的流程应为:
1)用随机数发生器对既有样本进行N 次重抽样,得到N 组新样本;
3) 分别计算总体样本的Bootstrap 数学期望估值和方差估值。
得到了随机白噪声ut的Bootstrap 数学期望估值和Bootstrap 方差估值后,便可依下式所示的概率密度函数生成完全随机型序列:
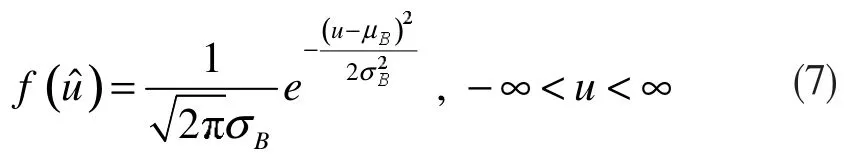
在此基础上,运用下式即可从辨识序列xt中消除随机白噪声ut的作用,得到相依随机型序列:

3.2 融合迭代和递推机制的
自回归模型求解方法
文献[13]用矩阵分块求逆的递推方法对升阶后的自回归模型进行求解,但矩阵求逆过程中所积累的误差不能忽视,故此引入融合迭代和递推机制的求解方法,通过迭代法对模型进行求解,在迭代计算收敛的条件下便可以将计算误差控制在某一特定范围内。

则有[16-17]:
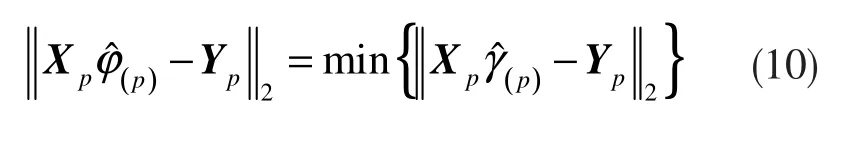
而剩余向量为:
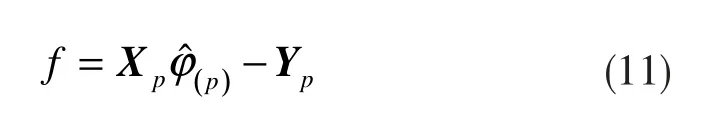
满足:

从候补数据序列递补一个新的数据xp+1,得到第p+1 个方程:
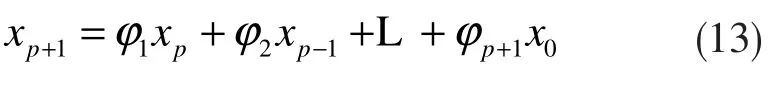
于是,有:
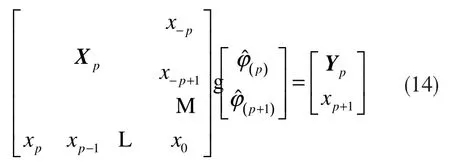
对式(14)的系数矩阵进行如下的分块:
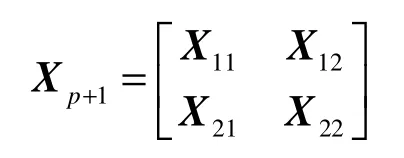
其中,X11∈Rp×p,X12∈Rp×1,X21∈R1×p,X22∈R 。令,Y1, f1∈Rp,,Y2, f2∈R,则从式(11)~(12)有:
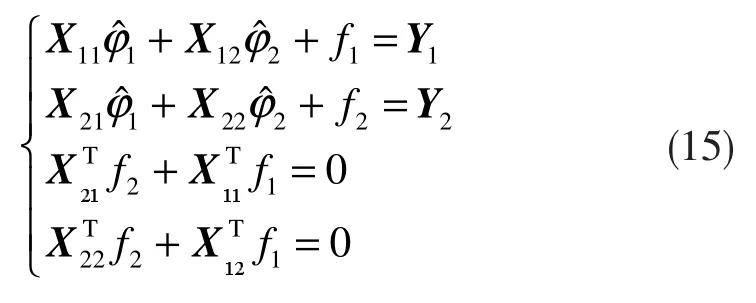
将式(15)的方程组扩展为增广系统,有:
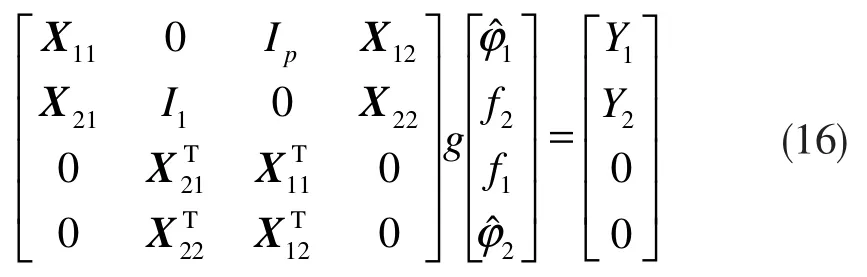
设:
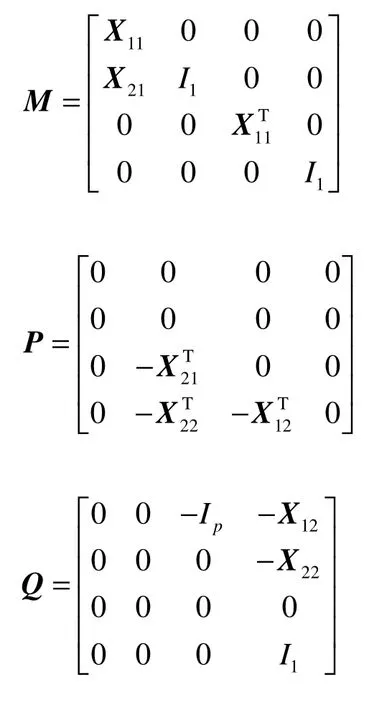
则式(16)的超松弛迭代(SOR)求解表达式为[18]:
式(17)中,ω∈(0,2),称为松弛因子;而迭代矩阵则为:
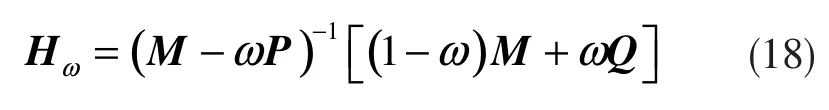
给定某一迭代求解误差值,便可运用式(17)迭代求解升阶后的模型参数,然后从候补数据序列递补一个新的数据继续进行升阶辨识。如果出现rank(Xp+1) <p+1,则确定当前的自回归模型的阶数为p,并同时结束整个辨识过程。
3.3 算法设计
综上所述,可以设计如下的平稳时序数据的高效辨识改进算法。
算法名称:平稳时序数据的高效辨识改进算法
输入:平稳时序数据序列xt(t=1,2,…,n)、Bootstrap 重抽样次数N、迭代求解误差e;
步骤1:对xt进行N 次Bootstrap 重抽样,并估算总体样本的Bootstrap 数学期望估值和Bootstrap方差估值;
步骤2:根据步骤1 的计算结果,按照式(7)生成完全随机型序列,并利用式(8)析出相依随机型序列,同时置p=0;
步骤3:从候补数据序列递补一个新的数据xp+1,在迭代求解误差e 的约束条件下,依照式(17)的迭代和递推机制计算升阶后的参数向量
步骤4:若rank(Xp+1)<p+1 成立,则跳转至步骤6,否则跳转至步骤5;
步骤5:p=p+1,跳转至步骤3;
步骤6:打印输出计算结果并结束算法。
4 实验及结果分析
为验证上述改进算法的有效性及先进性,选取不同阶数,并叠加不同高斯正态分布的完全随机型序列的平稳时序数据进行实验。实验在PC 机上进行,其硬件配置为:
Intel 酷睿i5 4570 四核CPU,
Kingmax DDR3 16GB RAM,
Samsung 850PRO SSD 固态硬盘;
操作系统与开发环境为:
Microsoft Windows 10,
Microsoft Visual Studio 2010 集成开发环境中的C++。
在实验过程中,着重从辨识精度和计算成本等技术指标方面与现有算法进行对比,并就相关结果加以详细分析和讨论。
4.1 实验过程与方法
为不失一般性,使用阶数分别为2、4 及6 共三个平稳时序数据模型进行实验。具体的模型参数如表1 所示。此外,在实验的过程中,分别在上述模型叠加了数学期望和方差为{(0,1),(1,2)}的完全随机型序列。
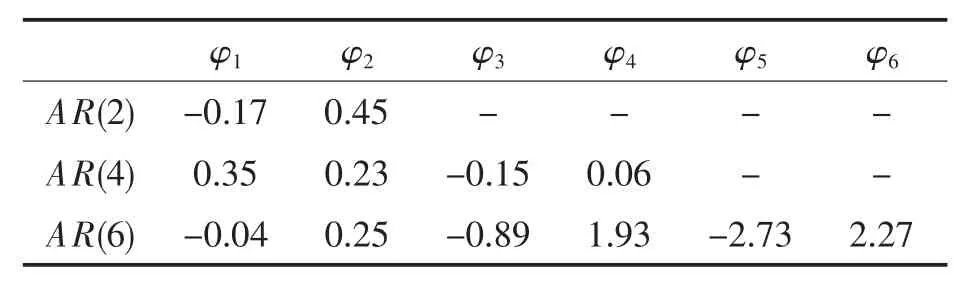
表1 实验选用数据模型具体参数
对上述不同阶数的自回归模型、不同数学期望和方差的完全随机型序列进行组合,便可得到不同的实验组合,实验过程中将对文献[13]算法和本改进算法的辨识性能指标进行相关的比对。
4.2 实验的结果与分析
为了全面考察各算法的辨识精度,引入平均绝对百分误差(Mean Absolute Percentage Error, MAPE)的性能评价标准,其具体定义如式(19)所示[19]:
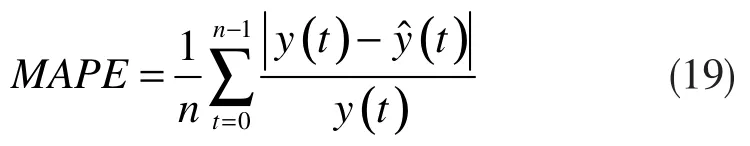
各种实验组合的辨识结果如表2 所示,它们的辨识误差曲线则如图2~图4 所示。
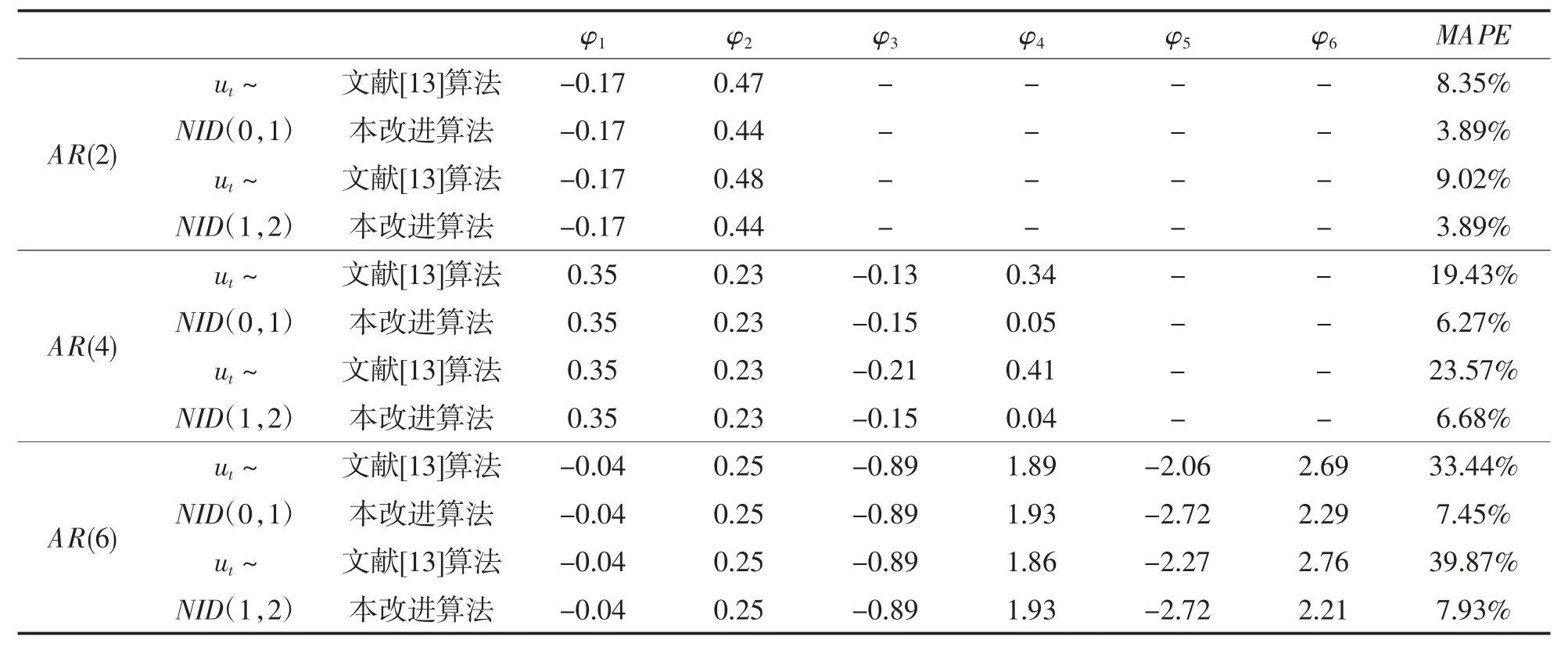
表2 各种实验组合的辨识结果
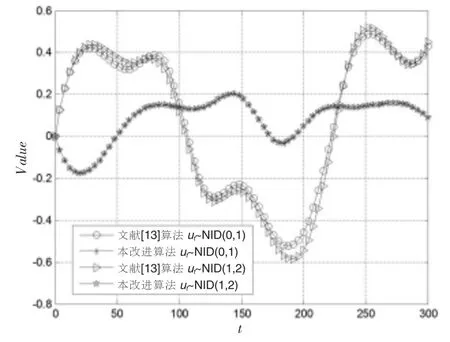
图2 AR(2)模型实验组合的辨识误差曲线
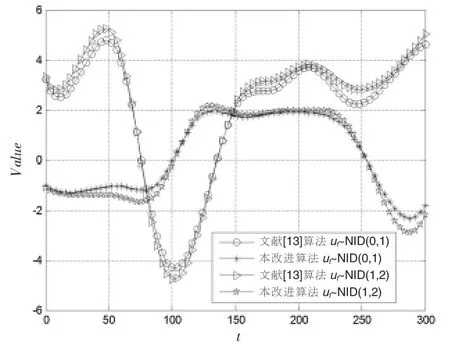
图3 AR(4)模型实验组合的辨识误差曲线
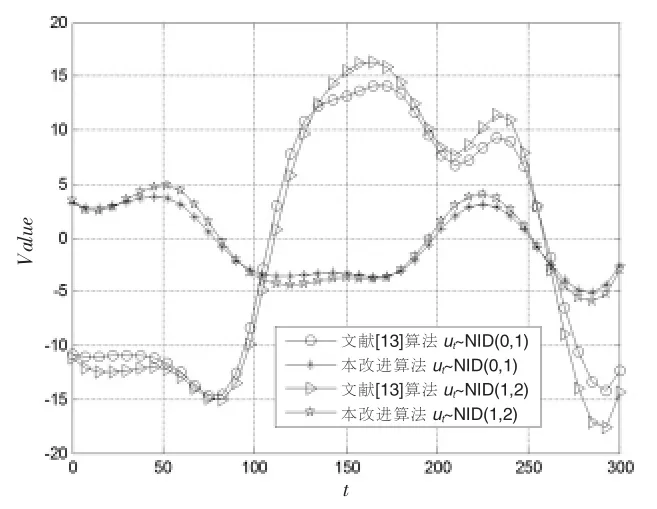
图4 AR(6)模型实验组合的辨识误差曲线
通过对比表2 中各种实验组合的辨识结果,结合图2~图4 的辨识误差曲线,便可发现:模型阶数和完全随机型序列均在不同程度上影响着算法的辨识精度。其中,文献[13]算法的辨识精度与模型阶数有着高度的非线性增长关系,在阶数从2 升至4、6 的过程中,其辨识精度也从高精度辨识(MAPE≤10 )向良好辨识(10<MAPE≤20%)、可行辨识(20<MAPE≤30%)以至粗略辨识(30<MAPE≤50%)切换;经过对比明显可见,改进算法的辨识精度具有良好的稳定性,在升阶过程中,其辨识精度始终维持在高精度辨识的范围内。事实上,本改进算法在通过Bootstrap 重抽样对完全随机型序列进行估计和消除后,其自回归模型方程有了更为精确的数学描述,从而保证了估参过程中的误差没有随着阶数的增加而增加。另一方面,具有较大的数学期望和方差的完全随机型序列对算法的辨识精度也有一定的制约。对于文献[13]算法而言,由于忽略了的作用,其自回归模型方程的数学描述出现了更大的偏差;对于本改进算法而言,由于完全随机型序列在原序列中的成分比重加大,在某一程度上也影响了Bootstrap 重抽样估计的精度,但根据表2 的MAPE数值可知,该影响对改进算法而言还是较为轻微的。
为了评价融合迭代和递推机制的模型求解方法的计算性能,在实验过程中,利用Bootstrap 重抽样从待辨识序列中析出完全随机型序列后,分别用文献[13]的分块矩阵递推求逆方法、改进后的融合迭代和递推机制的求解法对同一辨识序列进行模型求解,结果如表3 所示。融合迭代和递推机制的求解法较分块矩阵递推求逆方法更为精确。此外,对比表2 和表3 的MAPE 数值,也可发现:文献[13]算法的辨识误差主要是由忽略了完全随机型序列而引起的。
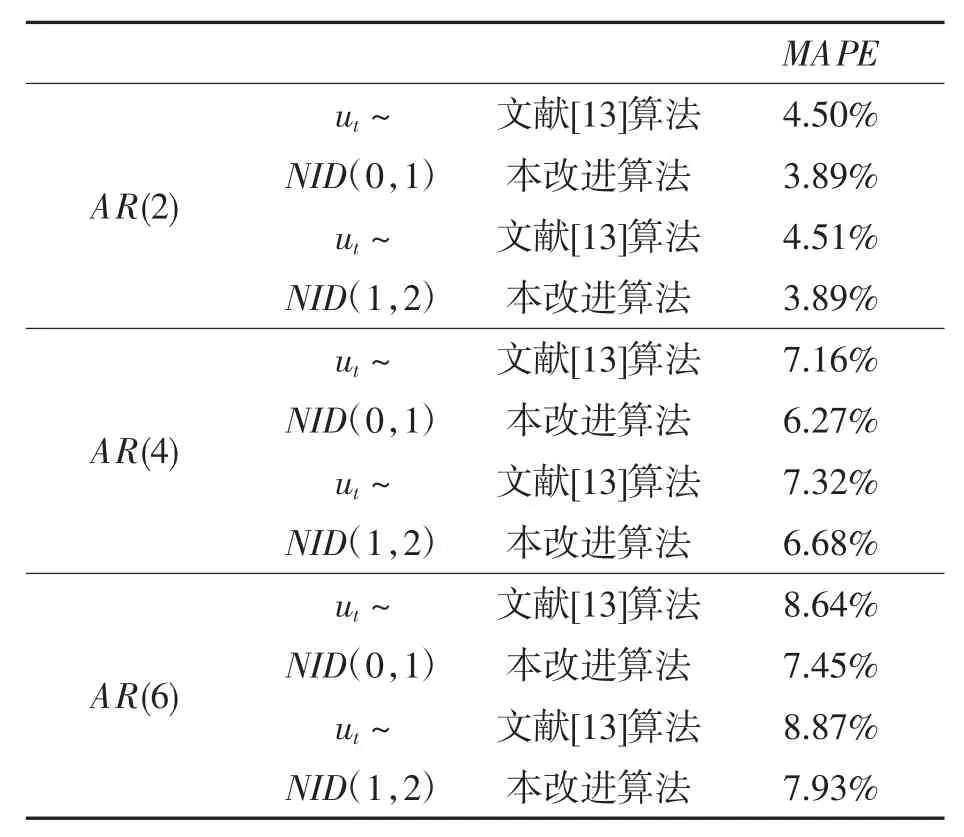
表3 不同模型估参法的辨识精度对比
在实验序列的样本长度n 为300,Bootstrap 重抽样次数N 为1000 的条件下,各种实验组合的计算耗时情况如图5 所示。由图易知,不同类型的完全随机型序列并不影响文献[13]算法及本改进算法的计算耗时。
从图5 可见,在不同模型阶数的辨识过程中,本改进算法的计算耗时较文献[13]算法增加了12%~15%左右。值得注意的是,改进算法由于设计了融合迭代和递推机制的模型参数估计方法,其计算耗时并没有随着模型阶数的增加而大幅增长,事实上,本算法所增加的计算耗时是由于引入了Bootstrap 重抽样处理而引起的,该耗时增量为定值,且仅与抽样次数N 有关。
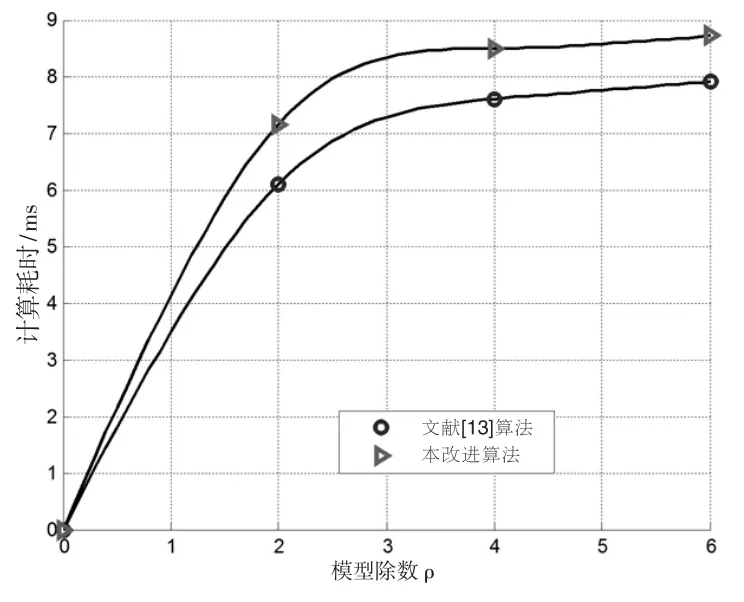
图5 各种实验模型组合的计算耗时
综上所述,改进算法仅花费了少量的额外计算耗时,其辨识精度稳定性便有了显著提升。据此,本改进算法是正确和有效的。
5 结束语
基于时序数据驱动的系统辨识,在实际应用中有着广泛的适用场合,在综合考虑已有算法的优劣的基础上,提出一种平稳时序数据的自回归模型高效辨识改进算法。经过实验得知,改进算法的辨识精度具有较强的鲁棒性。此改进算法还有继续完善的空间,下一步的主要工作应包括:改进现有的Bootstrap 重抽样的估计效率,研究更为高效的迭代和递推的求解机制,以便进一步提升算法的预测精度和计算效能。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
医疗装备(2022年17期)2022-09-19
小猕猴智力画刊(2022年3期)2022-03-28
农业工程学报(2022年1期)2022-03-25
南华大学学报(自然科学版)(2021年3期)2021-07-21
华东师范大学学报(自然科学版)(2021年3期)2021-06-03
意林·作文素材(2021年23期)2021-01-22
教育教学论坛(2018年39期)2018-09-25
读与写·教育教学版(2017年10期)2017-11-10
南都周刊(2015年4期)2015-09-10
